







这次主要谈一下对推荐系统中的用户相似度进行的一个改进。
首先有这样的一个现象,有些热门物品是很多人都共同拥有的,并不能代表兴趣所在,如:新华字典等,然而冷门物品往往可以反应兴趣所在,比如,买了数据挖掘导论,一般只有做数据挖掘的人才会买这个书。所以我们在计算用户相似度的时候,可以考虑给热门物品增加一个惩罚项。
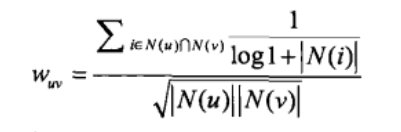
算法实现如下:
def UserSimilarity(train):
#build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in items.keys():
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1/math.log(1+len(users))
#calculate finial similarity matrix w
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv /math.sqrt(N[u]*N(v))
return W














 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









