






本篇文章都是基于之前的两篇文章所配置的环境开始,如果是还未跑通YOLOv8的纯小白可以参考我之前的文章先配置跑通YOLOv8。如果已经成功跑通YOLOv8,那就直接参考这篇文章即可。之后博主也会更新更多的相关改进教程和目标分割的一些源码复现,希望大家多多关注!!!
目录
1. 注意力机制介绍
1.1 CBAM注意力机制
CBAM(Convolutional Block Attention Module)是一种用于卷积神经网络的注意力机制,旨在增强模型对重要特征的提取能力。它由两个主要模块组成:通道注意力模块和空间注意力模块。
原文链接:CBAM论文

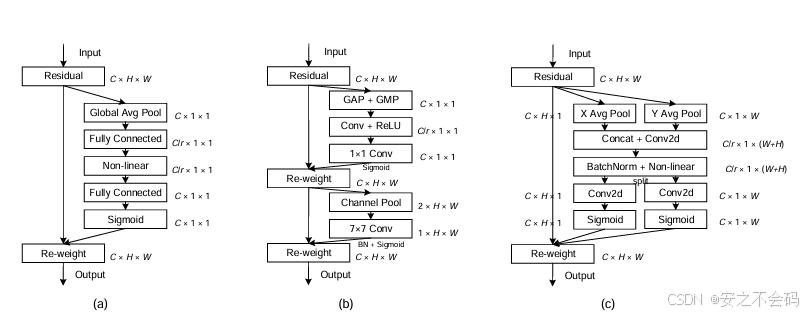
通道注意力模块:通过全局平均池化和最大池化获取通道维度的特征信息,利用共享的全连接层生成通道注意力权重,突出重要通道的特征。
空间注意力模块:在通道注意力输出的基础上,通过池化和卷积操作生成空间注意力权重,强调特征图中的关键空间区域。
CBAM通过串联这两个模块,能够自适应地调整特征图在通道和空间维度上的权重,提升模型的表现。由于其轻量级设计,CBAM可以方便地集成到现有网络中,广泛应用于图像分类、目标检测等任务。
1.2 SE注意力机制
SE(Squeeze-and-Excitation)注意力机制是一种用于增强卷积神经网络特征表达的注意力模块。它主要由两个步骤组成:
原文链接:SE论文
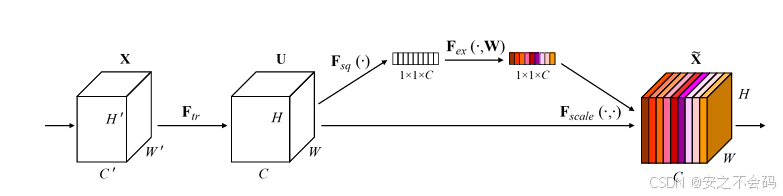
