







1.背景及其回顾
在之前的博客基于强化学习的空域作战辅助决策(1D)中尝试用PPO求解离散动作空间 A = { − 1 , 0 , 1 } × { − 1 , 0 , 1 } A = \{-1,0,1\} \times \{-1,0,1\} A={−1,0,1}×{−1,0,1}下的最优策略,若此时将动作空间拓宽至连续空间 A = [ a m i n ( F ) , a m a x ( F ) ] × [ a m i n ( J ) , a m a x ( J ) ] A = [a_{min}^{(F)},a_{max}^{(F)}]\times [a_{min}^{(J)},a_{max}^{(J)}] A=[amin(F),amax(F)]×[amin(J),amax(J)]下,此时就不得不用DDPG算法来求解相应的模型,得到最终的确定性网络 a = μ ( s ) a=\mu(s) a=μ(s)。
2.新模型环境的搭建
需要提前导入的库为:
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
状态空间将变成4维度:
s
t
=
(
x
F
(
t
)
,
v
F
(
t
)
,
x
J
(
t
)
,
v
J
(
t
)
)
T
s_t = (x_F^{(t)},v_F^{(t)},x_J^{(t)},v_J^{(t)})^T
st=(xF(t),vF(t),xJ(t),vJ(t))T。其状态转移方程为:
x
F
(
t
+
1
)
=
x
F
(
t
)
+
v
F
(
t
)
Δ
t
+
1
2
a
F
(
t
)
Δ
t
2
v
F
(
t
+
1
)
=
v
F
(
t
)
+
a
F
(
t
)
Δ
t
x
J
(
t
+
1
)
=
x
J
(
t
)
+
v
J
(
t
)
Δ
t
+
1
2
a
J
(
t
)
Δ
t
2
v
J
(
t
+
1
)
=
v
J
(
t
)
+
a
J
(
t
)
Δ
t
x_F^{(t+1)}=x^{(t)}_F+v_F^{(t)}\Delta t + \frac{1}{2}a_F^{(t)}\Delta t^2\\v_F^{(t+1)}=v_F^{(t)}+a_F^{(t)}\Delta t\\ x_J^{(t+1)}=x^{(t)}_J+v_J^{(t)}\Delta t + \frac{1}{2}a_J^{(t)}\Delta t^2\\v_J^{(t+1)}=v_J^{(t)}+a_J^{(t)}\Delta t
xF(t+1)=xF(t)+vF(t)Δt+21aF(t)Δt2vF(t+1)=vF(t)+aF(t)ΔtxJ(t+1)=xJ(t)+vJ(t)Δt+21aJ(t)Δt2vJ(t+1)=vJ(t)+aJ(t)Δt奖励函数不变。
代码基本与之前相同:
# 下面搭建连续行为空间的环境对象
class SAMenv(object):
def __init__(self,L=100,Delta_t=10/3600,t0=15,tJ=3,v_F=740.0/3600,v_J=740.0/3600,a_Fmax=36*360,a_Jmax=36*360,R_F=40,R_J=30,R_SAM=40,P_disable=0.5):
self.L = L
self.Delta_t = Delta_t
self.tJ = tJ
self.v_F = v_F
self.v_J = v_J
self.R_F = R_F
self.R_J = R_J
self.a_Fmax = a_Fmax
self.a_Jmax = a_Jmax
self.R_SAM = R_SAM
self.t0 = t0
self.P_disable = P_disable
self.Jammer_time = 0
self.Fighter_time = 0
self.SAM_disable = 0
self.observation_space_num = 4
self.action_space_num = 2
self.Jammer_wait_time = 0 # 与tJ对应,干扰机的发射时间
self.state = np.array([0,0,np.random.random()*L,0])
def reset(self):
self.state = np.array([0,0,np.random.random()*self.L,0])
self.SAM_disable = 0
self.Jammer_time = 0
self.Fighter_time = 0
self.Jammer_wait_time = 0
return self.state
def step(self,action):
# action;0-8的二维化,类型为int
a_F = action[0]
a_J = action[1]
# 战斗机与干扰机的加速度有范围
if a_F >= self.a_Fmax:
a_F = self.a_Fmax
elif a_F <= -self.a_Fmax:
a_F = -self.a_Fmax
if a_J >= self.a_Jmax:
a_J = self.a_Jmax
elif a_J <= -self.a_Jmax:
a_J = -self.a_Jmax
# 储存当前动作
self.a_F = a_F
self.a_J = a_J
# 当前的状态变量
x_F = self.state[0]
v_F = self.state[1]
x_J = self.state[2]
v_J = self.state[3]
# 下一个时刻的状态变量
x_F_ = x_F + v_F*self.Delta_t + 0.5*a_F*(self.Delta_t)**2
v_F_ = v_F + a_F*self.Delta_t
x_J_ = x_J + v_J*self.Delta_t + 0.5*a_J*(self.Delta_t)**2
v_J_ = v_J + a_J*self.Delta_t
# 限制战斗机在一定区域内飞行
if x_F_ >= self.L:
x_F_ = self.L
if x_F_ <= 0:
x_F_ = 0
# 限制干扰机在一定区域内飞行
if x_J_ >= self.L:
x_J_ = self.L
if x_J_ <=0:
x_J_ = 0
# 对下个状态进行赋值
self.state = np.array([x_F_,v_F_,x_J_,v_J_])
# 当前的战斗机与干扰机与SAM的距离
d_F_ = self.L - x_F_
d_J_ = self.L - x_J_
# 如果干扰机与战斗机均在SAM射程之外,则返回-1
if d_J_ >= self.R_SAM and d_F_ >= self.R_SAM:
return self.state,-1,False
# 如果干扰机/战斗机持续在射程内则更新瞄准时间
if d_J_ <= self.R_SAM and self.Jammer_time < self.t0:
self.Jammer_time += self.Delta_t
if d_F_ <= self.R_SAM and self.Fighter_time < self.t0:
self.Fighter_time += self.Delta_t
# 如果干扰机/战斗机超过射程则重新记录时间
if d_J_ > self.R_SAM:
self.Jammer_time = 0
if d_J_ > self.R_J:
self.Jammer_time = 0
if d_F_ > self.R_SAM:
self.Fighter_time = 0
if d_J_ <= self.R_J:
self.Jammer_wait_time += self.Delta_t
# 若干扰机的干扰对SAM系统起了作用
if self.Jammer_wait_time >= self.tJ:
self.SAM_disable = 1
# 如果SAM系统能正常工作
if self.SAM_disable == 0:
# 瞄准时间已到
if d_J_ <= self.R_SAM and self.Jammer_time >= self.t0:
self.Jammer_time = 0 #击毁之后重新记录时间
self.Jammer_wait_time = 0
return self.state,-100,True
if d_F_ <= self.R_SAM and self.Fighter_time >= self.t0:
self.Fighter_time = 0
return self.state,-100,True
# 如果SAM系统被麻痹
if self.SAM_disable == 1:
#将依照一定的概率执行瞄准与击毁操作
if np.random.random() >= (1 - self.P_disable):
if d_J_ <= self.R_SAM and self.Jammer_time >= self.t0:
self.Jammer_time = 0 #击毁之后重新记录时间
self.Jammer_wait_time = 0
return self.state,-100,True
if d_F_ <= self.R_SAM and self.Fighter_time >= self.t0:
self.Fighter_time = 0
return self.state,-100,True
# 如果SAM系统在战斗机射程以内且战斗机未被击落,战斗机将对SAM系统产生致命打击
if d_F_ <= self.R_F:
return self.state,1000,True
# 如果以上情况都没执行,则正常返回
return self.state,-1,False
下面是测试代码:
env = SAMenv()
state = env.reset()
print("当前状态时是:",state)
next_state,r,_ = env.step(np.array([1000,1000]))
print("接下来状态是:",next_state)
print("奖励是:",r)
下面是结果:

3.DDPG算法实现
下面需要先定义参数初始化函数以及参数更新函数:
# 下面定义一种初始化网络参数的范围
def param_init(size,fanin=None):
fanin = fanin or size[0]
v = 1./np.sqrt(fanin)
x = torch.Tensor(size).uniform_(-v,v)
return x.type(torch.FloatTensor)
# 网络的参数更新函数
def soft_update(target,source,tau):
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.data.copy_(
target_param.data*(1.0-tau) + param.data*tau
)
def hard_update(target,source):
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.data.copy_(param.data)
再定义确定性评委网络:
class Actor(nn.Module):
def __init__(self,num_states,num_actions,action_limits=1):
super(Actor,self).__init__()
self.action_limits = action_limits
self.fc1 = nn.Linear(num_states,256)
self.fc1.weight.data = param_init(self.fc1.weight.size())
self.fc2 = nn.Linear(256,128)
self.fc2.weight.data = param_init(self.fc2.weight.size())
self.fc3 = nn.Linear(128,64)
self.fc3.weight.data = param_init(self.fc3.weight.size())
self.fc4 = nn.Linear(64,num_actions)
self.fc4.weight.data.uniform_(-0.003,0.003)
def forward(self,state):
state = torch.from_numpy(state).float()
x = F.relu(self.fc1(state))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
action = torch.tanh(self.fc4(x))*self.action_limits
return action
以及评委网络:
class Critic(nn.Module):
def __init__(self,num_states,num_actions,num_hiddens=256,lr=1e-2):
super(Critic,self).__init__()
# Q(s,a)
self.fcs1 = nn.Linear(num_states,num_hiddens)
self.fcs1.weight.data = param_init(self.fcs1.weight.size())
self.fcs2 = nn.Linear(num_hiddens,num_hiddens)
self.fcs2.weight.data = param_init(self.fcs2.weight.size())
# v(s)
self.fca1 = nn.Linear(num_actions,num_hiddens)
self.fca1.weight.data = param_init(self.fca1.weight.size())
