









作者 |德新
编辑 |王博

经过100万到200万级别短视频Clips的训练,理想智驾搭载端到端+VLM视觉语言模型技术的第一个版本(OTA 6.1.0 E2E-VLM Beta 1),已经向千人级别的内测用户开放。
这可能是目前在国内,作为一个普通车主有机会用上的绝少数搭载了端到端技术的智驾软件版本。
从2023年下半年到眼下,在短短一年之内,端到端和大模型,迅速成为智驾行业对技术发展的共识。
关于理想的端到端智驾系统,理想团队曾在7月初的一场线上发布会上分享过「端到端 + VLM」双系统的设计思路。
一个月后,伴随新软件版本向千人团开放,理想智驾副总裁郎咸朋、理想智驾技术研发负责人贾鹏在北京接受了多家媒体的采访。
站在百万级Clips训练数据的节点上,郎咸朋说,「我们还在摸索数据提升和性能提升的边界,现在还(远远)没有看到上限。」
目前理想积累了超过12亿公里可用的驾驶场景数据,通过对已有的80万车主驾驶行为的评分,其中约3%驾驶行为分在90分以上的车主,可以称为「老司机」。
车队老司机的驾驶数据,成为端到端模型训练源源不断的燃料。
一、与特斯拉不同,双系统设计
纯粹的端到端的智驾系统,存在一个天然的缺陷:其训练的数据是基于已知的驾驶场景,如果是没有见过的场景,系统就没法很好地工作。
理想在内部一直有PD与RD两支团队,前者负责产品交付,后者主导技术预研。
大约不到一年之前,在RD主导的技术分享会上,内部最早提到了慢思考与快思考两套系统的设计理念。
去年10月的战略会,理想内部明确了智能驾驶是公司接下来重要的发展方向。而向AI和端到端技术的切换,也在今年上半年正式提上智驾团队的日程。双系统的设计,很自然地成为理想端到端智驾研发的基础思考。
今年,理想团队对特斯拉FSD的体验,也让团队更加坚信了双系统的设计。
贾鹏说,「我们开V12.3发现,它东西海岸的表现差异非常大。西海岸特别好,旧金山附近非常顺,基本没有太多接管;但是到了东海岸,到波士顿、纽约,它表现急剧下降;到纽约后,纽约非常复杂,接管率会高非常多。」
纽约跟国内的上海、广州相比还算相对简单。那么在中国做自动驾驶,在车端芯片算力有限的情况下,仅仅靠一个端到端的模型,真的可以吗?
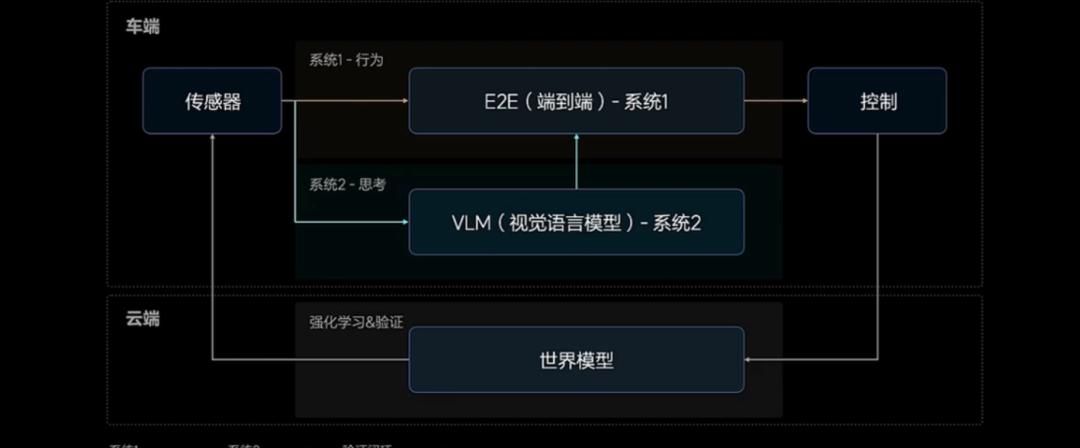
理想智驾的双系统设计,是在端到端模型的基础上,再加一个有泛化能力、逻辑思考能力的系统,也就是VLM(视觉语言大模型)。VLM不直接输出控制信号,但会给端到端的模型提供决策依据。
贾鹏介绍车端的端到端与VLM模型之间的关系:
「两个系统都是实时运行。端到端因为模型小一些,它帧率比较高,比如跑十几赫兹;VLM参数量就大得多,是22亿参数,目前能跑到3 - 4赫兹之间。」
尤其在一些大的复杂场景,比如高速收费站选通道走ETC还是人工、施工路段、学校路段、连续坑洼路段,VLM会给到端到端模型一些信息输入。
HiEV在实车体验理想的端到端+VLM内测版本时,也发现系统会针对施工、学校等特殊路段给出提醒。理想的工作人员介绍:目前这部分信息直接来自于VLM,而不是来自导航信息。
贾鹏认为,接下来车端的模型会有两个趋势:
