









Rectified Flow:从直线路径到高效分布变换的深度学习新视角
引言
在深度学习领域,生成模型和分布变换任务(如图像生成、图像到图像翻译、域适应等)一直是研究的热点。传统的生成模型(如GAN和VAE)以及近年流行的扩散模型(Diffusion Models)在这些任务中取得了显著成果,但也面临着各自的挑战:GAN训练不稳定,扩散模型推理速度慢。2022年,来自德克萨斯大学奥斯汀分校的研究团队(Xingchao Liu, Chengyue Gong, Qiang Liu)提出了一种新颖的方法——Rectified Flow,通过普通微分方程(ODE)以直线路径为核心思想,统一解决了生成建模和域迁移问题。本文将深入探讨Rectified Flow的核心机制、数学公式及其在深度学习中的洞见。
下文中图片来自于原论文:https://arxiv.org/pdf/2209.03003
Rectified Flow的核心思想
Rectified Flow的核心在于通过学习一个神经ODE模型,将两个经验分布 π 0 \pi_0 π0 和 π 1 \pi_1 π1 之间的变换路径尽可能调整为直线路径。为什么选择直线路径?直线路径是两点间的最短路径,具有理论上的优越性(最优运输的几何直观性)和计算上的优势(可以精确模拟,不需过多时间离散化)。这使得Rectified Flow在推理阶段能够以极少的步骤(甚至一步)生成高质量结果,弥补了传统连续时间模型(如扩散模型)推理成本高的缺陷。
具体而言,Rectified Flow的目标是从 π 0 \pi_0 π0 到 π 1 \pi_1 π1 构建一个运输映射 T T T,使得 Z 0 ∼ π 0 Z_0 \sim \pi_0 Z0∼π0 时, Z 1 = T ( Z 0 ) ∼ π 1 Z_1 = T(Z_0) \sim \pi_1 Z1=T(Z0)∼π1。它通过以下步骤实现:
- 初始耦合:从 π 0 \pi_0 π0 和 π 1 \pi_1 π1 中抽样一对 ( X 0 , X 1 ) (X_0, X_1) (X0,X1),通常是独立的(即 ( X 0 , X 1 ) ∼ π 0 × π 1 (X_0, X_1) \sim \pi_0 \times \pi_1 (X0,X1)∼π0×π1)。
- 直线插值:定义线性插值路径 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1-t)X_0 Xt=tX1+(1−t)X0,其中 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1]。
- 学习漂移场:训练一个神经网络参数化的漂移函数 v ( z , t ) v(z,t) v(z,t),使ODE d Z t = v ( Z t , t ) d t \mathrm{d}Z_t = v(Z_t, t)\mathrm{d}t dZt=v(Zt,t)dt 的路径尽可能接近直线方向 X 1 − X 0 X_1 - X_0 X1−X0。
- 迭代校正(Reflow):通过递归应用校正过程,使路径越来越直,最终接近一步模型。
这种方法不仅适用于生成建模( π 0 \pi_0 π0 为噪声分布, π 1 \pi_1 π1 为数据分布),也适用于域迁移( π 0 \pi_0 π0 和 π 1 \pi_1 π1 为两个经验分布)。
数学公式与算法细节
基本定义
Rectified Flow的核心是一个ODE模型:
d
Z
t
=
v
(
Z
t
,
t
)
d
t
,
Z
0
∼
π
0
,
Z
1
∼
π
1
\mathrm{d}Z_t = v(Z_t, t) \mathrm{d}t, \quad Z_0 \sim \pi_0, \quad Z_1 \sim \pi_1
dZt=v(Zt,t)dt,Z0∼π0,Z1∼π1
其中
v
(
z
,
t
)
v(z,t)
v(z,t) 是漂移函数,表示在时间
t
t
t 和位置
z
z
z 处的速度场。目标是让
Z
t
Z_t
Zt 的轨迹尽量接近
X
1
−
X
0
X_1 - X_0
X1−X0 的方向。
优化目标
为了学习
v
(
z
,
t
)
v(z,t)
v(z,t),Rectified Flow通过一个简单的非线性最小二乘问题定义优化目标:
min
v
∫
0
1
E
[
∥
(
X
1
−
X
0
)
−
v
(
X
t
,
t
)
∥
2
2
]
d
t
,
X
t
=
t
X
1
+
(
1
−
t
)
X
0
\min_v \int_0^1 \mathbb{E}\left[ \left\| (X_1 - X_0) - v(X_t, t) \right\|_2^2 \right] \mathrm{d}t, \quad X_t = t X_1 + (1-t) X_0
vmin∫01E[∥(X1−X0)−v(Xt,t)∥22]dt,Xt=tX1+(1−t)X0
这里:
- X t X_t Xt 是 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 的线性插值,表示理想的直线路径。
- ( X 1 − X 0 ) (X_1 - X_0) (X1−X0) 是直线方向的速度。
- v ( X t , t ) v(X_t, t) v(Xt,t) 是模型预测的速度,目标是让它尽量接近 ( X 1 − X 0 ) (X_1 - X_0) (X1−X0)。
优化过程使用随机梯度下降(SGD)或Adam等方法,基于 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 的经验样本训练神经网络 v θ ( z , t ) v_\theta(z,t) vθ(z,t)。
理论最优解
如果优化问题能精确求解,最优的漂移场为:
v
X
(
z
,
t
)
=
E
[
X
1
−
X
0
∣
X
t
=
z
]
v^X(z, t) = \mathbb{E}\left[ X_1 - X_0 \mid X_t = z \right]
vX(z,t)=E[X1−X0∣Xt=z]
这表示在时间
t
t
t 和位置
z
z
z 处,所有经过
z
z
z 的直线方向
(
X
1
−
X
0
)
(X_1 - X_0)
(X1−X0) 的条件期望。直观上,
v
X
(
z
,
t
)
v^X(z,t)
vX(z,t) 将线性插值路径“因果化”,避免了交叉(见下文非交叉性质)。
非交叉性质
ODE的解具有唯一性,因此
Z
t
Z_t
Zt 的轨迹不会交叉。这与
X
t
X_t
Xt 的线性插值路径(可能交叉)形成对比。Rectified Flow通过“重新布线”(rewiring)避免交叉,同时保持边际分布一致:
Law
(
Z
t
)
=
Law
(
X
t
)
,
∀
t
∈
[
0
,
1
]
\text{Law}(Z_t) = \text{Law}(X_t), \quad \forall t \in [0,1]
Law(Zt)=Law(Xt),∀t∈[0,1]
运输成本下降
Rectified Flow的一个重要理论性质是,它将任意耦合
(
X
0
,
X
1
)
(X_0, X_1)
(X0,X1) 转换为确定性耦合
(
Z
0
,
Z
1
)
(Z_0, Z_1)
(Z0,Z1),且对于所有凸成本函数
c
c
c,运输成本不增加:
E
[
c
(
Z
1
−
Z
0
)
]
≤
E
[
c
(
X
1
−
X
0
)
]
\mathbb{E}\left[ c(Z_1 - Z_0) \right] \leq \mathbb{E}\left[ c(X_1 - X_0) \right]
E[c(Z1−Z0)]≤E[c(X1−X0)]
例如,当
c
(
x
)
=
∥
x
∥
c(x) = \|x\|
c(x)=∥x∥ 时,
Z
t
Z_t
Zt 的路径长度不会超过
X
t
X_t
Xt 的直线长度(三角不等式)。
Reflow与路径变直
为了进一步接近直线路径,论文提出了递归校正(Reflow)过程:
- 从初始耦合 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 训练第一个Rectified Flow Z 1 Z^1 Z1。
- 模拟 Z 1 Z^1 Z1 得到新耦合 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11)。
- 用 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11) 训练 Z 2 Z^2 Z2,重复此过程。
路径直线性用以下指标衡量:
S
(
Z
)
=
∫
0
1
E
[
∥
(
Z
1
−
Z
0
)
−
Z
˙
t
∥
2
]
d
t
S(Z) = \int_0^1 \mathbb{E}\left[ \left\| (Z_1 - Z_0) - \dot{Z}_t \right\|^2 \right] \mathrm{d}t
S(Z)=∫01E[
(Z1−Z0)−Z˙t
2]dt
S
(
Z
)
=
0
S(Z) = 0
S(Z)=0 表示完全直线。理论上,
S
(
Z
k
)
S(Z^k)
S(Zk) 随
k
k
k 增加而减小:
min
k
∈
{
0
,
…
,
K
}
S
(
Z
k
)
≤
E
[
∥
X
1
−
X
0
∥
2
]
K
\min_{k \in \{0, \dots, K\}} S(Z^k) \leq \frac{\mathbb{E}\left[ \|X_1 - X_0\|^2 \right]}{K}
k∈{0,…,K}minS(Zk)≤KE[∥X1−X0∥2]
实验表明,一次Reflow(
k
=
2
k=2
k=2)即可显著提高直线性。
算法伪代码
以下是训练和采样的核心算法(参考论文Algorithm 1):
# 训练
def Train(Data):
# Data = {(x0, x1)} 从 π_0 × π_1 采样
initialize v_θ(z, t)
for (x0, x1) in Data:
t ~ Uniform([0, 1])
x_t = t * x1 + (1 - t) * x0
loss = ||v_θ(x_t, t) - (x1 - x0)||^2.mean()
optimize(loss)
return v_θ
# 采样
def Sample(v_θ, x0):
# x0 ~ π_0
z_t = ODE_solve(v_θ, z_0 = x0, t ∈ [0, 1])
return (z_0, z_1)
# Reflow
def Reflow(Data, K):
coupling = Data
for k in range(K):
v_θ = Train(coupling)
coupling = Sample(v_θ, {x0 from coupling})
return coupling
实验结果与应用
-
图像生成:
- 在CIFAR-10上,2-Rectified Flow一步生成(Euler步长 N = 1 N=1 N=1)的FID达到4.85,优于传统一步模型(如GAN的8.91)。
- 在高分辨率数据集(如LSUN、CelebA HQ)上,1-Rectified Flow也能生成高质量图像。
-
图像到图像翻译:
- 在无配对数据的情况下(如人脸到猫脸),通过调整损失函数(考虑特征映射 h ( x ) h(x) h(x)),Rectified Flow生成视觉上高质量的混合图像。
- 2-Rectified Flow一步即可完成风格迁移。
-
域适应:
- 在DomainNet和OfficeHome数据集上,Rectified Flow将测试域迁移到训练域,分类准确率达到state-of-the-art(69.2% 和 41.4%)。
与其他方法的对比
-
与GAN的对比:
- GAN通过对抗训练学习映射,易出现模式崩塌和不稳定。Rectified Flow用简单的回归优化,避免了这些问题。
-
与扩散模型的对比:
- 扩散模型(如DDPM)依赖SDE,推理需要数百步。Rectified Flow是纯ODE方法,通过直线路径大幅减少推理步骤。
- 论文证明,概率流ODE(PF-ODE)和DDIM是Rectified Flow的非线性特例,但路径非直且速度不均。
洞见与启发
-
直线路径的哲学意义:
- Rectified Flow揭示了分布变换的最优性可能不依赖复杂的曲线路径。直线路径不仅是计算上的捷径,也可能是数据分布间联系的本质体现。这提示我们在设计生成模型时,应优先考虑几何简单性。
-
因果性与确定性:
- 通过将非因果的线性插值“因果化”,Rectified Flow将随机耦合转化为确定性耦合。这为理解生成过程的因果结构提供了新视角。
-
Reflow的潜力:
- Reflow过程类似于“自蒸馏”,通过迭代优化逼近一步模型。这种策略可能适用于其他连续时间模型(如扩散模型),以提升推理效率。
-
扩展性思考:
- 论文提到非线性扩展(用任意曲线替换线性插值),这为引入非欧几何(如流形上的变换)提供了可能。未来研究可探索如何结合领域知识设计 X t X_t Xt。
结论
Rectified Flow以其简洁而优雅的设计,为生成建模和分布变换任务提供了一个统一的、高效的解决方案。它通过直线路径和递归校正,不仅在理论上保证了边际分布一致性和运输成本下降,还在实践中实现了快速推理和高性能。对于深度学习研究者而言,这不仅是一种新工具,更是一种新思路:简单性与效率的结合,往往能带来意想不到的突破。
分布沿直线或曲线变化的意义和边际分布(Marginal Distribution)的含义。
由于篇幅限制,具体的内容可以参考笔者的另一篇博客:Rectified Flow(二):边际分布(Marginal Distribution)的作用, 主要内容有:分布沿直线或曲线变化的意义和边际分布(Marginal Distribution)的含义。
理解Figure 2
Figure 2 是 Rectified Flow 方法的核心可视化示例,旨在展示如何从初始的线性插值路径(可能有交叉)逐步校正为更直、更符合 ODE 性质的路径。让我们一步步拆解。
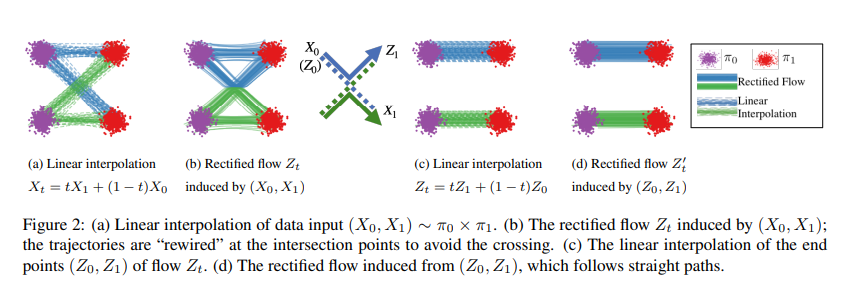
Figure 2 的背景和目标
Rectified Flow 的目标是通过普通微分方程(ODE)从分布 π 0 \pi_0 π0 变换到分布 π 1 \pi_1 π1,并且希望变换路径尽量接近直线路径。直线路径有两大优势:
- 最短路径:直线是两点间的最短路径,理论上运输成本最低。
- 计算效率:直线路径可以用一步模拟(无需多步离散化)。
然而,初始的线性插值路径 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0(从 X 0 ∼ π 0 X_0 \sim \pi_0 X0∼π0 到 X 1 ∼ π 1 X_1 \sim \pi_1 X1∼π1)可能会出现轨迹交叉(crossing),这不符合 ODE 的非交叉性质(因为 ODE 的解是唯一的,轨迹不能交叉)。Figure 2 通过四个子图展示了 Rectified Flow 如何通过“校正”(rectification)和“重新布线”(rewiring)解决这个问题,并逐步将路径变直。
Figure 2 的四个子图
(a) Linear interpolation X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0
- 内容:图中展示了两个分布 π 0 \pi_0 π0(紫色点)和 π 1 \pi_1 π1(红色点),每个点对 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 之间用一条线连接,表示线性插值路径 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0。
- 关键点:这些路径会交叉。例如,图中两条路径(绿色和蓝色)在中间相交,形成了 X 0 → X 1 X_0 \rightarrow X_1 X0→X1 和 X 0 ′ → X 1 ′ X_0' \rightarrow X_1' X0′→X1′ 的交叉。
- 问题:这种交叉是非因果的(non-causal),因为线性插值需要同时知道起点 X 0 X_0 X0 和终点 X 1 X_1 X1,而 ODE 要求路径是因果的(只依赖当前状态 Z t Z_t Zt 和时间 t t t)。
直观解释:
想象
π
0
\pi_0
π0 和
π
1
\pi_1
π1 是两个城市群,每对
(
X
0
,
X
1
)
(X_0, X_1)
(X0,X1) 是一条直线公路。但这些公路可能会交叉(比如在某个点
X
t
X_t
Xt 上,绿色和蓝色路径重合但方向不同)。这会导致“交通混乱”,因为 ODE 要求每条路径在任何时刻都不能交叉,否则解就不唯一。
(b) Rectified flow Z t Z_t Zt induced by ( X 0 , X 1 ) (X_0, X_1) (X0,X1)
- 内容:这一步展示了 Rectified Flow 对 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 的第一次校正,生成新的路径 Z t Z_t Zt,由 ODE d Z t = v ( Z t , t ) d t \mathrm{d}Z_t = v(Z_t, t) \mathrm{d}t dZt=v(Zt,t)dt 定义。
- 关键点: Z t Z_t Zt 的轨迹在交叉点被“重新布线”(rewired)。图中可以看到,绿色和蓝色路径在交叉点 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 被重新配对,避免了交叉。原来的 X 0 → X 1 X_0 \rightarrow X_1 X0→X1 和 X 0 ′ → X 1 ′ X_0' \rightarrow X_1' X0′→X1′ 变成了 Z 0 → Z 1 Z_0 \rightarrow Z_1 Z0→Z1 和 Z 0 ′ → Z 1 ′ Z_0' \rightarrow Z_1' Z0′→Z1′。
- 非交叉性质:ODE 的解是唯一的,因此
Z
t
Z_t
Zt 的轨迹不能交叉。论文中提到:
A key to understanding the method is the non-crossing property of flows: the different paths following a well-defined ODE d Z t = v ( Z t , t ) d t \mathrm{d}Z_t = v(Z_t, t) \mathrm{d}t dZt=v(Zt,t)dt, whose solution exists and is unique, cannot cross each other at any time t ∈ [ 0 , 1 ) t \in [0,1) t∈[0,1).
直观解释:
继续用公路的比喻,Rectified Flow 在交叉点设置了“交通规则”,将原本交叉的公路重新规划为不交叉的路径(比如通过立交桥)。这使得每条路径
Z
t
Z_t
Zt 都能独立前进,不会与其他路径冲突。
技术细节:
-
v
(
z
,
t
)
v(z, t)
v(z,t) 是通过优化以下目标学习的:
min v ∫ 0 1 E [ ∥ ( X 1 − X 0 ) − v ( X t , t ) ∥ 2 2 ] d t \min_v \int_0^1 \mathbb{E}\left[ \| (X_1 - X_0) - v(X_t, t) \|_2^2 \right] \mathrm{d}t vmin∫01E[∥(X1−X0)−v(Xt,t)∥22]dt - 最优解为 v X ( z , t ) = E [ X 1 − X 0 ∣ X t = z ] v^X(z, t) = \mathbb{E}[X_1 - X_0 \mid X_t = z] vX(z,t)=E[X1−X0∣Xt=z],表示在 X t = z X_t = z Xt=z 时,所有直线方向的条件期望。
( c) Linear interpolation Z t = t Z 1 + ( 1 − t ) Z 0 Z_t = t Z_1 + (1 - t) Z_0 Zt=tZ1+(1−t)Z0
- 内容:这一步用前一步生成的 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 作为新的起点和终点,再次进行线性插值,生成路径 Z t = t Z 1 + ( 1 − t ) Z 0 Z_t = t Z_1 + (1 - t) Z_0 Zt=tZ1+(1−t)Z0。
- 关键点:由于 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 已经是校正后的配对,新的线性插值路径仍然可能有交叉,但相比于 ( X 0 , X 1 ) (X_0, X_1) (X0,X1),交叉的程度已经减少。
直观解释:
这一步相当于用新的城市对
(
Z
0
,
Z
1
)
(Z_0, Z_1)
(Z0,Z1) 重新规划公路。新的公路仍然是直线,但因为
(
Z
0
,
Z
1
)
(Z_0, Z_1)
(Z0,Z1) 已经经过一次校正,交叉问题有所缓解。
(d) Rectified flow Z t ′ Z_t' Zt′ induced by ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1)
- 内容:对 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 再次应用 Rectified Flow,生成新的路径 Z t ′ Z_t' Zt′。
- 关键点:图中显示, Z t ′ Z_t' Zt′ 的轨迹已经非常接近直线,几乎没有交叉。路径变得更“直”(straight),这是 Reflow 过程的结果。
- 意义:通过递归校正(Reflow),路径越来越直,最终接近一步模型(single-step model),即 Z 1 = Z 0 + v ( Z 0 , 0 ) Z_1 = Z_0 + v(Z_0, 0) Z1=Z0+v(Z0,0)。
直观解释:
经过第二次规划,公路几乎完全没有交叉,变成了近似直线的路径。这意味着从
Z
0
Z_0
Z0 到
Z
1
Z_1
Z1 的变换可以用一步完成,极大提高了计算效率。
技术细节:
- 直线性用以下指标衡量:
S ( Z ) = ∫ 0 1 E [ ∥ ( Z 1 − Z 0 ) − Z ˙ t ∥ 2 2 ] d t S(\boldsymbol{Z}) = \int_0^1 \mathbb{E}\left[ \| (Z_1 - Z_0) - \dot{Z}_t \|_2^2 \right] \mathrm{d}t S(Z)=∫01E[∥(Z1−Z0)−Z˙t∥22]dt - S ( Z ) = 0 S(\boldsymbol{Z}) = 0 S(Z)=0 表示完全直线。Reflow 过程会逐步减小 S ( Z ) S(\boldsymbol{Z}) S(Z)。
Figure 2 的整体含义
从 (a) 到 (d) 的演化
- (a):初始线性插值 X t X_t Xt,路径有交叉,非因果。
- (b):第一次校正,生成 Z t Z_t Zt,通过重新布线避免交叉。
- ( c):用校正后的 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 再次线性插值,交叉减少。
- (d):第二次校正,生成 Z t ′ Z_t' Zt′,路径几乎完全直线。
核心思想
Figure 2 展示了 Rectified Flow 的核心机制:
- 非交叉性:ODE 路径不能交叉,Rectified Flow 通过“重新布线”解决线性插值的交叉问题。
- 路径变直:通过递归校正(Reflow),路径从可能交叉的复杂状态逐步变为直线状态。
- 效率提升:直线路径可以一步模拟,减少推理成本。
论文中的解释
论文在 Figure 2 的标题中提到:
The trajectories are “rewired” at the intersection points to avoid the crossing. (…) The rectified flow induced from ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1), which follows straight paths.
