







 本文介绍了LSTM模型的基本原理,强调了其在处理序列数据依赖和记忆功能的优势,以及在实际应用中的优化方法,如使用灰狼优化算法调整超参数。文章还提供了GWO-LSTM预测模型的实现示例。
本文介绍了LSTM模型的基本原理,强调了其在处理序列数据依赖和记忆功能的优势,以及在实际应用中的优化方法,如使用灰狼优化算法调整超参数。文章还提供了GWO-LSTM预测模型的实现示例。
本期文章将介绍LSTM的原理及其优化实现
序列数据有一个特点,即“没有曾经的过去则不存在当前的现状”,这类数据以时间为纽带,将无数个历史事件串联,构成了当前状态,这种时间构筑起来的事件前后依赖关系称其为时间依赖,利用这类依赖关系进行建模是对其进行学习的关键。
近年来,越来越多的神经网络模型被用于序列数据的预测,如股票、电力负荷、风电功率、心电信号等场景,并取得了不错的效果。
通常,神经网络模型可以分为两类:
一类是以BP神经网络为代表的神经网络,这类网络结构简单,但容易出现陷入局部极值、过拟合等问题,并且其并没有对于依赖关系进行利用;
另一类是更深层次、更高效的深度神经网络模型,如CNN、RNN、LSTM,这类网络是较为前沿和高效的预测模型,其能够拟合输入变量间的非线性复杂关系,并且对于RNN和LSTM来说,其能够克服传统神经网络没有记忆功能的问题,可以有效的根据历史信息进行学习和预测。相对于RNN,LSTM能避免RNN在长序列数据中出现的梯度消失或爆炸的问题,是最为流行的RNN(LSTM是在RNN基础上的改进),因此LSTM在序列数据学习中得到了广泛应用。
LSTM同样面临着隐含层神经元个数、学习率、迭代次数等超参数设置的问题,这些参数都将影响LSTM的预测精度,利用优化算法进行超参数的寻优比经验法更为科学高效,因此本文将详细介绍LSTM模型的原理及其优化实现。
00 目录
1 LSTM模型原理
2 优化算法及其改进概述
3 GWO-LSTM预测模型
4 代码目录
5 实验结果
6 源码获取
01 LSTM神经网络模型[1]
长短时记忆神经网络(LSTM)是Sepp Hochreiter和Jurgen Schmidhuber在1997年对递归神经网络(RNN)进行改进的算法。