Squeeze:通过全局平均池化将每个通道的空间信息压缩为一个全局特征描述符,生成通道级的统计信息。
Excitation:利用全连接层和激活函数(如ReLU和Sigmoid)学习通道间的依赖关系,生成通道注意力权重,并对原始特征进行加权,突出重要通道的特征。
SE模块通过显式建模通道间的关系,能够自适应地调整特征图中各通道的权重,提升模型的表现。由于其简单高效,SE模块可以轻松嵌入到现有网络中,广泛应用于图像分类、目标检测等任务。
1.3 CA注意力机制
CA(Coordinate Attention)注意力机制是一种用于增强卷积神经网络特征表达的注意力模块,专注于同时捕捉通道关系和空间位置信息。它通过以下两个步骤实现:
原文链接:CA论文
坐标信息嵌入:将输入特征图分别沿水平方向和垂直方向进行全局池化,生成一对方向感知的特征描述符,捕获空间位置信息。
坐标注意力生成:将上述特征描述符拼接并通过卷积和激活函数生成注意力权重,分别应用于水平和垂直方向,从而增强模型对空间位置和通道关系的建模能力。
CA注意力机制通过显式建模空间位置和通道间的依赖关系,能够更精确地定位目标并增强特征表达。由于其轻量级设计,CA模块可以方便地集成到现有网络中,广泛应用于图像分类、目标检测等任务。
2 添加注意力机制
2.1 复制相应的注意力机制源码
2.1.1 CBAM注意力机制源码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, channels: int) -> None:
