






 文章介绍了如何在Ultralytics的YOLOv8框架中集成MSHA注意力机制,包括从GitHub下载代码、添加注意力模块至任务和模型配置,以及如何通过修改train.py进行训练。
文章介绍了如何在Ultralytics的YOLOv8框架中集成MSHA注意力机制,包括从GitHub下载代码、添加注意力模块至任务和模型配置,以及如何通过修改train.py进行训练。
一、下载代码
点击下方链接到github下载
ultralytics: YOLOv8 🚀 Ultralytics 同步更新官方最新版 YOLOv8 (gitee.com) https://gitee.com/monkeycc/ultralytics本文下载的代码版本为8.0.154,不同版本的代码结构可能会不同
https://gitee.com/monkeycc/ultralytics本文下载的代码版本为8.0.154,不同版本的代码结构可能会不同
二、注意力机制代码
本文使用MSHA注意力机制,代码如下
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]),
requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]),
requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
c1, c2, c3, c4 = content_content.size()
if self.pos:
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(
0, 1, 3, 2) # 1,4,1024,64
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return out三、添加进Yolov8
1.在Yolov8的ultralytics/nn这个路径下创建文件,建议与注意力机制的模块同名。
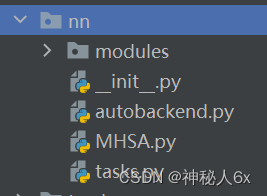
