






2013 年,Mikolov 等人在 Google。 注意到一些值得注意的事情。
他们正在构建一个模型,将单词嵌入到向量空间中——这个问题从 20 世纪 80 年代开始就已经有很长的学术历史了。 他们的模型使用了一个优化目标,旨在将单词之间的相关关系转化为嵌入空间中的距离关系:一个向量与词汇表中的每个单词相关联,并且对向量进行优化,以便表示向量之间的点积(余弦接近度) 频繁共现的单词将更接近 1,而表示很少共现的向量之间的点积将更接近 0。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包
他们发现由此产生的嵌入空间不仅仅能够捕获语义相似性。 它具有某种形式的突发学习能力——它能够执行“文字算术”,这是它未经训练的能力。 空间中存在一个向量,可以将其添加到任何男性名词上,以获得一个接近其女性对应词的点。 如: V(king) - V(man) + V(woman) = V(queen)。 “性别向量”。 很酷! 似乎有几十个这样的神奇向量——一个复数向量,一个从野生动物名称到最接近的宠物名称的向量,等等。
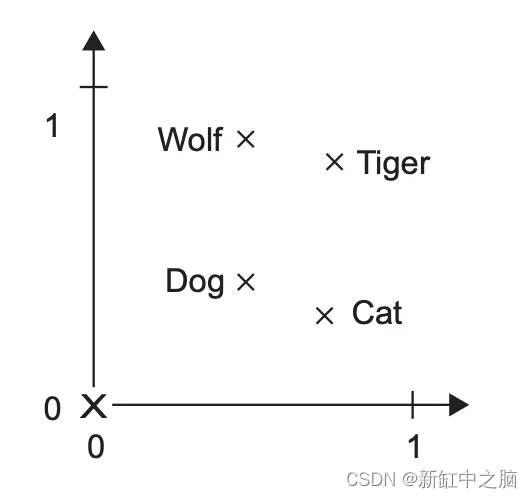
插图:一个 2D 嵌入空间,使得连接“狼”和“狗”的向量与连接“虎”和“猫”的向量相同。
1、Word2Vec 和LLM:赫布学习类比
快进十年——我们现在处于LLM时代。 从表面上看,现代LLM似乎与原始的 word2vec 模型相差无几。 它们能生成完美流利的语言——这是 word2vec 完全无法做到的——并且似乎对任何主题都很了解。 然而,它们实际上与古老的 word2vec 有很多共同点。
两者都是关于在向量空间中嵌入标记(单词或子单词)。 两者都依赖相同的基本原理来学习这个空间:一起出现的标记最终在嵌入空间中靠近在一起。 在这两种情况下,用于比较标记的距离函数是相同的:余弦距离。 甚至嵌入空间的维数也相似:约为 10e3 或 10e4。
你可能会问——等等,有人告诉我LLM是自回归模型,经过训练可以根据前一个单词序列预测下一个单词。 这与 word2vec 最大化共现标记之间点积的目标有何关系?
在实践中,LLM似乎确实在接近的位置对相关标记进行编码,因此必须存在联系。 答案是自注意力(self-attention)。
自注意力是 Transformer 架构中最重要的组成部分。 它是一种通过线性重新组合来自某些先前空间的令牌嵌入来学习新令牌嵌入空间的机制,加权组合对已经彼此“更接近”的令牌(即具有更高的点积)给予更大的重要性。 它将倾向于将已经接近的标记的向量聚集在一起——随着时间的推移,在一个空间中,标记相关关系转变为嵌入邻近关系(以余弦距离而言)。 Transformer 通过学习一系列逐步完善的嵌入空间来工作,每个嵌入空间都基于重新组合前一个嵌入空间的元素。
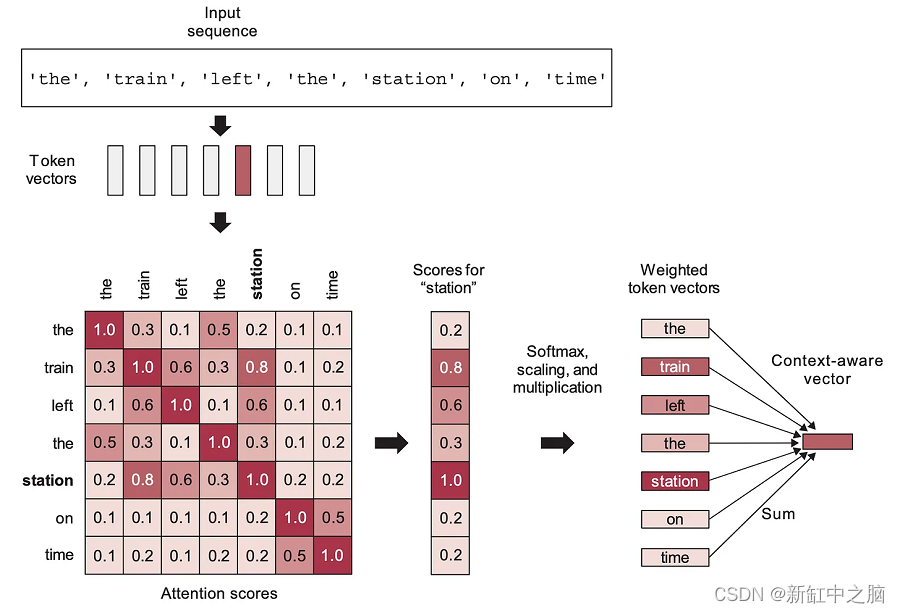
自注意力如何工作:这里计算“station”和序列中每个其他单词之间的注意力分数,然后使用它们对成为新“station”向量的单词向量之和进行加权。
自注意力赋予 Transformer 两个关键属性:
- 他们学习的嵌入空间在语义上是连续的,即在嵌入空间中移动一点只会稍微改变相应标记的面向人类的含义。 word2vec空间也验证了这个性质。
- 他们学习的嵌入空间在语义上是插值的,即在嵌入空间中的两点之间取中间点会产生一个代表相应标记之间“中间含义”的点。 这是因为每个新的嵌入空间都是通过在前一个空间的向量之间进行插值来构建的。
请注意,这与大脑的学习方式并不完全不同。 大脑中的关键学习原理是赫布学习——简而言之,“神经元一起放电,连接在一起”。 神经放电事件(可能代表动作或感知输入)之间的相关关系被转化为大脑网络中的邻近关系,就像transformer(和 word2vec)将相关关系转变为向量邻近关系一样。 两者都是信息空间的地图。
3、从涌现词算术到涌现向量程序
当然,word2vec 和 LLM 之间也存在显着差异。 Word2vec 并不是为生成文本采样而设计的。 LLM 更大,可以编码更复杂的转换。 事实是,word2vec 在很大程度上是一个玩具模型:它对于语言建模就像 MNIST 像素上的逻辑回归对于最先进的图像计算机视觉模型一样。 基本原理基本相同,但玩具模型缺乏任何有意义的表示能力。 Word2vec 甚至不是深度神经网络——它具有浅层、单层架构。 与此同时,LLM 具有任何人训练过的任何模型中最高的表示能力——它们具有数十个 Transformer 层,总共数百层,参数数量范围达到数十亿。
就像 word2vec 一样,LLM最终会学习有用的语义函数,作为将标记组织到向量空间的副产品。 但由于表示能力的增强和更精细的自回归优化目标,我们不再局限于“性别向量”或“复数向量”等线性变换。 LLM 可以存储任意复杂的向量函数——事实上,如此复杂,以至于将它们称为向量程序而不是函数会更准确。
Word2vec 使你能够执行基本操作,例如 plural(cat) → cats or male_to_female(king) → queen。 与此同时,LLM可以创造纯粹的魔法——比如 write_this_in_style_of_shakespeare("…your poem…") → "…new poem…"。 它们包含数百万个这样的程序。
4、LLM作为程序数据库
你可以将 LLM 视为类似于数据库:它存储信息,你可以通过提示检索这些信息。 但LLM和数据库之间有两个重要的区别。
第一个区别是LLM是一种连续的插值数据库。 你的数据不是存储为一组离散条目,而是存储为向量空间(一条曲线)。 你可以在曲线上移动(正如我们所讨论的,它在语义上是连续的)以探索附近的相关点。 你可以在不同数据点之间的曲线上进行插值以找到它们的中间值。 这意味着你可以从数据库中检索的内容比你输入的内容多得多 - 尽管并非所有内容都是准确的,甚至是有意义的。 插值可以导致泛化,但也可能导致幻觉。
第二个区别是LLM不仅仅包含数据。 它确实包含大量数据——事实、地点、人物、日期、事物、关系。 但它也是——或许主要是——一个程序数据库。
请注意,它们并不完全是你习惯处理的那种程序。 你可能会想到确定性的 Python 程序——一系列逐步处理数据的符号语句。 不是这个。 相反,这些向量程序是高度非线性的函数,将潜在嵌入空间映射到自身。 类似于 word2vec 的魔法向量,但要复杂得多。
5、作为程序查询的提示
要从LLM那里获取信息,你必须提示它。 如果LLM就像一个包含数百万个矢量程序的数据库,那么提示就像该数据库中的搜索查询。 提示的一部分可以解释为“程序键”,即您要检索的程序的索引,部分可以解释为程序输入。
考虑以下示例提示: “rewrite the following poem in the style of Shakespeare: …my poem…”