- 第一,模型规模变大。系统一和系统二两个模型有可能合一,从松耦合走向紧耦合;
- 第二,借鉴多模态大模型的趋势,向原生多模态发展,既能做语言也能做语音,也能做视觉,也能做激光雷达。这样一套范式能够支撑机器人、具身智能的应用,走向通用人工智能。
二、理想的世界模型
端到端和VLM都是车端的模型,称为系统1和系统2。
而理想的云端模型,内部称之为系统3,也就是大家熟知的「世界模型」。
端到端时代,迭代后的新模型版本是完全的黑盒,没有中间结果。这也意味着,对新版本的评价和验证工作,假设在原来多模块架构的情况下下,只需要评估其中改动更新的1%,那现在变成了需要100%地进行验证。
「肯定不可能每发一个版本,就搞很多车全国各地跑跑,跑也跑不过来,而且能力也不是这么测试的。」郎咸朋说。
理想的世界模型设计,类比人类的驾照考试、教师资格证考试或者律师考试,核心是建立对专业能力的评价体系。世界模型被用于能力重建,或者说生成考题。
「我们有自己的真题库,是人在路上驾驶的正确行为。还有错题库,是正常的测试和开车过程中,用户接管、退出的数据。
还有一些模拟题,根据所有的数据举一反三,比如这个地方出匝道老有问题,那针对匝道的场景再生成一些内容。」
有了这些题目之后,团队了解模型迭代前的上一个版本的能力,在哪些题上会出错;而训练完的新模型,要检验之前的题还会不会错,同时保证之前对的题依然正确。
再根据新版模型的打分,决定是否可以迭代到车端,投入到更大范围的千人早鸟测试,再进一步下发给更多用户。
这样的考核,蕴含了大量的里程数,首先考题本身具有一定规模,其次这些题目「基本上是上万公里,但不是真正只跑几万公里就能得出来的,是综合的结果」。
就像高考一样,高考题的设计,并不是把高中的每一本书都考一遍,但需要实现能力评估的作用。
而「世界模型」作为考题,它的设计也是一项复杂的工作。
理想目前的「出题团队」是一支混合团队,包含了产品团队、主观评价团队,也包括一部分当前在无图版本中负责功能开发的工程师。
理想认为智驾在未来很长一段时间内,大部分的工作会集中在一头和一尾。
「中间模型本身的设计,可能没有那么多人。」贾鹏说,「一头是数据,一头是考试。大部分人都在做这两件事。」
三、端到端时代的智驾开发模式
12亿公里的行驶数据库,再加上80万车主中3%的老司机,成为一个庞大的数据资源池子。
理想当前的OTA 6.1.0版,使用了100多万条Clips来训练。
什么概念呢?200万条短视频基本上对应40亿帧,如果采用人工标注3D框的方式,单人每天大概可以标注3帧。所以无论从时间还是金钱的角度,端到端的训练数据必须是自动标注了。
在百万条Clips中,理想主要使用了两类数据:一类是30秒,一类是1分钟的数据。
人类的大部分驾驶决策集中在5秒以内,30秒就意味着覆盖几个小的场景;但一些长决策,比如当前本车在最左车道,之后要从最右车道下匝道,这样的行为有时需要一分钟或者更久。长决策则需要将有持续关系的数据拼接在一起,让模型能够理解场景的前后关系。
数据规模和数据配比,是影响模型表现的其中两个关键因素。
理想之前的端到端模型,在80万Clips训练数据规模时,还实现不了过环岛;但到了100万Clips规模时,突然惊喜地发现模型能够自主通过环岛了。
