










VAPO:高效解决长链推理任务的强化学习框架
在大型语言模型(LLM)的快速发展中,长链推理(Long Chain-of-Thought, Long-CoT) 任务(如数学推理、复杂问题求解)对模型的推理能力提出了更高要求。然而,传统的强化学习(RL)方法在处理此类任务时常常面临性能瓶颈,例如输出长度崩溃、训练不稳定等。ByteDance Seed团队在论文《VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks》中提出了VAPO(Value-based Augmented Proximal Policy Optimization),一个专为长链推理任务设计的价值导向强化学习框架。本文将介绍VAPO解决的问题、核心方法及其显著优势。
下文中图片来自于原论文:https://arxiv.org/pdf/2504.05118
VAPO解决的问题
长链推理任务要求模型通过逐步推理生成详细的解答,例如在数学竞赛(如AIME)中,模型需要在数百个标记(token)的序列中保持逻辑连贯,最终输出正确答案。传统强化学习方法(如PPO)在这些任务中面临以下三大挑战:
-
价值模型偏差(Value Model Bias):
- 价值模型通常从奖励模型初始化,但奖励模型只关注序列末尾的评分(如
<EOS>标记),对早期标记的估计偏低。这种初始化偏差导致价值模型无法准确预测长期回报。 - 传统GAE(广义优势估计)使用固定 λ \lambda λ(如0.95),在长序列中会导致奖励信号通过 λ T − t \lambda^{T-t} λT−t指数衰减( T T T为序列长度, t t t为时间步),使得早期标记几乎感知不到末尾奖励,进一步加剧偏差。
- 价值模型通常从奖励模型初始化,但奖励模型只关注序列末尾的评分(如
-
异构序列长度(Heterogeneous Sequence Lengths):
- 长链推理任务的生成序列长度变化很大(从几十到数百标记)。固定
λ
\lambda
λ的GAE无法适应不同长度的序列:
- 短序列:高方差(variance),因为依赖实际奖励的波动。
- 长序列:高偏差(bias),因为过多依赖可能不准确的未来价值估计。
- 这种不平衡使得模型在优化短序列和长序列时难以达到一致的性能。
- 长链推理任务的生成序列长度变化很大(从几十到数百标记)。固定
λ
\lambda
λ的GAE无法适应不同长度的序列:
-
奖励信号稀疏(Sparsity of Reward Signal):
- 在验证器驱动的任务(如AIME评分)中,奖励通常是二元的(正确为1,错误为0),且仅在序列末尾提供。这种稀疏性导致正确答案的采样极为困难,模型需要在探索(exploration)和利用(exploitation)之间找到平衡。
- 稀疏奖励加剧了训练的不稳定性,可能导致模型陷入次优解或浪费计算资源在无效探索上。
这些问题共同导致传统PPO在长链推理任务中性能低下,例如输出长度急剧缩短(“长度崩溃”)或推理能力退化。VAPO通过一系列创新设计,系统性地解决了这些挑战。
VAPO的核心方法
VAPO基于PPO算法,整合了VC-PPO [笔者的博客:ByteDance Seed团队:解锁PPO在长链思考任务中的潜力——VC-PPO的创新突破(一):原理介绍]、DAPO [笔者的博客:字节DAPO算法:改进DeepSeek的GRPO算法-解锁大规模LLM强化学习的新篇章(代码实现)]、GRPO (笔者的博客:DeepSeek-R1:冷启动下的强化学习之旅(代码实现))等方法的技术,并引入了新的优化策略。以下是VAPO的七大核心方法及其作用:
1. 价值预训练(Value Pretraining)
- 问题针对:解决价值模型初始化偏差。
- 方法:
- 使用固定策略(如SFT模型)生成响应序列,以蒙特卡洛回报(Monte-Carlo Return, λ = 1.0 \lambda=1.0 λ=1.0)训练价值模型。
- 优化目标是最小化价值损失(MSE)和提高解释方差(explained variance),直至收敛。
