






 本文详细介绍了姿态估计在计算机视觉中的重要性,包括其应用领域、基本概念、2D/3D区别,以及OpenPose、MoveNet、PoseNet等九种流行模型的原理和特点。这些模型推动了运动分析、医疗康复等领域的进步。
本文详细介绍了姿态估计在计算机视觉中的重要性,包括其应用领域、基本概念、2D/3D区别,以及OpenPose、MoveNet、PoseNet等九种流行模型的原理和特点。这些模型推动了运动分析、医疗康复等领域的进步。
“姿态估计?”……“姿态”一词对于不同的人来说可能有不同的含义,但我们不是在讨论阿诺德经典、奥林匹亚或选美表演。 那么,姿态估计到底是什么? 那么,让我们深入探讨这个话题。

推荐:用 NSDT编辑器 快速搭建可编程3D场景
姿态估计(Pose Estimation)在计算机视觉领域引起了极大的关注。 人们越来越感兴趣的是使用计算机视觉技术来实时识别和跟踪人或物体的运动的能力,这为跨行业提供了很多用处。 在先进技术不断发展的时代,姿势估计可以成为运动生物力学、动画、游戏、机器人、医疗康复和监视领域的有效工具。
本质上,姿态估计根据图像或视频中人的身体部位和关节位置来预测不同的姿势。 例如,我们可以在深蹲时自动检测关节、手臂、臀部和脊柱的位置。 现在,我们中的一些人可能想知道它有什么用处? 然而,考虑一下运动员受伤后康复或接受力量训练的例子; 姿态估计可以帮助运动分析师分析从深蹲的起始位置到结束位置的关键点。 因此,这些分析师可以纠正姿势并帮助防止训练损伤(图 1)。
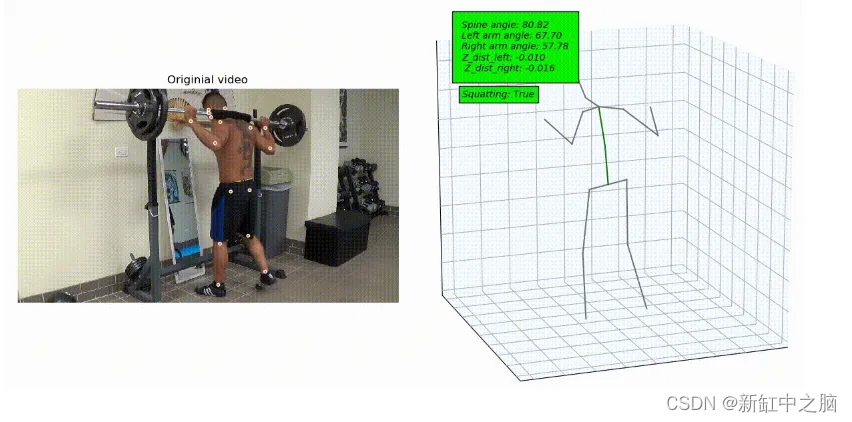
图 1:蹲下时的人体姿势估计
1、姿态估计的要点
用于从图像和视频中检测人物或物体的姿势估计。 然而,我们应该意识到姿势估计有不同的类别。
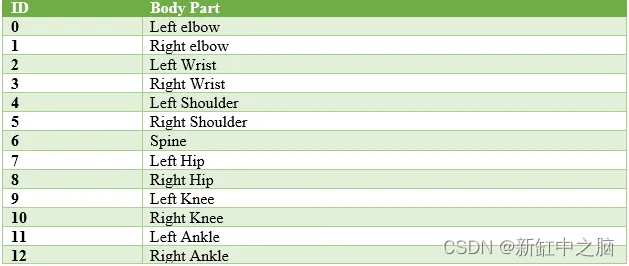
当研究对象是人类时,姿态分析是通过确定各种身体关节来执行的。 例如,可以通过某人的肘部位置或膝关节位置来确定。 这种形式的姿态检测属于人体姿态估计的范畴。 姿态估计模型以经过良好处理的图像或视频作为输入。 该模型根据输入图像中的信息提供有关不同关键点的输出。 一般来说,关键点配有 ID 和置信度分数,确定关键点存在于给定输入的特定位置的概率。 现在,如果我们回想起运动员之前进行深蹲的图像,我们可以分配各种 ID,例如:
相反,与人类主体不同,可以对主要是刚性的物体进行姿态估计; 因此,它们属于刚性姿态估计的范畴。
2、姿态估计:2D 还是3D?
姿态估计可以通过两种方式进行,即 2D 和 3D。 也许,我们中的一些人将 2D 和 3D 这些概念与动画领域联系起来。 然而,姿态估计的 2D 方面与基于像素值从图像中预测关键点相关。 因此,大多数二维人体姿态估计技术都实现特征提取方法来提供人体的适当关键点。
类似地,3D 姿态估计与从图像和视频中预测特定人或物体的空间位置相关。 随着深度学习的出现,这些模型的性能得到了显着提高,但它们的使用更加复杂,因为数据集需要根据人体的适当 3D 结构信息(包括背景和照明条件)进行整理。 此外,还有分别与检测一个人或物体或跟踪多个人和物体相关的单姿势和多姿势估计的新方法。
3、姿势估计模型
不同的研究人员提出了不同的姿态估计模型。 在我们深入研究之前,有必要了解人体姿势估计模型基本上分为三种类型:
- 运动学模型
- 平面模型
- 体块模型
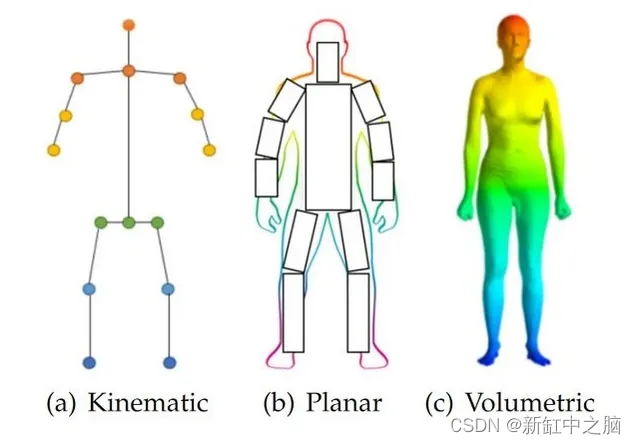
运动学模型可用于 2D 和 3D 位姿估计。 本质上,该模型侧重于不同的关节和肢体位置,以提供人体的结构信息。 因此,此类模型可以有效识别人体部位之间的各种关系。 然而,运动学模型在表示基于纹理或形状的信息时几乎没有限制。
接下来,我们讨论强调 2D 位姿估计的平面模型。 理想情况下,人体部位用矩形表示以提供近似的身体轮廓。
最后,体积姿态估计模型侧重于 3D 姿态估计。 这些是端到端深度学习模型,使用复杂的数据集进行训练,其中包括全身扫描的高分辨率数据,以得出各种形状和姿势的人体网格。
尽管不可能涵盖广泛的模型,但我们将讨论近年来用不同方法提出的一些最可靠和鲁棒的模型。
让我们看看9个最流行的姿势估计模型。
3.1 OpenPose
OpenPose 是卡内基梅隆大学开发的第一个实时估计模型。 该模型主要针对实时场景下多人的手部、面部、足部等人体关键点进行检测。 一般来说,图像在卷积神经网络(CNN)的帮助下进行处理,以生成特定输入的特征图。 此外,特征图通过 CNN 管线的不同阶段进行处理,以获得置信度图和亲和力场。