另一个案例则是,刚开始做端到端模型训练时,团队发现训练出来的模型,一般情况下开得可以,但在等红灯的时候,车辆行为有一些奇怪,总是非常急躁想要变道或者加塞。
后来团队才意识到,原来训练时,因为等红灯时周围场景没有变化,所以当时删掉了很多等红灯前十几秒或者一分钟的数据。
「我们发现训练端到端模型,跟古代炼丹没什么区别。」郎咸朋类比了古代炼制火药,「一硝二磺三木炭,做出来的炸药威力比较大;其他配比,可能也能点个火。」
因此,数据的配比十分关键。
修复红绿灯的案例,在于恢复车辆等待红灯变绿之前的信息,而要定位这样的问题,跟过去智驾的开发方式也有很大差别。
理想为此设计了一套专门的工具链:当一个问题案例(bad case)出现时,内部有一套分诊台Triage的机制,来自动地分析是属于哪一类问题的场景,这个分诊机制也是通过模型训练实现的,这样定位出需要补充或者替代什么样的数据,再进行下一步的训练,这个过程可能涉及同时训练多个版本的模型,「现在最多同时训十来个模型,再通过评分系统来打分。」
而如何通过数据链和基础设施,把所需要的数据高效地挖出来,则是一项需要多年积累的能力。
「某种意义上甚至大于模型的能力,因为没有这些良好的基建和数据,再好的模型也训练不出来。」郎咸朋认为。
四、10亿级美元投入,华蔚小理决战端到端
从7月底到本周,在几乎不到10天的时间内,蔚来、小鹏、理想、华为先后召开发布会,公布了各自在端到端智驾上的进展。
端到端上车的效果也是十分明显的。HiEV在体验理想端到端+VLM内测版本时,明显感受到它在一些相对复杂场景的处理上更加细腻、拟人。
端到端将支撑智驾功能,从之前的「点到点」晋级到「车位到车位」,也意味着断点更少、连续性更强,并且可以随时启动(不要求车辆在车道线内居中后开启)。
端到端还带来了整个链路执行速度的提升。
贾鹏告诉我们,过去分模块的系统从传感器信息进入到控制信号输出大概需要300 - 400毫秒,改为端到端后这个时间变成了100多毫秒。人很难感知到这样短的时间变化,但对于系统来说,这意味着更早发现、更加安全的能力,以及提前规划、更加丝滑的控制。
并且,当前端到端模型上车,仍然在非常早期的阶段,我们还难以想象千万级Clips训练获得的模型将实现什么样让人惊喜的效果。
端到端系统的上限在哪里?
「VLM现在应该是站在了一个无人区的边界。我们在做的过程中,发现数据规模带来的性能提升,现在还没有看到上限。」郎咸朋说。
目前就车端而言,上限在于芯片的算力以及内存带宽。
理想目前车端的端到端模型大概在3亿左右的参数量,3亿参数模型其能消化的训练数据,存在上限。VLM则要比端到端模型参数规模高一个级别,而跑在云端的世界模型,参数规模要大得多,可以说是几乎没有上限。
理想预估,明年在云端的训练算力上将会有一个指数级的上升,因为对于世界模型,理想情况下是要重建物理世界所有的信息,其需要的数据和算力消耗是难以预估的。
「如果做到 L3和L4级的自动驾驶,一年光训练算力花销就得到10亿美金。将来拼的就是算力和数据,背后拼的是钱。归根到底,拼的还是盈利能力。」


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