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
return x * self.act(avg_out + max_out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, 1, keepdim=True)
max_out = torch.max(x, 1, keepdim=True)[0]
out = self.act(self.cv1(torch.cat([avg_out, max_out], 1)))
return x * out
class CBAM(nn.Module):
def __init__(self, c1, kernel_size=7):
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x2.1.2 SE注意力机制源码
import torch.nn as nn
class SE_block(nn.Module):
def __init__(self, channel, scaling=16, use_inplace=True):
"""
SE注意力模块
:param channel: 输入特征图的通道数
:param scaling: 中间层的缩放比例,默认为16
:param use_inplace: 是否使用inplace操作,默认为True
"""
super(SE_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化
self.fc = nn.Sequential(
nn.Linear(channel, channel // scaling, bias=False), # 压缩通道
nn.ReLU(inplace=use_inplace), # 激活函数
nn.Linear(channel // scaling, channel, bias=False), # 恢复通道
nn.Sigmoid() # 生成注意力权重
)
def forward(self, x):
b, c, _, _ = x.size()
# Squeeze: 全局平均池化并展平
y = self.avg_pool(x).flatten(1)
# Excitation: 通过全连接层生成注意力权重
y = self.fc(y).view(b, c, 1, 1)
# Scale: 对输入特征图进行重标定
return x * y2.1.3 CA注意力机制源码
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, reduction=32):
super(CoordAtt, self).__init__()
oup = inp
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out2.2 添加相应注意力机制
2.2.1 建立注意力机制文件夹