# 全连接层
self.fc = nn.Linear(num_hiddens+num_hiddens,1)
self.fc.weight.data = param_init(self.fc.weight.size())
# 前馈
def forward(self,state,action):
# 输入为numpy
# 输出为Q(s,a)
state = torch.from_numpy(state).float()
action = torch.FloatTensor(action)
s1 = F.relu(self.fcs1(state))
s2 = F.relu(self.fcs2(s1))
a1 = F.relu(self.fca1(action))
x = torch.cat((s2,a1),dim=1)
x = self.fc(x)
return x
以及经验回放缓冲区(ReplayBuffer):
# 下面定义一个经验数组的类
from collections import deque
class Memory:
def __init__(self,capacity=20000):
self.capacity = capacity
self.memory_state = deque(maxlen=capacity)
self.memory_action = deque(maxlen=capacity)
self.memory_reward = deque(maxlen=capacity)
self.memory_next_state = deque(maxlen=capacity)
self.memory_done = deque(maxlen=capacity)
# 下面是往内存中填数据
def push(self,s,a,r,s_,done):
# 输入均为numpy类型数据
self.memory_state.append(s)
self.memory_action.append(a)
self.memory_reward.append(r)
self.memory_next_state.append(s_)
self.memory_done.append(done)
# 下面是往内存中抽出数据
def sample(self,batchsize=32):
sample_s,sample_a,sample_r,sample_s_,sample_done = [],[],[],[],[]
num_memory = len(self.memory_state)
for i in range(batchsize):
index = np.random.randint(low=0,high=num_memory)
sample_s.append(self.memory_state[index])
sample_a.append(self.memory_action[index])
sample_r.append(self.memory_reward[index])
sample_s_.append(self.memory_next_state[index])
sample_done.append(self.memory_done[index])
return sample_s,sample_a,sample_r,sample_s_,sample_done
# 清空数据
def cleanall(self):
clean(self.memory_state)
clean(self.memory_action)
clean(self.memory_reward)
clean(self.memory_next_state)
clean(self.memory_done)
再定义噪声的添加类:
# Ornstein-Uhlenbeck噪声模型
class OrnsteinUhlenbeckActionNoise:
def __init__(self,actions_num,mu=0,theta=0.15,sigma=0.2):
self.actions_num = actions_num
self.mu = mu
self.theta = theta
self.sigma = sigma
self.X = np.ones(self.actions_num)*self.mu
def reset(self):
self.X = np.ones(self.actions_num)*self.mu
def sample(self):
dx = self.theta*(self.mu - self.X)
dx = dx + self.sigma*np.random.randn(len(self.X))
self.X = self.X + dx
return self.X
下面是主要的DDPG实现类:
class DDPGagent:
def __init__(self,capacity=2e6,
batch_size=120,
states_num=4,
actions_num=1,
action_limit=3,
tau=0.2,
learning_rate=0.001,
gamma=0.9):
self.states_num = states_num
self.actions_num = actions_num
self.action_limit = action_limit
self.batch_size = batch_size
self.learning_rate = learning_rate
self.gamma = gamma
self.tau = tau
self.total_trans = 0
self.noise = OrnsteinUhlenbeckActionNoise(actions_num=actions_num)
self.memory = Memory(capacity=int(capacity))
# 配置网络参数
self.actor = Actor(num_states=self.states_num,num_actions=actions_num,action_limits=action_limit)
self.target_actor = Actor(num_states=self.states_num,num_actions=actions_num,action_limits=action_limit)
self.actor_optimizer=torch.optim.Adam(self.actor.parameters(),lr=self.learning_rate)
self.critic = Critic(num_states=states_num,num_actions=actions_num)
self.target_critic = Critic(num_states=states_num,num_actions=actions_num)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),lr=self.learning_rate)
