










解锁PPO在长链思考任务中的潜力——VC-PPO的创新突破
在强化学习(RL)和大语言模型(LLM)结合的领域中,Proximal Policy Optimization(PPO)作为一种经典的RL算法,因其在多种任务中的稳定性和高效性而广受青睐。然而,当面对需要长链思考(Long Chain-of-Thought, Long-CoT)的复杂任务(如奥林匹克级别的数学推理)时,PPO却常常表现不佳,甚至出现性能崩溃。近期,ByteDance Seed团队发表的论文《What’s Behind PPO’s Collapse in Long-CoT? Value Optimization Holds the Secret》(arXiv: 2503.01491v1)深入剖析了PPO在Long-CoT任务中的失效原因,并提出了Value-Calibrated PPO(VC-PPO)算法,为PPO在复杂推理任务中的应用带来了显著突破。本文将为熟悉PPO和RLHF的深度学习研究者介绍这篇论文的核心贡献。
论文链接:https://arxiv.org/pdf/2503.01491
PPO在Long-CoT任务中的失效根源
论文首先揭示了PPO在Long-CoT任务中失败的两个关键问题:
-
价值模型初始化偏差(Value Initialization Bias)
在RLHF实践中,价值模型通常由奖励模型初始化。然而,奖励模型的训练目标是针对序列末尾(标记)评分,而对序列前部标记缺乏有效评估。这导致价值模型在初始化时对早期标记的预期回报估计存在系统性偏差。实验表明,这种偏差使得优势估计(Advantage Estimation)对序列前部标记产生正向偏见,促使模型倾向于生成更短的输出,从而破坏Long-CoT所需的长时间探索和推理能力。 -
奖励信号衰减(Reward Signal Decay)
PPO中使用的广义优势估计(Generalized Advantage Estimation, GAE)通常设置折扣参数 λ = 0.95 \lambda=0.95 λ=0.95以降低方差。然而,在Long-CoT任务中,奖励信号通常仅在序列末尾提供(例如数学问题的正确性评分)。当 λ < 1 \lambda<1 λ<1时,奖励信号在向序列前部传播时会以 λ T − t \lambda^{T-t} λT−t的速率衰减( T T T为序列长度, t t t为时间步)。对于长序列,这意味着早期标记几乎无法感知到奖励信号,导致价值模型无法准确捕捉长期依赖,进而影响策略优化。
这些问题共同导致PPO在训练初期出现输出长度骤减和性能下降的现象,特别是在如美国邀请数学考试(AIME)等需要复杂推理的任务中。
VC-PPO:针对性解决方案
为解决上述问题,论文提出了Value-Calibrated PPO(VC-PPO),通过以下两大创新改进PPO的表现:
1. 价值预训练(Value Pretraining)
为缓解价值初始化偏差,VC-PPO在正式RL训练前对价值模型进行离线预训练。具体步骤包括:
- 使用固定的监督微调(SFT)策略 π S F T \pi_{SFT} πSFT生成响应序列。
- 以 λ = 1.0 \lambda=1.0 λ=1.0(即蒙特卡洛回报)计算GAE,优化价值模型直至收敛,监控价值损失和解释方差等指标。
- 保存预训练后的价值模型检查点,作为后续RL训练的起点。
这种方法通过让价值模型提前适应SFT策略的分布,显著降低了初始化偏差。实验表明,预训练后的价值模型能够更准确地估计各标记的预期回报,消除了对早期标记的正向偏差,从而避免了输出长度崩溃的问题。
2. 解耦GAE计算(Decoupled-GAE)
为应对奖励信号衰减,VC-PPO提出了解耦策略和价值模型的GAE计算:
- 价值模型:设置 λ critic = 1.0 \lambda_{\text{critic}}=1.0 λcritic=1.0,避免奖励信号在长序列中的衰减,确保早期标记能够充分感知末尾奖励,从而优化价值估计的偏置。
- 策略模型:保持 λ actor ∈ [ 0.95 , 1.0 ] \lambda_{\text{actor}}\in[0.95, 1.0] λactor∈[0.95,1.0](如0.95或0.99),以维持方差较小的优势估计,加速策略收敛。
论文通过理论分析证明,使用不同 λ \lambda λ值的价值函数不会为策略梯度引入额外偏差(见公式8)。这一设计在保持策略优化效率的同时,显著提升了价值模型对长序列奖励的建模能力。
实验结果与洞见
VC-PPO在AIME数据集上的表现令人印象深刻:
- 性能提升:在16k上下文长度下,VC-PPO在AIME 2024数据集上的pass@1得分达到48.8,超越了DeepSeek-R1报道的47.0,创下Qwen-32B-Base模型在同类设置下的最佳纪录。内部模型更是达到74的AIME得分。
- 消融研究:在8k上下文长度下,基线PPO的AIME pass@1仅为5.6,而VC-PPO提升至41.9。移除价值预训练或解耦GAE任一组件都会导致性能显著下降,验证了两者的重要性。
- 超参数分析:价值预训练100步为最佳,过长可能导致过拟合。 λ actor = 0.99 \lambda_{\text{actor}}=0.99 λactor=0.99在AIME任务中表现最优,但 λ actor ∈ [ 0.95 , 1.0 ] \lambda_{\text{actor}}\in[0.95, 1.0] λactor∈[0.95,1.0]均显著优于 λ actor = 1.0 \lambda_{\text{actor}}=1.0 λactor=1.0。
此外,论文还揭示了价值优化和策略优化在偏置-方差权衡上的差异:价值优化对高方差更宽容,偏好 λ = 1.0 \lambda=1.0 λ=1.0以降低偏置;而策略优化需要较低方差以确保收敛。这一发现为未来RLHF研究提供了新方向。
核心贡献总结
VC-PPO的提出为PPO在Long-CoT任务中的应用开辟了新路径,其核心贡献包括:
- 问题诊断:明确了价值初始化偏差和奖励信号衰减是PPO在Long-CoT任务中失效的根本原因。
- 创新算法:通过价值预训练消除初始化偏差,通过解耦GAE优化长序列奖励传播,显著提升PPO性能。
- 实证验证:在AIME等复杂推理任务中,VC-PPO展现了优于基线PPO和GRPO的性能,证明了其有效性。
- 理论洞见:揭示了价值和策略模型在偏置-方差权衡上的不同偏好,为RLHF优化提供了理论指导。
对研究者的启发
对于深度学习研究者,VC-PPO不仅提供了一种实用的算法改进,还带来了以下思考:
- 价值模型对齐的重要性:在RLHF中,价值模型与初始策略的对齐对维持复杂推理模式(如CoT)至关重要。
- 长序列优化的挑战:Long-CoT任务暴露了传统RL算法在长序列建模中的局限,提示我们在设计算法时需更关注奖励信号的传播。
- 偏置-方差权衡的差异:价值和策略优化的不同需求可能适用于更广泛的RL场景,值得进一步探索。
总之,VC-PPO通过精准的问题定位和创新的解决方案,为PPO在复杂推理任务中的应用注入了新活力。这篇论文不仅是Long-CoT任务研究的重要进展,也为RLHF领域的算法优化提供了宝贵启示。感兴趣的研究者可以进一步阅读原文,探索VC-PPO的实现细节和潜在扩展方向。
参考文献
Yufeng Yuan et al., “What’s Behind PPO’s Collapse in Long-CoT? Value Optimization Holds the Secret,” arXiv:2503.01491v1, 2025.