- 保存预训练检查点,供后续RL训练使用。
- 效果:通过无偏的蒙特卡洛回报,消除奖励模型带来的偏差,使价值模型能准确估计长期回报。
2. 解耦GAE(Decoupled-GAE)
- 问题针对:缓解长序列中的奖励信号衰减。
- 方法:
- 将GAE的
λ
\lambda
λ参数解耦为:
- 价值更新: λ critic = 1.0 \lambda_{\text{critic}}=1.0 λcritic=1.0,使用无偏的蒙特卡洛回报,确保奖励信号完整传播到早期标记。
- 策略更新: λ actor = 0.95 \lambda_{\text{actor}}=0.95 λactor=0.95(或动态调整),降低优势估计的方差,加速策略收敛。
- 将GAE的
λ
\lambda
λ参数解耦为:
- 效果:价值模型捕捉长期依赖,策略优化保持稳定性,兼顾准确性和效率。
3. 长度自适应GAE(Length-Adaptive GAE)
- 问题针对:处理异构序列长度导致的偏差-方差权衡问题。
- 方法:
- 动态调整策略的
λ
actor
\lambda_{\text{actor}}
λactor,基于序列长度
l
l
l:
λ actor = 1 − 1 α l \lambda_{\text{actor}} = 1 - \frac{1}{\alpha l} λactor=1−αl1
其中 α \alpha α为超参数(VAPO设为0.05),控制整体权衡。 - 对于短序列, λ actor \lambda_{\text{actor}} λactor较小,减少方差;对于长序列, λ actor \lambda_{\text{actor}} λactor接近1.0,减少偏差。
- 动态调整策略的
λ
actor
\lambda_{\text{actor}}
λactor,基于序列长度
l
l
l:
- 效果:确保短序列和长序列的优势估计都具有合适的偏差-方差特性,提升模型对不同长度响应的优化能力。
4. 更高裁剪范围(Clip-Higher)
- 问题针对:缓解稀疏奖励下的熵崩溃(entropy collapse),即模型过早收敛到低概率动作。
- 方法:
- 解耦PPO的裁剪范围,设置 ϵ low = 0.2 \epsilon_{\text{low}}=0.2 ϵlow=0.2, ϵ high = 0.28 \epsilon_{\text{high}}=0.28 ϵhigh=0.28。
- 更高的 ϵ high \epsilon_{\text{high}} ϵhigh为低概率动作提供更多上升空间,鼓励探索;较小的 ϵ low \epsilon_{\text{low}} ϵlow防止高概率动作被过度抑制。
- 效果:增强探索能力,避免模型陷入次优解,特别是在奖励稀疏的场景中。
5. 标记级策略梯度损失(Token-Level Policy Gradient Loss)
- 问题针对:传统序列级损失对长序列的权重不足,导致长序列问题难以有效优化。
- 方法:
- 修改PPO损失函数,将序列级平均改为标记级平均:
L PPO ( θ ) = − 1 ∑ i = 1 G ∣ σ i ∣ ∑ i = 1 G ∑ t = 1 ∣ σ i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \mathcal{L}_{\text{PPO}}(\theta) = -\frac{1}{\sum_{i=1}^G |\sigma_i|} \sum_{i=1}^G \sum_{t=1}^{|\sigma_i|} \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t} \right) LPPO(θ)=−∑i=1G∣σi∣1i=1∑Gt=1∑∣σi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t) - 每个标记的损失贡献均等,无论序列长度。
