







 本文详细探讨了Transformer模型中Attention机制的重要性,包括为何Attention不可或缺,Query、Key和Value的作用,以及编码器和解码器的工作原理。文章还解释了多头注意力和多层注意力层的设计,以及为何需要skipconnections来增强模型性能。
本文详细探讨了Transformer模型中Attention机制的重要性,包括为何Attention不可或缺,Query、Key和Value的作用,以及编码器和解码器的工作原理。文章还解释了多头注意力和多层注意力层的设计,以及为何需要skipconnections来增强模型性能。
1. 引言
最近,ChatGPT和其他聊天机器人将大语言模型LLMs推到了风口浪尖。这就导致了很多不是学ML和NLP领域的人关注并学习attention和Transformer模型。在本文中,我们将针对Transformer模型结构提出几个问题,并深入探讨其背后的技术理论。这篇文章针对的听众是已经研读过Transformer论文并大概了解attention如何工作的同学。
闲话少说,我们直接开始吧!
2. 为什么非Attention不可?
首先我们来将机器翻译作为例子进行讲解。在Attention机制出现之前,大多数机器翻译都是通过encoder-decoder网络结构来实现的。其中,编码器encoder的作用是通过一个RNN的网络来将输入句子(比如“I love you”)编码为一个特征向量;同时,解码器decoder的作用是接收上述特征向量并将其解码为其他语言(比如“我爱你”)。
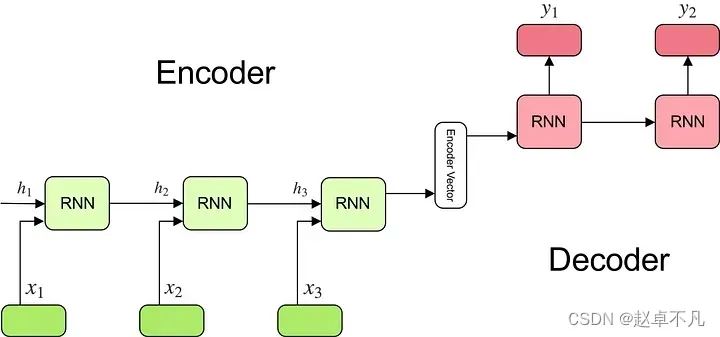
通过上述方法,编码器必须将整个输入压缩到一个固定大小的向量中,然后将该向量传递给解码器——我们期望这个向量必须包含输入句子的所有信息!显然这导致了信息瓶颈。有了注意力机制,我们不再需要将输入句子编码到单个向量中。相反,我们让解码器在生成输出的每个单词中,关注输入句子中的不同部分。
此外,以前的循环神经网络模型在输入和输出单词之间有很长的路径。如果我们有一个长度为50个单词构成的句子,解码器必须从50步前的第一个单词回忆起信息(并且最终这些数据必须压缩成一个向量)。因此,循环神经模网络型很难处理长文本依赖关系。注意力机制通过让解码器的每一步都能看到整个输入句子并决定需要关注什么词。这减少了路径长度,并使其在解码器的所有步骤中保持一致。
最后,先前的语言模型都严重依赖于RNN的方法,我们对句子进行编码时,我们从第一个单词(x1)开始并对其进行处理以获得第一个隐藏状态(h1); 然后我们输入第二个单词(x2)和之前的隐藏状态(h1)导出下一个隐藏状态(h2)。不幸的是,这个过程是按顺序执行的,这阻止了并行化。注意力通过一次性读入整个句子,并且并行地计算句子中每个单词的特征表示。
3. 什么是Query Key和Value?
我们先来举个栗子吧!假设我们在图书馆中,我们有一个具体的问题(Query), 书架上有很多图书,每个图书都有对用的书名(Key)表明书的内容。我们需要将问题(Query)与这些书名(Key)进行比较,以确定针对特定的(Query)每本书的相关性,对于每本书应该给多少关注(attention)。接着我们从相关书籍中得到信息(value)来回答上述问题。