优势估计对序列前部标记产生正向偏见
要理解为什么奖励模型对序列末尾(标记)评分会导致优势估计(Advantage Estimation)对序列前部标记产生正向偏见,而不是对序列末尾产生偏见,我们需要深入分析价值模型初始化偏差的机制、奖励模型与价值模型的训练目标差异,以及优势估计的计算过程。以下是详细的解释:
1. 奖励模型与价值模型的目标差异
在RLHF(Reinforcement Learning from Human Feedback)中,奖励模型和价值模型的训练目标有本质区别:
-
奖励模型:奖励模型通常被训练为对整个序列的输出质量进行评分,特别是在Long-CoT任务中,奖励信号主要在序列末尾的标记处提供。例如,在数学推理任务中,奖励模型会根据最终答案的正确性(出现在处)给出一个标量奖励(如正确为1.0,错误为-1.0)。奖励模型的目标是评估完整序列的“结果”,而对序列中早期的中间步骤(前部标记)缺乏直接的评分依据。因此,奖励模型对早期标记的评分可能不准确或偏低,因为这些标记对应的输出是“不完整的”或“未最终确定”的。
-
价值模型:价值模型的目标是估计在给定状态(或标记)下,未来累积奖励的期望值,即 V ( s t ) = E [ ∑ i = t T r i ∣ s t ] V(s_t) = \mathbb{E}[\sum_{i=t}^{T} r_i | s_t] V(st)=E[∑i=tTri∣st]。在Long-CoT任务中,由于奖励主要在<EOS>处提供,价值模型需要预测从当前标记到序列末尾的预期回报。理想情况下,价值模型应该对每个标记(包括早期标记)给出准确的回报估计,反映其对最终奖励的贡献。
在PPO的常见实践中,价值模型通常直接从训练好的奖励模型初始化。这意味着价值模型在训练开始时继承了奖励模型的特性,即倾向于对序列末尾(完整输出)的评分,而对早期标记的预期回报估计能力较弱。
2. 价值初始化偏差的来源
当价值模型从奖励模型初始化时,会出现以下问题:
-
奖励模型的局限性:奖励模型主要针对处的完整序列评分,对早期标记的评分可能偏低或不可靠(因为早期标记对应的输出尚未形成完整的答案)。例如,在数学推理任务中,早期标记可能只是问题的初步分析或中间计算步骤,奖励模型无法直接判断这些步骤的“价值”,因此可能给它们分配较低的分数。
-
价值模型的预期:价值模型需要估计每个标记的预期未来回报。理论上,早期标记的预期回报应该包含整个序列的奖励贡献(因为它们最终会影响处的奖励)。然而,由于初始化时价值模型继承了奖励模型的特性,它倾向于低估早期标记的回报(因为奖励模型对这些标记的评分较低或不可靠)。
这种低估导致价值模型在训练初期对早期标记的估值 V ( s t ) V(s_t) V(st)偏低,而对末尾标记(接近)的估值可能更接近实际奖励(因为奖励模型对末尾评分更准确)。
3. 优势估计的计算与正向偏见
优势估计(Advantage Estimation)是PPO中用来指导策略更新的核心量,其定义为:
A ^ t = ∑ i = 0 T − t − 1 λ i δ t + i , 其中 δ t + i = r t + i + V ( s t + i + 1 ) − V ( s t + i ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i}, \quad \text{其中} \quad \delta_{t+i} = r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) A^t=i=0∑T−t−1λiδt+i,其中δt+i=rt+i+V(st+i+1)−V(st+i)
- r t + i r_{t+i} rt+i:当前时间步的即时奖励。在Long-CoT任务中,通常只有在<EOS>处有非零奖励(如 r T = 1 r_T = 1 rT=1或 − 1 -1 −1),而其他时间步的奖励 r t + i = 0 r_{t+i} = 0 rt+i=0( t + i < T t+i < T t+i<T)。
- V ( s t + i ) V(s_{t+i}) V(st+i):价值模型对状态 s t + i s_{t+i} st+i的估值。
- λ \lambda λ:GAE的折扣参数,通常为0.95。
让我们逐步分析优势估计如何受到价值模型初始化偏差的影响:
(1) 早期标记的 δ t \delta_t δt分析
对于早期标记( t t t较小,远小于 T T T),由于奖励信号集中在<EOS>处, r t = 0 r_t = 0 rt=0(除非 t = T t=T t=T)。因此,TD误差 δ t \delta_t δt简化为:
δ t = r t + V ( s t + 1 ) − V ( s t ) = V ( s t + 1 ) − V ( s t ) \delta_t = r_t + V(s_{t+1}) - V(s_t) = V(s_{t+1}) - V(s_t) δt=rt+V(st+1)−V(st)=V(st+1)−V(st)
由于价值模型从奖励模型初始化,早期标记的 V ( s t ) V(s_t) V(st)往往被低估(因为奖励模型对不完整序列的评分较低)。假设真实的价值函数 V ∗ ( s t ) V^*(s_t) V∗(st)反映了未来奖励的期望,而初始化时的 V ( s t ) < V ∗ ( s t ) V(s_t) < V^*(s_t) V(st)<V∗(st),那么:
- V ( s t + 1 ) V(s_{t+1}) V(st+1)和 V ( s t ) V(s_t) V(st)都偏低,但 V ( s t + 1 ) V(s_{t+1}) V(st+1)对应的状态更接近末尾,可能比 V ( s t ) V(s_t) V(st)稍高(因为它更接近奖励模型擅长的末尾评分区域)。
- 因此, V ( s t + 1 ) − V ( s t ) V(s_{t+1}) - V(s_t) V(st+1)−V(st)可能为正,导致 δ t > 0 \delta_t > 0 δt>0。
这种正的TD误差累积到优势估计中,使得早期标记的 A ^ t \hat{A}_t A^t倾向于正值:
A ^ t ≈ ∑ i = 0 T − t − 1 λ i [ V ( s t + i + 1 ) − V ( s t + i ) ] \hat{A}_t \approx \sum_{i=0}^{T-t-1} \lambda^i [V(s_{t+i+1}) - V(s_{t+i})] A^t≈i=0∑T−t−1λi[V(st+i+1)−V(st+i)]
由于 T − t T-t T−t较大(早期标记到末尾的距离长),正的 δ t + i \delta_{t+i} δt+i会被累加,导致 A ^ t \hat{A}_t A^t表现出正向偏见。
(2) 末尾标记的 δ t \delta_t δt分析
对于接近的标记( t t t接近 T T T),情况有所不同。当 t = T − 1 t=T-1 t=T−1时:
δ T − 1 = r T − 1 + V ( s T ) − V ( s T − 1 ) \delta_{T-1} = r_{T-1} + V(s_T) - V(s_{T-1}) δT−1=rT−1+V(sT)−V(sT−1)
假设 r T − 1 = 0 r_{T-1} = 0 rT−1=0, V ( s T ) V(s_T) V(sT)是末尾状态的价值(通常接近实际奖励,因为奖励模型对末尾评分准确)。由于 V ( s T − 1 ) V(s_{T-1}) V(sT−1)可能仍被低估(但比早期标记的低估程度轻), V ( s T ) − V ( s T − 1 ) V(s_T) - V(s_{T-1}) V(sT)−V(sT−1)可能接近真实奖励的贡献, δ T − 1 \delta_{T-1} δT−1的偏见较小。
当 t = T t=T t=T时, r T r_T rT为实际奖励(如1或-1),优势估计直接反映奖励信号,偏差最小。因此,末尾标记的 A ^ t \hat{A}_t A^t受初始化偏差的影响较小,且更接近真实优势。
(3) 正向偏见为何集中在早期标记
由于价值模型对早期标记的低估更严重(因为这些标记距离奖励信号最远,奖励模型的评分最不可靠), δ t \delta_t δt的正向偏差在早期标记处累积得更多。优势估计 A ^ t \hat{A}_t A^t通过累加这些正的 δ t + i \delta_{t+i} δt+i,使得早期标记的正向偏见尤为显著。而对于末尾标记,价值估计更接近真实奖励, δ t \delta_t δt的偏差较小,优势估计的偏见也较小。
4. 正向偏见导致短输出倾向
在PPO中,策略更新依赖于优势估计 A ^ t \hat{A}_t A^t。如果早期标记的 A ^ t \hat{A}_t A^t普遍为正,模型会认为生成早期标记更有“优势”,从而倾向于更快地结束序列(即生成较短的输出)。这解释了为什么价值初始化偏差会导致模型输出长度崩溃,破坏Long-CoT任务所需的长时间探索和推理能力。
具体来说:
- 正向偏见的 A ^ t \hat{A}_t A^t鼓励模型在早期标记后停止生成(因为继续生成可能导致优势降低,特别是在价值模型低估后续标记的情况下)。
- 这与Long-CoT任务的需求相悖,因为Long-CoT需要模型生成长序列以完成复杂推理。
5. 为什么不是末尾标记产生偏见?