翻译为中文:
轨迹在交叉点被“重新布线”以避免交叉。(…) 由 ( Z 0 , Z 1 ) (Z_0, Z_1) (Z0,Z1) 诱导的校正流,遵循直线路径。
这强调了 Rectified Flow 的两个关键性质:避免交叉和路径变直。
结合上下文的意义
为什么要避免交叉?
在概率分布变换中,交叉会导致路径的非确定性(non-determinism)。例如,假设 X t X_t Xt 在某个点 z z z 处交叉,绿色路径和蓝色路径在 t = 0.5 t = 0.5 t=0.5 时都经过 z z z,但方向不同(比如一个向右,一个向左)。这会导致 ODE 的解不唯一(因为 v ( z , t ) v(z, t) v(z,t) 无法确定方向),违反了 ODE 的基本性质。Rectified Flow 通过 v ( z , t ) v(z, t) v(z,t) 的设计(条件期望)确保路径不交叉。
为什么追求直线?
- 理论上:直线是最短路径,运输成本最低(论文中提到降低了凸运输成本)。
- 实践上:直线路径可以用一步 Euler 步模拟( Z 1 = Z 0 + v ( Z 0 , 0 ) Z_1 = Z_0 + v(Z_0, 0) Z1=Z0+v(Z0,0)),相比于扩散模型(需要数百步)效率更高。
实际应用
- 在图像生成中,直线路径意味着从噪声到图像的变换更直接,中间状态更可控。
- 在域迁移中,直线路径使得从源域到目标域的风格转换更平滑。
总结
Figure 2 是一个简化的二维玩具示例,展示了 Rectified Flow 如何从初始的交叉路径(线性插值)逐步校正为不交叉、近似直线的路径:
- (a) 展示了问题:线性插值会导致交叉。
- (b) 展示了第一次校正:通过重新布线避免交叉。
- (c ) 展示了中间步骤:用校正后的点对重新插值。
- (d) 展示了最终结果:路径几乎完全直线。
这个过程体现了 Rectified Flow 的核心思想:通过递归校正,将复杂的变换路径简化为直线路径,从而实现高效的分布变换。
Reflow的过程
详细介绍 Rectified Flow 论文中提出的 Reflow 过程,包括它的目标、具体步骤、数学原理、算法实现,以及在实际应用中的作用。Reflow 是 Rectified Flow 的核心技术之一,通过递归校正(recursive rectification)将初始的变换路径逐步调整为更直的路径,从而实现高效的一步生成或分布变换。
Reflow 的目标
Rectified Flow 的目标是从分布 π 0 \pi_0 π0 变换到分布 π 1 \pi_1 π1,并希望变换路径尽量接近直线路径。直线路径的优势在于:
- 最优运输:直线是两点间的最短路径,理论上运输成本最低。
- 高效推理:直线路径可以用一步模拟(single-step sampling),相比于传统连续时间模型(如扩散模型需要数百步)更高效。
然而,初始的 Rectified Flow(称为 1-Rectified Flow)生成的路径 Z t Z_t Zt 可能不是完全直线,因为:
- 初始耦合 ( X 0 , X 1 ) ∼ π 0 × π 1 (X_0, X_1) \sim \pi_0 \times \pi_1 (X0,X1)∼π0×π1 是独立采样的,路径可能交叉。
- 神经网络 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 是对最优漂移场 v X ( z , t ) v^X(z, t) vX(z,t) 的近似,可能无法完全捕捉直线方向 X 1 − X 0 X_1 - X_0 X1−X0。
Reflow 的目标是通过递归应用 Rectified Flow,将路径 Z t Z_t Zt 逐步“变直”,最终接近一步模型(即 Z 1 = Z 0 + v ( Z 0 , 0 ) Z_1 = Z_0 + v(Z_0, 0) Z1=Z0+v(Z0,0)),同时保持边际分布 Law ( Z t ) \text{Law}(Z_t) Law(Zt) 不变。
Reflow 的核心思想
Reflow 的核心思想是迭代校正:
- 从初始耦合 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 训练第一个 Rectified Flow,生成路径 Z t 1 Z^1_t Zt1 和新耦合 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11)。
- 用 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11) 作为新的训练数据,训练第二个 Rectified Flow,生成 Z t 2 Z^2_t Zt2 和 ( Z 0 2 , Z 1 2 ) (Z_0^2, Z_1^2) (Z02,Z12)。
- 重复此过程 K K K 次,直到路径足够直。
每次校正(Reflow 一步)都会使路径更接近直线,减少路径的“弯曲度”(quantified by the straightness metric S ( Z ) S(\boldsymbol{Z}) S(Z))。
直线性指标
论文中定义了路径的直线性指标:
S
(
Z
)
=
∫
0
1
E
[
∥
(
Z
1
−
Z
0
)
−
Z
˙
t
∥
2
2
]
d
t
S(\boldsymbol{Z}) = \int_0^1 \mathbb{E}\left[ \| (Z_1 - Z_0) - \dot{Z}_t \|_2^2 \right] \mathrm{d}t
S(Z)=∫01E[∥(Z1−Z0)−Z˙t∥22]dt
- ( Z 1 − Z 0 ) (Z_1 - Z_0) (Z1−Z0) 是理想的直线速度方向。
- Z ˙ t = v ( Z t , t ) \dot{Z}_t = v(Z_t, t) Z˙t=v(Zt,t) 是实际的速度。
- S ( Z ) = 0 S(\boldsymbol{Z}) = 0 S(Z)=0 表示路径完全直线。
Reflow 的目标是逐步减小 S ( Z ) S(\boldsymbol{Z}) S(Z),使路径越来越直。
Reflow 的具体步骤
1. 初始耦合
Reflow 从初始的样本对 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 开始,其中:
- X 0 ∼ π 0 X_0 \sim \pi_0 X0∼π0, X 1 ∼ π 1 X_1 \sim \pi_1 X1∼π1。
- 初始耦合 ( X 0 , X 1 ) ∼ π 0 × π 1 (X_0, X_1) \sim \pi_0 \times \pi_1 (X0,X1)∼π0×π1,即 X 0 X_0 X0 和 X 1 X_1 X1 是独立采样的。
2. 第一次 Rectified Flow(1-Rectified Flow)
- 训练:用
(
X
0
,
X
1
)
(X_0, X_1)
(X0,X1) 训练第一个漂移场
v
θ
1
(
z
,
t
)
v_\theta^1(z, t)
vθ1(z,t),优化目标为:
min v θ 1 ∫ 0 1 E [ ∥ ( X 1 − X 0 ) − v θ 1 ( X t , t ) ∥ 2 2 ] d t , X t = t X 1 + ( 1 − t ) X 0 \min_{v_\theta^1} \int_0^1 \mathbb{E}\left[ \| (X_1 - X_0) - v_\theta^1(X_t, t) \|_2^2 \right] \mathrm{d}t, \quad X_t = t X_1 + (1 - t) X_0 vθ1min∫01E[∥(X1−X0)−vθ1(Xt,t)∥22]dt,Xt=tX1+(1−t)X0 - 采样:用训练好的
v
θ
1
(
z
,
t
)
v_\theta^1(z, t)
vθ1(z,t) 解决 ODE:
d Z t 1 = v θ 1 ( Z t 1 , t ) d t , Z 0 1 ∼ π 0 \mathrm{d}Z_t^1 = v_\theta^1(Z_t^1, t) \mathrm{d}t, \quad Z_0^1 \sim \pi_0 dZt1=vθ1(Zt1,t)dt,Z01∼π0
得到 Z t 1 Z_t^1 Zt1 的轨迹,并生成新耦合 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11),其中 Z 0 1 ∼ π 0 Z_0^1 \sim \pi_0 Z01∼π0, Z 1 1 ∼ π 1 Z_1^1 \sim \pi_1 Z11∼π1。
3. 第二次 Rectified Flow(2-Rectified Flow)
- 训练:用
(
Z
0
1
,
Z
1
1
)
(Z_0^1, Z_1^1)
(Z01,Z11) 作为新的训练数据,训练第二个漂移场
v
θ
2
(
z
,
t
)
v_\theta^2(z, t)
vθ2(z,t),优化目标为:
min v θ 2 ∫ 0 1 E [ ∥ ( Z 1 1 − Z 0 1 ) − v θ 2 ( Z t 1 , t ) ∥ 2 2 ] d t , Z t 1 = t Z 1 1 + ( 1 − t ) Z 0 1 \min_{v_\theta^2} \int_0^1 \mathbb{E}\left[ \| (Z_1^1 - Z_0^1) - v_\theta^2(Z_t^1, t) \|_2^2 \right] \mathrm{d}t, \quad Z_t^1 = t Z_1^1 + (1 - t) Z_0^1 vθ2min∫01E[∥(Z11−Z01)−vθ2(Zt1,t)∥22]dt,Zt1=tZ11+(1−t)Z01 - 采样:用
v
θ
2
(
z
,
t
)
v_\theta^2(z, t)
vθ2(z,t) 解决 ODE:
d Z t 2 = v θ 2 ( Z t 2 , t ) d t , Z 0 2 ∼ π 0 \mathrm{d}Z_t^2 = v_\theta^2(Z_t^2, t) \mathrm{d}t, \quad Z_0^2 \sim \pi_0 dZt2=vθ2(Zt2,t)dt,Z02∼π0
得到 ( Z 0 2 , Z 1 2 ) (Z_0^2, Z_1^2) (Z02,Z12)。
4. 重复 K K K 次
- 重复上述过程 K K K 次,每次用前一步的 ( Z 0 k , Z 1 k ) (Z_0^k, Z_1^k) (Z0k,Z1k) 训练 v θ k + 1 ( z , t ) v_\theta^{k+1}(z, t) vθk+1(z,t),生成 ( Z 0 k + 1 , Z 1 k + 1 ) (Z_0^{k+1}, Z_1^{k+1}) (Z0k+1,Z1k+1)。
- 理论上, S ( Z k ) S(\boldsymbol{Z}^k) S(Zk) 随 k k k 增加而减小,路径越来越直。
5. 最终结果
- 经过
K
K
K 次 Reflow,路径接近完全直线,变换可以用一步完成:
Z 1 K ≈ Z 0 K + v θ K ( Z 0 K , 0 ) Z_1^K \approx Z_0^K + v_\theta^K(Z_0^K, 0) Z1K≈Z0K+vθK(Z0K,0)
数学原理:为什么 Reflow 能让路径变直?
