






图像着色(image colorization)的目标是建立一个能够将逼真的颜色应用于黑色和灰色图像的模型。在本文中,我将指导你使用六种不同的神经网络为图像着色的生成模型的过程。
整个模型是用 PyTorch 构建的,图像预处理是借助 Scikit-Image 库进行的。所有代码都可以在这里找到。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、数据和预处理
在进行实际实施之前,我们需要一个包含彩色图像的相当大的数据集。请记住,我们的方法不需要相应的黑白图像,因为正如我们在第一篇文章中提到的那样,我们将使用 LAB 格式,这意味着我们可以分解训练集的图像并获取每个图像的黑白版本。我选择的数据集是图像着色数据集,其中包含 5,000 张用于训练的彩色图像和 739 张用于测试的图像。每张图像的尺寸为 400x400x3。它们的内容从食物、人物、动物、车辆的图像到外部和内部场所的图像不等。
唯一进行的预处理是将 RGB 转换为 LAB 格式。为此,我使用了 Scikit-Image 库和 PyTorch 提供的“Dataset”类来创建读取和加载图像的机制。有关更多详细信息,请查看“Dataset.py”文件。
2、架构和配置
关于神经网络的架构,我们已经提到我们将尝试实现一个自动编码器,其中编码器将由卷积层组成,解码器将包含转置卷积层。输入将是具有 1 个通道(L 值(亮度))的 400x400 图像。在输出中,我们将获得具有 2 个通道(a 和 b 值)的 400x400 图像。最终的彩色图像将通过将预测的 a 和 b 与输入 L 相结合来构建。
网络的架构是逐步构建的,从只有几层和参数的网络到具有更复杂信息流方法的多层网络。基本上,我遵循了奥卡姆剃刀原则,即逐步构建更复杂的解决方案,我试图将任务的实际复杂性反映到模型的复杂性中。
我们还没有讨论的一件事是层之间的批标准化。我保证会写一篇关于批标准化的文章,但现在你可以将批标准化视为一个巧妙的技巧,它允许我们在处理好权重值的同时加快训练过程。
批标准化远不止于此。我将在下一篇文章中解释一切。
作为激活函数,我使用了 ReLU,因为它是最安全的选项之一。批量大小设置为 32,这意味着使用包含 32 张图像的批量来训练网络。预测损失由均方误差 (MSE) 计算,而在实验中,网络使用了 Adam 优化器。
总的来说,我尝试了 6 个不同的网络。在后续部分中,我将提供所有网络的设置和结果。每个网络都在 200 张图像的开发集上进行了大约 200 个时期的训练。开发集用于在将整个数据集提供给模型之前测试和比较不同的架构,并且可以节省大量时间。
2.1 第一种架构
第一种也是最基本的架构如下图所示。我们用三种不同的学习率进行了 3 次独立实验,但它们的表现几乎相同。此外,它们甚至无法学习训练实例,这对于学习能力来说是一个危险信号。
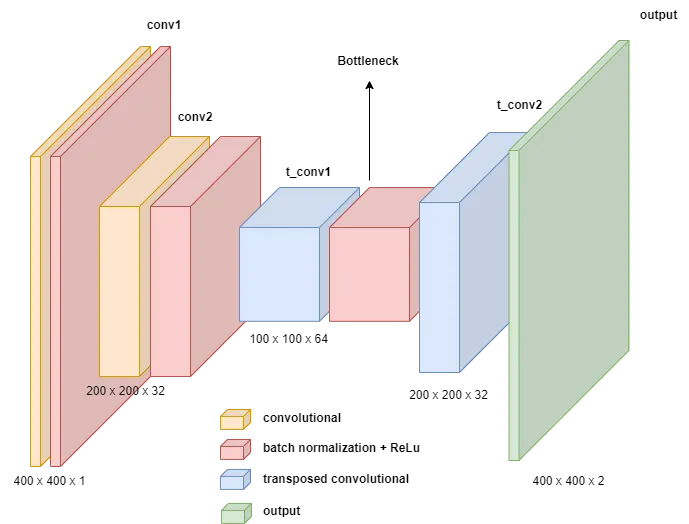
第一种架构