末尾标记的 A ^ t \hat{A}_t A^t受初始化偏差的影响较小,原因如下:
- 价值估计更准确:接近的标记对应的状态更接近奖励模型的训练目标(完整序列评分),因此 V ( s t ) V(s_t) V(st)的低估程度较轻, δ t \delta_t δt的偏差较小。
- 奖励信号主导:在处, r T r_T rT直接提供明确的奖励信号,优势估计主要由实际奖励驱动,而不是依赖不准确的价值估计。
- 累积效应减弱:对于末尾标记, T − t T-t T−t较小,优势估计中的累加项 ∑ i = 0 T − t − 1 λ i δ t + i \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i} ∑i=0T−t−1λiδt+i包含的项数较少,偏差累积的机会也较少。
因此,优势估计的正向偏见主要集中在早期标记,而不是末尾标记。
6. 实验证据与解决方案
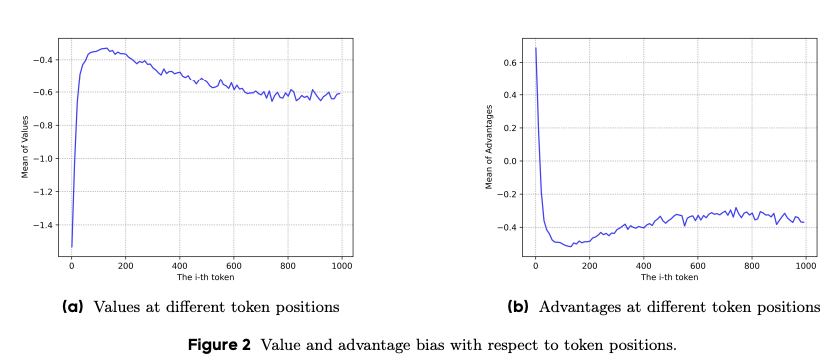
论文中的实验(见图2)进一步证实了这一现象:优势估计 A ^ t \hat{A}_t A^t与标记位置呈正相关,早期标记的 A ^ t \hat{A}_t A^t显著为正,导致模型倾向于生成短序列。VC-PPO通过以下方式解决了这一问题:
- 价值预训练:通过离线训练价值模型(使用SFT策略生成序列, λ = 1.0 \lambda=1.0 λ=1.0),使价值模型更好地估计早期标记的预期回报,消除初始化偏差。
- 解耦GAE:为价值模型设置 λ critic = 1.0 \lambda_{\text{critic}}=1.0 λcritic=1.0,确保奖励信号无衰减地传播到早期标记,进一步改善价值估计的准确性。
这些措施有效降低了早期标记的正向偏见,维持了长序列输出能力,从而提升了PPO在Long-CoT任务中的性能。
总结
奖励模型对评分导致价值模型初始化偏差,主要因为奖励模型对早期标记的评分不可靠,低估了它们的预期回报。这种低估在优势估计中表现为早期标记的正向偏见(因为 V ( s t + 1 ) − V ( s t ) > 0 V(s_{t+1}) - V(s_t) > 0 V(st+1)−V(st)>0累积),促使模型倾向于生成短序列。末尾标记的偏差较小,因为价值估计更接近实际奖励,且奖励信号直接主导优势计算。VC-PPO通过价值预训练和解耦GAE有效缓解了这一问题,为PPO在Long-CoT任务中的应用提供了解决方案。
奖励信号向前衰减
要理解为什么论文中提到“奖励信号在向序列前部传播时会以 λ T − t \lambda^{T-t} λT−t的速率衰减”,以及为什么这里描述为“从后往前传播”而不是“从前往后”,我们需要深入分析广义优势估计(Generalized Advantage Estimation, GAE)的计算过程、Long-CoT任务中奖励信号的特性,以及“传播”在价值估计中的含义。以下是详细的解释。
1. Long-CoT任务中奖励信号的特性
在Long-CoT(长链思考)任务中,例如数学推理问题,奖励信号通常具有以下特点:
- 稀疏奖励:奖励信号主要在序列末尾的
<EOS>标记处提供。例如,只有当模型生成完整的答案(出现在<EOS>处)并被验证为正确时,才会分配一个非零奖励(如 r T = 1 r_T = 1 rT=1表示正确, r T = − 1 r_T = -1 rT=−1表示错误)。对于序列中的其他标记( t < T t < T t<T),即时奖励通常为零( r t = 0 r_t = 0 rt=0)。 - 长序列依赖:由于Long-CoT任务需要生成较长的推理链(可能包含数百个标记),早期标记(靠近序列开头)的行为对最终奖励有重要影响,但这种影响需要通过整个序列传播到末尾才能显现。
在这样的设置下,强化学习的目标是通过PPO优化策略,使模型学会生成能够最大化末尾奖励的序列。然而,PPO依赖于价值模型和优势估计来指导策略更新,而价值模型需要准确估计每个标记的预期回报。这就引出了奖励信号在价值估计中的“传播”问题。
2. 价值估计与奖励信号的传播
在强化学习中,价值函数 V ( s t ) V(s_t) V(st)定义为从状态 s t s_t st开始,遵循当前策略 π \pi π所能获得的未来累积奖励的期望:
V ( s t ) = E π [ ∑ i = t T r i ∣ s t ] V(s_t) = \mathbb{E}_\pi \left[ \sum_{i=t}^{T} r_i \mid s_t \right] V(st)=Eπ[i=t∑Tri∣st]
在Long-CoT任务中,由于 r t = 0 r_t = 0 rt=0(对于 t < T t < T t<T),价值函数主要依赖于末尾的奖励 r T r_T rT:
V ( s t ) ≈ E π [ r T ∣ s t ] V(s_t) \approx \mathbb{E}_\pi \left[ r_T \mid s_t \right] V(st)≈Eπ[rT∣st]
这意味着,早期状态 s t s_t st(对应于序列前部的标记)的价值需要反映末尾奖励 r T r_T rT的贡献。然而,价值模型并不是直接观察 r T r_T rT,而是通过训练学习如何从当前状态估计未来的奖励。因此,奖励信号( r T r_T rT)需要某种方式“影响”早期状态的价值估计。这种影响在价值更新或优势估计中表现为一种“传播”过程。
3. GAE中的奖励信号传播
广义优势估计(GAE)是PPO中用来计算优势 A ^ t \hat{A}_t A^t的方法,其公式为:
A ^ t = ∑ i = 0 T − t − 1 λ i δ t + i , 其中 δ t + i = r t + i + V ( s t + i + 1 ) − V ( s t + i ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i}, \quad \text{其中} \quad \delta_{t+i} = r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) A^t=i=0∑T−t−1λiδt+i,其中δt+i=rt+i+V(st+i+1)−V(st+i)
- δ t + i \delta_{t+i} δt+i:时序差分(TD)误差,表示当前估计与实际回报的偏差。
- λ \lambda λ:GAE的折扣参数,通常为0.95,用于权衡偏差与方差。
- r t + i r_{t+i} rt+i:即时奖励,在Long-CoT任务中,只有 r T ≠ 0 r_T \neq 0 rT=0。
为了理解奖励信号的传播,我们需要看看价值模型的优化目标。价值模型通过最小化价值损失来学习,价值目标(target)通常基于GAE计算的回报。论文中提到(见公式5),价值目标可以表示为:
V target ( s t ) = { ∑ i = 0 T − t − 1 λ i ( r t + i + V ( s t + i + 1 ) − V ( s t + i ) ) + V ( s t ) , λ < 1.0 ∑ i = 0 T − t − 1 r t + i , λ = 1.0 V^{\text{target}}(s_t) = \begin{cases} \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) \right) + V(s_t), & \lambda < 1.0 \\ \sum_{i=0}^{T-t-1} r_{t+i}, & \lambda = 1.0 \end{cases} Vtarget(st)={∑i=0T−t−1λi(rt+i+V(st+i+1)−V(st+i))+V(st),∑i=0T−t−1rt+i,λ<1.0λ=1.0
在Long-CoT任务中, r t + i = 0 r_{t+i} = 0 rt+i=0(对于 t + i < T t+i < T t+i<T),只有 r T ≠ 0 r_T \neq 0 rT=0。让我们分析 λ < 1.0 \lambda < 1.0 λ<1.0的情况:
- 对于状态 s t s_t st,价值目标依赖于未来的TD误差 δ t + i \delta_{t+i} δt+i。
- 当 i = T − t − 1 i = T-t-1 i=T−t−1时(对应于末尾标记), r T r_T rT会出现在 δ T = r T + V ( s T + 1 ) − V ( s T ) \delta_T = r_T + V(s_{T+1}) - V(s_T) δT=rT+V(sT+1)−V(sT)中(假设 V ( s T + 1 ) = 0 V(s_{T+1}) = 0 V(sT+1)=0,因为序列在 T T T处终止)。
- 这个 r T r_T rT通过 λ i \lambda^i λi的权重影响前面的状态。例如,对于 s T − 1 s_{T-1} sT−1, r T r_T rT的贡献权重为 λ 0 = 1 \lambda^0 = 1 λ0=1;对于 s T − 2 s_{T-2} sT−2,权重为 λ 1 \lambda^1 λ1;对于 s t s_t st( t t t远小于 T T T),权重为 λ T − t − 1 \lambda^{T-t-1} λT−t−1。
因此,末尾的奖励 r T r_T rT对早期状态 s t s_t st的价值估计的贡献被 λ T − t − 1 \lambda^{T-t-1} λT−t−1缩放。当 λ < 1 \lambda < 1 λ<1(如 λ = 0.95 \lambda = 0.95 λ=0.95)且 T − t T-t T−t很大(即 t t t靠近序列开头)时, λ T − t − 1 \lambda^{T-t-1} λT−t−1会变得非常小。例如,若 T − t = 100 T-t = 100 T−t=100,则 λ 100 = 0.9 5 100 ≈ 0.006 \lambda^{100} = 0.95^{100} \approx 0.006 λ100=0.95100≈0.006,意味着 r T r_T rT对 s t s_t st的影响几乎为零。这种现象被论文称为“奖励信号衰减”。
4. 为什么是“从后往前传播”?