首先打开YOLOv8项目,然后打开ultralytics文件夹下的nn文件夹内创建一个名为Attention的文件夹,具体步骤如下:
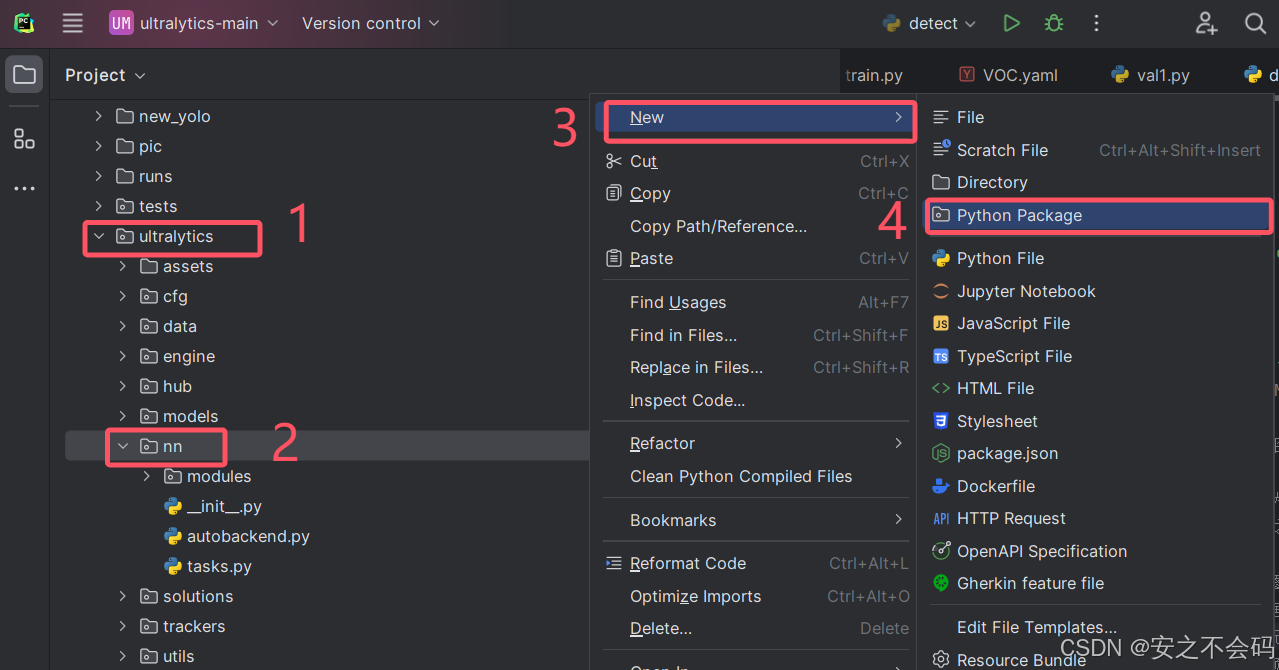
创建好之后如下图所示
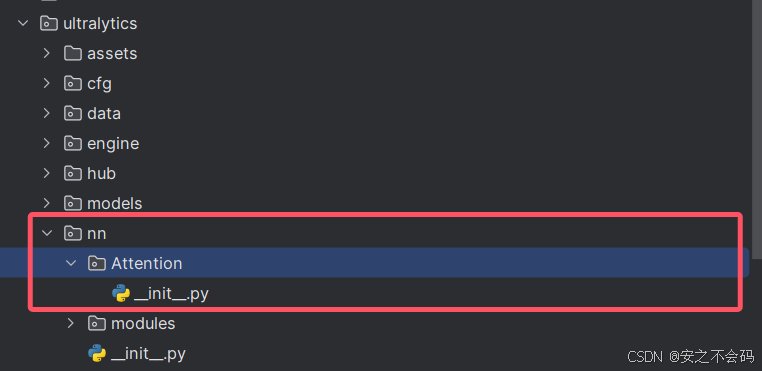
然后在该文件夹内建立一个python文件,名称就设置为需要添加的注意力机制的名称,这里我用CBAM来举例(其他注意力机制方式一样)
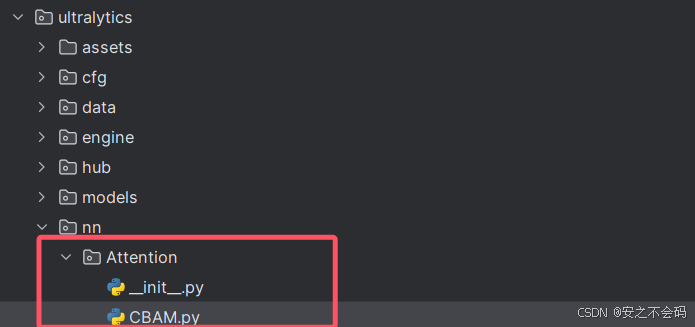
建立好之后就是这样,然后将相关注意力机制的源码复制到建立的python中,如下所示
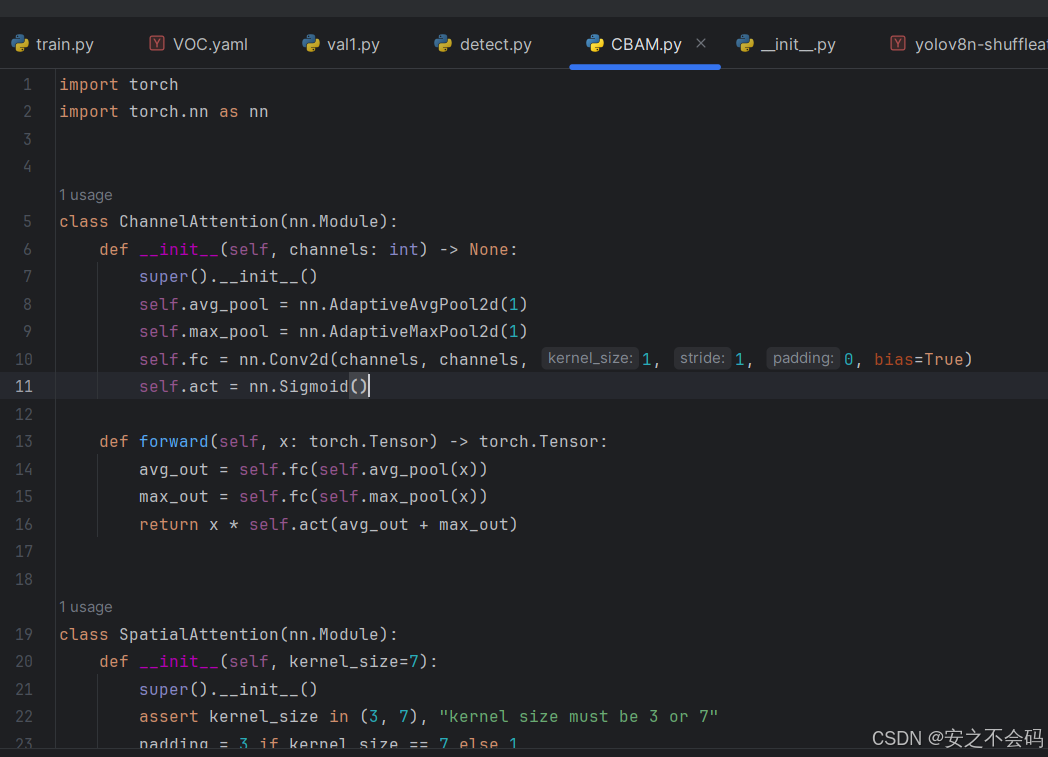
然后打开同文件夹内的__init__.py,并在里面引用我们的CBAM模块
from ultralytics.nn.Attention.CBAM import CBAM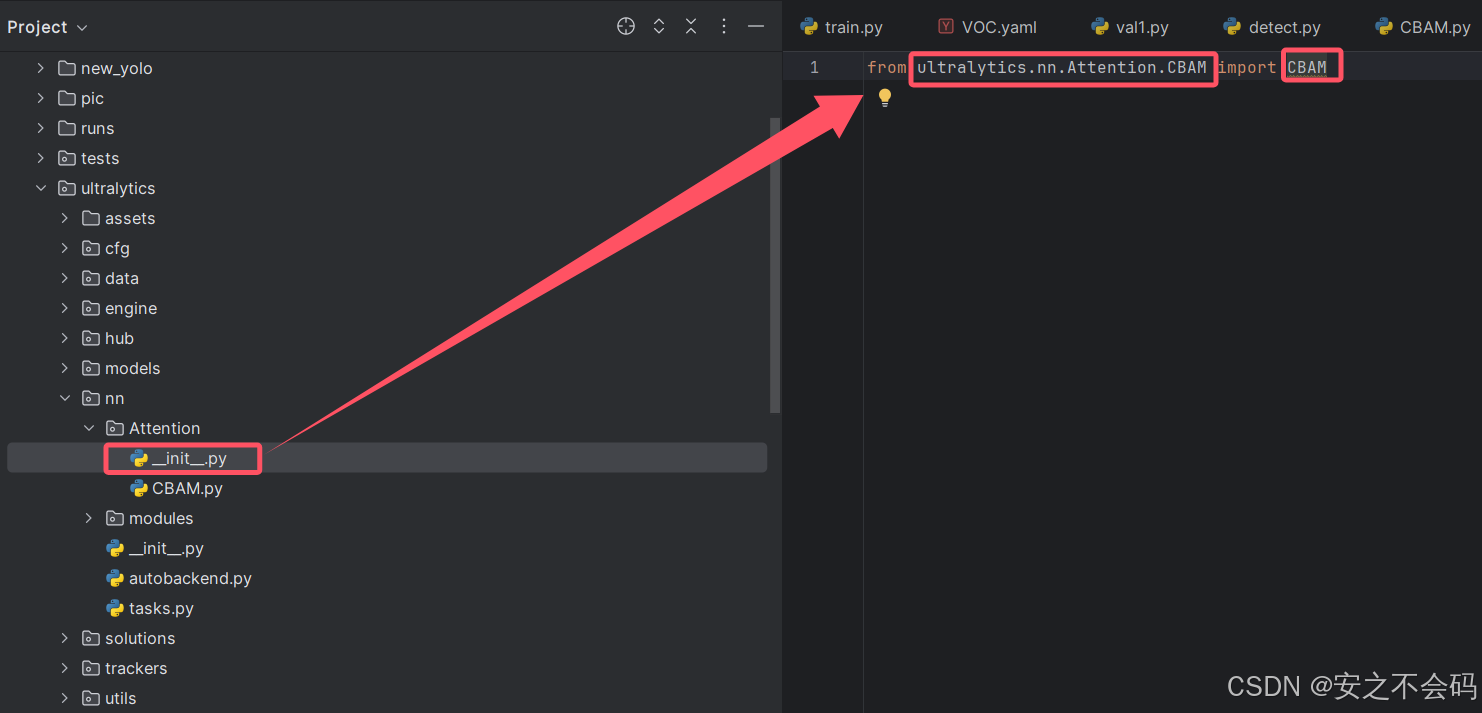
前面部分是你需要添加的注意力机制的文件,然后后面的是模块名称(这个名称需要根据你这个代码中最后的命名来决定,不是自己定的) ,具体如下所示
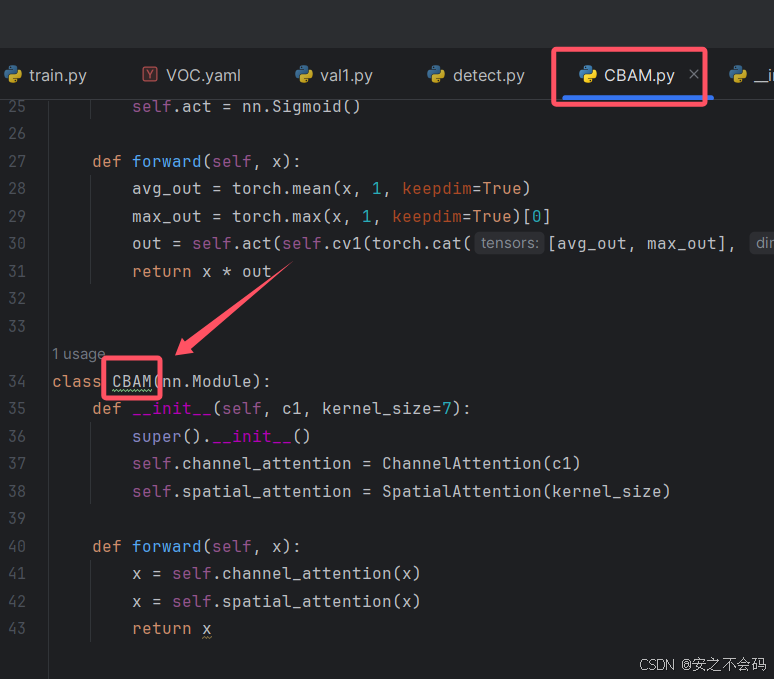
2.2.2 添加注意力机制
首先打开ultralytics下面的nn文件夹中的tasks.py文件,然后在代码的开头输入以下代码(以CBAM为例)