# 硬件参数更新
hard_update(self.target_actor,self.actor)
hard_update(self.target_critic,self.critic)
# 下面是选择动作
def select_action(self,state):
# 用Actor网络进行搜索
# 输入state为numpy类型
# state = torch.tensor(state).float()
action = self.actor.forward(state).detach()
new_action = action.data.numpy() + self.noise.sample()*self.action_limit
new_action = new_action.clip(min=-1*self.action_limit,max=self.action_limit)
return new_action
# 通过经验回放中进行学习
def learn_from_memory(self):
## 首先优化评论家网络参数
s,a,r,s_,done = self.memory.sample(self.batch_size)
# 下面进行数据类型转换
s = np.array(s)
s_ = np.array(s_)
r = torch.tensor(r)
# 根据target_actor得到其动作a_
a_ = self.target_actor.forward(s_).detach()
# 计算a_动作对应的target_critic(s,a)
next_val = torch.squeeze(self.target_critic.forward(s_,a_).detach())
y_expected = r + self.gamma*next_val
y_expected = torch.FloatTensor(y_expected)# 转换数据类型
# 下面计算预测值
a = torch.FloatTensor(a)
y_predicted = torch.squeeze(self.critic.forward(s,a))
# 计算损失项loss_critic
loss_critic = F.smooth_l1_loss(y_predicted,y_expected)
# 下面开始更新critic
self.critic_optimizer.zero_grad()
loss_critic.backward()
self.critic_optimizer.step()
# 下面开始更新actor
pred_a = self.actor.forward(s)
loss_actor = -1*torch.sum(self.critic.forward(s,pred_a))
self.actor_optimizer.zero_grad()
loss_actor.backward()
self.actor_optimizer.step()
# 下面更新网络参数
soft_update(target=self.target_actor,source=self.actor,tau=self.tau)
soft_update(target=self.target_critic,source=self.critic,tau=self.tau)
return (loss_critic.item(),loss_actor.item())
# 下面用来训练网络
def train_network(self,env,epsiodes=800):
epsiode_rewards = []
loss_critics,loss_actors = [],[]
for epsiode in range(epsiodes):
state = env.reset()
epsiode_reward = 0.0
loss_critic,loss_actor = 0.0,0.0
time_in_epsiode = 0
is_done = False
while not is_done:
action = self.select_action(state)
next_state,reward,is_done = env.step(action)
self.memory.push(state,action,reward,next_state,is_done)
# 如果样本数数目够>=batchsize的话就可以抽样
if len(self.memory.memory_state) >= self.batch_size:
loss_c,loss_a = self.learn_from_memory()
loss_critic += loss_c
loss_actor += loss_a
time_in_epsiode += 1
if time_in_epsiode == 0:# 避免除0误差
time_in_epsiode = 1
loss_critic = loss_critic/time_in_epsiode
loss_actor = loss_actor/time_in_epsiode
state = next_state
epsiode_reward += reward
epsiode_rewards.append(epsiode_reward)
loss_critics.append(loss_critic)
loss_actors.append(loss_actor)
print("第{}次迭代的奖励为:{:},平均奖励为{:.2f}".format(epsiode,epsiode_reward,np.mean(epsiode_rewards)))
return epsiode_rewards,loss_critics,loss_actors
下面是主函数实现过程:
# 网络训练的迭代次数10次,batchsize为1200,replaybuffer容量1e7,学习率0.0001
DDPGAgent = DDPGagent(capacity=1e7,batch_size=1200,states_num=4,actions_num=2,action_limit=36*360,gamma=0.9,learning_rate=0.0001)
epsiode_rewards,loss_critics,loss_actors = DDPGAgent.train_network(env=env,epsiodes=10)
由于硬件限制,这里只进行10次epochs得到的结果如下所示:

将loss图像画出来如下:
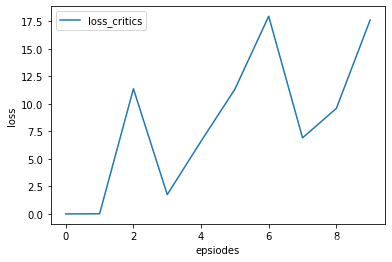
下面尝试绘制其rewards图像:
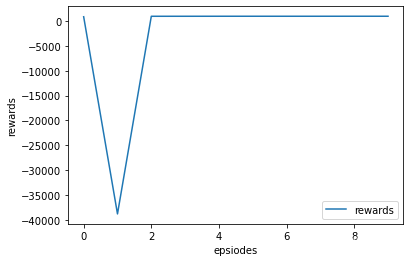
















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