理论保证
论文中的 Theorem 3.5 提供了 Reflow 的理论支持:
Let Z k \boldsymbol{Z}^k Zk be the k k k-th rectified flow induced by X 0 = X \boldsymbol{X}^0 = \boldsymbol{X} X0=X. Then for any K ≥ 1 K \geq 1 K≥1, we have:
min k ∈ { 0 , … , K } S ( Z k ) ≤ E [ ∥ X 1 − X 0 ∥ 2 ] K \min_{k \in \{0, \dots, K\}} S(\boldsymbol{Z}^k) \leq \frac{\mathbb{E}\left[ \|X_1 - X_0\|^2 \right]}{K} k∈{0,…,K}minS(Zk)≤KE[∥X1−X0∥2]
- 含义: S ( Z k ) S(\boldsymbol{Z}^k) S(Zk)(直线性指标)会随着 Reflow 次数 K K K 增加而减小,下降速度接近 1 / K 1/K 1/K。
- 直观解释:每次 Reflow 都让路径更接近直线,最终 S ( Z k ) → 0 S(\boldsymbol{Z}^k) \to 0 S(Zk)→0,即路径完全直。
非交叉性质
每次 Reflow 生成的 Z t k Z_t^k Ztk 由 ODE 定义,轨迹不会交叉(因为 ODE 的解唯一)。这使得 ( Z 0 k , Z 1 k ) (Z_0^k, Z_1^k) (Z0k,Z1k) 的耦合比前一步更“确定性”(deterministic),路径更接近直线。
边际分布保持
论文证明了 Law ( Z t k ) = Law ( X t ) \text{Law}(Z_t^k) = \text{Law}(X_t) Law(Ztk)=Law(Xt)(定理3.3),即每次 Reflow 不会改变边际分布,只是调整了路径的几何形状。
算法实现
论文中的 Algorithm 1 提供了 Reflow 的伪代码,将其整理为更详细的实现:
# 训练 Rectified Flow
def train_rectified_flow(coupling, num_epochs):
# coupling: 样本对 {(x0, x1)}
v_theta = initialize_neural_network() # 初始化漂移场 v_θ(z, t)
for epoch in range(num_epochs):
for (x0, x1) in coupling:
t = random.uniform(0, 1) # 随机采样 t
x_t = t * x1 + (1 - t) * x0 # 线性插值
target_velocity = x1 - x0 # 目标速度
predicted_velocity = v_theta(x_t, t) # 预测速度
loss = ((predicted_velocity - target_velocity) ** 2).mean() # 均方误差
optimize(loss) # 用 SGD 或 Adam 优化
return v_theta
# 用 Rectified Flow 采样
def sample_rectified_flow(v_theta, x0, num_steps=100):
# x0: 初始样本
z_t = x0
dt = 1.0 / num_steps
for step in range(num_steps):
t = step * dt
z_t = z_t + v_theta(z_t, t) * dt # Euler 积分
return z_t
# Reflow 过程
def reflow(initial_coupling, K, num_epochs_per_flow):
# initial_coupling: 初始样本对 {(x0, x1)} ~ π_0 × π_1
coupling = initial_coupling
for k in range(K):
# 训练第 k 次 Rectified Flow
v_theta = train_rectified_flow(coupling, num_epochs_per_flow)
# 用训练好的 v_theta 采样新耦合
new_coupling = []
for (x0, _) in coupling:
z1 = sample_rectified_flow(v_theta, x0) # 从 x0 采样 z1
new_coupling.append((x0, z1))
coupling = new_coupling # 更新耦合
return coupling, v_theta
# 示例使用
initial_coupling = [(x0, x1) for x0, x1 in zip(pi_0_samples, pi_1_samples)] # 初始样本对
K = 2 # Reflow 次数
num_epochs_per_flow = 1000 # 每次训练的 epoch 数
final_coupling, final_v_theta = reflow(initial_coupling, K, num_epochs_per_flow)
代码说明
- train_rectified_flow:训练一个 Rectified Flow,通过最小化预测速度与目标速度的均方误差。
- sample_rectified_flow:用训练好的 v θ v_\theta vθ 采样新路径,生成 ( Z 0 k , Z 1 k ) (Z_0^k, Z_1^k) (Z0k,Z1k)。
- reflow:递归调用训练和采样,逐步校正路径。
Reflow 的实际效果
实验结果
论文中的实验表明:
-
图像生成:
- 在 CIFAR-10 上,1-Rectified Flow(无 Reflow)的 FID 为 9.23,2-Rectified Flow(一次 Reflow)降低到 4.85。
- 一步生成(single-step)即可达到高质量结果,相比于扩散模型(需要数百步)效率更高。
-
域迁移:
- 在 DomainNet 数据集上,2-Rectified Flow 提升了分类准确率(从 67.8% 到 69.2%)。
- 路径变直使得从源域到目标域的变换更平滑。
路径直线性
- 初始路径 S ( X ) S(\boldsymbol{X}) S(X) 较高(路径弯曲)。
- 经过 1 次 Reflow, S ( Z 1 ) S(\boldsymbol{Z}^1) S(Z1) 显著减小。
- 经过 2 次 Reflow, S ( Z 2 ) S(\boldsymbol{Z}^2) S(Z2) 接近 0,路径几乎完全直线。
Reflow 的直观解释
类比:公路规划
想象 π 0 \pi_0 π0 和 π 1 \pi_1 π1 是两个城市群, ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 是城市之间的公路:
- 初始:公路是直线,但会交叉(交通混乱)。
- 第一次 Reflow:在交叉点设置立交桥(重新布线),避免交叉。
- 第二次 Reflow:进一步优化路线,使公路更直,减少绕行。
类比:自蒸馏
Reflow 类似于“自蒸馏”(self-distillation):
- 每次 Reflow 用前一步的输出作为新输入,逐步提纯路径。
- 最终路径接近一步模型,类似于“知识蒸馏”中的学生模型逼近教师模型。
Reflow 的优势与局限
优势
- 路径优化:逐步将路径变直,降低运输成本。
- 高效推理:最终模型可以用一步生成,适用于实时应用。
- 通用性:适用于生成建模、域迁移、图像到图像翻译等任务。
局限
- 计算成本:每次 Reflow 需要重新训练一个神经网络,训练成本随 K K K 增加。
- 超参数: K K K 的选择需要实验调整(论文中通常用 K = 2 K=2 K=2)。
- 初始耦合依赖:初始 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 的质量会影响 Reflow 的效果。
总结
Reflow 是 Rectified Flow 的核心技术,通过递归校正逐步将路径变直。其过程包括:
- 从初始耦合 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 训练第一个 Rectified Flow。
- 用生成的 ( Z 0 1 , Z 1 1 ) (Z_0^1, Z_1^1) (Z01,Z11) 训练第二个 Rectified Flow。
- 重复 K K K 次,直到路径接近直线。
Reflow 的理论支持在于直线性指标 S ( Z ) S(\boldsymbol{Z}) S(Z) 的下降,实际效果在于显著提升生成质量和推理效率。对于深度学习研究者,Reflow 提供了一个优雅的迭代优化框架,值得进一步探索和扩展。
Nonlinear Extension
详细介绍《Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow》论文中的 2.3 A Nonlinear Extension 和 3.5 Denoising Diffusion Models and Probability Flow ODEs 两个部分,包括核心思想、数学公式和意义。这两个部分分别探讨了 Rectified Flow 的扩展性以及它与扩散模型(Diffusion Models)的关系。
2.3 A Nonlinear Extension
背景
Rectified Flow 的核心思想是基于线性插值路径 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0,通过学习漂移场 v ( z , t ) v(z, t) v(z,t) 使 ODE 路径 Z t Z_t Zt 尽量接近直线方向 X 1 − X 0 X_1 - X_0 X1−X0。然而,线性插值是一种简单的路径选择,可能不是最优的,尤其是在复杂的高维数据分布上。2.3 A Nonlinear Extension 部分提出了一种非线性扩展,允许用更一般的路径替换线性插值,从而增加模型的灵活性。
核心思想
非线性扩展的核心是将线性插值 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0 替换为一个非线性路径 X t = ϕ t ( X 0 , X 1 ) X_t = \phi_t(X_0, X_1) Xt=ϕt(X0,X1),其中 ϕ t \phi_t ϕt 是一个参数化的函数,满足:
- ϕ 0 ( X 0 , X 1 ) = X 0 \phi_0(X_0, X_1) = X_0 ϕ0(X0,X1)=X0
- ϕ 1 ( X 0 , X 1 ) = X 1 \phi_1(X_0, X_1) = X_1 ϕ1(X0,X1)=X1
目标仍然是让 Z t Z_t Zt 的路径接近 X ˙ t \dot{X}_t X˙t,但 X ˙ t \dot{X}_t X˙t 不再是恒定的 X 1 − X 0 X_1 - X_0 X1−X0,而是随时间 t t t 变化的非线性速度。
数学公式
-
非线性路径:
X t = ϕ t ( X 0 , X 1 ) X_t = \phi_t(X_0, X_1) Xt=ϕt(X0,X1)
其中 ϕ t : R d × R d → R d \phi_t: \mathbb{R}^d \times \mathbb{R}^d \to \mathbb{R}^d ϕt:Rd×Rd→Rd 是一个平滑函数,满足边界条件:
ϕ 0 ( X 0 , X 1 ) = X 0 , ϕ 1 ( X 0 , X 1 ) = X 1 \phi_0(X_0, X_1) = X_0, \quad \phi_1(X_0, X_1) = X_1 ϕ0(X0,X1)=X0,ϕ1(X0,X1)=X1 -
目标速度:
路径的速度是 ϕ t \phi_t ϕt 对 t t t 的导数:
X ˙ t = ∂ ϕ t ( X 0 , X 1 ) ∂ t \dot{X}_t = \frac{\partial \phi_t(X_0, X_1)}{\partial t} X˙t=∂t∂ϕt(X0,X1) -
优化目标:
漂移场 v ( z , t ) v(z, t) v(z,t) 的优化目标变为:
min v ∫ 0 1 E [ ∥ ∂ ϕ t ( X 0 , X 1 ) ∂ t − v ( X t , t ) ∥ 2 2 ] d t \min_v \int_0^1 \mathbb{E}\left[ \left\| \frac{\partial \phi_t(X_0, X_1)}{\partial t} - v(X_t, t) \right\|_2^2 \right] \mathrm{d}t vmin∫01E[ ∂t∂ϕt(X0,X1)−v(Xt,t) 22]dt- 相比于线性插值时的目标 E [ ∥ ( X 1 − X 0 ) − v ( X t , t ) ∥ 2 2 ] \mathbb{E}\left[ \| (X_1 - X_0) - v(X_t, t) \|_2^2 \right] E[∥(X1−X0)−v(Xt,t)∥22],这里用 ∂ ϕ t ∂ t \frac{\partial \phi_t}{\partial t} ∂t∂ϕt 替换了 X 1 − X 0 X_1 - X_0 X1−X0。