from ultralytics.nn.Attention import CBAM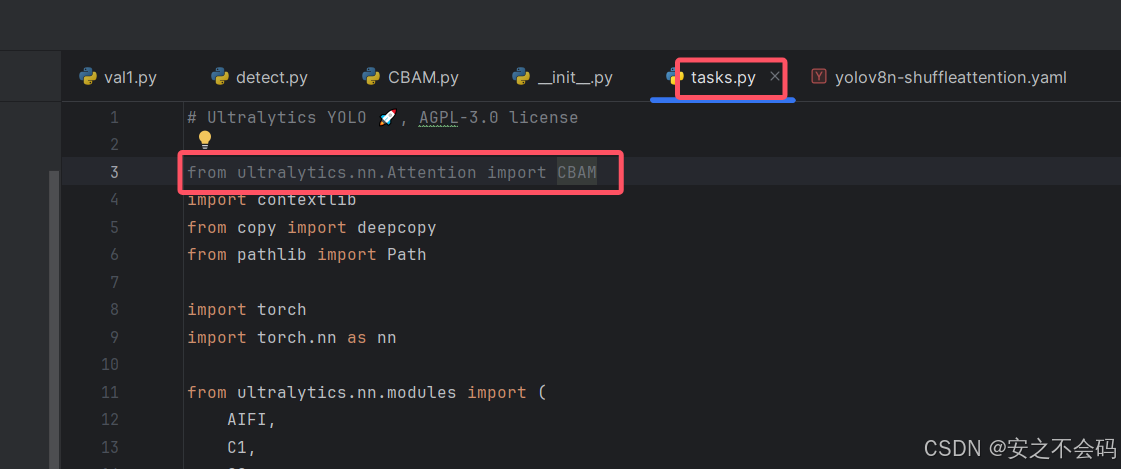
然后还是在这个文件夹中,ctrl+f 搜索parse,找到以下代码部分
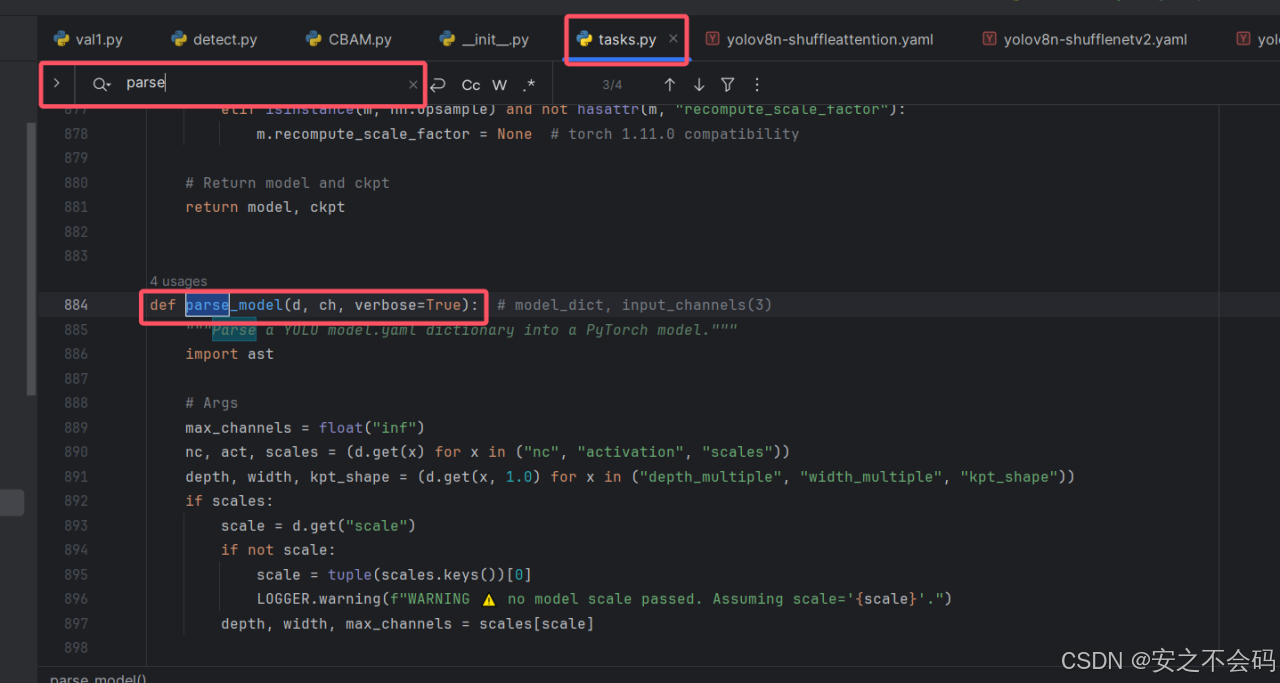
在这个代码中,将下面部分添加到指定位置,大家参考我的截图添加(如果你添加的是别的注意力机制,只需要将括号内的CBAM换成其他的就行,如果你同时想把很多注意力机制都配置好的话,你可以在括号内CBAM后面加个 , 然后将注意力机制模块跟到后面就行)
elif m in {CBAM}:
c2 = ch[f]
args = [c2,*args]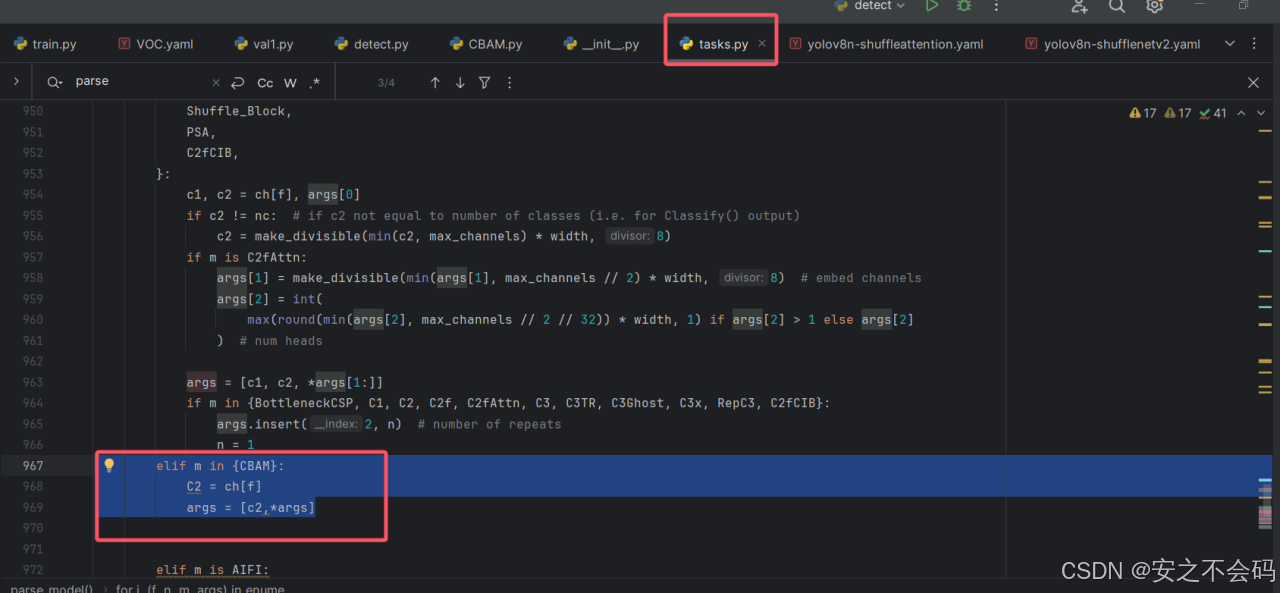
2.2.3 配置对应的yaml文件
打开ultralytics文件夹下面的cfg文件夹,其中的v8文件夹中有一个yolov8.yaml文件,我们复制这个文件,然后将这个文件继续粘贴在该文件夹中,然后重新命名
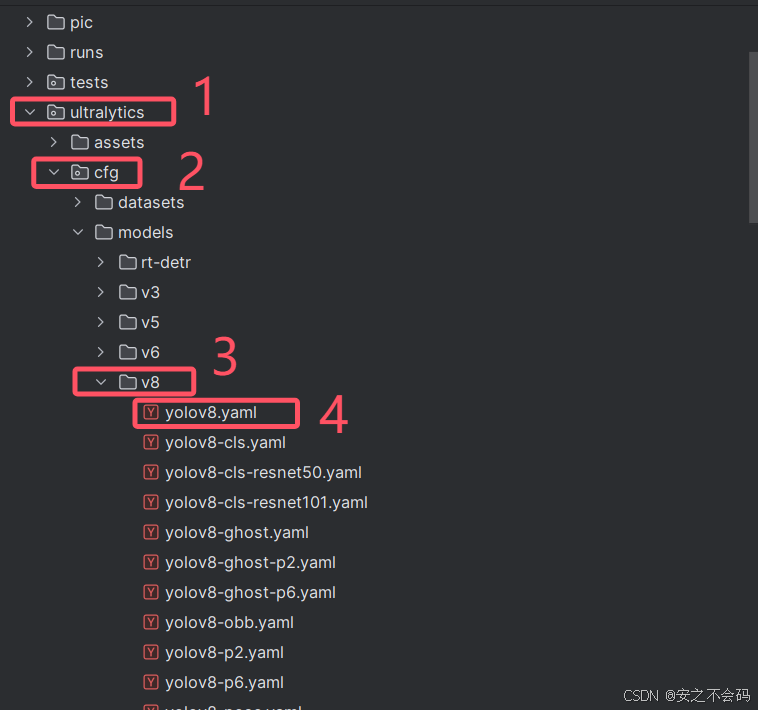
粘贴之后记得重命名,最好是命名为yolov8n-CBAM(这是以CBAM举例,然后最好是带一个n,不然有时候后面会报个错误)
找到自己新创建的.yaml文件,然后将里面的内容全部删除,如下所示
将我下面给的内容全部粘贴在里面
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