- 修改PPO损失函数,将序列级平均改为标记级平均:
- 效果:长序列的优化权重增加,模型更关注长链推理中的关键步骤,提升训练稳定性。
6. 正例语言模型损失(Positive Example LM Loss)
- 问题针对:提高稀疏奖励下正确样本的利用效率。
- 方法:
- 对采样到的正确答案(正例),添加负对数似然(NLL)损失:
L NLL ( θ ) = − 1 ∑ σ i ∈ T ∣ σ i ∣ ∑ σ i ∈ T ∑ t = 1 ∣ σ i ∣ log π θ ( a t ∣ s t ) \mathcal{L}_{\text{NLL}}(\theta) = -\frac{1}{\sum_{\sigma_i \in \mathcal{T}} |\sigma_i|} \sum_{\sigma_i \in \mathcal{T}} \sum_{t=1}^{|\sigma_i|} \log \pi_\theta(a_t | s_t) LNLL(θ)=−∑σi∈T∣σi∣1σi∈T∑t=1∑∣σi∣logπθ(at∣st)
其中 T \mathcal{T} T为正确答案集合。 - 总损失为: L ( θ ) = L PPO ( θ ) + μ ⋅ L NLL ( θ ) \mathcal{L}(\theta) = \mathcal{L}_{\text{PPO}}(\theta) + \mu \cdot \mathcal{L}_{\text{NLL}}(\theta) L(θ)=LPPO(θ)+μ⋅LNLL(θ), μ = 0.1 \mu=0.1 μ=0.1。
- 对采样到的正确答案(正例),添加负对数似然(NLL)损失:
- 效果:通过模仿学习增强正例的学习,减少试错成本,提升训练效率。
7. 组采样(Group-Sampling)
- 问题针对:优化稀疏奖励下的探索-利用平衡。
- 方法:
- 减少每批次使用的提示数量(512个提示),但对每个提示重复采样多次(16次)。
- 相比于单次采样更多提示,组采样提供更丰富的对比信号(正例与负例)。
- 效果:增强模型对同一提示下不同响应的学习能力,提高正确答案的采样概率。
VAPO的性能表现
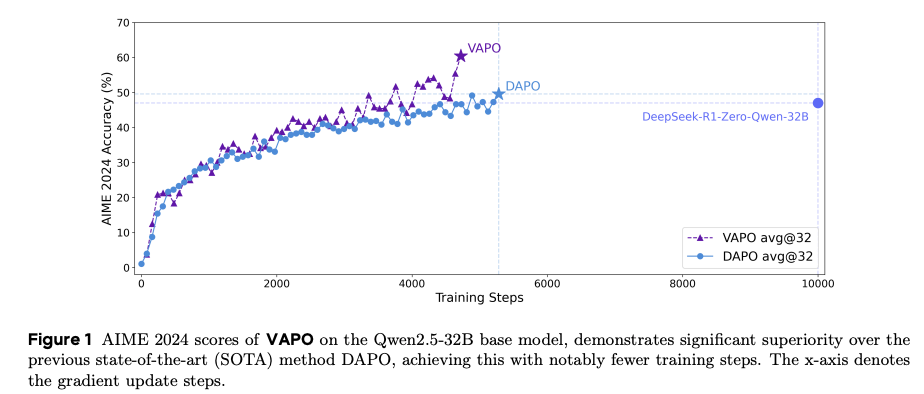
VAPO在AIME 2024数据集上的表现令人瞩目,基于Qwen2.5-32B模型取得了60.4的得分,超越了之前的SOTA方法DAPO(50分)和DeepSeek-R1-Zero-Qwen-32B(47分),比传统PPO(5分)提升了12倍。具体优势包括:
- 高效性:VAPO仅需5000步梯度更新即可达到SOTA性能,比DAPO少用40%的训练步数。
- 稳定性:多次独立运行无训练崩溃,分数稳定在60-61之间,熵变化平滑,避免了长度崩溃。
- 长序列优化:VAPO在长序列上的表现尤为突出,生成长度和推理质量均优于DAPO。
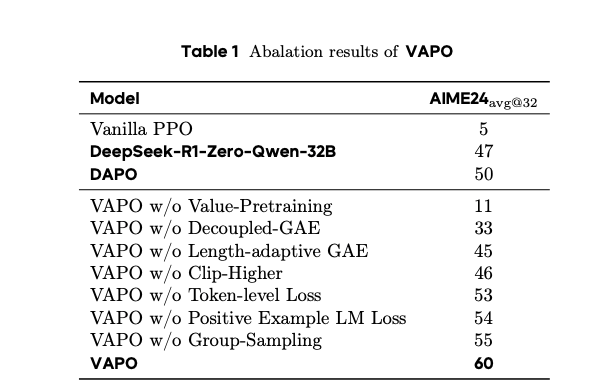
消融实验进一步验证了每个方法的贡献:
- 无价值预训练:得分降至11,模型发生长度崩溃。
- 无解耦GAE:得分降至33,奖励信号衰减严重。
- 无长度自适应GAE:得分降至45,异构序列优化受限。
- 无更高裁剪:得分降至46,探索不足。
- 无标记级损失:得分降至53,长序列优化不足。
- 无正例LM损失:得分降至54,正例利用效率降低。
- 无组采样:得分降至55,对比信号不足。
总结
VAPO通过整合价值预训练、解耦GAE、长度自适应GAE等七大创新方法,成功解决了长链推理任务中的三大难题:价值模型偏差、异构序列长度和奖励信号稀疏。它不仅在性能上大幅超越了无价值方法(如DAPO、GRPO),还在训练效率和稳定性上树立了新标杆。对于研究者和开发者而言,VAPO提供了一个强大的强化学习框架,适用于数学推理、代码生成等需要深入推理的复杂任务。未来,VAPO的设计理念有望推广到更多RLHF场景,推动大型语言模型在推理能力上的进一步突破。
长度自适应GAE