第一种架构的配置
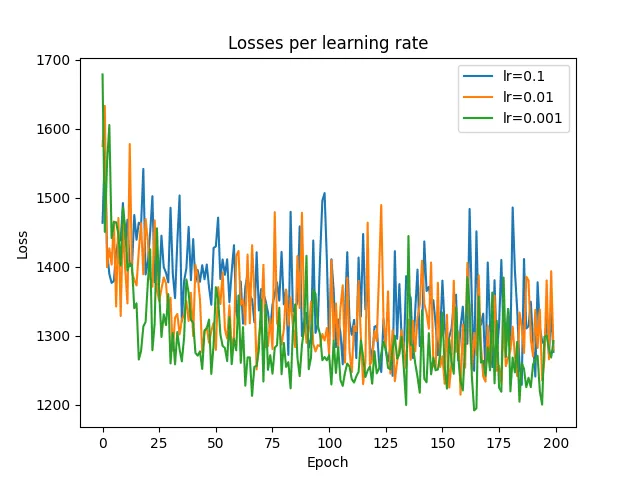
第一种架构的损失
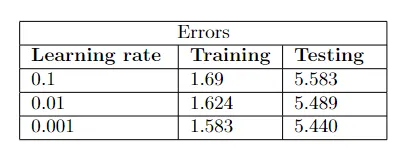
第一种架构的错误

第一种架构的结果(左:训练集,右:测试集)。图片下方的数字表示 MSE
2.2 第二种架构
第二种架构本质上是对前一种架构的增强,我在编码器和解码器中分别添加了 1 个卷积层和 1 个转置卷积层。在这种情况下,与第一种情况相比,损失有所减少,而学习率为 0.001 的实验显示出更好的结果。尽管网络确实尝试在某些地方添加一些颜色,但它仍然无法为图像着色。

第二种架构
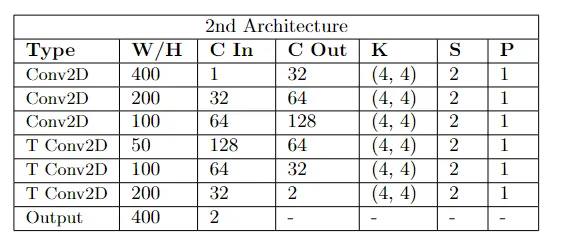
第二种架构的配置
 第二种架构的损失
第二种架构的损失
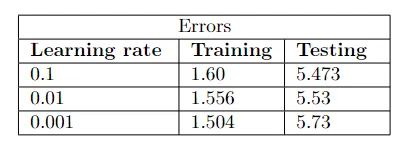
第二种架构的错误

第二架构的结果(左:训练集,右:测试集)
2.3 第三种架构
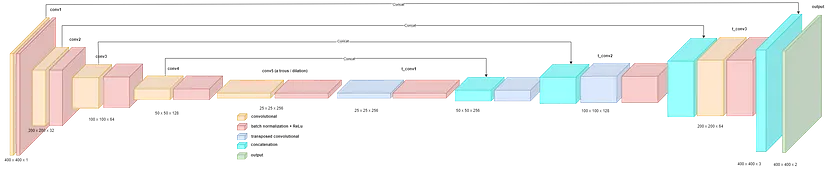
第三种架构不仅仅是一种增强,而是一种整体修改。我已经调整了网络以实现所谓的 U-Net [1]。U-Net 布局使用先前计算的编码器输出作为解码器后续部分的输入。通过这种方式,我们确保网络不会丢失任何重要信息。U-Net 的确切结构如下所示:
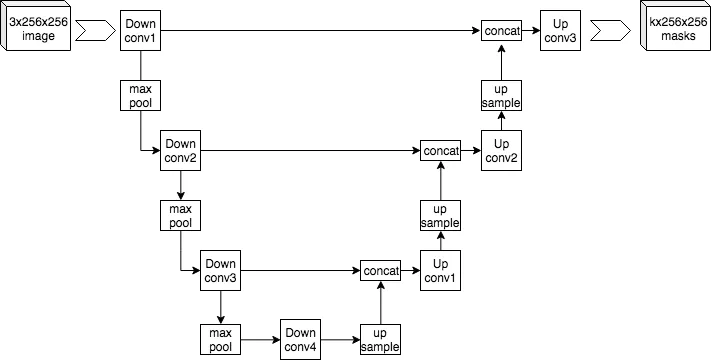
U-Net 布局
通过这种方法,网络收敛速度更快,训练集和测试集上的错误率也更低。此外,这是第一个能够一致应用特定颜色的网络。
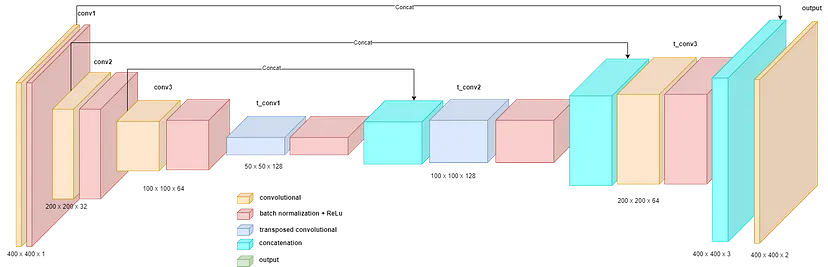
第三种架构

