









深入分析Tanh激活函数:数学特性、应用与洞见
在深度学习领域,激活函数的选择对神经网络的性能有着深远的影响。双曲正切函数(tanh)作为一种经典的非线性激活函数,因其独特的数学性质和对梯度传播的支持,在神经网络设计中占据重要地位。本文将从数学定义、特性分析、梯度行为以及实际应用的角度,深入探讨tanh激活函数,并提供Python代码绘制其图像,帮助研究者更直观地理解其行为。我们还将挖掘一些深刻的洞见,以启发深度学习研究者对其应用场景的思考。
一、Tanh激活函数的数学定义
tanh函数是双曲正切函数,定义为:
tanh ( x ) = sinh ( x ) cosh ( x ) = e x − e − x e x + e − x \text{tanh}(x) = \frac{\sinh(x)}{\cosh(x)} = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=cosh(x)sinh(x)=ex+e−xex−e−x
其中,( sinh ( x ) = e x − e − x 2 \sinh(x) = \frac{e^x - e^{-x}}{2} sinh(x)=2ex−e−x) 和 ( cosh ( x ) = e x + e − x 2 \cosh(x) = \frac{e^x + e^{-x}}{2} cosh(x)=2ex+e−x) 分别是双曲正弦和双曲余弦函数。tanh函数的输出范围为 ( ( − 1 , 1 ) (-1, 1) (−1,1)),这是一个关键特性,区别于例如Sigmoid函数的 ( ( 0 , 1 ) (0, 1) (0,1)) 输出范围。
从定义可以看出,tanh是对输入 ( x x x) 进行非线性变换的核心在于指数函数的组合,其对称性(关于原点)是其独特之处。
二、Tanh的数学与计算特性
-
输出范围与零中心性
与Sigmoid函数不同,tanh的输出以0为中心(即均值为0),这在神经网络中具有重要意义。零中心输出可以使后续层的输入分布更加平衡,避免因偏向正值或负值而导致的梯度更新偏移。这种特性在深层网络中尤其有益,因为它有助于缓解梯度偏移问题。 -
导数形式
tanh的导数可以通过其定义直接推导:
d d x tanh ( x ) = 1 − tanh 2 ( x ) \frac{d}{dx} \text{tanh}(x) = 1 - \text{tanh}^2(x) dxdtanh(x)=1−tanh2(x)
导数的最大值为1(当 ( x = 0 x = 0 x=0) 时),并且随着 ( ∣ x ∣ |x| ∣x∣) 增大迅速趋于0。这种形式表明tanh在输入接近0时具有较强的非线性,而在输入较大或较小时趋于饱和。 -
饱和问题
当 ( ∣ x ∣ |x| ∣x∣) 较大时,tanh的值接近1或-1,导数接近0。这种饱和现象会导致梯度消失问题,尤其是在深层网络中,反向传播时梯度可能因多次乘以小于1的值而迅速衰减。这是tanh的一个局限性,但在浅层网络或适当的初始化策略下,这一问题可以得到缓解。 -
对称性
tanh是奇函数,即 ( tanh ( − x ) = − tanh ( x ) \text{tanh}(-x) = -\text{tanh}(x) tanh(−x)=−tanh(x))。这种对称性使得tanh在处理具有对称分布的数据时表现出色,例如标准化后的输入。
三、绘制Tanh图像的Python代码
为了更直观地理解tanh的行为,我们可以用Python结合NumPy和Matplotlib绘制其图像及其导数:
import numpy as np
import matplotlib.pyplot as plt
# 定义tanh函数及其导数
def tanh(x):
return np.tanh(x)
def tanh_derivative(x):
return 1 - np.tanh(x)**2
# 生成输入数据
x = np.linspace(-5, 5, 1000)
# 计算tanh和其导数的值
y_tanh = tanh(x)
y_deriv = tanh_derivative(x)