为了详细解释 长度自适应GAE(Length-Adaptive GAE),我们需要从以下几个方面展开:首先明确 λ \lambda λ的含义及其与序列长度的关系,然后分析偏差-方差权衡问题,最后给出代码实现并说明如何在实践中应用。我们将结合论文《VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks》和长链推理(Long-CoT)任务的背景,深入剖析这一方法。
1. λ \lambda λ是什么?与序列长度的关系
1.1 λ \lambda λ的定义
在强化学习(RL)中,广义优势估计(Generalized Advantage Estimation, GAE) 用于计算优势函数 A ^ t \hat{A}_t A^t,帮助策略优化。GAE的公式为:
A ^ t = ∑ i = 0 T − t − 1 ( γ λ ) i δ t + i , 其中 δ t + i = r t + i + γ V ( s t + i + 1 ) − V ( s t + i ) \hat{A}_t = \sum_{i=0}^{T-t-1} (\gamma \lambda)^i \delta_{t+i}, \quad \text{其中} \quad \delta_{t+i} = r_{t+i} + \gamma V(s_{t+i+1}) - V(s_{t+i}) A^t=i=0∑T−t−1(γλ)iδt+i,其中δt+i=rt+i+γV(st+i+1)−V(st+i)
- δ t + i \delta_{t+i} δt+i:时序差分(TD)误差,表示即时奖励 r t + i r_{t+i} rt+i加上下一状态的价值估计 γ V ( s t + i + 1 ) \gamma V(s_{t+i+1}) γV(st+i+1)与当前状态价值 V ( s t + i ) V(s_{t+i}) V(st+i)的差。
- γ \gamma γ:折扣因子,在RLHF(如Long-CoT任务)中通常设为1.0(论文中也省略 γ \gamma γ,假设 γ = 1 \gamma=1 γ=1)。
- λ \lambda λ:GAE参数,范围 [ 0 , 1 ] [0, 1] [0,1],控制偏差(bias)和方差(variance)的权衡。
- T T T:序列总长度, t t t:当前时间步。
λ \lambda λ的作用是决定优势估计如何在以下两种极端方法之间插值:
- λ = 0 \lambda = 0 λ=0:仅使用单步TD误差( A ^ t = δ t \hat{A}_t = \delta_t A^t=δt),方差低但偏差高,因为它忽略了长期回报。
- λ = 1 \lambda = 1 λ=1:等价于蒙特卡洛回报(Monte-Carlo Return, A ^ t = ∑ i = 0 T − t − 1 r t + i − V ( s t ) \hat{A}_t = \sum_{i=0}^{T-t-1} r_{t+i} - V(s_t) A^t=∑i=0T−t−1rt+i−V(st)),偏差为零(无偏),但方差高,因为它直接依赖整个轨迹的随机奖励。
在Long-CoT任务中,奖励通常是稀疏的,仅在序列末尾( t = T t=T t=T)提供(如 r T = 1 r_T = 1 rT=1或 0 0 0,其他 r t + i = 0 r_{t+i} = 0 rt+i=0)。这使得 λ \lambda λ的选择对训练效果尤为重要。
1.2 固定 λ \lambda λ的问题
传统GAE(如VC-PPO中使用的 λ actor = 0.95 \lambda_{\text{actor}} = 0.95 λactor=0.95)假设所有序列适合相同的 λ \lambda λ值。然而,在Long-CoT任务中,序列长度 l = T − t l = T-t l=T−t(剩余标记数)差异很大(从几十到数百标记),固定 λ \lambda λ会导致以下问题:
-
短序列(如 l = 10 l=10 l=10):