图 3:OpenPose 测试结果
如需更多信息,你可以在其 GitHub 存储库上找到更多信息。
3.2 MoveNet
MoveNet 是由 Google 研究人员使用 TensorFlow.js 开发的。 研究人员声称该模型超快且高度准确,能够检测人体的 17 个关键点。

图 4:MoveNet 姿态检测
MoveNet有两个版本:Lighting版本针对低延迟要求的应用程序,而Thunder版本是为专注于实现更高准确度的应用程序而设计的。 此外,这两种模型都能够进行实时检测,并已被证明可有效检测实时健身、运动或基于医疗保健的应用。
3.3 PoseNet
PoseNet 是另一种流行的姿势检测模型。 该模型可以实时检测姿势,并且可以有效地进行人体的单姿势和多姿势检测。
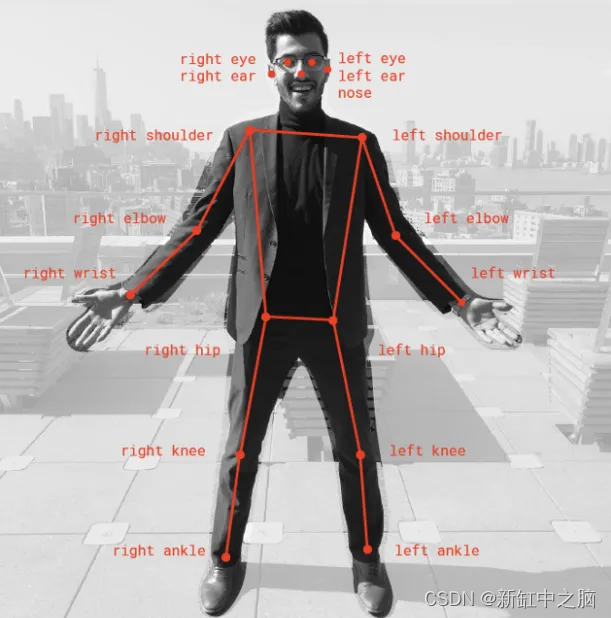
图4:PoseNet-17关键点
PoseNet 是一种深度学习模型,它使用 TensorFlow 来检测不同的身体部位,并通过加入其他关键点来提供全面的骨骼信息。 此外,PoseNet还为人体从眼睛到脚踝的各个部位提供了17个关键点。 生成置信度分数以确定模型从图像中识别特定关键点的准确程度,从而确定模型的准确性。 有关测试和配置的所有信息都可以通过 GitHub 访问。
3.4 DC姿势
DCPose 代表深度双连续网络(Deep Dual Consecutive Network),旨在从多个帧中检测人体姿势。