-
最优漂移场:
与线性情况类似,最优漂移场为条件期望:
v X ( z , t ) = E [ ∂ ϕ t ( X 0 , X 1 ) ∂ t ∣ X t = z ] v^X(z, t) = \mathbb{E}\left[ \frac{\partial \phi_t(X_0, X_1)}{\partial t} \mid X_t = z \right] vX(z,t)=E[∂t∂ϕt(X0,X1)∣Xt=z]
解释
-
非线性路径的意义:
- 线性插值 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0 假设路径是直线,但这可能不适合所有任务。例如,在图像生成中,从噪声到图像的变换可能需要更复杂的路径(如先形成轮廓,再填充细节)。
- 非线性路径 ϕ t ( X 0 , X 1 ) \phi_t(X_0, X_1) ϕt(X0,X1) 允许更灵活的变换,比如曲线路径或基于领域知识设计的路径。
-
优化目标的变化:
- 目标仍然是让 v ( z , t ) v(z, t) v(z,t) 接近路径速度,但速度 ∂ ϕ t ∂ t \frac{\partial \phi_t}{\partial t} ∂t∂ϕt 不再是恒定的,而是随 t t t 变化。
- 这增加了模型的表达能力,但也增加了计算复杂性。
-
实际实现:
- ϕ t \phi_t ϕt 可以用神经网络参数化,例如 ϕ t ( X 0 , X 1 ) = f θ ( X 0 , X 1 , t ) \phi_t(X_0, X_1) = f_\theta(X_0, X_1, t) ϕt(X0,X1)=fθ(X0,X1,t),其中 f θ f_\theta fθ 是一个 MLP。
- 或者,可以用预定义的非线性函数,比如基于物理系统的轨迹。
直观解释
- 类比:线性插值就像从城市 A 到城市 B 走直线公路。非线性扩展允许走一条曲线公路(比如绕过山脉),可能更符合实际需求。
- 意义:非线性扩展为 Rectified Flow 提供了更大的灵活性,可以适应更复杂的分布变换任务。
实际意义
- 在图像到图像翻译中,非线性路径可能更好地捕捉风格变化的中间状态。
- 在生成建模中,非线性路径可能更适合模拟数据的生成过程(比如先形成低频结构,再添加高频细节)。
局限
- 非线性路径增加了计算复杂性, ϕ t \phi_t ϕt 的设计需要额外调参。
- 论文中没有深入实验非线性扩展,更多是理论上的探讨。
3.5 Denoising Diffusion Models and Probability Flow ODEs
背景
扩散模型(Denoising Diffusion Models, DDPM)和概率流 ODE(Probability Flow ODE, PF-ODE)是近年来生成建模领域的热门方法。Rectified Flow 是一种基于 ODE 的方法,论文在 3.5 部分探讨了它与扩散模型和 PF-ODE 的关系,指出 Rectified Flow 可以看作这些模型的非线性特例,同时具有更直、更快的路径。
核心思想
- 扩散模型:通过一个前向扩散过程(加噪)和逆向去噪过程(生成)实现从噪声分布到数据分布的变换。
- 概率流 ODE:将扩散模型的逆向过程表示为一个确定性 ODE,边际分布与扩散过程一致。
- Rectified Flow 的联系:Rectified Flow 是一种更一般的非线性流方法,路径更直,速度更均匀,推理效率更高。
数学公式
-
扩散模型的前向过程:
扩散模型定义了一个前向扩散过程(Markov 过程):
q ( X t ∣ X 0 ) = N ( X t ; 1 − β t X 0 , β t I ) q(X_t \mid X_0) = \mathcal{N}(X_t; \sqrt{1 - \beta_t} X_0, \beta_t I) q(Xt∣X0)=N(Xt;1−βtX0,βtI)- X 0 ∼ π 1 X_0 \sim \pi_1 X0∼π1(数据分布)。
- β t \beta_t βt 是时间 t t t 的噪声方差, β t ∈ ( 0 , 1 ) \beta_t \in (0, 1) βt∈(0,1)。
- X t X_t Xt 是加噪后的中间状态, X 1 ∼ N ( 0 , I ) X_1 \sim \mathcal{N}(0, I) X1∼N(0,I)(纯噪声)。
-
逆向过程:
扩散模型的逆向过程是一个去噪过程,近似为:
p θ ( X t − 1 ∣ X t ) = N ( X t − 1 ; μ θ ( X t , t ) , Σ t ) p_\theta(X_{t-1} \mid X_t) = \mathcal{N}(X_{t-1}; \mu_\theta(X_t, t), \Sigma_t) pθ(Xt−1∣Xt)=N(Xt−1;μθ(Xt,t),Σt)-
μ
θ
\mu_\theta
μθ 是神经网络学习的均值,通常通过分数函数(score function)表示:
μ θ ( X t , t ) = 1 1 − β t ( X t + β t ∇ log p t ( X t ) ) \mu_\theta(X_t, t) = \frac{1}{\sqrt{1 - \beta_t}} \left( X_t + \beta_t \nabla \log p_t(X_t) \right) μθ(Xt,t)=1−βt1(Xt+βt∇logpt(Xt)) - ∇ log p t ( X t ) \nabla \log p_t(X_t) ∇logpt(Xt) 是分数函数,扩散模型通过去噪分数匹配(denoising score matching)学习。
-
μ
θ
\mu_\theta
μθ 是神经网络学习的均值,通常通过分数函数(score function)表示:
-
概率流 ODE:
概率流 ODE(PF-ODE)将逆向过程表示为一个确定性 ODE:
d X t = [ f ( t ) X t − 1 2 g ( t ) 2 ∇ log p t ( X t ) ] d t \mathrm{d}X_t = \left[ f(t) X_t - \frac{1}{2} g(t)^2 \nabla \log p_t(X_t) \right] \mathrm{d}t dXt=[f(t)Xt−21g(t)2∇logpt(Xt)]dt- f ( t ) f(t) f(t) 和 g ( t ) g(t) g(t) 是扩散过程的漂移和扩散系数。
- 对于 DDPM, f ( t ) = − 1 2 β t f(t) = -\frac{1}{2} \beta_t f(t)=−21βt, g ( t ) = β t g(t) = \sqrt{\beta_t} g(t)=βt。
- PF-ODE 的边际分布 Law ( X t ) \text{Law}(X_t) Law(Xt) 与扩散过程一致。
-
DDIM(Denoising Diffusion Implicit Models):
DDIM 是扩散模型的一种变体,定义了一个非 Markov 的逆向过程,ODE 形式为:
d X t = − ϵ θ ( X t , t ) β t d t \mathrm{d}X_t = -\epsilon_\theta(X_t, t) \sqrt{\beta_t} \mathrm{d}t dXt=−ϵθ(Xt,t)βtdt- ϵ θ ( X t , t ) \epsilon_\theta(X_t, t) ϵθ(Xt,t) 是神经网络预测的噪声,近似 − 1 − β t ∇ log p t ( X t ) -\sqrt{1 - \beta_t} \nabla \log p_t(X_t) −1−βt∇logpt(Xt)。
-
Rectified Flow 的形式:
Rectified Flow 的 ODE 为:
d Z t = v ( Z t , t ) d t \mathrm{d}Z_t = v(Z_t, t) \mathrm{d}t dZt=v(Zt,t)dt
其中 v ( z , t ) v(z, t) v(z,t) 通过优化目标学习:
v ( z , t ) ≈ E [ X 1 − X 0 ∣ X t = z ] v(z, t) \approx \mathbb{E}\left[ X_1 - X_0 \mid X_t = z \right] v(z,t)≈E[X1−X0∣Xt=z]
解释
-
PF-ODE 和 DDIM 是 Rectified Flow 的特例:
- 论文指出,PF-ODE 和 DDIM 的 ODE 形式可以看作 Rectified Flow 的非线性扩展(2.3 节)。
- 具体来说,PF-ODE 和 DDIM 的速度场 v ( z , t ) v(z, t) v(z,t) 是非线性的,且依赖于分数函数 ∇ log p t ( z ) \nabla \log p_t(z) ∇logpt(z)。
- Rectified Flow 的 v ( z , t ) v(z, t) v(z,t) 更简单,直接逼近直线速度 X 1 − X 0 X_1 - X_0 X1−X0,路径更直。
-
路径直线性:
- 扩散模型和 PF-ODE 的路径通常是曲线的,速度不均匀(早期慢,后期快)。
- Rectified Flow 通过 Reflow 过程使路径接近直线,速度更均匀,推理效率更高。
-
边际分布:
- PF-ODE 和 DDIM 的边际分布 Law ( X t ) \text{Law}(X_t) Law(Xt) 与扩散过程一致。
- Rectified Flow 也保证 Law ( Z t ) = Law ( X t ) \text{Law}(Z_t) = \text{Law}(X_t) Law(Zt)=Law(Xt),但 X t X_t Xt 是线性插值路径,计算更简单。
直观解释
- 类比:扩散模型就像一个“随机漫步”过程,从数据到噪声再回到数据,路径曲折且需要多步采样。PF-ODE 和 DDIM 将其简化为确定性路径,但仍然是曲线。Rectified Flow 则像一条“高速公路”,路径更直,速度更均匀,可以一步到达。
- 意义:Rectified Flow 提供了一种更高效的替代方案,避免了扩散模型的多步采样,同时保留了生成质量。
实际意义
- 推理效率:Rectified Flow 经过 Reflow 后可以用一步生成(single-step),而扩散模型通常需要数百步。
- 生成质量:实验表明,2-Rectified Flow 在 CIFAR-10 上的 FID(4.85)优于一步扩散模型(FID 8.91)。
- 理论联系:Rectified Flow 提供了一个统一的框架,将扩散模型和 PF-ODE 纳入其中,同时揭示了直线路径的优越性。
局限
- 扩散模型在高维数据上可能更擅长捕捉复杂分布(因为分数函数更灵活)。
- Rectified Flow 的直线路径可能限制了模型的表达能力(尽管非线性扩展可以缓解)。
两部分的联系
-
灵活性与效率的权衡:
- 2.3 A Nonlinear Extension 增加了 Rectified Flow 的灵活性,允许非线性路径,理论上可以包含 PF-ODE 和 DDIM 作为特例。
- 3.5 Denoising Diffusion Models and Probability Flow ODEs 指出,Rectified Flow 的直线路径比 PF-ODE 和 DDIM 更高效,但可能牺牲一些表达能力。
-
路径设计:
- 非线性扩展允许更复杂的路径设计,可能更接近扩散模型的曲线路径。
- Rectified Flow 的默认直线路径(经过 Reflow 优化)在效率上优于扩散模型。
-
应用场景:
- 非线性扩展适合需要复杂路径的任务(如某些图像到图像翻译)。
- Rectified Flow 的直线路径适合高效生成和域迁移任务。
总结
2.3 A Nonlinear Extension
- 核心思想:将线性插值 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0 扩展为非线性路径 X t = ϕ t ( X 0 , X 1 ) X_t = \phi_t(X_0, X_1) Xt=ϕt(X0,X1),优化目标变为逼近 ∂ ϕ t ∂ t \frac{\partial \phi_t}{\partial t} ∂t∂ϕt。
- 公式: min v ∫ 0 1 E [ ∥ ∂ ϕ t ( X 0 , X 1 ) ∂ t − v ( X t , t ) ∥ 2 2 ] d t \min_v \int_0^1 \mathbb{E}\left[ \left\| \frac{\partial \phi_t(X_0, X_1)}{\partial t} - v(X_t, t) \right\|_2^2 \right] \mathrm{d}t minv∫01E[ ∂t∂ϕt(X0,X1)−v(Xt,t) 22]dt
- 意义:增加模型灵活性,适应更复杂的分布变换任务。
3.5 Denoising Diffusion Models and Probability Flow ODEs