- λ = 0.95 \lambda = 0.95 λ=0.95时,末尾奖励 r T r_T rT的贡献为 λ l − 1 = 0.9 5 9 ≈ 0.63 \lambda^{l-1} = 0.95^9 \approx 0.63 λl−1=0.959≈0.63,仍保留部分信号,但优势估计主要依赖实际奖励 r T r_T rT,导致方差较高(因为 r T r_T rT可能是 1 1 1或 0 0 0,波动大)。
- 短序列更需要低方差估计,以稳定策略更新。
-
长序列(如 l = 100 l=100 l=100):
- λ = 0.95 \lambda = 0.95 λ=0.95时, r T r_T rT的贡献为 λ l − 1 = 0.9 5 99 ≈ 0.006 \lambda^{l-1} = 0.95^{99} \approx 0.006 λl−1=0.9599≈0.006,几乎衰减为零。优势估计几乎完全依赖价值模型 V ( s t + i ) V(s_{t+i}) V(st+i)的 bootstrapping(自举),但价值模型可能不准确,导致偏差(bias)积累。
- 长序列需要低偏差估计,以确保末尾奖励信号能有效传播到早期标记。
因此,固定 λ \lambda λ无法同时满足短序列(低方差)和长序列(低偏差)的需求,导致优化效果不佳。
1.3 长度自适应GAE的解决方案
VAPO提出长度自适应GAE,动态调整 λ actor \lambda_{\text{actor}} λactor以适应序列长度 l l l,公式为:
λ actor = 1 − 1 α l \lambda_{\text{actor}} = 1 - \frac{1}{\alpha l} λactor=1−αl1
- l l l:序列长度(通常为生成部分的标记数,即 T − t T-t T−t)。
- α \alpha α:超参数,控制偏差-方差权衡的强度,VAPO设为0.05。
- 公式含义:
- 短序列(小 l l l): α l \alpha l αl较小, 1 α l \frac{1}{\alpha l} αl1较大, λ actor \lambda_{\text{actor}} λactor较小(如 l = 10 l=10 l=10, α = 0.05 \alpha=0.05 α=0.05, λ actor = 1 − 1 0.05 ⋅ 10 = 0.8 \lambda_{\text{actor}} = 1 - \frac{1}{0.05 \cdot 10} = 0.8 λactor=1−0.05⋅101=0.8),强调低方差。
- 长序列(大 l l l): α l \alpha l αl较大, 1 α l \frac{1}{\alpha l} αl1较小, λ actor \lambda_{\text{actor}} λactor接近1.0(如 l = 100 l=100 l=100, λ actor = 1 − 1 0.05 ⋅ 100 = 0.98 \lambda_{\text{actor}} = 1 - \frac{1}{0.05 \cdot 100} = 0.98 λactor=1−0.05⋅1001=0.98),强调低偏差。
- 设计原理:
- 论文提出,GAE中TD误差的权重之和应与序列长度成正比:
∑ t = 0 ∞ λ actor t = 1 1 − λ actor ≈ α l \sum_{t=0}^{\infty} \lambda_{\text{actor}}^t = \frac{1}{1 - \lambda_{\text{actor}}} \approx \alpha l t=0∑∞λactort=1−λactor1≈αl - 解出 λ actor \lambda_{\text{actor}} λactor,得到上述公式,确保不同长度的序列具有一致的信号传播强度。
- 论文提出,GAE中TD误差的权重之和应与序列长度成正比:
通过这种动态调整,长度自适应GAE使短序列的优化更稳定(低方差),长序列的优化更准确(低偏差),从而提升模型对异构序列的处理能力。
2. 偏差-方差权衡问题
2.1 什么是偏差-方差权衡?
