







上篇文章中我们使用libtorch实现了LeNet-5卷积神经网络,并对Minst数据集进行训练与分类。本文我们尝试使用该实现的网络对更加复杂的Cifar-10数据集进行训练、分类。
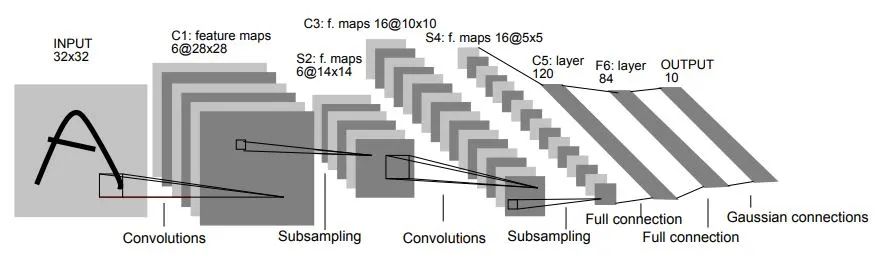
LeNet-5网络地总体结构如下,详细请参考上方地链接。
1. Cifar-10数据集介绍
Cifar-10是一个专门用于测试图像分类的公开数据集,其包含的彩色图像分为10种类型:飞机、轿车、鸟、猫、鹿、狗、蛙、马、船、货车。且这10种类型图像的标签依次为0、1、2、3、4、5、6、7、8、9。
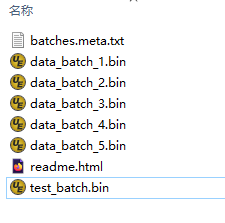
该数据集分为Python、Matlab、C/C++三个不同的版本,顾名思义,三个版本分别适用于对应的三种编程语言。因为我们使用的是C/C++语言,所以使用对应的C/C++版本就好,该版本的数据集包含6个bin文件,如下图所示,其中data_batch_1.bin~data_batch_5.bin通常用于训练,而test_batch.bin则用于训练之后的识别测试。
如下图所示,每个bin文件包含10000*3073个字节数据,在每个3073数据块中,第一个字节是0~9的标签,后面3072字节则是彩色图像的三通道数据:红通道 --> 绿通道 --> 蓝通道 (1024 --> 1024 --> 1024)。其中每1024字节的数据就是一帧单通道的32*32图像,3帧32*32字节的单通道图像则组成了一帧彩色图像。所以总体来说,每一个bin文件包含了10000帧32*32的彩色图像。

2. 训练策略
(1) epoch
首先我们讲一下epoch的概念:一个epoch就是将所有的训练数据都输入神经网络,并完成前向传播、反向传播、参数更新的过程。比如我们使用Cifar-10数据集进行训练的时候,训练数据包含于5个bin文件中,每个bin文件有10000张32*32图像,因此总共有5*10000张训练图像,当我们把这5*10000张训练图像都输入网络并完成训练的过程,就是一个epoch过程。
然而,往往一个epoch过程过程达不到参数收敛的目的,因此需要执行多个epoch过程,也就是说:使用这5*10000张训练图像完成一次训练之后,在此次训练得到参数模型的基础上,再重复使用这5*10000张训练图像进行下一轮训练。
(2) 学习率的改变
我们把学习率α的初始值设置为0.001,每完成一个epoch,参数都进一步接近收敛状态,因此这个时候我们需要适当比例地减小α,以缩短步长:
α = α*0.8
3. 数据格式转换
(1) 图像格式转换
我们使用Opencv来读取Cifar-10图像为Mat格式,但是libtorch框架处理的数据格式为Tensor格式,因此首先需要把Mat格式的图像转换为Tensor格式。调用from_blob函数可方便进行转换,不过要注意转换时需指定数据维度为1*1*row*col,其中row、col分别为图像的高、宽。
//test_img[i]为Mat格式,test_img[i].data为Mat的数据首地址
//{ 1, 1, test_img[i].rows, test_img[i].cols }指定Tensor张量的维度为1*1*row*col
//torch::kFloat表示以float格式转换数据,该类型要与Mat本来的数据类型相一致,否则会出错
torch::Tensor inputs = torch::from_blob(test_img[i].data, { 1, 1, test_img[i].rows, test_img[i].cols }, torch::kFloat);
(1) 标签格式转换
我们读取的标签为单个uchar型数据,但是libtorch框架处理的数据格式为Tensor格式,因此首先需要把单个uchar数据转换为Tensor格式。调用from_blob函数也可方便转换,同样要注意转换时需指定数据维度为1,也就是只有一个数据的张量。
//test_label[i]为一个uchar数据,&test_label[i]表示该数据的地址
//{ 1 }表示该张量的维度为1
//torch::kByte表示以uchar类型读取该数据,该参数需要与数据本身的类型一致
//toType(torch::kLong)表示把Tensor张量转换为long int类型,因为要求标签的类型为long int
torch::Tensor labels = torch::from_blob(&test_label[i], { 1 }, torch::kByte).toType(torch::kLong);
4. 主要代码实现
(1) 读取Cifar-10数据与标签代码
读取到的图像为uchar型的三通道彩色图像,因此需要将其转换为单通道灰度图,并转换为-1~1之间的浮点型数据,方便后续的训练、分类。
void read_cifar_bin(char *bin_path, vector<Mat> &img_liat, vector<uchar> &label_list)
{
const int img_num = 10000;
const int img_size = 3073; //第一字节是标签
const int img_size_1 = 1024;
const int data_size = img_num * img_size;
const int row = 32;
const int col = 32;
uchar *cifar_data = (uchar *)malloc(data_size);
if (cifar_data == NULL)
{
cout << "malloc failed" << endl;
return;
}
FILE *fp = fopen(bin_path, "rb");
if (fp == NULL)
{
cout << "fopen file failed" << endl;
free(cifar_data);
return;
}
fread(cifar_data, 1, data_size, fp);
img_liat.clear();
label_list.clear();
for (int i = 0; i < img_num; i++)
{
long int offset = i * img_size;
long int offset0 = offset + 1; //红
long int offset1 = offset0 + img_size_1; //绿
long int offset2 = offset1 + img_size_1; //蓝