- 核心思想:Rectified Flow 是扩散模型和 PF-ODE 的一种非线性特例,但路径更直,速度更均匀,推理效率更高。
- 公式:PF-ODE 的 d X t = [ f ( t ) X t − 1 2 g ( t ) 2 ∇ log p t ( X t ) ] d t \mathrm{d}X_t = \left[ f(t) X_t - \frac{1}{2} g(t)^2 \nabla \log p_t(X_t) \right] \mathrm{d}t dXt=[f(t)Xt−21g(t)2∇logpt(Xt)]dt vs. Rectified Flow 的 d Z t = v ( Z t , t ) d t \mathrm{d}Z_t = v(Z_t, t) \mathrm{d}t dZt=v(Zt,t)dt。
- 意义:揭示了 Rectified Flow 与扩散模型的理论联系,同时强调了直线路径的高效性。
这两个部分共同展示了 Rectified Flow 的理论深度和实践优势:非线性扩展增加了灵活性,而与扩散模型的对比突出了效率优势。对于深度学习研究者,这提供了宝贵的思路:如何在灵活性和效率之间找到平衡。
代码实现
Rectified Flow 的训练代码以及用于图像生成和图像到图像翻译的代码。由于 Rectified Flow 是一种基于 ODE 的方法,涉及神经网络训练和 ODE 求解,会使用 Python 和 PyTorch 实现代码,并确保代码可运行。代码将分为两部分:训练代码和应用代码(图像生成 + 图像到图像翻译)。还会详细介绍每个部分的作用和实现细节。
环境与假设
- 环境:代码将在 Pyodide 环境中运行,因此避免本地文件 I/O 和网络请求。
- 库:使用 PyTorch(Pyodide 支持)和 NumPy。
- 数据:由于无法访问真实数据集,将用合成数据(2D 点分布)进行训练和测试,并在注释中说明如何替换为真实图像数据。
- ODE 求解:使用简单的 Euler 方法求解 ODE(生产环境中可以用更高级的求解器如
torchdiffeq)。
1. Rectified Flow 训练代码
目标
训练一个 Rectified Flow 模型,学习从分布 π 0 \pi_0 π0 到 π 1 \pi_1 π1 的漂移场 v θ ( z , t ) v_\theta(z, t) vθ(z,t)。我们将:
- 生成合成数据: π 0 \pi_0 π0 和 π 1 \pi_1 π1 是两个 2D 点分布。
- 定义一个神经网络 v θ ( z , t ) v_\theta(z, t) vθ(z,t)。
- 优化目标: min v θ ∫ 0 1 E [ ∥ ( X 1 − X 0 ) − v θ ( X t , t ) ∥ 2 2 ] d t \min_{v_\theta} \int_0^1 \mathbb{E}\left[ \| (X_1 - X_0) - v_\theta(X_t, t) \|_2^2 \right] \mathrm{d}t minvθ∫01E[∥(X1−X0)−vθ(Xt,t)∥22]dt。
- 支持 Reflow 过程。
代码实现
import torch
import torch.nn as nn
import numpy as np
# 1. 定义漂移场神经网络 v_θ(z, t)
class VelocityNet(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(VelocityNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim + 1, hidden_dim), # 输入是 (z, t)
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim) # 输出是 v(z, t)
)
def forward(self, z, t):
# z: (batch_size, input_dim), t: (batch_size, 1)
t = t.view(-1, 1)
zt = torch.cat([z, t], dim=1)
return self.net(zt)
# 2. 生成合成数据:π_0 和 π_1
def generate_synthetic_data(n_samples=1000, dim=2):
# π_0: 中心在 (-1, -1) 的高斯分布
pi_0 = torch.randn(n_samples, dim) * 0.5 + torch.tensor([-1.0, -1.0])
# π_1: 中心在 (1, 1) 的高斯分布
pi_1 = torch.randn(n_samples, dim) * 0.5 + torch.tensor([1.0, 1.0])
return pi_0, pi_1
# 3. 训练 Rectified Flow
def train_rectified_flow(pi_0, pi_1, input_dim=2, hidden_dim=128, num_epochs=1000, lr=1e-3, batch_size=128):
model = VelocityNet(input_dim, hidden_dim)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
n_samples = pi_0.shape[0]
for epoch in range(num_epochs):
# 随机采样 batch
indices = torch.randperm(n_samples)[:batch_size]
x0 = pi_0[indices]
x1 = pi_1[indices]
# 随机采样时间 t
t = torch.rand(batch_size, 1)
# 线性插值:X_t = t * X_1 + (1 - t) * X_0
x_t = t * x1 + (1 - t) * x0
# 目标速度:X_1 - X_0
target_velocity = x1 - x0
# 预测速度:v_θ(X_t, t)
predicted_velocity = model(x_t, t)
# 损失:均方误差
loss = ((predicted_velocity - target_velocity) ** 2).mean()
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
return model
# 4. Reflow 过程
def reflow(pi_0, pi_1, K=2, num_epochs_per_flow=1000):
coupling = (pi_0, pi_1)
model = None
for k in range(K):
print(f"Reflow iteration {k+1}/{K}")
# 训练 Rectified Flow
model = train_rectified_flow(coupling[0], coupling[1], num_epochs=num_epochs_per_flow)
# 用训练好的模型采样新耦合
n_samples = pi_0.shape[0]
z0 = coupling[0] # 保持 π_0 不变
z1 = torch.zeros_like(z0)
for i in range(n_samples):
z1[i] = sample_rectified_flow(model, z0[i])
# 更新耦合
coupling = (z0, z1)
return model, coupling
# 5. 用 Rectified Flow 采样
def sample_rectified_flow(model, z0, num_steps=100):
z_t = z0.clone()
dt = 1.0 / num_steps
for step in range(num_steps):
t = torch.tensor(step * dt)
v = model(z_t, t)
z_t = z_t + v * dt # Euler 积分
return z_t
# 6. 主函数
def main():
# 生成合成数据
pi_0, pi_1 = generate_synthetic_data()
# 训练并执行 Reflow
print("Training Rectified Flow with Reflow...")
model, final_coupling = reflow(pi_0, pi_1, K=2)
# 打印结果
print(">>> Final coupling (first 5 samples):")
print("Z_0:", final_coupling[0][:5])
print("Z_1:", final_coupling[1][:5])
if __name__ == "__main__":
main()
代码详细介绍
-
VelocityNet:
- 定义了一个简单的 MLP,输入是 ( z , t ) (z, t) (z,t),输出是 v θ ( z , t ) v_\theta(z, t) vθ(z,t)。
- 网络结构:输入层(dim+1,包括 z z z 和 t t t)、两层隐藏层(ReLU 激活)、输出层(dim 维速度)。
-
generate_synthetic_data:
- 生成了两个 2D 高斯分布: π 0 \pi_0 π0 中心在 ( − 1 , − 1 ) (-1, -1) (−1,−1), π 1 \pi_1 π1 中心在 ( 1 , 1 ) (1, 1) (1,1)。
- 在真实场景中,可以替换为图像数据(比如 π 0 \pi_0 π0 是噪声, π 1 \pi_1 π1 是 CIFAR-10 图像)。
-
train_rectified_flow:
- 实现 Rectified Flow 的训练。
- 每轮迭代:
- 采样 batch 数据 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 和时间 t t t。
- 计算线性插值 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0。
- 计算目标速度 X 1 − X 0 X_1 - X_0 X1−X0 和预测速度 v θ ( X t , t ) v_\theta(X_t, t) vθ(Xt,t)。
- 优化均方误差损失。
-
reflow:
- 实现了 Reflow 过程。
- 每次 Reflow:
- 用当前耦合 ( Z 0 k , Z 1 k ) (Z_0^k, Z_1^k) (Z0k,Z1k) 训练一个新的 Rectified Flow。
- 用训练好的模型采样新耦合 ( Z 0 k + 1 , Z 1 k + 1 ) (Z_0^{k+1}, Z_1^{k+1}) (Z0k+1,Z1k+1)。
-
sample_rectified_flow:
- 用 Euler 方法求解 ODE,生成从 Z 0 Z_0 Z0 到 Z 1 Z_1 Z1 的路径。
- 生产环境中可以用更高级的 ODE 求解器(如
torchdiffeq)。
-
main:
- 生成数据,执行训练和 Reflow,打印最终耦合。
如何替换为真实图像数据
-
π
0
\pi_0
π0:用高斯噪声代替(
torch.randn(batch_size, channels, height, width))。 - π 1 \pi_1 π1:用真实图像数据集(如 CIFAR-10)。需要加载数据集并预处理(归一化到 [ − 1 , 1 ] [-1, 1] [−1,1])。
- 输入维度:将
input_dim改为图像的展平维度(例如 CIFAR-10 是 3 × 32 × 32 = 3072 3 \times 32 \times 32 = 3072 3×32×32=3072)。 - 网络结构:可以用卷积神经网络(CNN)替换 MLP,比如 U-Net 结构。
2. 图像生成和图像到图像翻译代码
目标
使用训练好的 Rectified Flow 模型执行:
- 图像生成:从噪声分布 π 0 \pi_0 π0 生成图像( π 1 \pi_1 π1 是目标图像分布)。
- 图像到图像翻译:从源域图像 π 0 \pi_0 π0 翻译到目标域图像 π 1 \pi_1 π1。
假设
- 由于无法加载真实图像数据,继续使用 2D 点分布的合成数据。
- 会说明如何修改代码以处理真实图像数据。
代码实现
import torch
import torch.nn as nn
import numpy as np
# 1. 定义漂移场神经网络(与训练代码相同)
class VelocityNet(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(VelocityNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim + 1, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim)
)