# 绘制图像
plt.figure(figsize=(10, 6))
# 绘制tanh函数
plt.subplot(2, 1, 1)
plt.plot(x, y_tanh, label='tanh(x)', color='blue')
plt.title('Tanh Activation Function')
plt.xlabel('x')
plt.ylabel('tanh(x)')
plt.grid(True)
plt.legend()
# 绘制tanh导数
plt.subplot(2, 1, 2)
plt.plot(x, y_deriv, label="tanh'(x)", color='red')
plt.title('Derivative of Tanh')
plt.xlabel('x')
plt.ylabel("tanh'(x)")
plt.grid(True)
plt.legend()
# 调整布局并显示
plt.tight_layout()
plt.show()
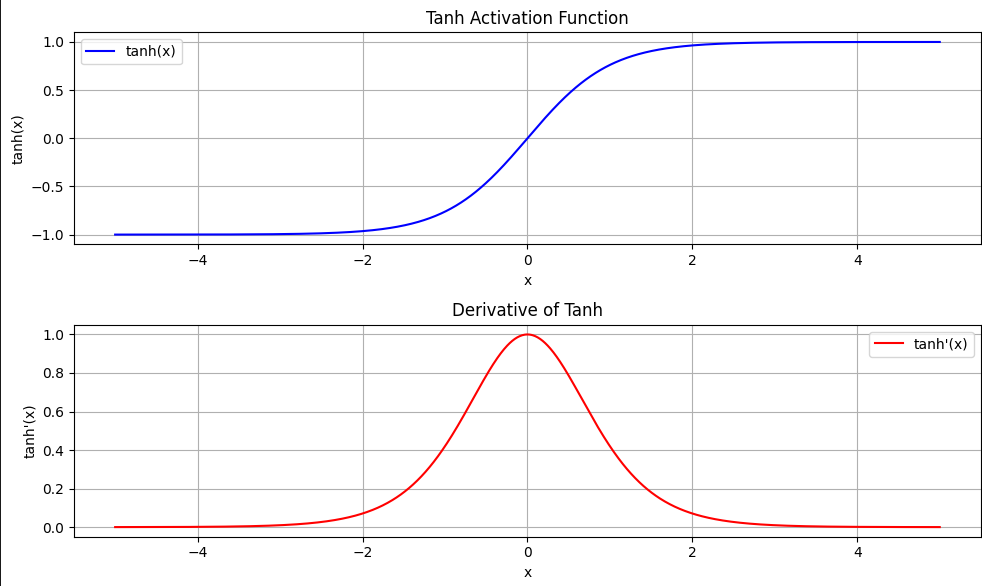
运行这段代码,你将看到两张图:
- 上图是tanh函数的S形曲线,从-1平滑过渡到1。
- 下图是其导数,呈现钟形曲线,在 ( x = 0 x = 0 x=0) 时达到峰值1,两侧迅速衰减。
Output
四、Tanh在深度学习中的应用与洞见
-
与Sigmoid的对比
tanh可以看作是Sigmoid函数的拉伸和偏移版本:
tanh ( x ) = 2 ⋅ sigmoid ( 2 x ) − 1 \text{tanh}(x) = 2 \cdot \text{sigmoid}(2x) - 1 tanh(x)=2⋅sigmoid(2x)−1
这种关系表明tanh本质上是Sigmoid的“零中心化”版本。因此,在需要零中心输出的场景(如RNN的隐藏层更新)中,tanh通常优于Sigmoid。 -
在RNN中的角色
在传统循环神经网络(RNN)中,tanh常被用作隐藏层的激活函数。原因在于其零中心性有助于保持梯度的稳定性,尤其是在处理时间序列数据时。然而,随着输入序列的加长,tanh的饱和问题会导致梯度消失,限制了其在长序列上的表现。这也促成了LSTM和GRU等结构的诞生,它们通过门机制缓解这一问题。 -
初始化策略的启示
使用tanh时,权重初始化的选择尤为重要。例如,Xavier初始化(Glorot初始化)通过控制输入和输出的方差,使得tanh的梯度在前向和反向传播中保持相对稳定。研究者可以进一步探索自适应初始化方法,以更好地匹配tanh的饱和特性。 -
与ReLU的权衡
相比于ReLU(Rectified Linear Unit),tanh在输入接近0时提供更平滑的非线性,但在饱和区域表现不佳。ReLU因其简单性和梯度传播能力在现代深度学习中更受欢迎。然而,在某些任务中(如生成模型或需要对称性的网络),tanh仍具有不可替代的优势。 -
深刻的洞见:tanh的“信息压缩”
tanh将输入压缩到 ( ( − 1 , 1 ) (-1, 1) (−1,1)) 区间,可以看作一种“信息标准化”的过程。这种压缩在某些场景下(如对抗生成网络GAN的生成器输出)非常有用,因为它强制输出符合某种分布约束。然而,这种压缩也可能丢失输入的动态范围,研究者需要权衡这种特性对模型表达能力的影响。
五、总结与展望
tanh激活函数凭借其零中心性、对称性和平滑的非线性,在深度学习早期扮演了重要角色。尽管在现代深度网络中,ReLU及其变种逐渐占据主导地位,但tanh在特定场景下仍有其独特的价值。研究者可以通过结合正则化、更好的初始化策略以及混合激活函数设计,进一步挖掘tanh的潜力。
通过本文的分析和可视化代码,希望读者能更深入地理解tanh的数学本质与应用场景,并在实践中找到适合其特性的任务。未来,随着激活函数设计的不断创新,tanh的经典思想或许会以新的形式融入深度学习的研究前沿。
后记
2025年3月24日13点43分于上海,在grok 3大模型辅助下完成。

















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