它旨在解决递归神经网络(RNN)产生的梯度消失问题,在长距离依赖任务中的表现也远好于RNN。LSTM模型的工作方式和RNN基本相同,但是LSTM模型实现了更为复杂的内部处理单元来处理上下文信息的存储与更新。
Hochreiter 等人主要引入了记忆单元和门控单元实现对历史信息和长期状态的保存,通过门控逻辑来控制信息的流动。后来Graves等人对LSTM单元进行了完善,引入了遗忘门,使得LSTM模型能够学习连续任务,并能对内部状态进行重置。
LSTM主要由三个门控逻辑(输入、遗忘和输出)实现。门控可以看作一层全连接层,LSTM对信息的存储和更新正是由这些门控来实现的。更具体地说,门控由Sigmoid函数和点乘运算实现。
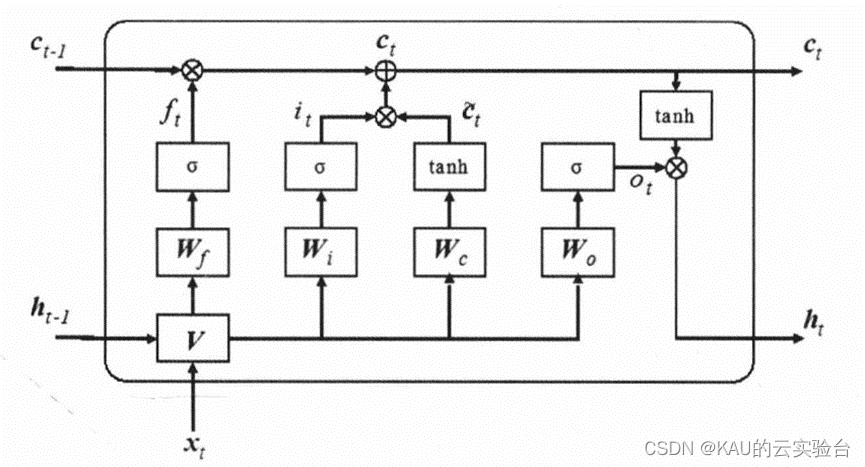
这里分别使用i、f、o来表示输入门、遗忘门和输出门,O表示对应元素相乘,W和b分别表示网络的权重矩阵与偏置向量。在时间步为t时,LSTM隐含层的输入与输出向量分别为x,和h,,记忆单元为c,,输入门用于控制网络当前输入数据x,流入记忆单元的多少,即有多少可以保存到c,,其值为:
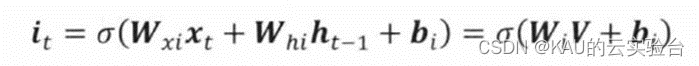
遗忘门是LSTM 的关键组成部分,可以控制哪些信息要保留哪些要遗忘,并且以某种方式避免当梯度随时间反向传播时引发的梯度消失和爆炸问题。遗忘门可以决定历史信息中的哪些信息会被丢弃,即判断上一时刻记忆单元ct-1中的信息对当前记忆单元ct的影响程度。
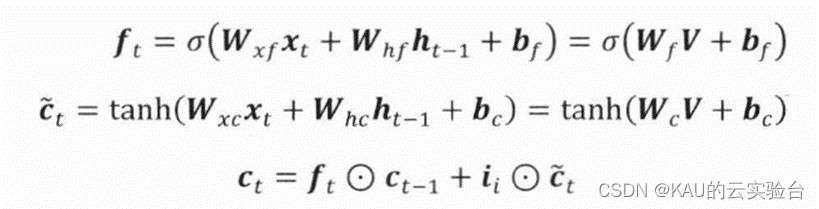
输出门控制记忆单元c,对当前输出值h,的影响,即记忆单元中的哪一部分会在时间步t输出。输出门的值及隐含层的输出值可表示为:
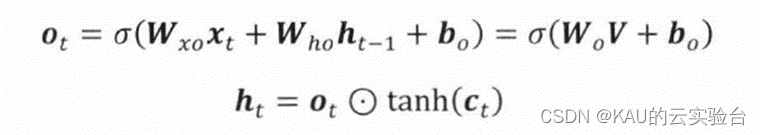
02 优化算法及其改进概述
前面的文章中作者介绍了许多种优化算法及其改进算法,
这里我们以灰狼优化算法为例,其他算法同理。作者的代码很多都是标准化的,其他文章里的算法替换起来也很容易。
03 GWO-LSTM预测模型
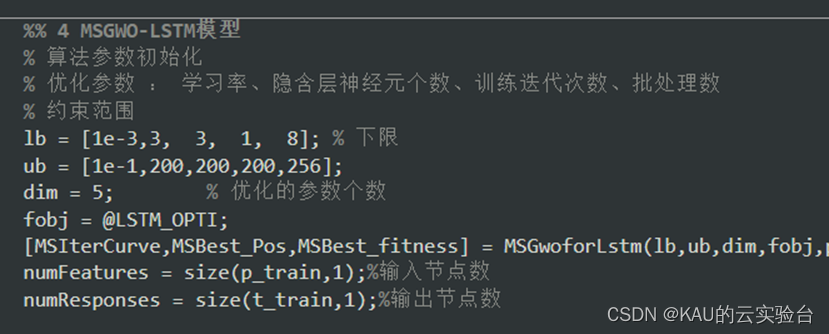