现在我们来解答核心问题:为什么论文描述奖励信号是“向序列前部传播”(从后往前),而不是“从前往后”?
(1) 价值估计的动态过程
价值函数的计算本质上是一个动态规划过程。理想情况下,价值函数通过Bellman方程定义:
V ( s t ) = E [ r t + V ( s t + 1 ) ∣ s t ] V(s_t) = \mathbb{E} \left[ r_t + V(s_{t+1}) \mid s_t \right] V(st)=E[rt+V(st+1)∣st]
在Long-CoT任务中, r t = 0 r_t = 0 rt=0(对于 t < T t < T t<T),所以:
V ( s t ) = V ( s t + 1 ) , 直到 V ( s T − 1 ) = E [ r T ] V(s_t) = V(s_{t+1}), \quad \text{直到} \quad V(s_{T-1}) = \mathbb{E} [r_T] V(st)=V(st+1),直到V(sT−1)=E[rT]
这意味着,末尾的奖励 r T r_T rT通过价值函数的递归关系逐级影响前面的状态:
- V ( s T − 1 ) V(s_{T-1}) V(sT−1)直接依赖于 r T r_T rT。
- V ( s T − 2 ) V(s_{T-2}) V(sT−2)依赖于 V ( s T − 1 ) V(s_{T-1}) V(sT−1),间接依赖于 r T r_T rT。
- 以此类推, V ( s t ) V(s_t) V(st)通过链式依赖最终受到 r T r_T rT的影响。
这种依赖关系表明,奖励信号 r T r_T rT从序列末尾( t = T t=T t=T)开始,通过价值函数的计算,逐步“传递”到序列前部( t t t较小)。这正是“从后往前传播”的含义。
(2) GAE中的传播机制
在GAE计算中,奖励信号的传播更加明确。考虑 A ^ t \hat{A}_t A^t的展开形式:
A ^ t = δ t + λ δ t + 1 + λ 2 δ t + 2 + ⋯ + λ T − t − 1 δ T − 1 \hat{A}_t = \delta_t + \lambda \delta_{t+1} + \lambda^2 \delta_{t+2} + \cdots + \lambda^{T-t-1} \delta_{T-1} A^t=δt+λδt+1+λ2δt+2+⋯+λT−t−1δT−1
其中, δ T − 1 = r T − 1 + V ( s T ) − V ( s T − 1 ) \delta_{T-1} = r_{T-1} + V(s_T) - V(s_{T-1}) δT−1=rT−1+V(sT)−V(sT−1)包含了 r T r_T rT的贡献(假设 r T − 1 = 0 r_{T-1} = 0 rT−1=0)。这个 δ T − 1 \delta_{T-1} δT−1通过 λ T − t − 1 \lambda^{T-t-1} λT−t−1的权重影响 A ^ t \hat{A}_t A^t。换句话说,末尾的奖励 r T r_T rT通过GAE的累加机制,逐步影响前面的优势估计。
具体来说:
- 对于 t = T − 1 t = T-1 t=T−1, A ^ T − 1 \hat{A}_{T-1} A^T−1直接受到 r T r_T rT的影响。
- 对于 t = T − 2 t = T-2 t=T−2, A ^ T − 2 \hat{A}_{T-2} A^T−2通过 λ δ T − 1 \lambda \delta_{T-1} λδT−1间接受到 r T r_T rT的影响。
- 对于更早的 t t t, r T r_T rT的贡献通过更高的 λ \lambda λ次幂(如 λ T − t − 1 \lambda^{T-t-1} λT−t−1)传递。
这种从末尾奖励 r T r_T rT开始,逐级影响前面标记的 A ^ t \hat{A}_t A^t的过程,正是论文中描述的“奖励信号向序列前部传播”。
(3) 为什么不是“从前往后”?
你提到的“从前往后”(如第一个标记、第二个标记……)是序列生成的时间顺序,即模型按照 t = 1 , 2 , … , T t=1, 2, \ldots, T t=1,2,…,T的顺序生成标记。然而,奖励信号的传播与生成顺序无关,而是与价值估计和优势计算的因果关系有关:
- 在序列生成时,模型从头到尾生成标记,但此时奖励 r T r_T rT尚未出现(因为答案尚未完成)。
- 在训练阶段,价值模型和优势估计需要根据末尾的奖励 r T r_T rT来评估每个标记的贡献。由于 r T r_T rT出现在序列末尾,价值模型必须通过递归或累加的方式,将 r T r_T rT的影响“回溯”到前面的状态或标记。
因此,“传播”描述的是奖励信号在价值更新或优势估计中的传递方向,而不是序列生成的时间顺序。末尾的 r T r_T rT通过价值函数或GAE的计算,逐步影响前面的 V ( s t ) V(s_t) V(st)或 A ^ t \hat{A}_t A^t,这自然是从序列末尾(后)到序列开头(前)的过程。
5. 为什么 λ < 1 \lambda < 1 λ<1导致衰减?
当 λ < 1 \lambda < 1 λ<1时,GAE中的权重 λ i \lambda^i λi随着 i i i增大而指数衰减。对于早期标记( t t t较小), T − t T-t T−t很大, λ T − t − 1 \lambda^{T-t-1} λT−t−1变得非常小,导致 r T r_T rT对 A ^ t \hat{A}_t A^t的贡献几乎为零。论文中提到:
奖励信号传播到第 t 个标记的强度 ∝ λ T − t r T \text{奖励信号传播到第}t\text{个标记的强度} \propto \lambda^{T-t} r_T 奖励信号传播到第t个标记的强度∝λT−trT
当 λ = 0.95 \lambda = 0.95 λ=0.95且 T − t = 100 T-t = 100 T−t=100时, λ 100 ≈ 0.006 \lambda^{100} \approx 0.006 λ100≈0.006,意味着 r T r_T rT对早期标记的影响微乎其微。这会导致价值模型无法准确捕捉长期依赖,进而影响策略优化,因为早期标记的 A ^ t \hat{A}_t A^t无法反映最终奖励的真实贡献。
当 λ = 1.0 \lambda = 1.0 λ=1.0时, λ T − t = 1 \lambda^{T-t} = 1 λT−t=1,奖励信号 r T r_T rT能够无衰减地传播到所有标记,价值目标简化为:
V target ( s t ) = ∑ i = 0 T − t − 1 r t + i = r T ( 因为只有 r T ≠ 0 ) V^{\text{target}}(s_t) = \sum_{i=0}^{T-t-1} r_{t+i} = r_T \quad (\text{因为只有} r_T \neq 0) Vtarget(st)=i=0∑T−t−1rt+i=rT(因为只有rT=0)
这确保了早期标记的价值估计能够充分感知末尾奖励,从而改善长期依赖的建模。
6. VC-PPO的解决方案
VC-PPO通过解耦GAE解决了奖励信号衰减问题:
- 价值模型:设置 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0,使奖励信号 r T r_T rT无衰减地传播到早期标记,确保 V ( s t ) V(s_t) V(st)准确反映长期依赖。
- 策略模型:保持 λ actor ∈ [ 0.95 , 1.0 ] \lambda_{\text{actor}} \in [0.95, 1.0] λactor∈[0.95,1.0],以维持较低的方差,促进策略收敛。
这种设计允许价值模型更好地捕捉末尾奖励对早期标记的贡献,同时保持策略更新的稳定性。
7. 总结
- 奖励信号向前传播的含义:在Long-CoT任务中,奖励信号 r T r_T rT出现在序列末尾(处)。价值模型和GAE通过递归或累加的方式,将 r T r_T rT的影响传递到前面的状态或标记。这种传递方向是从序列末尾( t = T t=T t=T)到序列开头( t = 1 t=1 t=1),因此被描述为“从后往前传播”。
- 为什么不是从前往后:序列生成是按时间顺序从前往后,但价值估计和优势计算的因果关系是从末尾奖励回溯到前面标记,与生成顺序无关。
- 衰减的原因:当 λ < 1 \lambda < 1 λ<1时,GAE中的权重 λ T − t \lambda^{T-t} λT−t使 r T r_T rT对早期标记的影响指数衰减,导致价值模型无法捕捉长期依赖。
通过理解价值函数和GAE的计算机制,我们可以清楚地看到,奖励信号的传播本质上是动态规划中的回溯过程,而VC-PPO通过优化 λ \lambda λ解决了衰减问题,从而提升了PPO在Long-CoT任务中的性能。
Decoupled GAE解释
在论文《What’s Behind PPO’s Collapse in Long-CoT? Value Optimization Holds the Secret》中,3.3节“Improving In-training Value Estimate with Decoupled-GAE”提出了Decoupled-GAE方法,旨在解决PPO在Long-CoT任务中因奖励信号衰减导致的价值估计问题。本节详细分析了传统GAE的局限性,并通过解耦策略和价值模型的 λ \lambda λ参数来优化训练过程中的价值估计。以下将详细介绍Decoupled-GAE的核心内容,解释方差公式(公式6)和Equation 8的推导与意义,并说明这两个公式的用途。
1. Decoupled-GAE的核心思想
在传统的PPO算法中,广义优势估计(Generalized Advantage Estimation, GAE)使用单一的 λ \lambda λ参数(通常为0.95)来计算策略(actor)和价值模型(critic)的优势估计。然而,在Long-CoT任务中,奖励信号通常仅在序列末尾(处)提供,导致以下问题:
- 奖励信号衰减:当 λ < 1 \lambda < 1 λ<1时,末尾奖励 r T r_T rT对早期标记的影响通过 λ T − t \lambda^{T-t} λT−t衰减( T T T为序列长度, t t t为时间步),使得价值模型无法准确捕捉长期依赖。
- 价值与策略优化的不同需求:价值模型优化更关注低偏置(bias),以准确估计长期回报;而策略优化更关注低方差(variance),以确保训练稳定和快速收敛。
Decoupled-GAE的创新在于将策略和价值模型的GAE计算解耦,允许两者使用不同的 λ \lambda λ值:
- 价值模型:设置 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0,避免奖励信号衰减,使价值估计无偏(unbiased),更适合Long-CoT任务中的稀疏奖励场景。
- 策略模型:保持 λ actor ∈ [ 0.95 , 1.0 ] \lambda_{\text{actor}} \in [0.95, 1.0] λactor∈[0.95,1.0](如0.95或0.99),以降低优势估计的方差,加速策略收敛。
这种解耦设计在保持策略优化效率的同时,显著提升了价值模型对长序列奖励的建模能力。
2. 背景:GAE与奖励信号衰减
在介绍Decoupled-GAE之前,我们先回顾GAE的定义。GAE用于估计优势函数 A ^ t \hat{A}_t A^t,其公式为:
A ^ t = ∑ i = 0 T − t − 1 ( γ λ ) i δ t + i , 其中 δ t + i = r t + i + γ V ( s t + i + 1 ) − V ( s t + i ) \hat{A}_t = \sum_{i=0}^{T-t-1} (\gamma \lambda)^i \delta_{t+i}, \quad \text{其中} \quad \delta_{t+i} = r_{t+i} + \gamma V(s_{t+i+1}) - V(s_{t+i}) A^t=i=0∑T−t−1(γλ)iδt+i,其中δt+i=rt+i+γV(st+i+1)−V(st+i)
- δ t + i \delta_{t+i} δt+i:时序差分(TD)误差。
- r t + i r_{t+i} rt+i:即时奖励。
- γ \gamma γ:折扣因子,在RLHF中通常设为1.0(论文中为了简化,省略了 γ \gamma γ,假设 γ = 1 \gamma = 1 γ=1)。
- λ \lambda λ:GAE参数,控制偏差与方差的权衡。
- V ( s t ) V(s_t) V(st):价值模型对状态 s t s_t st的估值。
在Long-CoT任务中, r t + i = 0 r_{t+i} = 0 rt+i=0(对于 t + i < T t+i < T t+i<T),只有 r T ≠ 0 r_T \neq 0 rT=0(末尾奖励)。当 λ < 1 \lambda < 1 λ<1时, r T r_T rT对早期标记的贡献通过 λ T − t − 1 \lambda^{T-t-1} λT−t−1衰减,导致 A ^ t \hat{A}_t A^t无法有效反映末尾奖励的影响。
价值目标(value target)可以从GAE推导出来(见论文公式5):
V target ( s t ) = { ∑ i = 0 T − t − 1 λ i ( r t + i + V ( s t + i + 1 ) − V ( s t + i ) ) + V ( s t ) , λ < 1.0 ∑ i = 0 T − t − 1 r t + i , λ = 1.0 V^{\text{target}}(s_t) = \begin{cases} \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) \right) + V(s_t), & \lambda < 1.0 \\ \sum_{i=0}^{T-t-1} r_{t+i}, & \lambda = 1.0 \end{cases} Vtarget(st)={∑i=0T−t−1λi(rt+i+V(st+i+1)−V(st+i))+V(st),∑i=0T−t−1rt+i,λ<1.0λ=1.0
当 λ < 1 \lambda < 1 λ<1时, r T r_T rT的贡献被 λ T − t − 1 \lambda^{T-t-1} λT−t−1缩放,导致早期标记的价值目标几乎忽略末尾奖励。设置 λ = 1.0 \lambda = 1.0 λ=1.0可以避免衰减,但可能增加方差,这对策略优化不利。因此,Decoupled-GAE提出了解耦 λ actor \lambda_{\text{actor}} λactor和 λ critic \lambda_{\text{critic}} λcritic的方案。
3. Decoupled-GAE的实现
Decoupled-GAE的核心是将GAE计算分为两部分:
- 策略优势估计:使用 λ actor \lambda_{\text{actor}} λactor(如0.95)计算 A ^ t \hat{A}_t A^t,用于策略更新,以降低方差:
A ^ t actor = ∑ i = 0 T − t − 1 λ actor i δ t + i \hat{A}_t^{\text{actor}} = \sum_{i=0}^{T-t-1} \lambda_{\text{actor}}^i \delta_{t+i} A^tactor=i=0∑T−t−1λactoriδt+i
- 价值目标:使用 λ critic \lambda_{\text{critic}} λcritic(通常为1.0)计算价值目标 V target ( s t ) V^{\text{target}}(s_t) Vtarget(st),用于价值模型更新,以降低偏置:
V target ( s t ) = ∑ i = 0 T − t − 1 λ critic i ( r t + i + V ( s t + i + 1 ) − V ( s t + i ) ) + V ( s t ) V^{\text{target}}(s_t) = \sum_{i=0}^{T-t-1} \lambda_{\text{critic}}^i \left( r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) \right) + V(s_t) Vtarget(st)=i=0∑T−t−1λcritici(rt+i+V(st+i+1)−V(st+i))+V(st)
当 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0时, V target ( s t ) = r T V^{\text{target}}(s_t) = r_T Vtarget(st)=rT(因为 r t + i = 0 r_{t+i} = 0 rt+i=0, t + i < T t+i < T t+i<T),确保奖励信号无衰减地传播到早期标记。
在算法实现上(见论文算法1),VC-PPO分别计算:
- 策略的优势 A ^ t \hat{A}_t A^t(用 λ actor \lambda_{\text{actor}} λactor)。
- 价值目标 R R R(用 λ critic \lambda_{\text{critic}} λcritic)。
这种解耦允许价值模型专注于准确估计长期回报,而策略模型专注于稳定更新。
4. 方差公式(公式6)的解释
4.1 公式内容
论文中的方差公式(公式6)分析了GAE优势估计的方差,用于说明为什么策略优化需要较低的 λ \lambda λ值。公式如下:
Var [ A ^ t λ ] = Var [ ∑ i = 0 T − t − 1 λ i δ t + i ] = ∑ i = 0 T − t − 1 λ 2 i Var [ δ t + i ] + 2 ∑ i = 0 T − t − 1 ∑ j = i + 1 T − t − 1 λ i + j Cov [ δ t + i , δ t + j ] \text{Var}[\hat{A}_t^\lambda] = \text{Var}\left[ \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i} \right] = \sum_{i=0}^{T-t-1} \lambda^{2i} \text{Var}[\delta_{t+i}] + 2 \sum_{i=0}^{T-t-1} \sum_{j=i+1}^{T-t-1} \lambda^{i+j} \text{Cov}[\delta_{t+i}, \delta_{t+j}] Var[A^tλ]=Var[i=0∑T−t−1λiδt+i]=i=0∑T−t−1λ2iVar[δt+i]+2i=0∑T−t−1j=i+1∑T−t−1λi+jCov[δt+i,δt+j]
- A ^ t λ \hat{A}_t^\lambda A^tλ:使用 λ \lambda λ计算的优势估计。
- δ t + i \delta_{t+i} δt+i:TD误差, δ t + i = r t + i + V ( s t + i + 1 ) − V ( s t + i ) \delta_{t+i} = r_{t+i} + V(s_{t+i+1}) - V(s_{t+i}) δt+i=rt+i+V(st+i+1)−V(st+i)。
- Var [ δ t + i ] \text{Var}[\delta_{t+i}] Var[δt+i]:第 t + i t+i t+i步TD误差的方差。
- Cov [ δ t + i , δ t + j ] \text{Cov}[\delta_{t+i}, \delta_{t+j}] Cov[δt+i,δt+j]:不同时间步TD误差之间的协方差。
4.2 公式推导
优势估计 A ^ t λ \hat{A}_t^\lambda A^tλ是TD误差的加权和:
A ^ t λ = ∑ i = 0 T − t − 1 λ i δ t + i \hat{A}_t^\lambda = \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i} A^tλ=i=0∑T−t−1λiδt+i
根据方差的性质,对于加权和的随机变量 X = ∑ i a i Y i X = \sum_i a_i Y_i X=∑iaiYi,方差为:
Var [ X ] = ∑ i a i 2 Var [ Y i ] + 2 ∑ i < j a i a j Cov [ Y i , Y j ] \text{Var}[X] = \sum_i a_i^2 \text{Var}[Y_i] + 2 \sum_{i < j} a_i a_j \text{Cov}[Y_i, Y_j] Var[X]=i∑ai2Var[Yi]+2i<j∑aiajCov[Yi,Yj]
将 A ^ t λ \hat{A}_t^\lambda A^tλ代入,权重 a i = λ i a_i = \lambda^i ai=λi,随机变量 Y i = δ t + i Y_i = \delta_{t+i} Yi=δt+i,得:
Var [ A ^ t λ ] = ∑ i = 0 T − t − 1 ( λ i ) 2 Var [ δ t + i ] + 2 ∑ i = 0 T − t − 1 ∑ j = i + 1 T − t − 1 λ i λ j Cov [ δ t + i , δ t + j ] \text{Var}[\hat{A}_t^\lambda] = \sum_{i=0}^{T-t-1} (\lambda^i)^2 \text{Var}[\delta_{t+i}] + 2 \sum_{i=0}^{T-t-1} \sum_{j=i+1}^{T-t-1} \lambda^i \lambda^j \text{Cov}[\delta_{t+i}, \delta_{t+j}] Var[A^tλ]=i=0∑T−t−1(λi)2Var[δt+i]+2i=0∑T−t−1j=i+1∑T−t−1λiλjCov[δt+i,δt+j]
即:
Var [ A ^ t λ ] = ∑ i = 0 T − t − 1 λ 2 i Var [ δ t + i ] + 2 ∑ i = 0 T − t − 1 ∑ j = i + 1 T − t − 1 λ i + j Cov [ δ t + i , δ t + j ] \text{Var}[\hat{A}_t^\lambda] = \sum_{i=0}^{T-t-1} \lambda^{2i} \text{Var}[\delta_{t+i}] + 2 \sum_{i=0}^{T-t-1} \sum_{j=i+1}^{T-t-1} \lambda^{i+j} \text{Cov}[\delta_{t+i}, \delta_{t+j}] Var[A^tλ]=i=0∑T−t−1λ2iVar[δt+i]+2i=0∑T−t−1j=i+1∑T−t−1λi+jCov[δt+i,δt+j]
4.3 公式解释
这个公式揭示了 A ^ t λ \hat{A}_t^\lambda A^tλ的方差如何受到 λ \lambda λ的影响:
- 第一项: ∑ i = 0 T − t − 1 λ 2 i Var [ δ t + i ] \sum_{i=0}^{T-t-1} \lambda^{2i} \text{Var}[\delta_{t+i}] ∑i=0T−t−1λ2iVar[δt+i]表示各TD误差的方差贡献,权重为 λ 2 i \lambda^{2i} λ2i。当 λ < 1 \lambda < 1 λ<1时, λ 2 i \lambda^{2i} λ2i随 i i i增大快速衰减,意味着后期( i i i较大)的TD误差对总方差的贡献较小。这降低了高方差的TD误差(通常出现在序列末尾,因为 r T r_T rT可能波动较大)的影响。
- 第二项: 2 ∑ i = 0 T − t − 1 ∑ j = i + 1 T − t − 1 λ i + j Cov [ δ t + i , δ t + j ] 2 \sum_{i=0}^{T-t-1} \sum_{j=i+1}^{T-t-1} \lambda^{i+j} \text{Cov}[\delta_{t+i}, \delta_{t+j}] 2∑i=0T−t−1∑j=i+1T−t−1λi+jCov[δt+i,δt+j]表示TD误差之间的协方差贡献。 λ i + j \lambda^{i+j} λi+j同样随 i , j i, j i,j增大而衰减,减少了后期TD误差的相关性影响。
当 λ \lambda λ减小时(如从1.0降到0.95), λ 2 i \lambda^{2i} λ2i和 λ i + j \lambda^{i+j} λi+j的衰减更快,意味着后期的高方差TD误差(特别是接近 r T r_T rT的误差)对 A ^ t λ \hat{A}_t^\lambda A^tλ的影响被显著削弱,从而降低总方差。
4.4 公式的用途
方差公式用于说明为什么策略优化需要较低的 λ \lambda λ值:
- 策略更新的稳定性:PPO的策略更新依赖于优势估计 A ^ t \hat{A}_t A^t,通过梯度 ∇ θ log π θ ( a t ∣ s t ) A ^ t \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t ∇θlogπθ(at∣st)A^t进行优化。如果 A ^ t \hat{A}_t A^t的方差过高,策略梯度会变得不稳定,导致训练震荡或收敛缓慢。
- 长序列的挑战:在Long-CoT任务中,序列长度 T − t T-t T−t可能很大, λ = 1.0 \lambda = 1.0 λ=1.0会导致所有TD误差均等地贡献方差,尤其是末尾的 r T r_T rT可能引入较大波动(例如正确与错误的奖励差异)。降低 λ \lambda λ(如0.95)可以削弱后期TD误差的影响,从而减少 A ^ t \hat{A}_t A^t的方差,提升策略优化的效率。
- 计算资源的约束:如论文所述,训练大语言模型需要大量计算资源,较低的 λ \lambda λ通过减少方差可以加速收敛,符合实际工程需求。
然而,较低的 λ \lambda λ会导致奖励信号衰减(偏置增加),对价值模型不利。因此,Decoupled-GAE允许 λ actor < 1 \lambda_{\text{actor}} < 1 λactor<1以优化策略,而 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0以优化价值估计。
5. Equation 8的解释
5.1 公式内容
Equation 8证明了使用不同 λ \lambda λ值的价值函数( V ˉ \bar{V} Vˉ,可能由 λ critic \lambda_{\text{critic}} λcritic计算)不会为策略梯度引入额外偏置。公式如下:
E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] = E t [ ∇ θ log π θ ( a t ∣ s t ) ∑ i = 0 T − t − 1 λ i ( r t + i + V ˉ ( s t + i + 1 ) − V ˉ ( s t + i ) ) ] \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] = \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+i}) \right) \right] Et[∇θlogπθ(at∣st)A^t]=Et[∇θlogπθ(at∣st)i=0∑T−t−1λi(rt+i+Vˉ(st+i+1)−Vˉ(st+i))]
= E t [ ∇ θ log π θ ( a t ∣ s t ) ( ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T − V ˉ ( s t ) ) ] = \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \left( (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) \right) \right] =Et[∇θlogπθ(at∣st)((1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T−Vˉ(st))]
= E t [ ∇ θ log π θ ( a t ∣ s t ) ( ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T ) ] = \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \left( (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} \right) \right] =Et[∇θlogπθ(at∣st)((1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T)]
其中:
- A ^ t \hat{A}_t A^t:使用 λ \lambda λ(即 λ actor \lambda_{\text{actor}} λactor)计算的优势估计。
- V ˉ \bar{V} Vˉ:可能使用不同 λ \lambda λ(如 λ critic \lambda_{\text{critic}} λcritic)计算的价值函数。
- G t : t + h G_{t:t+h} Gt:t+h: n n n-步回报,定义为:
G t : t + h = { ∑ i = 0 h − 1 r t + i + V ˉ ( s t + h ) , t + h < T ∑ i = 0 T − t − 1 r t + i , t + h = T G_{t:t+h} = \begin{cases} \sum_{i=0}^{h-1} r_{t+i} + \bar{V}(s_{t+h}), & t+h < T \\ \sum_{i=0}^{T-t-1} r_{t+i}, & t+h = T \end{cases} Gt:t+h={∑i=0h−1rt+i+Vˉ(st+h),∑i=0T−t−1rt+i,t+h<Tt+h=T
5.2 公式推导
为了验证 V ˉ \bar{V} Vˉ(使用不同 λ \lambda λ)不引入偏置,我们需要证明策略梯度 E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] \mathbb{E}_t [ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t ] Et[∇θlogπθ(at∣st)A^t]的期望不因 V ˉ \bar{V} Vˉ的变化而改变。
步骤1:优势估计的原始形式
优势估计为:
A ^ t = ∑ i = 0 T − t − 1 λ i ( r t + i + V ˉ ( s t + i + 1 ) − V ˉ ( s t + i ) ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+i}) \right) A^t=i=0∑T−t−1λi(rt+i+Vˉ(st+i+1)−Vˉ(st+i))
策略梯度为:
E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] = E t [ ∇ θ log π θ ( a t ∣ s t ) ∑ i = 0 T − t − 1 λ i ( r t + i + V ˉ ( s t + i + 1 ) − V ˉ ( s t + i ) ) ] \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] = \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+i}) \right) \right] Et[∇θlogπθ(at∣st)A^t]=Et[∇θlogπθ(at∣st)i=0∑T−t−1λi(rt+i+Vˉ(st+i+1)−Vˉ(st+i))]
步骤2:重写优势估计
我们将 A ^ t \hat{A}_t A^t重写为 n n n-步回报的形式。定义 n n n-步回报 G t : t + i G_{t:t+i} Gt:t+i:
G t : t + i = ∑ k = 0 i − 1 r t + k + V ˉ ( s t + i ) , 对于 i < T − t G_{t:t+i} = \sum_{k=0}^{i-1} r_{t+k} + \bar{V}(s_{t+i}), \quad \text{对于} \ i < T-t Gt:t+i=k=0∑i−1rt+k+Vˉ(st+i),对于 i<T−t
G t : T = ∑ k = 0 T − t − 1 r t + k , 对于 i = T − t G_{t:T} = \sum_{k=0}^{T-t-1} r_{t+k}, \quad \text{对于} \ i = T-t Gt:T=k=0∑T−t−1rt+k,对于 i=T−t
现在,我们尝试将 A ^ t \hat{A}_t A^t表示为 G t : t + i G_{t:t+i} Gt:t+i的组合。考虑以下变换:
A ^ t = ∑ i = 0 T − t − 1 λ i δ t + i , δ t + i = r t + i + V ˉ ( s t + i + 1 ) − V ˉ ( s t + I ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i \delta_{t+i}, \quad \delta_{t+i} = r_{t+i} + \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+I}) A^t=i=0∑T−t−1λiδt+i,δt+i=rt+i+Vˉ(st+i+1)−Vˉ(st+I)
我们可以通过数学归纳或直接展开来验证 A ^ t \hat{A}_t A^t的等价形式。目标是将其重写为:
A ^ t = ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T − V ˉ ( s t ) \hat{A}_t = (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) A^t=(1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T−Vˉ(st)
展开 A ^ t \hat{A}_t A^t:
A ^ t = ∑ i = 0 T − t − 1 λ i ( r t + i + V ˉ ( s t + i + 1 ) − V ˉ ( s t + i ) ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i \left( r_{t+i} + \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+i}) \right) A^t=i=0∑T−t−1λi(rt+i+Vˉ(st+i+1)−Vˉ(st+i))
将其分解:
A ^ t = ∑ i = 0 T − t − 1 λ i r t + i + ∑ i = 0 T − t − 1 λ i V ˉ ( s t + i + 1 ) − ∑ i = 0 T − t − 1 λ i V ˉ ( s t + I ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i r_{t+i} + \sum_{i=0}^{T-t-1} \lambda^i \bar{V}(s_{t+i+1}) - \sum_{i=0}^{T-t-1} \lambda^i \bar{V}(s_{t+I}) A^t=i=0∑T−t−1λirt+i+i=0∑T−t−1λiVˉ(st+i+1)−i=0∑T−t−1λiVˉ(st+I)
重新组织 V ˉ \bar{V} Vˉ项:
∑ i = 0 T − t − 1 λ i V ˉ ( s t + i + 1 ) = λ V ˉ ( s t + 1 ) + λ 2 V ˉ ( s t + 2 ) + ⋯ + λ T − t − 1 V ˉ ( s T ) \sum_{i=0}^{T-t-1} \lambda^i \bar{V}(s_{t+i+1}) = \lambda \bar{V}(s_{t+1}) + \lambda^2 \bar{V}(s_{t+2}) + \cdots + \lambda^{T-t-1} \bar{V}(s_T) i=0∑T−t−1λiVˉ(st+i+1)=λVˉ(st+1)+λ2Vˉ(st+2)+⋯+λT−t−1Vˉ(sT)
∑ i = 0 T − t − 1 λ i V ˉ ( s t + i ) = V ˉ ( s t ) + λ V ˉ ( s t + 1 ) + λ 2 V ˉ ( s t + 2 ) + ⋯ + λ T − t − 1 V ˉ ( s T − 1 ) \sum_{i=0}^{T-t-1} \lambda^i \bar{V}(s_{t+i}) = \bar{V}(s_t) + \lambda \bar{V}(s_{t+1}) + \lambda^2 \bar{V}(s_{t+2}) + \cdots + \lambda^{T-t-1} \bar{V}(s_{T-1}) i=0∑T−t−1λiVˉ(st+i)=Vˉ(st)+λVˉ(st+1)+λ2Vˉ(st+2)+⋯+λT−t−1Vˉ(sT−1)
相减:
∑ i = 0 T − t − 1 λ i ( V ˉ ( s t + i + 1 ) − V ˉ ( s t + i ) ) = ( λ V ˉ ( s t + 1 ) + λ 2 V ˉ ( s t + 2 ) + ⋯ + λ T − t − 1 V ˉ ( s T ) ) − ( V ˉ ( s t ) + λ V ˉ ( s t + 1 ) + ⋯ + λ T − t − 2 V ˉ ( s T − 1 ) ) \sum_{i=0}^{T-t-1} \lambda^i \left( \bar{V}(s_{t+i+1}) - \bar{V}(s_{t+i}) \right) = \left( \lambda \bar{V}(s_{t+1}) + \lambda^2 \bar{V}(s_{t+2}) + \cdots + \lambda^{T-t-1} \bar{V}(s_T) \right) - \left( \bar{V}(s_t) + \lambda \bar{V}(s_{t+1}) + \cdots + \lambda^{T-t-2} \bar{V}(s_{T-1}) \right) i=0∑T−t−1λi(Vˉ(st+i+1)−Vˉ(st+i))=(λVˉ(st+1)+λ2Vˉ(st+2)+⋯+λT−t−1Vˉ(sT))−(Vˉ(st)+λVˉ(st+1)+⋯+λT−t−2Vˉ(sT−1))
整理后:
= − V ˉ ( s t ) + λ T − t − 1 V ˉ ( s T ) + ∑ i = 1 T − t − 2 λ i V ˉ ( s t + i + 1 ) − ∑ i = 1 T − t − 2 λ i V ˉ ( s t + I ) = -\bar{V}(s_t) + \lambda^{T-t-1} \bar{V}(s_T) + \sum_{i=1}^{T-t-2} \lambda^i \bar{V}(s_{t+i+1}) - \sum_{i=1}^{T-t-2} \lambda^i \bar{V}(s_{t+I}) =−Vˉ(st)+λT−t−1Vˉ(sT)+i=1∑T−t−2λiVˉ(st+i+1)−i=1∑T−t−2λiVˉ(st+I)
继续展开,直到最后一项,最终得到:
A ^ t = ∑ i = 0 T − t − 1 λ i r t + i − V ˉ ( s t ) + λ T − t − 1 V ˉ ( s T ) \hat{A}_t = \sum_{i=0}^{T-t-1} \lambda^i r_{t+i} - \bar{V}(s_t) + \lambda^{T-t-1} \bar{V}(s_T) A^t=i=0∑T−t−1λirt+i−Vˉ(st)+λT−t−1Vˉ(sT)
现在将 r t + i r_{t+i} rt+i项与 G t : t + i G_{t:t+i} Gt:t+i关联:
∑ i = 0 T − t − 1 λ i r t + i = ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 ( ∑ k = 0 i − 1 r t + k ) + λ T − t − 1 ∑ k = 0 T − t − 1 r t + k \sum_{i=0}^{T-t-1} \lambda^i r_{t+i} = (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} \left( \sum_{k=0}^{i-1} r_{t+k} \right) + \lambda^{T-t-1} \sum_{k=0}^{T-t-1} r_{t+k} i=0∑T−t−1λirt+i=(1−λ)i=1∑T−t−1λi−1(k=0∑i−1rt+k)+λT−t−1k=0∑T−t−1rt+k
结合 G t : t + i G_{t:t+i} Gt:t+i的定义,验证等价性,最终得到:
A ^ t = ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T − V ˉ ( s t ) \hat{A}_t = (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) A^t=(1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T−Vˉ(st)
步骤3:验证无偏性
策略梯度的期望为:
E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] Et[∇θlogπθ(at∣st)A^t]