在强化学习中,优势估计 A ^ t \hat{A}_t A^t的目标是预测动作 a t a_t at在状态 s t s_t st下的真实优势(即 Q ( s t , a t ) − V ( s t ) Q(s_t, a_t) - V(s_t) Q(st,at)−V(st),预期未来回报超出基准的程度)。然而,估计过程会引入误差,表现为偏差(bias)和方差(variance):
-
偏差(Bias):
- 指估计值与真实值的系统性误差。
- 例如,当 λ < 1 \lambda < 1 λ<1时,GAE依赖价值模型 V ( s t ) V(s_t) V(st)的预测,如果 V ( s t ) V(s_t) V(st)不准确(常见于训练早期或长序列),会导致 A ^ t \hat{A}_t A^t偏离真实优势,产生偏差。
- 在长序列中,固定 λ < 1 \lambda < 1 λ<1(如0.95)使末尾奖励 r T r_T rT的贡献指数衰减,早期标记的优势估计几乎完全依赖 V ( s t ) V(s_t) V(st),偏差累积严重。
-
方差(Variance):
- 指估计值的随机波动性。
- 当 λ = 1 \lambda = 1 λ=1时,GAE等价于蒙特卡洛回报,直接使用实际奖励 r T r_T rT,无偏差,但 r T r_T rT的随机性(例如在Long-CoT中, r T = 1 r_T = 1 rT=1或 0 0 0)会导致 A ^ t \hat{A}_t A^t波动较大,尤其在短序列中(因为样本量少,随机性更显著)。
- 高方差会导致策略梯度更新不稳定,训练可能震荡或收敛缓慢。
-
权衡:
- 低 λ \lambda λ(如0.0):依赖单步TD误差,方差低(仅受当前奖励和价值估计影响),但偏差高(忽略长期回报)。
- 高 λ \lambda λ(如1.0):依赖整个轨迹的奖励,方差高(受所有奖励的随机性影响),但偏差低(无偏估计)。
- 理想的 λ \lambda λ应根据任务特性平衡这两者,使估计既准确又稳定。
2.2 长链推理中的偏差-方差问题
在Long-CoT任务中,偏差-方差权衡因序列长度的异构性而复杂化:
-
短序列(如10-50个标记):
- 奖励 r T r_T rT对早期标记的传播距离较短,即使 λ < 1 \lambda < 1 λ<1,信号衰减有限。
- 但短序列的样本量少, r T r_T rT的随机性( 1 1 1或 0 0 0)会导致高方差,尤其当 λ \lambda λ接近1.0时。
- 因此,短序列需要较小的 λ \lambda λ,以降低对 r T r_T rT的依赖,减少方差。
-
长序列(如100-500个标记):
- 奖励 r T r_T rT需传播到早期标记,固定 λ < 1 \lambda < 1 λ<1会导致严重衰减(如 λ 100 ≈ 0 \lambda^{100} \approx 0 λ100≈0),优势估计完全依赖价值模型。
- 如果价值模型不准确(常见于训练初期或复杂任务),会引入高偏差,导致模型无法学习正确的长期依赖。
- 因此,长序列需要较大的 λ \lambda λ(接近1.0),以减少偏差,确保 r T r_T rT的影响。
固定 λ \lambda λ无法同时满足这两种需求,导致模型在短序列上不稳定(高方差),在长序列上不准确(高偏差)。长度自适应GAE通过动态调整 λ actor \lambda_{\text{actor}} λactor,为不同长度的序列提供定制化的偏差-方差权衡。
3. 代码实现
以下是将长度自适应GAE集成到VC-PPO代码中的实现,基于之前的VC-PPO框架。我们将修改compute_gae函数,使
λ
actor
\lambda_{\text{actor}}
λactor根据序列长度动态计算,同时保留
λ
critic
\lambda_{\text{critic}}
λcritic为1.0(解耦GAE)。代码假设使用PyTorch,并与Long-CoT任务兼容。
代码请见:ByteDance Seed团队:Value-Calibrated Proximal Policy Optimization (VC-PPO)(二)代码实现
import torch
import numpy as np
def compute_length_adaptive_gae(rewards, values, sequence_lengths, alpha=0.05, lambda_critic=1.0, gamma=1.0):
"""
计算长度自适应GAE
参数:
rewards: 轨迹的奖励列表,长度为轨迹数
values: 价值估计,形状为[num_trajectories, seq_len]
sequence_lengths: 每条轨迹的生成序列长度列表
alpha: 长度自适应超参数,控制偏差-方差权衡
lambda_critic: 价值更新的GAE参数,通常为1.0
gamma: 折扣因子,默认为1.0
返回:
advantages_actor: 使用长度自适应lambda_actor计算的优势
value_targets_critic: 使用lambda_critic计算的价值目标
"""
advantages_actor = []
value_targets_critic = []
for traj_idx in range(len(rewards)):
# 获取当前轨迹的奖励、价值和序列长度
reward = rewards[traj_idx]
traj_values = values[traj_idx]
seq_len = sequence_lengths[traj_idx]
# 计算长度自适应的lambda_actor
lambda_actor = 1.0 - 1.0 / (alpha * seq_len) if seq_len > 0 else 0.95 # 防止除零