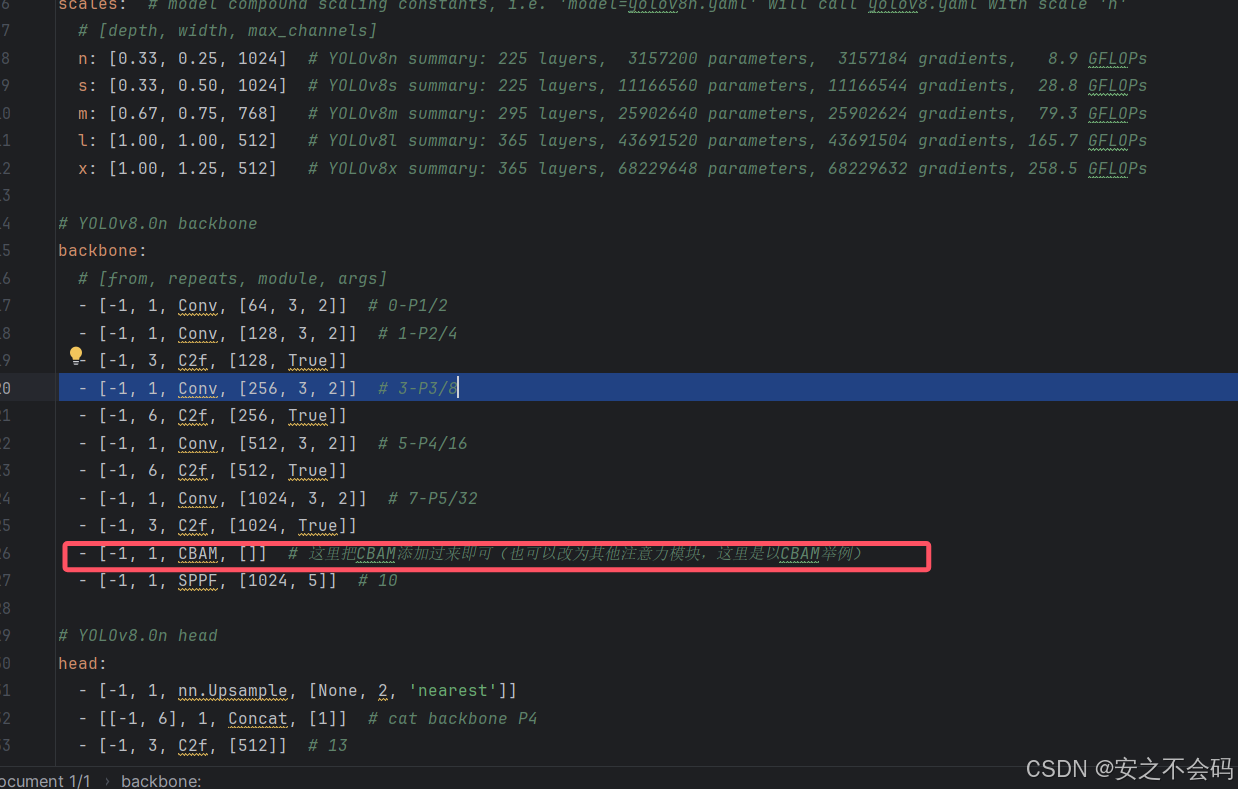
- [-1, 1, CBAM, []] # 这里把CBAM添加过来即可(也可以改为其他注意力模块,这里是以CBAM举例)
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)这里我是将CBAM添加在这个位置了,大家也可以添加在其他位置(比如添加在探测头里面,这个大家结合自己的需求就可以)
2.2.4 运行代码
然后我们复制这个.yaml文件的绝对路径
打开训练脚本,将里面的路径替换为刚才复制的.yaml文件路径
没有看过之前文章,没有训练脚本的,可以直接复制以下脚本
from ultralytics import YOLO
# Load a model
model = YOLO(r'G:\add\ultralytics-main\ultralytics\cfg\models\v8\yolov8n-CBAM.yaml') # build a new model from YAML
# model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
#model = YOLO(
#r'G:\add\ultralytics-main\ultralytics\cfg\models\v8\yolov8n-SimAM.yaml') # build from YAML and transfer weights