uchar label = cifar_data[offset]; //标签
Mat img(row, col, CV_8UC3);
for (int y = 0; y < row; y++)
{
for (int x = 0; x < col; x++)
{
int idx = y * col + x;
img.at<Vec3b>(y, x) = Vec3b(cifar_data[offset2 + idx], cifar_data[offset1 + idx], cifar_data[offset0 + idx]); //BGR
}
}
Mat gray;
cvtColor(img, gray, COLOR_BGR2GRAY); //三通道彩色图转换为单通道灰度图
gray.convertTo(gray, CV_32F); //uchar转换为float
gray = gray / 255.0; //范围0~1
gray = (gray - 0.5) / 0.5; //范围-1~1
img_liat.push_back(gray.clone()); //float
label_list.push_back(label); //uchar
}
fclose(fp);
free(cifar_data);
}
(2) LeNet-5网络定义
struct LeNet5 : torch::nn::Module
{
//arg_padding为C1层的padding参数,当输入图像为28*28时,需要将其填充为32x32的图像
//这里可能有人会有疑惑,为什么没有定义S2、S4层,这是因为池化层放在前向传播函数中执行即可,不需要再定义了,详细见forward函数
LeNet5(int arg_padding = 0)
//C1层
: C1(register_module("C1", torch::nn::Conv2d(torch::nn::Conv2dOptions(1, 6, 5).padding(arg_padding))))
//C3层
, C3(register_module("C3", torch::nn::Conv2d(6, 16, 5)))
//C5层
, C5(register_module("C5", torch::nn::Conv2d(16, 120, 5)))
//F6层
, F6(register_module("F6", torch::nn::Linear(120, 84)))
//OUTPUT层
, OUTPUT(register_module("OUTPUT", torch::nn::Linear(84, 10)))
{
}
~LeNet5()
{
}
//该函数用于将多维数据一维展开成一维向量
int64_t num_flat_features(torch::Tensor input)
{
int64_t num_features = 1;
auto sizes = input.sizes();
for (auto s : sizes)
{
num_features *= s;
}
return num_features;
}
//前向传播函数
torch::Tensor forward(torch::Tensor input)
{
namespace F = torch::nn::functional;
//这一步其实包含了3个操作,首先是C1层的卷积,其次是将卷积结果输入Relu函数,接着是将Relu函数的结果做最大值的池化操作
auto x = F::max_pool2d(F::relu(C1(input)), F::MaxPool2dFuncOptions({ 2,2 }));
//这一步也包含了3个操作,首先是C3层的卷积,其次是将卷积结果输入Relu函数,接着是将Relu函数的结果做最大值的池化操作
x = F::max_pool2d(F::relu(C3(x)), F::MaxPool2dFuncOptions({ 2,2 }));
//将C5层的卷积结果输入Relu函数,Relu函数的结果作为本层输出
x = F::relu(C5(x));
//120张1*1的卷积结果图像按顺序展开成长度为120的一维向量
x = x.view({ -1, num_flat_features(x) });
//F6层的Affine计算
x = F::relu(F6(x));
//OUTPUT层的Affine计算,注意这里不包括Softmax层计算,Softmax层计算放到后面的交叉熵误差函数中去做
x = OUTPUT(x);
return x;
}
//要求这里的各层定义与本结构体开头处的定义保持一致
int m_padding = 0;
torch::nn::Conv2d C1;
torch::nn::Conv2d C3;
torch::nn::Conv2d C5;
torch::nn::Linear F6;
torch::nn::Linear OUTPUT;
};
(3) 训练代码
Cifar-10图像本来就是32*32大小,因此不需要像Minst数据集那样填充数据。
void tran_lenet_5_cifar_10(void)
{
vector<Mat> train_img_total;
vector<uchar> train_label_total;
//定义一个LeNet-5网络结构体,输入的图像是32x32图像,不需要填充
LeNet5 net1(0);
//使用交叉熵误差函数
auto criterion = torch::nn::CrossEntropyLoss();
int kNumberOfEpochs = 8; //训练8个epoch
int data_file_num = 5; //总共5个训练文件
double alpha = 0.001; //学习率初始值0.001
for (int epoch = 0; epoch < kNumberOfEpochs; epoch++)
{
printf("epoch:%d\n", epoch+1);
//定义梯度下降法优化器
auto optimizer = torch::optim::SGD(net1.parameters(), torch::optim::SGDOptions(alpha).momentum(0.9));
for (int k = 1; k <= data_file_num; k++)
{
printf("data_file_num:%d\n", k);
auto running_loss = 0.;
char str[200] = { 0 };