超参数在一定程度上会影响LSTM网络的拟合精度,因此必须获得适合不同特征数据的最佳超参数值。然而,目前还没有成熟的理论来获得合适的超参数值。因此,本文采用灰狼优化算法,得到LSTM的最佳网络超参数值,包括初始学习率、隐含层神经元数、批次大小和训练迭代次数,即[lr,L1,L2,Batch,k]。其中增加隐藏层数可提高模型的非线性拟合能力,但同时也使模型更复杂,预测时间随之增加,甚至引发过拟合问题﹐因此本文将隐藏层数选择的范围控制在2层。优化参数的约束条件设置如下:
以MSE作为适应度,GWO-LSTM预测模型的流程图如下: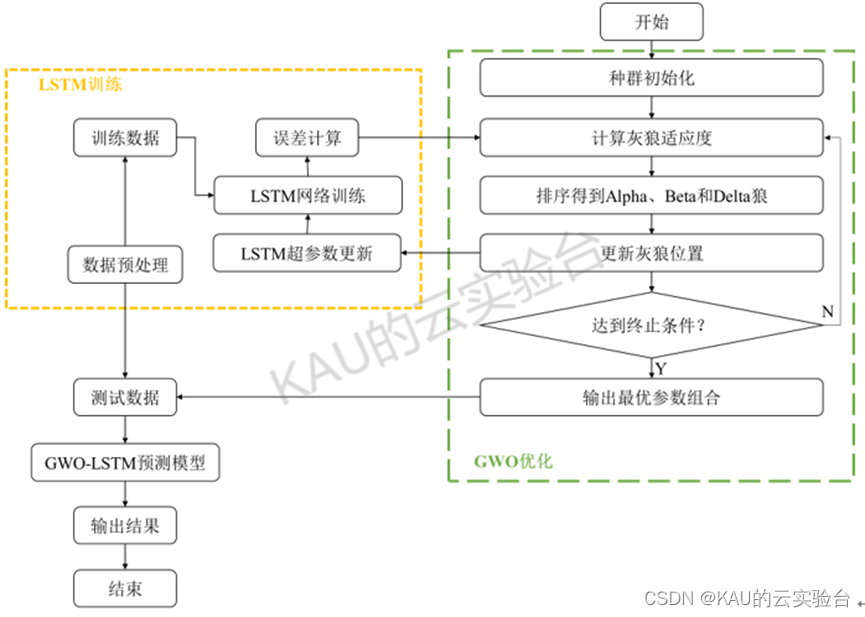
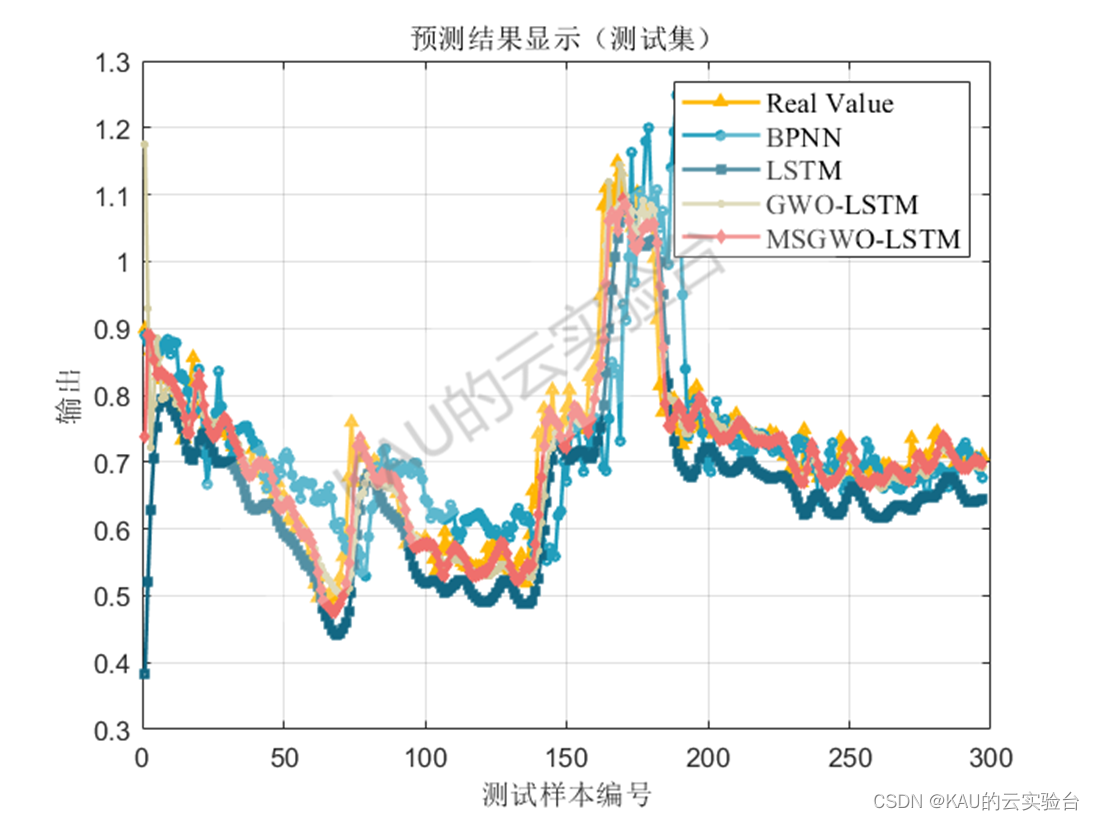
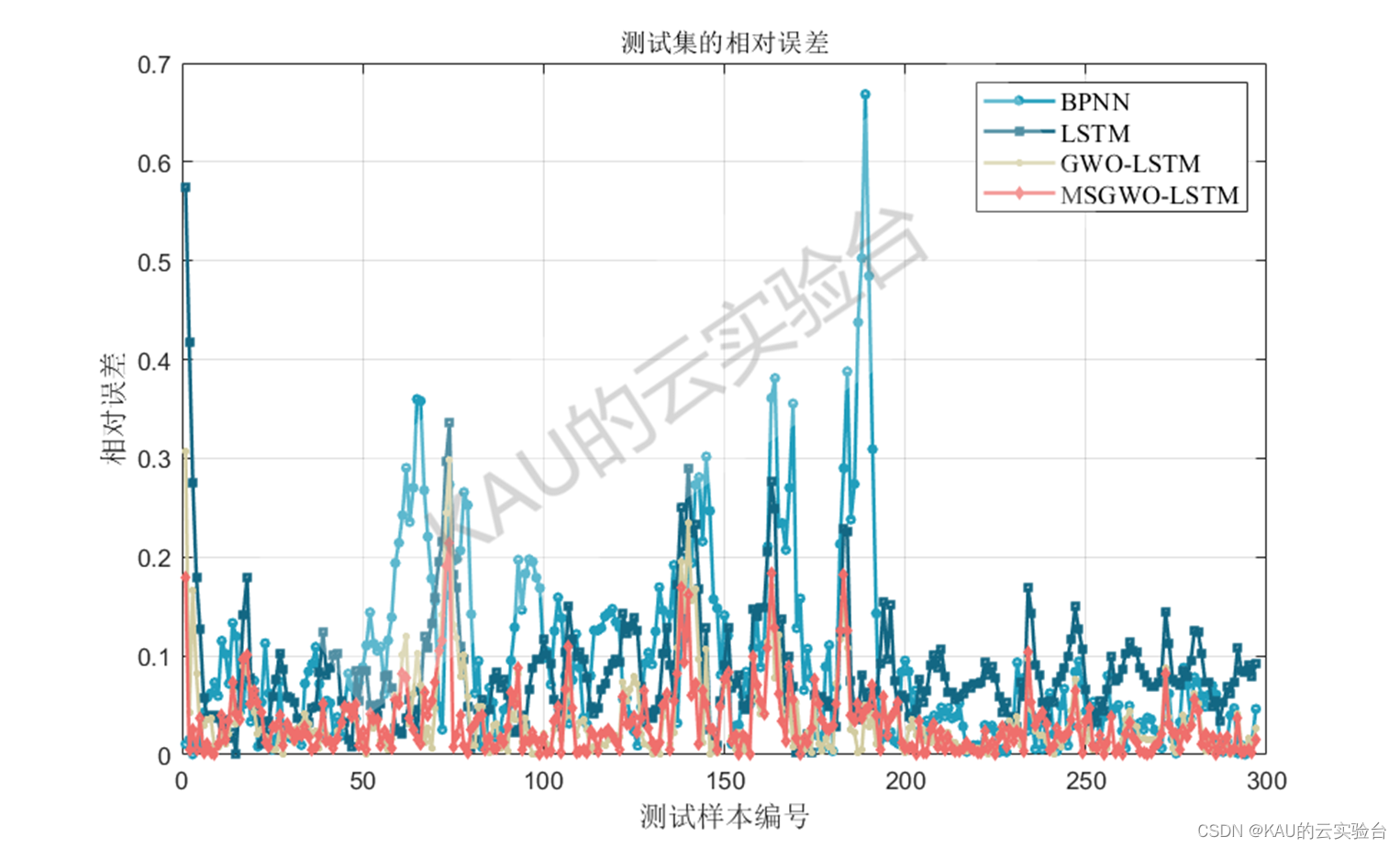
04 实验结果
以均方根差(Root Mean Square Error,RMSE) 、平均绝对百分误差( Mean Absolute Percentage Error,MAPE) 、平均绝对值误差 ( Mean Absolute Error,MAE) 和可决系数(coefficient of determination,R^2)作为序列数据拟合的评价标准。
