






目录
基于ARIMA模型的中国福州PM2.5趋势分析与预测 1
摘要 1
1.介绍 2
2.材料与方法 2
2.1数据源 3
2.2相关分析:Spearman的Rho试验 3
2.3ARIMA模型 3
2.4模型辨识 4
2.4.1模型参数估计与诊断 4
2.4.2 ARIMA模型预测 4
3.特性分析 4
3.1浓度分析 4
3.1.1PM2.5浓度的特征分析 4
3.1.2PM2.5浓度与气象参数的特征分析 5
3.1.3.PM2.5与其他污染物浓度的特征分析 6
3.2相关分析 6
3.3.1模型辨识 7
3.3.2模型参数估计与诊断 7
3.3.3ARIMA模型预测 7
4.总结与结论 9
致谢 10
2.3ARIMA模型
ARIMA模型是一种时间序列预测方法。将样本随时间形成的时间序列数据视为随机序列,该随机序列通过数学模型近似描述。一旦被识别,该模型就可以用于基于时间序列的过去值和当前值预测时间序列的未来值。
ARIMA模型由三部分组成。“AR”,即自回归部分,表示感兴趣的演化变量对其先前的值进行回归;“MA”部分,即移动平均部分,表示回归误差实际上是误差项的线性组合,其值同时发生和在过去,不同的时间,“I”,即集成的部分,表示数据值已经被替换为它们的值与先前值之间的差值。这些特性中的每一个的目的是使模型尽可能地适合数据。
ARIMA模型通常表示为ARIMA(p,d,q),其中“p”是自回归模型的阶数,“d”是差分程度,“q”是移动平均模型的阶数。
其中θi、i是参数,L是滞后算子,Xt是时间序列数据,εt是误差项。
2.4模型辨识
为了建立ARIMA模型,第一步是确定时间序列数据是平稳的还是非平稳的。我们可以通过运行序列图来诊断数据是否是平稳的,运行序列图可以从增强Dickey-Fuller(ADF)测试(Mushtaq,2011)中检测到。通常,非平稳性由缓慢衰减的自相关曲线来表示,然后应用差分方法。差分可以消除时间序列数据的变化,使数据更加稳定。
2.4.1模型参数估计与诊断
一旦确定了时间序列数据的平稳性,接下来就应该估计“p”和“q”。自相关和偏自相关以及Akaike信息准则(AIC)可用于参数估计。
自相关是信号与其本身作为延迟函数的延迟拷贝之间的相关性。这可以说明
其中E是期望值,Xa,Xb是给定时间a,b的过程所推广的值,其中μa,μb are是平均值,a,b are是方差。
与自相关函数相比,偏自相关函数不控制其它滞后。它给出时间序列与其自身滞后值的偏相关,从而控制所有较短的滞后时间中的时间序列值。这可以说明如下:
其中K是滞后和PT的部分自相关,K是XT的投影。
AIC作为ARIMA模型的阶数的有用判据。AIC的目标是获得最小值。AIC值越低,模型越适合数据。定义如下:
其中L是数据的似然函数,k定义为模型中拟合到数据的参数的数量。
2.4.2 ARIMA模型预测
在模型辨识、模型参数估计和诊断之后,最后一步是建立预测模型。
3.特性分析
3.1浓度分析
3.1.1PM2.5浓度的特征分析
根据PM2.5与气象参数和其他污染物之间的变化趋势,将12_月分为4个时段:1期(3月至4月)、2期(5月至7月,以下简称暖期)、3期(8月至10月)和4期(11月至2月,以下简称暖期)。冷期)。图3显示了两年的月平均PM2.5浓度,范围从19至52_μg/m3(2014年8月至2016年7月)。
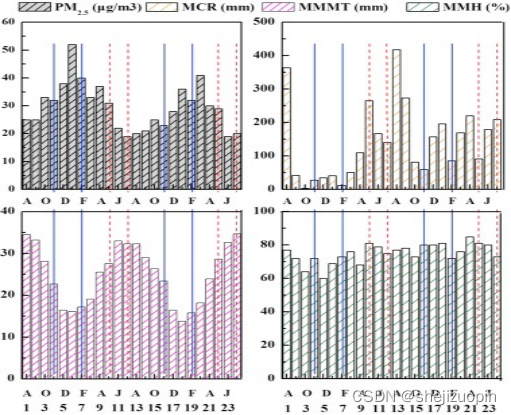
图1月平均PM2.5浓度
4.总结与结论
本文详细讨论了福州市PM2.5浓度水平、污染物浓度与气象参数的关系,以及未来PM2.5浓度的预测。在寒冷和寒冷季节,季节变化呈现低水平和高水平。PM2.5浓度与PM10、SO2和NO2浓度呈显著正相关(1%显著水平),与MMMT和MCR呈显著负相关(分别为5%和1%显著水平),与MMH呈显著负相关(10%显著水平)。对PM2.5浓度的预测在两年内产生了与实际值类似的季节波动,并预测了下一年的类似趋势。


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