代入重写的 A ^ t \hat{A}_t A^t:
A ^ t = ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T − V ˉ ( s t ) \hat{A}_t = (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) A^t=(1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T−Vˉ(st)
策略梯度变为:
E t [ ∇ θ log π θ ( a t ∣ s t ) ( ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T − V ˉ ( s t ) ) ] \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \left( (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) \right) \right] Et[∇θlogπθ(at∣st)((1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T−Vˉ(st))]
根据策略梯度的性质, E t [ ∇ θ log π θ ( a t ∣ s t ) f ( s t ) ] = 0 \mathbb{E}_t [ \nabla_\theta \log \pi_\theta(a_t | s_t) f(s_t) ] = 0 Et[∇θlogπθ(at∣st)f(st)]=0(对于任意与动作无关的函数 f ( s t ) f(s_t) f(st)),因此:
E t [ ∇ θ log π θ ( a t ∣ s t ) V ˉ ( s t ) ] = 0 \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \bar{V}(s_t) \right] = 0 Et[∇θlogπθ(at∣st)Vˉ(st)]=0
于是:
E t [ ∇ θ log π θ ( a t ∣ s t ) A ^ t ] = E t [ ∇ θ log π θ ( a t ∣ s t ) ( ( 1 − λ ) ∑ i = 1 T − t − 1 λ i − 1 G t : t + i + λ T − t − 1 G t : T ) ] \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \hat{A}_t \right] = \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t | s_t) \left( (1-\lambda) \sum_{i=1}^{T-t-1} \lambda^{i-1} G_{t:t+i} + \lambda^{T-t-1} G_{t:T} \right) \right] Et[∇θlogπθ(at∣st)A^t]=Et[∇θlogπθ(at∣st)((1−λ)i=1∑T−t−1λi−1Gt:t+i+λT−t−1Gt:T)]
这表明, A ^ t \hat{A}_t A^t的期望不依赖于 V ˉ \bar{V} Vˉ的具体形式(即 V ˉ \bar{V} Vˉ是否由不同的 λ \lambda λ计算)。因此,使用 λ critic ≠ λ actor \lambda_{\text{critic}} \neq \lambda_{\text{actor}} λcritic=λactor的 V ˉ \bar{V} Vˉ不会改变策略梯度的期望,即不会引入偏置。
5.3 公式解释
Equation 8证明了以下关键点:
- 无偏性:策略梯度的期望仅依赖于 n n n-步回报 G t : t + i G_{t:t+i} Gt:t+i和 G t : T G_{t:T} Gt:T的加权组合,而与 V ˉ \bar{V} Vˉ的定义无关。这意味着即使 V ˉ \bar{V} Vˉ由 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0计算(而 A ^ t \hat{A}_t A^t由 λ actor = 0.95 \lambda_{\text{actor}} = 0.95 λactor=0.95计算),策略梯度仍然是无偏的。
- 灵活性:解耦 λ actor \lambda_{\text{actor}} λactor和 λ critic \lambda_{\text{critic}} λcritic不会破坏PPO的理论保证,允许我们在价值优化中使用 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0以降低偏置,而在策略优化中使用 λ actor < 1 \lambda_{\text{actor}} < 1 λactor<1以降低方差。
5.4 公式的用途
Equation 8的用途在于为Decoupled-GAE提供理论依据:
- 支持解耦设计:它证明了使用不同 λ \lambda λ值( λ actor \lambda_{\text{actor}} λactor和 λ critic \lambda_{\text{critic}} λcritic)计算优势和价值目标不会影响策略梯度的正确性。这为VC-PPO的实现提供了信心,允许灵活调整 λ \lambda λ以满足价值和策略优化的不同需求。
- 优化长序列任务:在Long-CoT任务中, λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0确保价值模型准确捕捉末尾奖励的长期依赖,而 λ actor < 1 \lambda_{\text{actor}} < 1 λactor<1确保策略更新稳定,从而兼顾性能和效率。
- 通用性:这一结果不仅适用于Long-CoT任务,还可能推广到其他稀疏奖励或长序列的RL场景,为RLHF算法设计提供了理论指导。
6. 两个公式的综合意义
-
方差公式(公式6):
- 作用:揭示了 λ \lambda λ对优势估计方差的影响,解释了为什么策略优化需要较低的 λ \lambda λ(如0.95)以减少方差,加速收敛。
- 在Decoupled-GAE中的意义:支持将 λ actor \lambda_{\text{actor}} λactor设为小于1.0,以优化策略更新的稳定性,而不强制价值模型使用相同的 λ \lambda λ。
-
Equation 8:
- 作用:证明了解耦 λ actor \lambda_{\text{actor}} λactor和 λ critic \lambda_{\text{critic}} λcritic不会引入策略梯度偏置,保证了Decoupled-GAE的理论正确性。
- 在Decoupled-GAE中的意义:为 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0提供了理论支持,使价值模型能够无偏地估计长期回报,解决奖励信号衰减问题。
综合来看,这两个公式共同支撑了Decoupled-GAE的设计:
- 方差公式强调了策略优化对低方差的需求,提示我们保持 λ actor < 1 \lambda_{\text{actor}} < 1 λactor<1。
- Equation 8确保了解耦设计的无偏性,允许 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0以优化价值估计。
7. Decoupled-GAE的效果
论文中的实验结果验证了Decoupled-GAE的有效性:
- 性能提升:在AIME数据集上,VC-PPO(包含Decoupled-GAE)将基线PPO的pass@1得分从5.6提升到41.9(8k上下文),显著优于仅使用单一 λ \lambda λ的配置。
- 消融研究:移除Decoupled-GAE(即 λ actor = λ critic = 0.95 \lambda_{\text{actor}} = \lambda_{\text{critic}} = 0.95 λactor=λcritic=0.95)导致性能下降(pass@1降至29.4),表明 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0对价值估计至关重要。
- λ actor \lambda_{\text{actor}} λactor选择:实验表明 λ actor = 0.99 \lambda_{\text{actor}} = 0.99 λactor=0.99在AIME任务中表现最佳,但 λ actor ∈ [ 0.95 , 1.0 ] \lambda_{\text{actor}} \in [0.95, 1.0] λactor∈[0.95,1.0]均优于 λ actor = 1.0 \lambda_{\text{actor}} = 1.0 λactor=1.0,验证了方差公式关于低 λ \lambda λ的预测。
8. 总结
Decoupled-GAE通过解耦策略和价值模型的GAE计算,解决了Long-CoT任务中奖励信号衰减的问题。其核心在于:
- 价值优化:设置 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0,避免奖励信号在长序列中的衰减,确保价值模型准确捕捉末尾奖励的长期依赖。
- 策略优化:保持 λ actor < 1 \lambda_{\text{actor}} < 1 λactor<1(如0.95或0.99),通过降低优势估计的方差提高训练效率。
方差公式(公式6) 量化了 λ \lambda λ对方差的影响,解释了策略优化需要较低 λ \lambda λ的原因,为 λ actor \lambda_{\text{actor}} λactor的选择提供了依据。Equation 8证明了解耦 λ \lambda λ的无偏性,为Decoupled-GAE的理论正确性提供了保障。这两个公式共同支持了VC-PPO的设计,使其在AIME等复杂推理任务中显著优于基线PPO,为RLHF在长序列任务中的应用提供了重要启示。
代码实现
由于篇幅限制,具体的代码实现请参考笔者的另一篇博客:ByteDance Seed团队:Value-Calibrated Proximal Policy Optimization (VC-PPO)(二)代码实现
后记
2025年4月14日于上海,在grok 3大模型辅助下完成。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