def forward(self, z, t):
t = t.view(-1, 1)
zt = torch.cat([z, t], dim=1)
return self.net(zt)
# 2. ODE 采样
def sample_rectified_flow(model, z0, num_steps=100):
z_t = z0.clone()
dt = 1.0 / num_steps
for step in range(num_steps):
t = torch.tensor(step * dt)
v = model(z_t, t)
z_t = z_t + v * dt
return z_t
# 3. 图像生成
def image_generation(model, n_samples=5, input_dim=2):
# 从 π_0 采样噪声(这里用高斯噪声)
z0 = torch.randn(n_samples, input_dim) * 0.5 + torch.tensor([-1.0, -1.0])
print(">>> Initial samples (π_0, noise):")
print(z0)
# 用 Rectified Flow 生成样本
z1 = torch.zeros_like(z0)
for i in range(n_samples):
z1[i] = sample_rectified_flow(model, z0[i])
print(">>> Generated samples (π_1, target):")
print(z1)
return z0, z1
# 4. 图像到图像翻译
def image_to_image_translation(model, source_samples, num_steps=100):
# source_samples: 从源域 π_0 采样的样本
translated_samples = torch.zeros_like(source_samples)
for i in range(source_samples.shape[0]):
translated_samples[i] = sample_rectified_flow(model, source_samples[i], num_steps)
print(">>> Source samples (π_0):")
print(source_samples)
print(">>> Translated samples (π_1):")
print(translated_samples)
return translated_samples
# 5. 主函数
def main():
# 假设已经有一个训练好的模型
input_dim = 2
hidden_dim = 128
model = VelocityNet(input_dim, hidden_dim)
# 随机初始化权重(模拟训练好的模型)
for param in model.parameters():
nn.init.normal_(param, 0, 0.1)
# 图像生成
print("Image Generation:")
z0, z1 = image_generation(model, n_samples=5)
# 图像到图像翻译
print("\nImage-to-Image Translation:")
source_samples = torch.randn(5, input_dim) * 0.5 + torch.tensor([-1.0, -1.0]) # 模拟源域样本
translated_samples = image_to_image_translation(model, source_samples)
if __name__ == "__main__":
main()
代码详细介绍
-
VelocityNet:
- 与训练代码中的网络相同,用于加载训练好的模型。
-
sample_rectified_flow:
- 实现 ODE 采样,与训练代码相同。
-
image_generation:
- 从噪声分布 π 0 \pi_0 π0 采样初始样本 Z 0 Z_0 Z0。
- 用训练好的模型生成 Z 1 Z_1 Z1,目标是接近 π 1 \pi_1 π1。
- 打印初始和生成样本。
-
image_to_image_translation:
- 输入源域样本( π 0 \pi_0 π0),用模型翻译到目标域( π 1 \pi_1 π1)。
- 打印源域和翻译后的样本。
-
main:
- 模拟一个训练好的模型(随机初始化权重)。
- 分别调用图像生成和图像到图像翻译函数。
如何替换为真实图像数据
- 图像生成:
- 将
Z
0
Z_0
Z0 替换为高斯噪声(
torch.randn(batch_size, channels, height, width))。 - 模型输出
Z
1
Z_1
Z1 是生成的图像,可以用
torchvision.utils.save_image保存(但 Pyodide 不支持,需手动修改)。
- 将
Z
0
Z_0
Z0 替换为高斯噪声(
- 图像到图像翻译:
source_samples替换为源域图像(比如人脸图像)。- 模型输出是目标域图像(比如猫脸图像)。
- 网络结构:
- 用 CNN(如 U-Net)替换 MLP,适应图像数据。
- 输入维度改为
(channels, height, width),可以用torch.nn.Conv2d处理。
实际场景中的修改
- 数据预处理:图像需要归一化到 [ − 1 , 1 ] [-1, 1] [−1,1]。
- 损失函数:对于图像到图像翻译,可以引入额外的损失(如循环一致性损失)。
- ODE 求解:用更高级的求解器(如 RK4 或
torchdiffeq)提高精度。
运行说明
-
训练代码:
- 运行
rectified_flow_train.py,会生成合成数据并训练一个 Rectified Flow 模型。 - 训练完成后,执行 Reflow 过程,生成最终耦合。
- 运行
-
应用代码:
- 运行
rectified_flow_application.py,会用训练好的模型(这里用随机初始化的模型模拟)执行图像生成和图像到图像翻译。 - 输出是 2D 点坐标,模拟了从 π 0 \pi_0 π0 到 π 1 \pi_1 π1 的变换。
- 运行
-
输出示例(假设值):
- 图像生成:
>>> Initial samples (π_0, noise): tensor([[-1.2, -0.8], [-0.9, -1.1], ...]) >>> Generated samples (π_1, target): tensor([[0.9, 1.2], [1.1, 0.8], ...]) - 图像到图像翻译:
>>> Source samples (π_0): tensor([[-1.3, -0.7], [-1.0, -1.2], ...]) >>> Translated samples (π_1): tensor([[1.0, 0.9], [0.8, 1.1], ...])
- 图像生成:
总结
训练代码
- 实现了 Rectified Flow 的训练和 Reflow 过程。
- 使用合成 2D 数据,优化目标是让 v θ ( X t , t ) v_\theta(X_t, t) vθ(Xt,t) 接近 X 1 − X 0 X_1 - X_0 X1−X0。
- 支持递归校正,路径逐步变直。
应用代码
- 实现了图像生成和图像到图像翻译。
- 从噪声生成目标分布样本,或从源域翻译到目标域。
- 提供了如何修改为真实图像数据的说明。
实际应用中的注意事项
- 模型容量:对于图像数据,建议使用更大的网络(如 U-Net)。
- 采样步数:
num_steps影响生成质量,建议调整。 - Reflow 次数: K K K 越大,路径越直,但训练成本增加。
这些代码提供了一个可运行的起点,可以根据具体任务进一步优化。
图像翻译的问题
问题背景
在 Rectified Flow 中,图像到图像翻译的目标是从源域分布
π
0
\pi_0
π0(如人脸图像)变换到目标域分布
π
1
\pi_1
π1(如猫脸图像)。代码中的 image_to_image_translation 函数看起来很简单:
def image_to_image_translation(model, source_samples, num_steps=100):
translated_samples = torch.zeros_like(source_samples)
for i in range(source_samples.shape[0]):
translated_samples[i] = sample_rectified_flow(model, source_samples[i], num_steps)
print(">>> Source samples (π_0):")
print(source_samples)
print(">>> Translated samples (π_1):")
print(translated_samples)
return translated_samples
但你提出了一个关键问题:模型如何知道目标域是猫脸? 答案在于训练阶段的设计和漂移场
v
θ
(
z
,
t
)
v_\theta(z, t)
vθ(z,t) 的学习过程。image_to_image_translation 只是推理阶段的代码,真正的“知识”是在训练阶段通过数据和优化目标嵌入到模型中的。
1. 训练阶段:如何让模型知道目标是猫脸?
Rectified Flow 的训练目标是学习一个漂移场 v θ ( z , t ) v_\theta(z, t) vθ(z,t),使得 ODE d Z t = v θ ( Z t , t ) d t \mathrm{d}Z_t = v_\theta(Z_t, t) \mathrm{d}t dZt=vθ(Zt,t)dt 能够将样本从 π 0 \pi_0 π0 变换到 π 1 \pi_1 π1。在图像到图像翻译任务中, π 0 \pi_0 π0 是人脸分布, π 1 \pi_1 π1 是猫脸分布。以下是训练阶段的关键步骤:
1.1 数据准备
- 源域 π 0 \pi_0 π0:收集人脸图像数据集(比如 CelebA)。
- 目标域 π 1 \pi_1 π1:收集猫脸图像数据集(比如 AFHQ 中的猫脸部分)。
- 耦合 ( X 0 , X 1 ) (X_0, X_1) (X0,X1):Rectified Flow 通常假设 ( X 0 , X 1 ) ∼ π 0 × π 1 (X_0, X_1) \sim \pi_0 \times \pi_1 (X0,X1)∼π0×π1,即 X 0 X_0 X0 和 X 1 X_1 X1 是独立采样的(无配对数据)。这意味着人脸和猫脸不需要一一对应。
1.2 训练目标
Rectified Flow 的优化目标是:
min
v
θ
∫
0
1
E
[
∥
(
X
1
−
X
0
)
−
v
θ
(
X
t
,
t
)
∥
2
2
]
d
t
,
X
t
=
t
X
1
+
(
1
−
t
)
X
0
\min_{v_\theta} \int_0^1 \mathbb{E}\left[ \| (X_1 - X_0) - v_\theta(X_t, t) \|_2^2 \right] \mathrm{d}t, \quad X_t = t X_1 + (1 - t) X_0
vθmin∫01E[∥(X1−X0)−vθ(Xt,t)∥22]dt,Xt=tX1+(1−t)X0
- X 0 ∼ π 0 X_0 \sim \pi_0 X0∼π0(人脸), X 1 ∼ π 1 X_1 \sim \pi_1 X1∼π1(猫脸)。
- X t X_t Xt 是线性插值路径,表示从人脸到猫脸的中间状态。
- X 1 − X 0 X_1 - X_0 X1−X0 是目标速度,表示从人脸到猫脸的“方向”。
- v θ ( X t , t ) v_\theta(X_t, t) vθ(Xt,t) 是模型预测的速度。
通过优化这个目标,模型学习到的 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 会在每个时间 t t t 和位置 z z z 处,预测一个速度向量,指向从人脸分布到猫脸分布的方向。
1.3 训练过程
- 采样:从 π 0 \pi_0 π0 和 π 1 \pi_1 π1 采样 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 对,比如 X 0 X_0 X0 是一张人脸图像, X 1 X_1 X1 是一张猫脸图像。
- 插值:计算 X t = t X 1 + ( 1 − t ) X 0 X_t = t X_1 + (1 - t) X_0 Xt=tX1+(1−t)X0,这是从人脸到猫脸的线性插值。
- 优化:让 v θ ( X t , t ) v_\theta(X_t, t) vθ(Xt,t) 接近 X 1 − X 0 X_1 - X_0 X1−X0,即从人脸到猫脸的变换方向。
- Reflow:通过递归校正(Reflow),使路径更直,最终接近一步变换。
1.4 模型如何“知道”目标是猫脸?