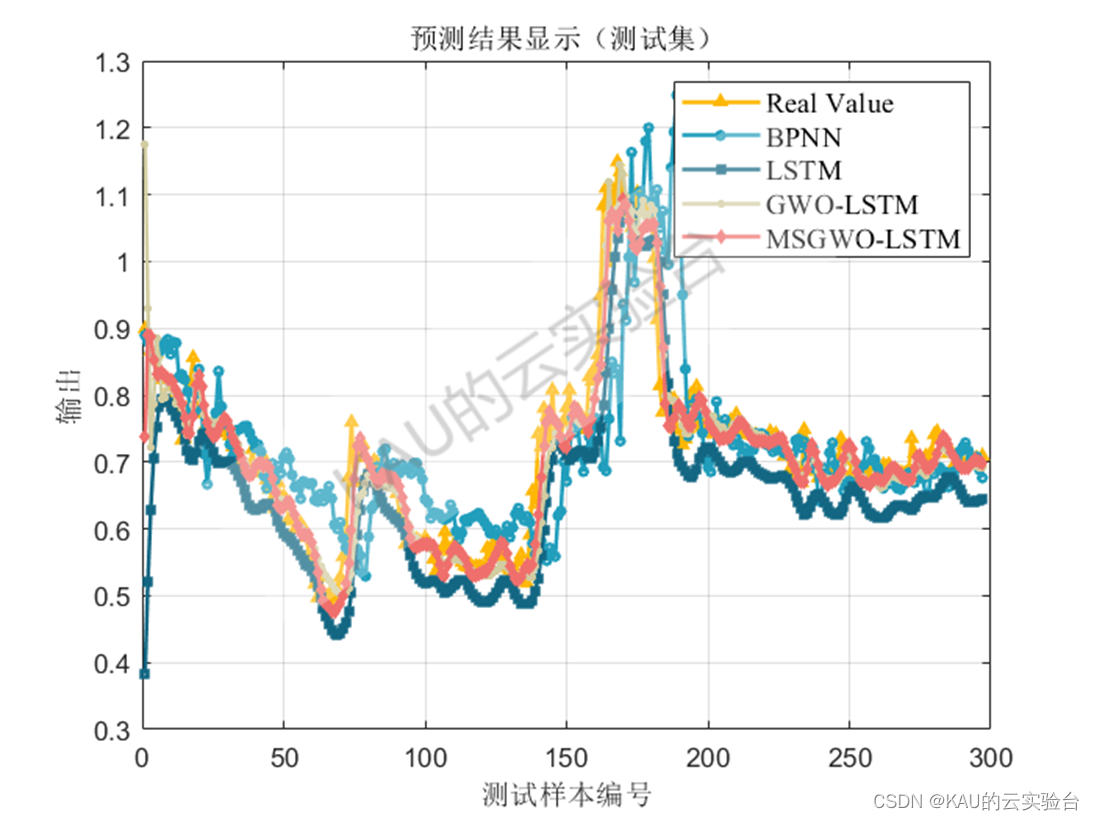
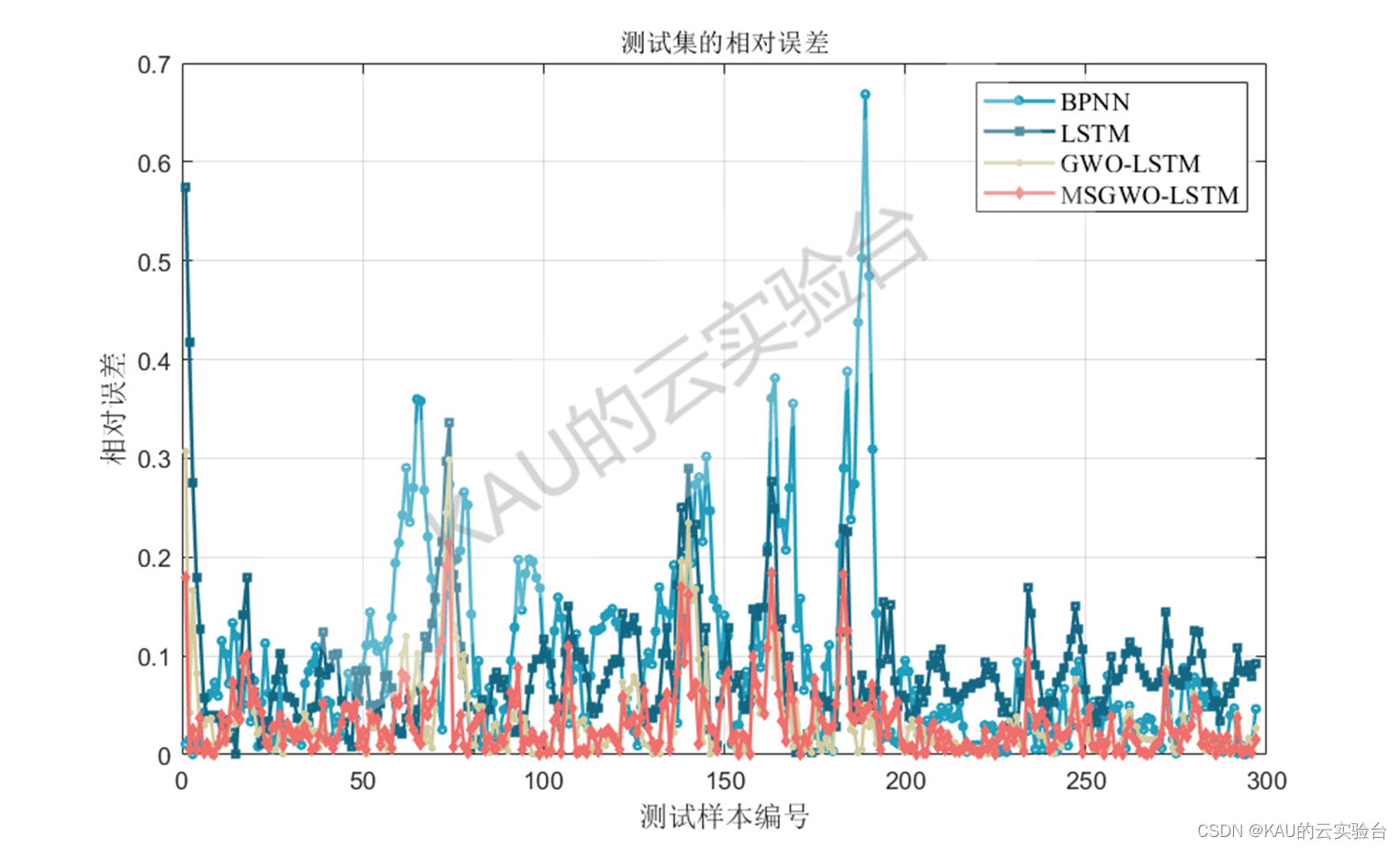
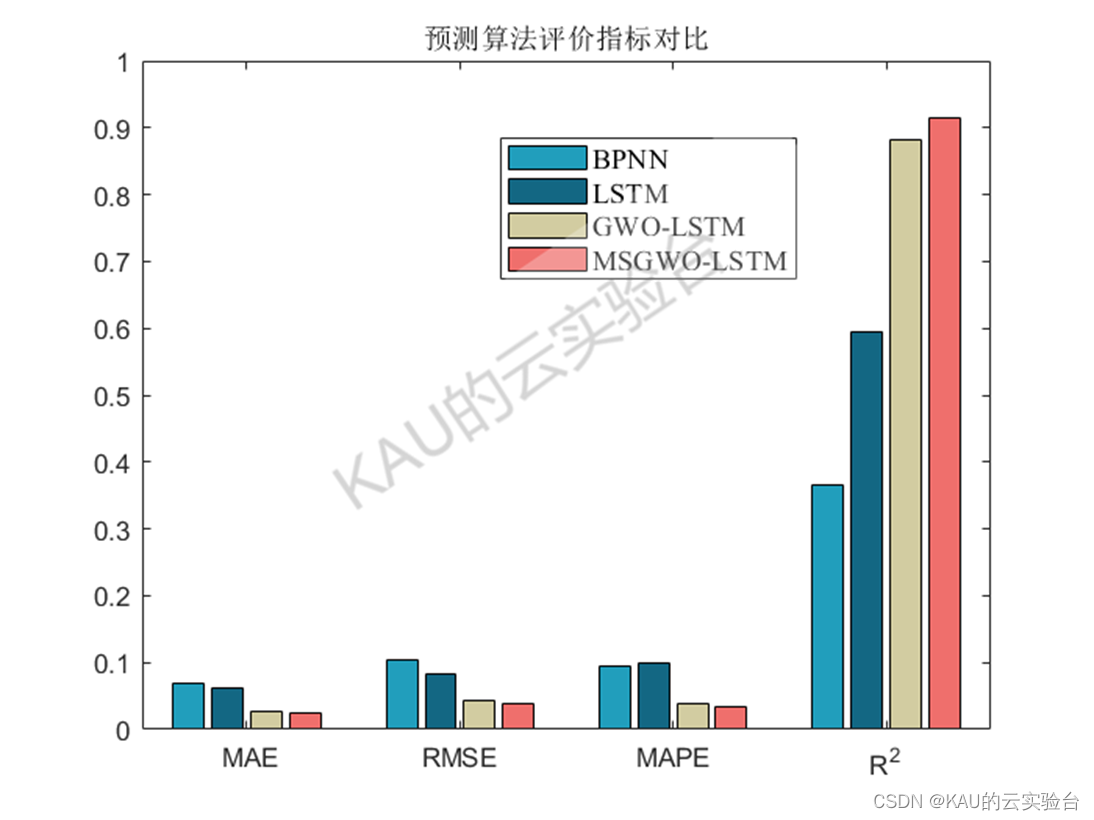
图中MSGWO为作者前面改进的灰狼优化算法
05 源码获取
代码注释详细,一般只需要替换数据集就行了,注意数据的行是样本,列是变量,源码提供3个版本
1.免费版
其主要是LSTM预测模型,包含Matlab和Python的程序,对于需要进行一些简单预测或者是想学习LSTM算法的同学足够了。

获取方式——GZH(KAU的云实验台)后台回复:LSTM
2.付费版1
主要是GWO优化LSTM的预测模型,这个只包含了Matlab程序,包括BP、LSTM、GWO-LSTM的预测对比。因为最近比较忙,Python就没有出,程序的注释详细,易于替换,卡卡之前介绍过的智能优化算法都可以进行替换。
获取方式——GZH后台回复:GWOLSTM
3.付费版2
主要是MSGWO优化LSTM的预测模型,这个只包含了Matlab程序,包括BP、LSTM、GWO-LSTM、MSGWO-LSTM的预测对比,也即在结果展示中的图片,其中MSGWO即为卡卡前面的融合多策略的改进灰狼优化算法的文章,程序的注释详细,这部分程序包含了函数测试、预测模型两个部分,可以用来发这类方向的文章,当然你也可以在卡卡算法的基础上再作创新改进,比如预测模型上可以再对预测误差做一个预测模型进行级联,或者对改进的灰狼算法再引入别的修改策略等等。
获取方式——GZH后台回复:MSGWOLSTM
[1]游皓麟著.Python预测之美:数据分析与算法实战[M] .电子工业出版社
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞/在看(ง •̀_•́)ง(不点也行)。

















 2973
2973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