lambda_actor = min(max(lambda_actor, 0.0), 1.0) # 限制在[0, 1]
# 初始化优势和价值目标
traj_advantages_actor = []
traj_value_targets_critic = []
T = len(traj_values) - 1 # 价值估计包括最后一个标记
for t in range(T):
# 计算单步TD误差
delta = reward if t == T-1 else 0.0 # Long-CoT中仅末尾有奖励
delta += (gamma * traj_values[t+1] if t+1 < T else 0.0) - traj_values[t]
# 策略优势(使用lambda_actor)
advantage_actor = delta
if lambda_actor < 1.0:
for k in range(1, T-t):
delta_k = (reward if t+k == T-1 else 0.0) + \
(gamma * traj_values[t+k+1] if t+k+1 < T else 0.0) - traj_values[t+k]
advantage_actor += (gamma * lambda_actor)**k * delta_k
# 价值目标(使用lambda_critic,通常为1.0)
delta_critic = delta
if lambda_critic < 1.0:
for k in range(1, T-t):
delta_k = (reward if t+k == T-1 else 0.0) + \
(gamma * traj_values[t+k+1] if t+k+1 < T else 0.0) - traj_values[t+k]
delta_critic += (gamma * lambda_critic)**k * delta_k
value_target_critic = delta_critic + traj_values[t]
traj_advantages_actor.append(advantage_actor)
traj_value_targets_critic.append(value_target_critic)
advantages_actor.append(traj_advantages_actor)
value_targets_critic.append(traj_value_targets_critic)
# 转换为张量
advantages_actor = torch.tensor(advantages_actor, dtype=torch.float32)
value_targets_critic = torch.tensor(value_targets_critic, dtype=torch.float32)
return advantages_actor, value_targets_critic
# 修改VC-PPO训练函数中的GAE计算部分
def train_vc_ppo(
model_name="Qwen/Qwen2.5-32B",
value_checkpoint_path="./value_checkpoint/epoch_10/value_checkpoint.pt",
prompts=["Solve the equation x^2 - 5x + 6 = 0"],
num_epochs=10,
num_trajectories=100,
batch_size=4,
num_mini_batches=4,
policy_lr=1e-6,
value_lr=2e-6,
clip_eps=0.2,
alpha=0.05, # 长度自适应超参数
lambda_critic=1.0,
max_length=512,
save_path="./vcJune2025/vc_ppo_checkpoint",
device="cuda"
):
# ...(其他初始化代码与VC-PPO一致)
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
policy_model = PolicyModel(base_model).to(device)
old_policy_model = PolicyModel(base_model).to(device)
old_policy_model.load_state_dict(policy_model.state_dict())
policy_optimizer = optim.Adam(policy_model.parameters(), lr=policy_lr)
value_model = ValueModel(base_model).to(device)
checkpoint = torch.load(value_checkpoint_path)
value_model.load_state_dict(checkpoint["value_model_state_dict"])
value_optimizer = optim.Adam(value_model.parameters(), lr=value_lr)
env = LongCoTEnvironment(tokenizer, policy_model, prompts, max_length)
for epoch in range(num_epochs):
states, actions, log_probs, rewards, values, sequence_lengths = [], [], [], [], [], []
print(f"Epoch {epoch+1}/{num_epochs}: Collecting trajectories...")