在翻译任务中,Query指代我们需要计算attention的单词。在encoder的例子中,query一般指代当前上下文中当前输入的单词。举个栗子,假设上下文语境中输入句子的第一个单词,我们将会有一个query向量,我们将其命名为q1。
同时,Keys在翻译任务中,指代整个输入句子中的全部单词。第一个单词对应的Key的向量为k1, 第二个单词对应的key的向量为k2,其他单词类似。向量key用来帮助模型理解输入中每个单词和当前Query的相关性。在上述栗子中,我们计算所有key和q1的相似性。
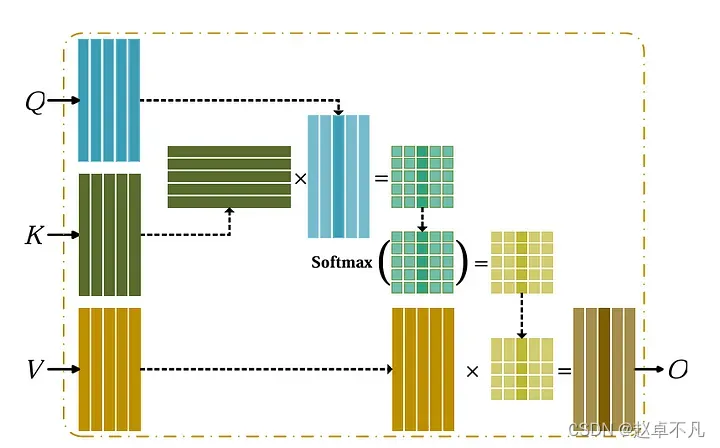
Attention一般定义为我们的查询单词query word(上例中的q1)应该给句子中的每个单词(k1,k2等)多少关注度attention。这个计算过程一般通过计算查询向量query vector和所有的key vectors的点积实现。点积一般用来评估两个向量间的相似性。如果某项query - key对应的点积较高,那就说明我们需要特别关注这一项。一般来说,上述点积计算完后还需要进一个函数softmax来执行归一化操作。
每个单词也可以被对应的value来表示,value一般特指用来表征该单词含义的向量。所有value vector被上述计算出来的attention score进行加权求和。结果看起来就是,每个contex word也就是我们的query都被attention-based weight对句子中的所有输入单词进行加权,其中和query最相近的单词含有较高的权重。
4.编码器和解码器的作用是什么?
编码器encoder接受文本作为输入,比如待翻译的句子,输出为一些嵌入embeddings。这些输出的embeddings可以被用来做分类,翻译,语义相似性计算等任务。自注意力机制确保encoder可以权衡输入中每个单词的重要程度,并解决了RNN中长文本语义依赖问题。
相反,解码器接受编码器的输出作为输入,比如句子开始标识start token和encoder的输出embeddings, 并返回预测下一个可能输出单词的概率。自注意力机制可以确保decoder关注目前生成的输出的不同部分;交叉注意力机制可以帮助解码器关注编码器的输出。
5. 解码器如何预测单词?
解码器输出下一个单词的概率(即每个可能的单词都有相关的概率)。因此,我们可以通过贪婪地选择概率最高的单词来作为下一个要生成的单词。或者,我们可以使用beam search算法,保持top n个预测,为每个top n 的预测生成下一个单词的n个预测,并选择误差较小的组合。
6. 为什么需要多头注意力机制?
多个头(head)可以让模型同时考虑多个单词。因为我们在注意力中使用了softmax函数,所以它在放大最高值的同时排挤了相对较低的值。因此,每个head都倾向于关注单个输入元素。
我们来看个栗子,假设我们的输入句子为:The chicken crossed the road carelessly。一般来说,以下词语与crossed相关,模型应该给予更多的关注:
chicken指当前执行crossed动作的目标road指被crossed的对象carelessly指执行crossing动作的程度修饰词
如果我们只有一个attention head,我们可能只会关注上述中的单个单词,也就是chicken, road或者carelessly。而多头注意力就可以关注多个单词。而且模型本身还提供了冗余,即使单个head失败,我们还有其他的attention heads来进行补充。
7. 为什么需要多个注意力层?
多个注意力层attention layers的设计就是为了构建冗余。假设我们只有一个注意力层,那么这个注意力层就必须做到完美无瑕–这种假设一般都很脆弱,往往容易得到次优的结果。此时,我们可以使用多个注意力层attention layers来解决这个问题,每个注意力层都使用前一层的输出并带有和输入直接相连的skip connection结构。这样设计的目的就是为了如果每个注意力层出现问题,skip connection和下游的注意力层可以缓解这个问题。
此外,多个注意力层的叠加也可以扩展模型的感受野。第一个注意力层通过注意输入句子中成对单词之间的注意力得分来生成上下文向量。然后,第二层基于成对的上下文向量生成更深层次的上下文向量,依次类推。有了多层注意力层,Transformer可以拥有更广泛的感受野,可以关注输入句子中的不同级别的语义交互。
8. 为什么需要skip connections?
因为注意力起着过滤器的作用,它阻止了大多数信息的传递。因此,如果注意力的得分很小或为零,对注意力层输入的微小改变很可能不会影响输出。这可能导致模型取得局部最优。
skip connections 有助于减轻过滤不良注意力的影响。即使输入的注意力权重为零且输入被阻止,skip connections 也可以将该输入的副本直接添加到输出中。这样可以确保即使对输入进行很小的更改也会对输出产生明显的影响。此外,skip connections保留了输入的语句:在Transformer中如果没有skip connections结构,不能保证上下文单词会在Transformer中处理自己。skip connections结构通过获取上下文单词向量并将其添加到输出中来确保这一点。
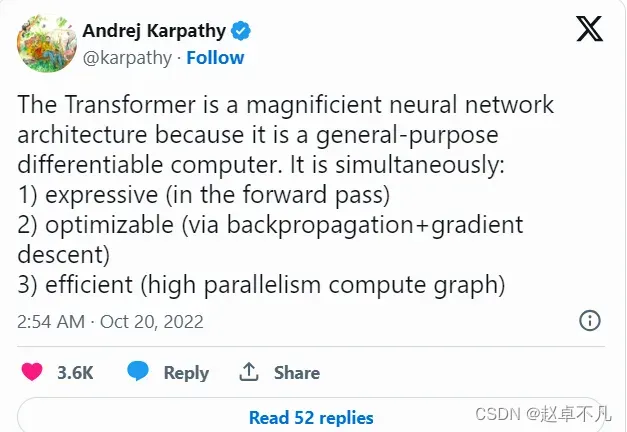
最后,让我们看看大佬Andrej Karpathy对Transformer结构的总结:
9. 参考
本文相关参考如下:
【1】Attention is All You Need:链接
【2】The ilustrated Transformer: 链接
【3】Transformers From Scratch:链接
【4】Understanding the Attention Mechanism in Sequence Models:链接
【5】Some Intuition on Attention and the Transformer:链接


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