图5:DCPose姿态估计结果
DCPose框架利用深度学习技术来克服多帧人体姿势估计中的关键挑战,例如运动模糊、视频散焦以及由于依赖每个视频帧而发生的遮挡。 此外,在这些视频帧之间提供各种时间参考,以促进准确的关键点检测。 此外,时间合并器充当编码器以实现更广泛的搜索范围,而残差融合模块负责计算不同方向上的残差。
3.5 DensePose
DensePose 是一种人体姿势估计器,旨在从有关人体 3D 表面的 RGB 图像中映射各种基于人体的像素。

图 6:DensePose根据 RGB 图像进行姿势估计
DensePose可以针对单姿势和多姿势估计需求来实现。 DensePose 使用包含图像到表面标注信息的大规模数据集形式的地面实况。 此外,还提出了一种循环神经网络(RCNN),能够以每秒多帧的速度回归每个人类受试者之间与不同身体部位相关的 UV 坐标。
3.6 HighHRNet
HighHRNet 是一种流行的自下而上姿势估计模型,旨在解决由于尺度差异而预测矮个子正确姿势时的一些挑战。
特征金字塔是HighHRNet不可或缺的组成部分,允许所提出的方法从尺度感知表示中学习,帮助估计精确的关键点,以确定矮个子的姿势估计的变化。 特征金字塔主要包括HRNet模型生成的特征图输出,包括转置卷积生成的高分辨率输出。
此外,作者还透露,对于中等身材的人来说,该模型的 AP 性能比一些现有的自下而上的方法高出 2.5%。 此外,该模型在估计拥挤场景中的姿势时也能有效地执行。
3.7 Lightweight OpenPose
Lightweight OpenPose 是 OpenPose 的优化版本,专注于实时推理,而不会在模型的准确性方面下降太多。 该模型可以通过不同的关键点检测图像中每个人的人体姿势。 作者声称该模型在不涉及任何后处理的情况下实现了 40% 的单尺度推理 AP。

图 7:Lightweight OpenPose 结果
3.8 AlphaPose
AlphaPose 是一个令人兴奋的姿势估计产品。 无论你是尝试检测购物街中的多个人、快闪族还是街头表演者,现在都可以借助此模型实现。

图 8:AlphaPose 跟踪结果
此外,AlphaPose 估计器是第一个在 COCO 数据集和 MPII 数据集上分别实现超过 70 mAP 和 80 mAP 的开源产品。 理想情况下,该模型可以匹配不同帧中人的姿势,并且非常有能力作为在线姿态跟踪器表现良好。
3.9 TransPose
TransPose 是一种姿态估计模型,它实现了基于 CNN 的特征提取方法、Transformer编码器和预测功能。

图 9:TransPose 估计结果
Transpose具有Transfermer等内置功能,可以从不同关键点之间的远程空间关系中捕获信息。 最终输出提供了有关预测关键点位置及其依赖的各种依赖关系的关键信息。 此外,该模型在 COCO 数据集上产生了 75.8AP 的优异结果,并根据 MPII 基准通过适当的传输实现了卓越的性能。
4、结束语
姿态检测是计算机视觉领域不断发展的研究领域。 从提供现实生活中的应用程序到在云中服务器上运行的应用程序,姿态估计在业界获得了极大的关注。 事实上,先进的姿态估计模型更快、更小,可以在移动设备上发挥作用,这提供了充足的机会。
这些模型对于实时体育分析师来说是有效的,对于医疗康复、私人教练和现实游戏来说甚至是可靠的。 尽管已经开发了各种应用程序,但每个新模型都旨在改进以前模型的一些局限性。 然而,随着深度学习和多种开源技术的出现,各种产品都可以改变未来人体姿势估计的执行方式。 因此,令人兴奋的前景已经打开,使得跨行业有效实施最先进的姿势检测应用成为可能。

















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