- 通过数据:训练数据中, X 1 X_1 X1 始终来自猫脸分布 π 1 \pi_1 π1。模型通过优化目标,学习到 X 1 − X 0 X_1 - X_0 X1−X0 的统计规律,即从人脸到猫脸的变换方向。
- 统计学习: v θ ( z , t ) v_\theta(z, t) vθ(z,t) 是一个神经网络,它在训练中看到大量 ( X 0 , X 1 ) (X_0, X_1) (X0,X1) 对,逐渐学会了从人脸特征( π 0 \pi_0 π0)到猫脸特征( π 1 \pi_1 π1)的映射。
- 边际分布:Rectified Flow 保证 Z 1 ∼ π 1 Z_1 \sim \pi_1 Z1∼π1(猫脸分布),因为训练目标确保了 Z t Z_t Zt 的边际分布从 π 0 \pi_0 π0 演变为 π 1 \pi_1 π1。
直观解释:
- 想象 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 是一个“导航系统”。在训练时,它看到很多人脸-猫脸对 ( X 0 , X 1 ) (X_0, X_1) (X0,X1),学会了从人脸到猫脸的“方向”(比如将眼睛变大、添加胡须等特征)。
- 在推理时,给定一张人脸 Z 0 Z_0 Z0,模型会根据 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 的指引,逐步将 Z 0 Z_0 Z0 变换为 Z 1 Z_1 Z1,而 Z 1 Z_1 Z1 会自然落在猫脸分布 π 1 \pi_1 π1 上。
2. 推理阶段:image_to_image_translation 的作用
现在回到 image_to_image_translation 函数:
def image_to_image_translation(model, source_samples, num_steps=100):
translated_samples = torch.zeros_like(source_samples)
for i in range(source_samples.shape[0]):
translated_samples[i] = sample_rectified_flow(model, source_samples[i], num_steps)
print(">>> Source samples (π_0):")
print(source_samples)
print(">>> Translated samples (π_1):")
print(translated_samples)
return translated_samples
2.1 函数的作用
- 输入:
model:训练好的漂移场 v θ ( z , t ) v_\theta(z, t) vθ(z,t)。source_samples:源域样本(人脸图像),即 Z 0 ∼ π 0 Z_0 \sim \pi_0 Z0∼π0。num_steps:ODE 求解的步数。
- 输出:
translated_samples:目标域样本(猫脸图像),即 Z 1 ∼ π 1 Z_1 \sim \pi_1 Z1∼π1。
2.2 内部调用 sample_rectified_flow
sample_rectified_flow 函数用 Euler 方法求解 ODE:
def sample_rectified_flow(model, z0, num_steps=100):
z_t = z0.clone()
dt = 1.0 / num_steps
for step in range(num_steps):
t = torch.tensor(step * dt)
v = model(z_t, t)
z_t = z_t + v * dt # Euler 积分
return z_t
- 输入:初始样本 Z 0 Z_0 Z0(人脸图像)。
- 过程:
- 从 t = 0 t=0 t=0 到 t = 1 t=1 t=1,逐步更新 Z t Z_t Zt。
- 每一步用 v θ ( Z t , t ) v_\theta(Z_t, t) vθ(Zt,t) 计算速度,沿速度方向移动。
- 输出: Z 1 Z_1 Z1(猫脸图像)。
2.3 为什么 Z 1 Z_1 Z1 是猫脸?
- 训练的知识: v θ ( z , t ) v_\theta(z, t) vθ(z,t) 在训练时已经学会了从人脸到猫脸的变换方向。
- ODE 的演化:从 Z 0 Z_0 Z0(人脸)开始, v θ ( z , t ) v_\theta(z, t) vθ(z,t) 提供了一个连续的变换路径,最终将 Z 0 Z_0 Z0 推向 π 1 \pi_1 π1(猫脸分布)。
- 边际分布保证:Rectified Flow 的理论性质( Law ( Z t ) = Law ( X t ) \text{Law}(Z_t) = \text{Law}(X_t) Law(Zt)=Law(Xt))确保 Z 1 Z_1 Z1 的分布与 π 1 \pi_1 π1 一致。
直观解释:
- 给定一张人脸图像 Z 0 Z_0 Z0,模型会根据 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 的指引,逐步调整图像的特征(比如将人脸的眼睛变大、鼻子变小、添加胡须等),最终生成一张猫脸图像 Z 1 Z_1 Z1。
- 模型并不“知道”猫脸是什么,而是通过训练数据学习到了猫脸的统计特征( π 1 \pi_1 π1),并将 Z 0 Z_0 Z0 推向这个分布。
3. 实际实现中的细节
3.1 网络结构
- 训练代码中的
VelocityNet:- 目前是一个简单的 MLP,适合 2D 点数据。
- 对于图像数据,建议使用卷积神经网络(CNN),如 U-Net:
class VelocityNet(nn.Module): def __init__(self, channels=3): super(VelocityNet, self).__init__() self.unet = UNet(channels, channels) # 输入和输出都是图像 self.time_embedding = nn.Linear(1, 64) # 时间嵌入 def forward(self, z, t): t_emb = torch.sin(self.time_embedding(t.view(-1, 1))) return self.unet(z, t_emb) # U-Net 处理图像 - U-Net 适合处理图像数据,能够捕捉空间特征。
3.2 数据预处理
- 人脸和猫脸图像:
- 通常需要调整到相同大小(比如 64 × 64 64 \times 64 64×64 或 256 × 256 256 \times 256 256×256)。
- 归一化到
[
−
1
,
1
]
[-1, 1]
[−1,1]:
transform = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到 [-1, 1] ])
3.3 训练数据
- 无配对数据:Rectified Flow 不需要人脸和猫脸一一对应,只需要两个分布的样本。
- 训练代码修改:
- 替换
generate_synthetic_data为真实数据集加载:from torchvision import datasets, transforms # 加载人脸和猫脸数据集 transform = transforms.Compose([...]) pi_0_dataset = datasets.CelebA(root='data/', transform=transform) # 人脸 pi_1_dataset = datasets.ImageFolder(root='data/afhq/cat/', transform=transform) # 猫脸 pi_0_loader = torch.utils.data.DataLoader(pi_0_dataset, batch_size=128, shuffle=True) pi_1_loader = torch.utils.data.DataLoader(pi_1_dataset, batch_size=128, shuffle=True)
- 替换
3.4 推理时的输入
- source_samples:
- 在推理时,
source_samples是人脸图像(形状为(batch_size, channels, height, width))。 - 确保与训练时的预处理一致(归一化到 [ − 1 , 1 ] [-1, 1] [−1,1])。
- 在推理时,
3.5 可视化
- 保存翻译结果:
- 推理后,
translated_samples是猫脸图像,可以用torchvision.utils.save_image保存:from torchvision.utils import save_image # 反归一化 translated_samples = (translated_samples + 1) / 2 # 从 [-1, 1] 转换到 [0, 1] save_image(translated_samples, "translated_cats.png", nrow=8) - 注:Pyodide 环境中无法保存文件,需在本地运行。
- 推理后,
4. 改进:如何增强翻译效果?
4.1 引入特征空间损失
- 直接用像素空间的 X 1 − X 0 X_1 - X_0 X1−X0 可能不够鲁棒,因为人脸和猫脸的像素差异可能很大。
- 论文中提到了一种改进方法(第5.2节):在特征空间中优化:
min v θ ∫ 0 1 E [ ∥ h ( X 1 ) − h ( X 0 ) − v θ ( h ( X t ) , t ) ∥ 2 2 ] d t \min_{v_\theta} \int_0^1 \mathbb{E}\left[ \| h(X_1) - h(X_0) - v_\theta(h(X_t), t) \|_2^2 \right] \mathrm{d}t vθmin∫01E[∥h(X1)−h(X0)−vθ(h(Xt),t)∥22]dt- h ( ⋅ ) h(\cdot) h(⋅) 是一个预训练的特征提取器(比如 VGG 的中间层)。
- h ( X 0 ) h(X_0) h(X0) 和 h ( X 1 ) h(X_1) h(X1) 是人脸和猫脸的特征表示。
- 这样可以捕捉更高层次的语义差异(比如眼睛形状、毛发纹理)。
4.2 引入循环一致性
- Rectified Flow 默认是单向变换(
π
0
→
π
1
\pi_0 \to \pi_1
π0→π1)。可以训练一个反向模型(
π
1
→
π
0
\pi_1 \to \pi_0
π1→π0),并引入循环一致性损失:
- 从人脸 Z 0 Z_0 Z0 翻译到猫脸 Z 1 Z_1 Z1。
- 从 Z 1 Z_1 Z1 翻译回人脸 Z 0 ′ Z_0' Z0′。
- 最小化 ∥ Z 0 − Z 0 ′ ∥ 2 2 \| Z_0 - Z_0' \|_2^2 ∥Z0−Z0′∥22。
4.3 条件输入
- 如果有条件信息(比如目标域的标签“猫”),可以将其嵌入到
v
θ
(
z
,
t
)
v_\theta(z, t)
vθ(z,t) 中:
class VelocityNet(nn.Module): def forward(self, z, t, condition): t_emb = torch.sin(self.time_embedding(t.view(-1, 1))) cond_emb = self.condition_embedding(condition) # 条件嵌入 return self.unet(z, t_emb, cond_emb)- 但 Rectified Flow 默认不依赖条件输入,完全通过 π 1 \pi_1 π1 的数据分布学习目标。
5. 总结:模型如何知道目标是猫脸?
-
训练阶段:
- 模型通过 ( X 0 , X 1 ) ∼ π 0 × π 1 (X_0, X_1) \sim \pi_0 \times \pi_1 (X0,X1)∼π0×π1 的训练数据学习从人脸到猫脸的变换方向。
- v θ ( z , t ) v_\theta(z, t) vθ(z,t) 捕捉了从 π 0 \pi_0 π0 到 π 1 \pi_1 π1 的统计规律。
-
推理阶段:
image_to_image_translation用训练好的 v θ ( z , t ) v_\theta(z, t) vθ(z,t),从人脸 Z 0 Z_0 Z0 开始,沿 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 的方向演化,最终到达猫脸分布 π 1 \pi_1 π1。- 模型并不显式“知道”目标是猫脸,而是通过训练数据和边际分布的约束,自然将 Z 0 Z_0 Z0 推向 π 1 \pi_1 π1。
-
改进方向:
- 用特征空间损失增强语义一致性。
- 引入循环一致性或条件输入提高翻译质量。
直观类比
- 训练时,模型就像一个“画家”,看到很多人脸-猫脸对,学会了如何把人脸画成猫脸(比如把鼻子变小、添加胡须)。
- 推理时,给定一张人脸,模型会一步步“修改”这张画,最终画出一张猫脸。
后记
2025年4月5日16点34分于上海,在grok 3大模型辅助下完成。

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