sprintf(str, "D:/Program Files (x86)/Microsoft Visual Studio 14.0/prj/KNN_test/KNN_test/cifar-10-batches-bin/data_batch_%d.bin", k);
//读取10000张cifar-10训练图像
read_cifar_bin(str, train_img_total, train_label_total);
for (int i = 0; i < train_img_total.size(); i++)
{
//Mat转换为Tensor
torch::Tensor inputs = torch::from_blob(train_img_total[i].data, { 1, 1, train_img_total[i].rows, train_img_total[i].cols }, torch::kFloat); //1*1*32*32
//uchar转换为Tensor
torch::Tensor labels = torch::from_blob(&train_label_total[i], { 1 }, torch::kByte).toType(torch::kLong); //1
//清零梯度
optimizer.zero_grad();
//前向传播
auto outputs = net1.forward(inputs);
//计算交叉熵误差
auto loss = criterion(outputs, labels);
//误差反向传播
loss.backward();
//更新参数
optimizer.step();
//累加每1000个误差值,方便查看训练时交叉熵误差函数的下降情况
running_loss += loss.item().toFloat();
if ((i + 1) % 1000 == 0)
{
printf("loss: %.3f\n", running_loss / 1000);
running_loss = 0.;
}
}
}
alpha *= 0.8; //完成一个epoch,减小学习率
}
printf("Finish training!\n");
torch::serialize::OutputArchive archive;
net1.save(archive);
archive.save_to("mnist_cifar_10.pt");
printf("Save the training result to mnist.pt.\n");
}
(4) 分类测试代码
void test_lenet_5_cifar_10(void)
{
LeNet5 net1(0);
torch::serialize::InputArchive archive;
archive.load_from("mnist_cifar_10.pt"); //加载上一步骤训练好的模型
net1.load(archive);
//读取测试数据与标签
vector<Mat> test_img;
vector<uchar> test_label;
read_cifar_bin("D:/Program Files (x86)/Microsoft Visual Studio 14.0/prj/KNN_test/KNN_test/cifar-10-batches-bin/test_batch.bin", test_img, test_label);
int total_test_items = 0, passed_test_items = 0;
double total_time = 0.0;
for (int i = 0; i < test_img.size(); i++)
{
//将Mat格式转换为Tensor格式
torch::Tensor inputs = torch::from_blob(test_img[i].data, { 1, 1, test_img[i].rows, test_img[i].cols }, torch::kFloat); //1*1*32*32
//uchar转换为Tensor
torch::Tensor labels = torch::from_blob(&test_label[i], { 1 }, torch::kByte).toType(torch::kLong); //1
//使用训练好的模型对测试数据进行分类,也即前向传播过程
auto outputs = net1.forward(inputs);
//得到分类值,0 ~ 9
auto predicted = (torch::max)(outputs, 1);
//比较分类结果和对应的标签是否一致,如果一致则认为分类正确
if (labels[0].item<int>() == std::get<1>(predicted).item<int>())
passed_test_items++;
total_test_items++;
printf("label: %d.\n", labels[0].item<int>());
printf("predicted label: %d.\n", std::get<1>(predicted).item<int>());
}
printf("total_test_items=%d, passed_test_items=%d, pass rate=%f\n", total_test_items, passed_test_items, passed_test_items*1.0 / total_test_items);
}
(5) main函数
int main()
{
tran_lenet_5_cifar_10(); //训练
test_lenet_5_cifar_10(); //测试
return EXIT_SUCCESS;
}
5. 运行结果
运行上述代码,先训练模型、保存模型,然后再加载模型(实际使用时如果已经训练好模型,可直接加载模型而不需要再训练)。
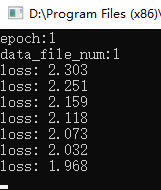
训练时目标函数(损失函数)的变化如下图所示,可以看到其值逐步减小:
待训练完成以及保存模型之后,就可以加载模型对数据进行分类预测啦,我们的分类结果如下图所示,准确率达到了60.3%,这个分类结果并不理想,这是因为LeNet-5网络还是相对简单了,对相对Minst更复杂的数据分类效果并不好。因此在接下来的文章中我们将使用libtorch来实现更加复杂的网络,敬请期待~

欢迎扫码关注以下微信公众号,接下来会不定时更新更加精彩的内容噢~
















 2483
2483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