“rewrite this in the style of”是程序的关键。 它指向程序空间中的特定位置。“Shakespeare”和“..my poem…”是程序输入。- LLM 的输出是程序执行的结果。
现在,请记住,LLM 作为程序数据库的类比只是一个心理模型 - 你还可以使用其他模型。 一种更常见但不太具有启发性的方法是将LLM视为自回归文本生成器,它输出最有可能遵循给定训练数据分布的提示的单词序列之一,即专注于LLM优化的任务。 如果你牢记多种方法来模拟LLM的工作,你就会更好地理解LLM——希望你会发现这个新方法很有用。
6、提示工程作为程序搜索过程
请记住,这个“程序数据库”是连续的和插值的——它不是一组离散的程序。 这意味着稍微不同的提示,例如“以 x 的风格抒情地重新表述此文本”仍然会指向程序空间中非常相似的位置,从而导致程序的行为非常接近但不完全相同。
你可以使用数千种变体,每种变体都会产生相似但略有不同的程序。 这就是为什么需要提示的工程设计。 没有先验的理由说明为什么你的第一个简单的程序密钥会产生该任务的最佳程序。 LLM不会“理解”你的意思,然后以最好的方式执行它——它只是在你可能到达的许多可能的位置中获取你的提示指向的程序。
提示工程是搜索程序空间以找到根据经验似乎在目标任务上表现最佳的程序的过程。 这与在 Google 搜索某个软件时尝试不同的关键字没有什么不同。
如果LLM实际上理解了你告诉他们的内容,则不需要此搜索过程,因为无论你的提示使用““rewrite”一词而不是“rephrase”,,还是你使用前缀,所传达的有关目标任务的信息量都不会改变你的提示是“一步一步思考”。 永远不要假设LLM第一次就“明白了”——请记住,你的提示只是无限程序海洋中的一个地址,所有这些都是通过自回归优化目标将标记组织到向量空间中的副产品。
一如既往,理解LLM最重要的原则是你应该抵制将其拟人化的诱惑。
原文链接:我理解的LLM提示工程 - BimAnt














 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