第三种架构的配置
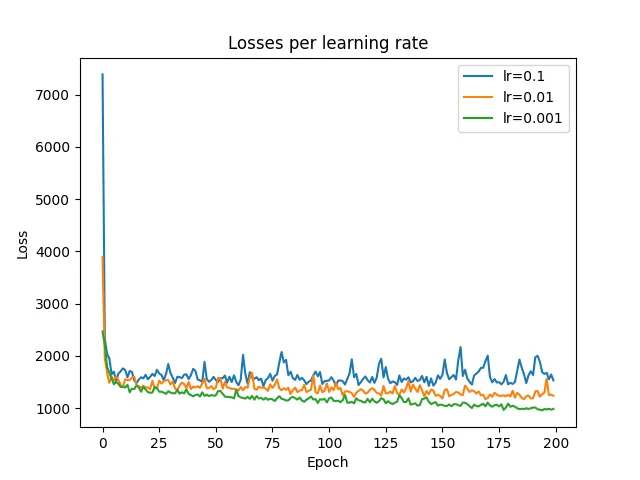
第三种架构的损失

第三种架构的错误

第三种架构的结果(左:训练集,右:测试集)
2.4 第四种架构
此架构基于前一种架构,并在编码器和解码器上添加了一个额外层。最终结果显示训练集中的损失进一步减少,并且输出包含更多彩色区域。请注意,测试损失已经增加。这意味着我们的模型在训练集上过度拟合,但这在目前不是问题,因为构建模型的第一步是确保它能够学习。这是通过让模型过度拟合到一定程度来实现的,然后通过增加训练集,过度拟合问题通常会消失。

