








论文链接:https://arxiv.org/pdf/2411.07975
github链接:https://github.com/deepseek-ai/Janus
亮点直击
统一多模态框架: 提出 JanusFlow,一个同时处理图像理解和文本到图像生成任务的统一模型,解决了任务分离带来的架构复杂性问题。
创新优化策略: 采用任务解耦和表示对齐两大关键策略,提高理解与生成任务的独立性与语义一致性。
卓越性能表现:在多模态理解与文本到图像生成基准测试中超越现有专用模型和统一模型,取得领先成绩。
紧凑高效的设计:仅用 1.3B 参数实现性能突破,展示出高效模型在多模态任务中的巨大潜力。
效果展示
文生图


多模态理解


总结速览
解决的问题
当前图像理解与生成任务通常由专门的模型完成,统一模型在性能和效率上仍然存在局限性,难以在两个领域中同时达到优异表现。
提出的方案
提出 JanusFlow 框架,采用极简架构,将自回归语言模型与rectified flow相结合,实现图像理解与生成的统一。
应用的技术
-
Rectified Flow:作为生成建模的先进方法,简化了在大语言模型框架中训练的复杂性。
-
理解与生成解码器的解耦:分别优化理解与生成任务的编码器。
-
表示对齐:在统一训练过程中对理解和生成的表示进行对齐,增强统一模型的表现力。
达到的效果
-
性能提升:在标准基准上显著优于现有的统一模型,并在各领域中表现出与专用模型媲美甚至更优的性能。
-
模型简化:无需复杂的架构修改,即可在统一框架内有效训练,提升效率和通用性。
JanusFlow
本节介绍 JanusFlow 的架构以及我们的训练策略。
背景
多模态大语言模型(MLLMs)
给定一个数据集 ,其中包含离散的 token 序列,每个序列可以表示为 ,大语言模型(LLMs)通过自回归方式对序列分布进行建模。
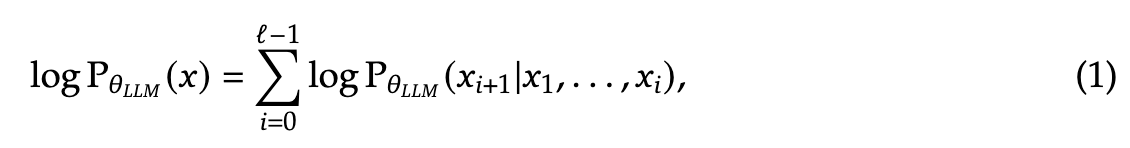
其中, 表示 LLM 的参数, 是序列长度。在经过大规模数据集的训练后,LLMs 展现出在各种任务中的泛化能力,并能够遵循多样化的指令。为了扩展这些模型以处理视觉输入,LLMs 会与视觉编码器结合。例如,LLaVA 通过投影层将 LLM 与预训练的 CLIP 图像编码器集成,将提取的图像特征转换为 LLM 可处理的联合嵌入空间(作为词嵌入)。借助大规模多模态数据集和日益强大的 LLMs,这种架构推动了能够解决多种视觉语言任务的先进多模态模型的发展。
Rectified Flow
对于一个包含连续 维数据点的数据集 ,其中 从未知的数据分布 中抽取,Rectified Flow [55, 60] 通过学习一个定义在时间 上的常微分方程(ODE)来建模数据分布:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