# 断点续训
# Load a model
#model = YOLO(r'G:\add\ultralytics-main\runs\detect\train3\weights\last.pt') # load a partially trained model
if __name__ == '__main__':
results = model.train(data=r'G:\add\ultralytics-main\ultralytics\cfg\datasets\VOC.yaml',batch=75,epochs=10,imgsz=640,resume=True,workers=8)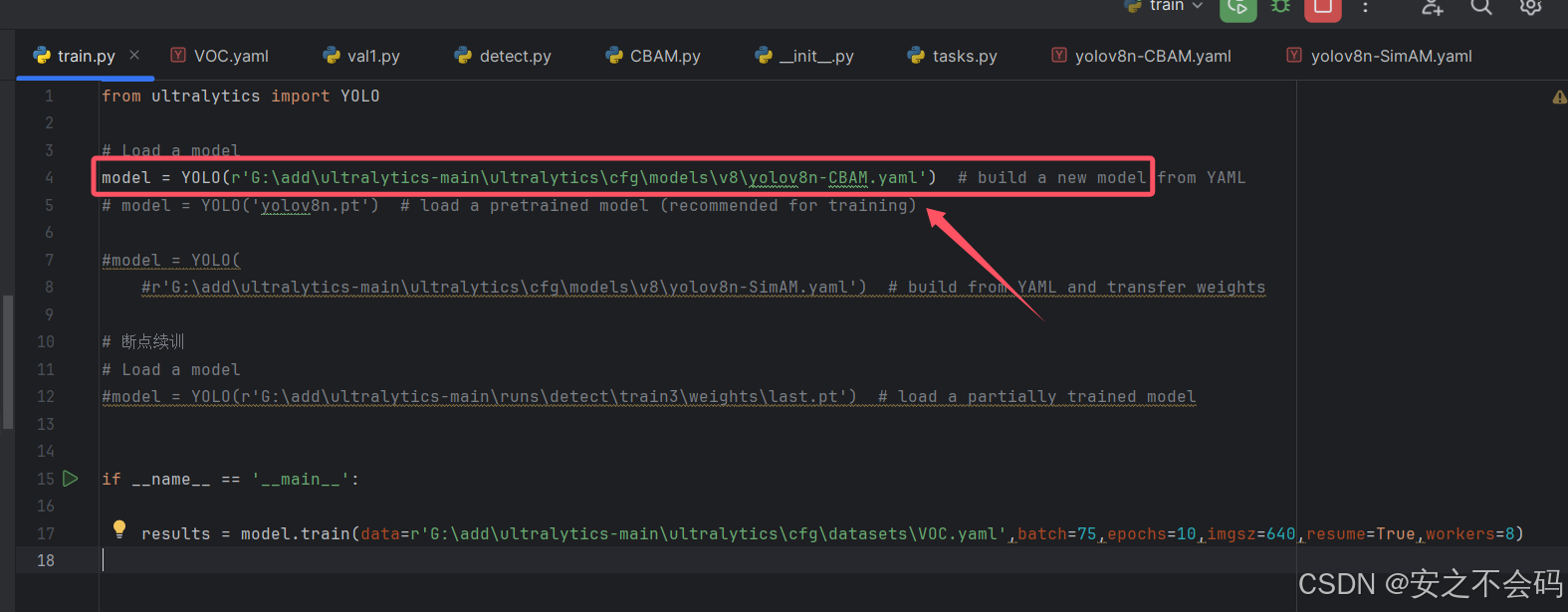
将yaml文件路径替换完之后,运行该脚本即可
出现以下界面表示添加成功
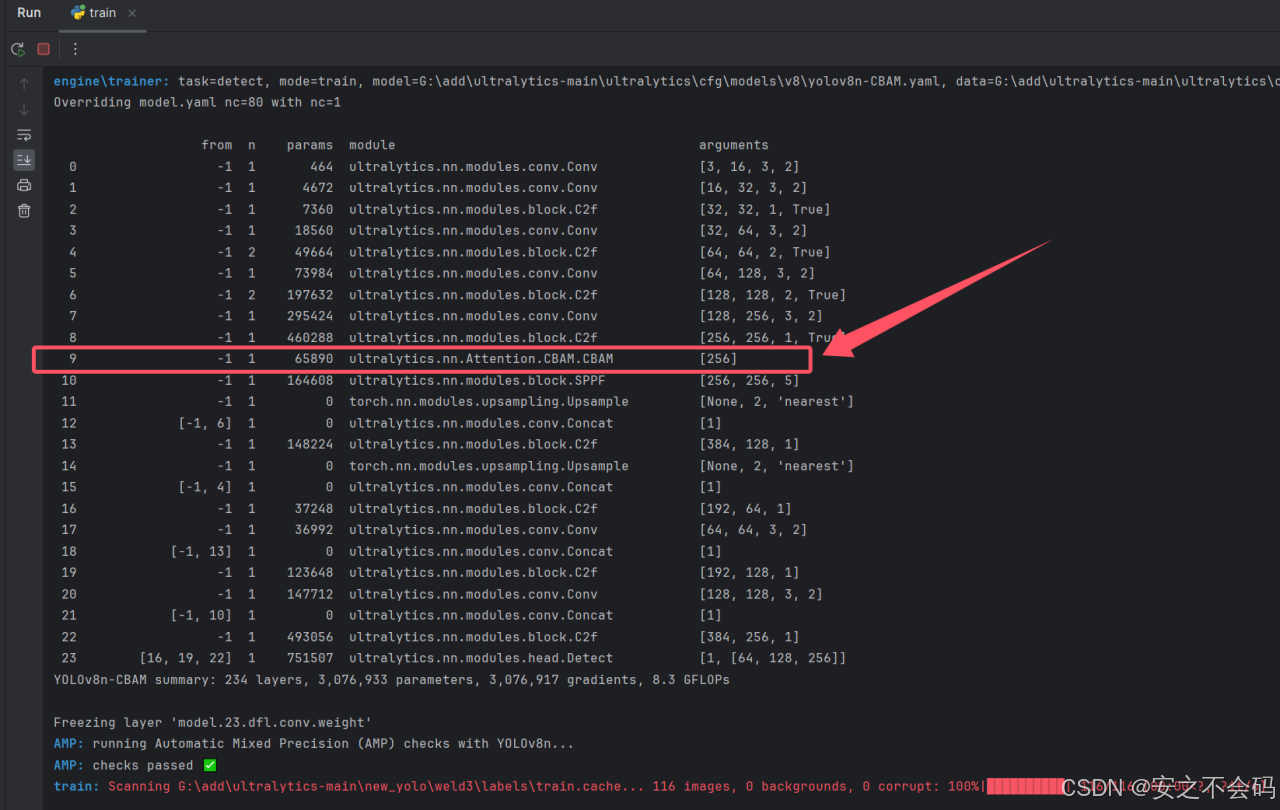
这里博主由于篇幅缘故就不再继续添加其他几个模块了,大家可以按照CBAM的模块对应添加即可,几乎是一摸一样的,然年有任何问题也欢迎大家在评论区留言
3. 总结
博客主要详细教学了在YOLOv8中添加注意力机制的超详细步骤,基本大家只要按步骤来就肯定可以复现成功,后续博主也会再更新一些关于YOLOv8的其他改进方法,期待大家多多关注!!!大家有想看的内容也可以在评论区留言!


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