第四种架构
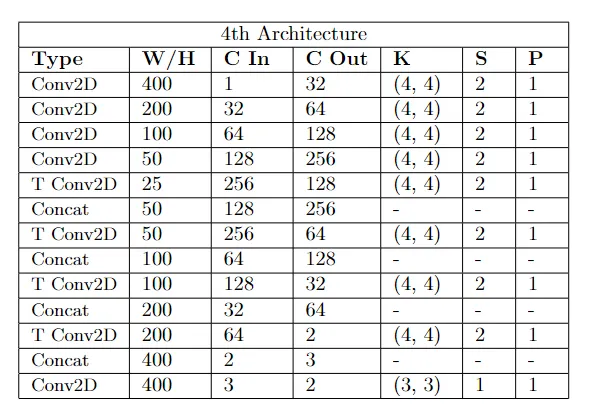
第四种架构的配置

第四种架构的损失

第四种架构的错误

第四种架构的结果(左:训练集,右:测试集)
2.5 第五种架构
在此阶段,我选择通过引入扩张层(也称为“a trous”层)来修改网络布局。有研究表明,对于像我们这样的案例,预测效果有显著改善 [2]。同样,损失进一步减少,模型能够更精确地为图像着色。
第五种架构
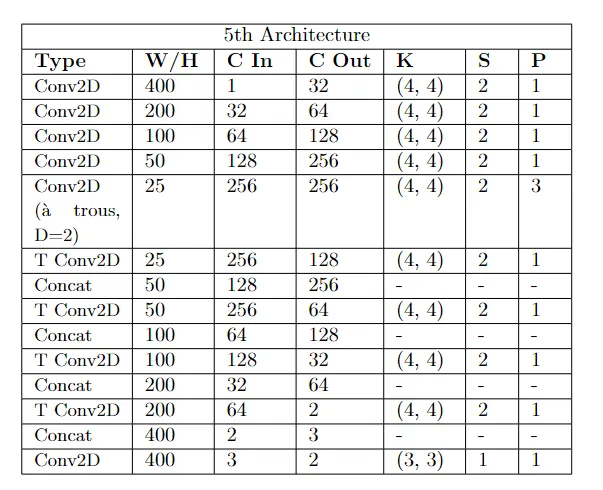
第五种架构的配置
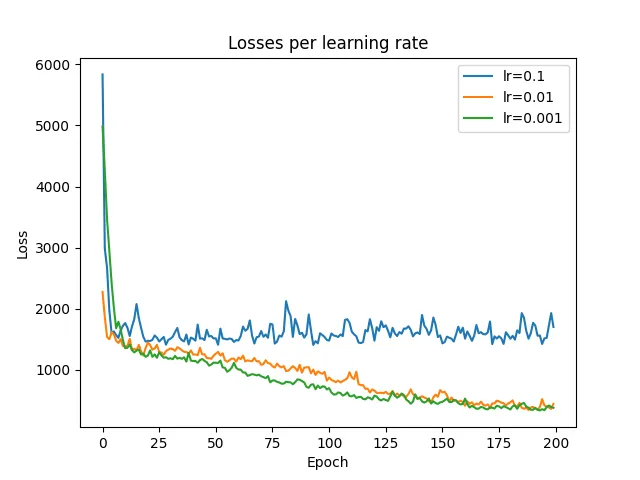
第五种架构的损失

第五种架构的错误

第 5 种架构的结果(左:训练集,右:测试集)
2.6 第六种架构
最后一种架构是第五种情况的增强版本,我在其中添加了 2 个额外层。结果与之前的版本没有太大差别,这使得该架构成为一个很好的停止点。公平地说,在某些方面,架构 5 比 6 更好,但由于后者表现出较低的过度拟合,我选择它作为最终模型。

第六种架构
 第六种架构的 配置
第六种架构的 配置
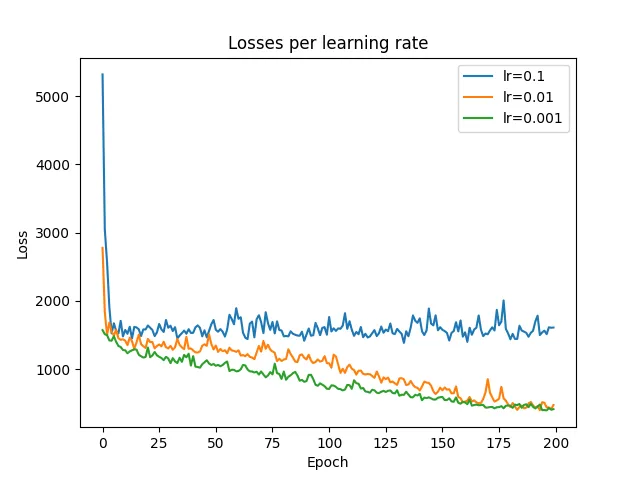
第六种架构的损失
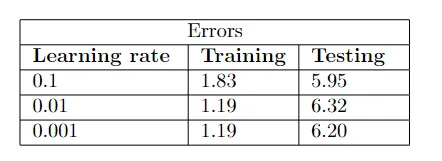
第六种架构的错误

第 6 种架构的结果(左:训练集,右:测试集)
三、最终结果
在 Google Colab Pro GPU 上,对第 6 架构开发集的训练持续了大约 40 分钟,在 i5–4690K@3.9GHz CPU 上持续了大约 2.5 小时。由于时间限制和 GPU 可用性,我只能使用 CPU 进行训练。这就是为什么最终架构是在 2,000 张图像上进行训练而不是在整个数据集上进行训练的原因。因此,我以 0.001 的学习率对模型进行了 300 次训练,持续了 3 天。最终结果令人鼓舞,因为该模型不仅能够为训练期间遇到的图像着色,还能为以前从未见过的图像着色!
训练集:

训练数据 I 的最终结果

训练数据 II 的最终结果
测试集:

测试数据 I 的最终结果
 测试数据 II 的最终结果
测试数据 II 的最终结果
至此,关于使用神经网络解决图像着色问题的整个系列就结束了。我真的希望你在这个过程中学到了很多东西,同时也玩得很开心。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