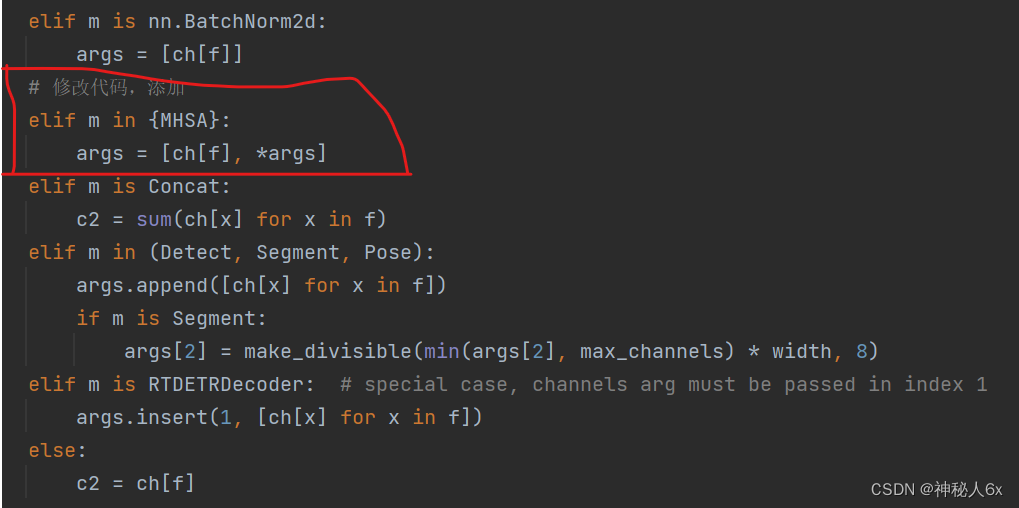
2.在task.py中添加代码
task.py还是在上述的路径下。打开,找到parse_model(d, ch, verbose=True)函数,做如下添加。

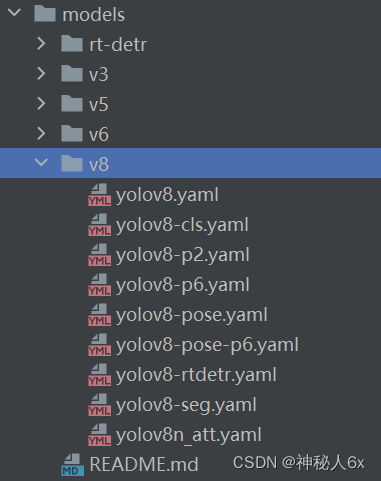
3.创建新的yaml文件
在ultralytics/cfg/models/v8这个路径下创建新的yaml文件,yolov8n_att.yaml文件
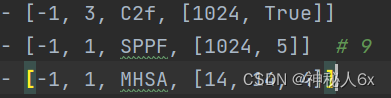
将yolov8.yaml文件的内容复制到yolov8n_att.yaml文件中,防止错误。
在要添加注意力模块的层下方添加,本文是对SPPF层做注意力机制,所以就在SPPF层下方。
修改head的内容
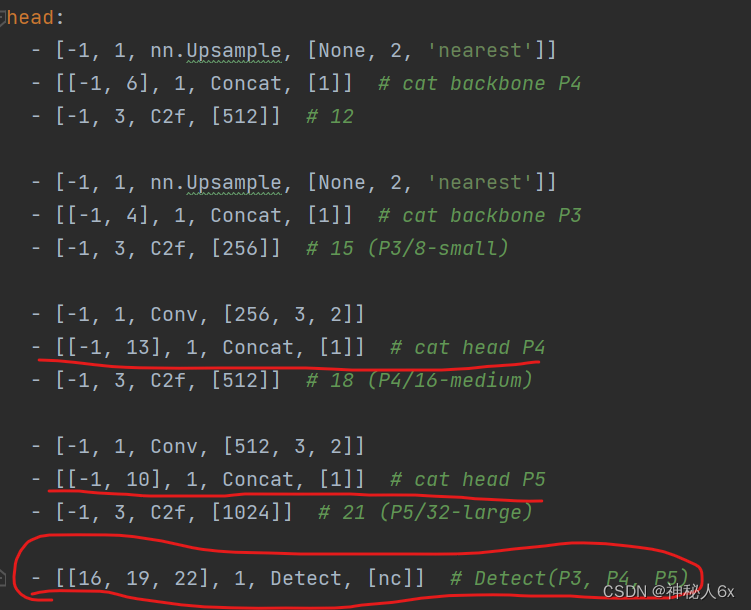
就是修改原来函数中层数发生变化的地方。
至此,修改完成。
四、训练
yolov8训练分为可以分为两种,命令行与代码。这里推荐的是通过修改train.py代码来实现。
在主文件夹下找到train.py文件,如下图。
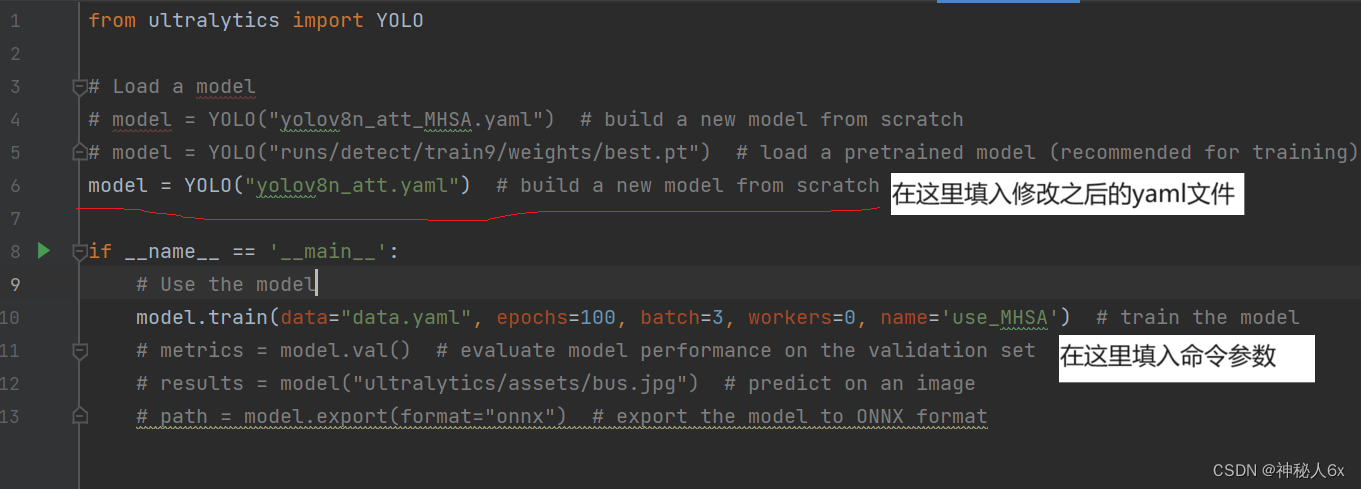
一般来说,添加注意力机制之后,只需要修改yaml与data两个参数,如图中红线画住的区域。这里解释一下,yaml参数的default后面的路径指的是你要训练的模型的结构文件,这本文中就是修改为yolov8n_att.yaml文件的路径;data参数default路径是你要训练的数据的data.yaml文件的路径,修改训练数据时修改它。还有其他参数可以去ultralytics官网查看。
在本文中,在不修改训练数据的情况下,修改yaml参数后的路径为yolov8_att.yaml路径,然后运行train.py即可开始训练。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