for _ in tqdm(range(num_trajectories)):
input_ids, generated_ids, action_ids, action_log_probs, reward = env.generate_trajectory(policy_model)
with torch.no_grad():
value = value_model(generated_ids, attention_mask=(generated_ids != tokenizer.pad_token_id).long())
seq_len = generated_ids.size(1) - input_ids.size(1) # 生成部分的长度
states.append(generated_ids)
actions.append(action_ids)
log_probs.append(action_log_probs)
rewards.append(reward)
values.append(value.cpu().numpy())
sequence_lengths.append(seq_len)
# 计算长度自适应GAE
print("Computing Length-Adaptive GAE...")
advantages_actor, value_targets_critic = compute_length_adaptive_gae(
rewards, values, sequence_lengths, alpha, lambda_critic
)
# ...(其余代码与VC-PPO一致:创建数据集、优化策略和价值模型、保存检查点等)
return policy_model, value_model, tokenizer
4. 代码实现详解
4.1 函数:compute_length_adaptive_gae
-
输入:
rewards:每条轨迹的末尾奖励(列表,长度为轨迹数)。values:价值模型的估计值(形状为[num_trajectories, seq_len])。sequence_lengths:每条轨迹的生成序列长度(列表)。alpha:超参数,控制 λ actor \lambda_{\text{actor}} λactor的调整强度,VAPO设为0.05。lambda_critic:价值更新的 λ \lambda λ,通常为1.0。gamma:折扣因子,默认为1.0。
-
核心逻辑:
- 遍历每条轨迹,获取奖励、价值和序列长度。
- 计算 λ actor = 1 − 1 α ⋅ seq_len \lambda_{\text{actor}} = 1 - \frac{1}{\alpha \cdot \text{seq\_len}} λactor=1−α⋅seq_len1,并限制在 [ 0 , 1 ] [0, 1] [0,1]。
- 对于每个时间步
t
t
t:
- 计算单步TD误差 δ t \delta_t δt,在Long-CoT中,非末尾奖励为0,末尾为 r T r_T rT。
- 策略优势:累加折扣后的TD误差,折扣因子为 γ ⋅ λ actor \gamma \cdot \lambda_{\text{actor}} γ⋅λactor。
- 价值目标:类似计算,但使用 λ critic \lambda_{\text{critic}} λcritic(通常为1.0,简化为一阶TD)。
- 将结果转换为张量返回。
-
优化:
- 添加防止除零的检查(
seq_len > 0)。 - 使用
min和max确保 λ actor \lambda_{\text{actor}} λactor合法。 - 在Long-CoT中,奖励稀疏性简化了计算(仅末尾非零)。
- 添加防止除零的检查(
4.2 训练函数:train_vc_ppo
- 修改部分:
- 添加
sequence_lengths收集:在生成轨迹时,计算生成部分的长度(generated_ids.size(1) - input_ids.size(1))。 - 调用
compute_length_adaptive_gae替换原compute_gae,传入sequence_lengths和alpha。
- 添加
- 与VC-PPO的区别:
- 原VC-PPO使用固定 λ actor \lambda_{\text{actor}} λactor(如0.95),而VAPO动态计算。
- 其余逻辑(数据集创建、PPO更新、检查点保存)保持一致。
4.3 实际应用中的注意事项
- 序列长度计算:
- 确保
seq_len仅包含生成部分(排除提示部分),符合Long-CoT任务的定义。 - 对于填充(padding)的序列,需通过
attention_mask过滤无效标记。
- 确保
-
α
\alpha
α的选择:
- VAPO设 α = 0.05 \alpha=0.05 α=0.05,适用于AIME任务(序列长度50-500)。
- 对于其他任务,可通过网格搜索调整 α \alpha α(如0.01-0.1)。
- 计算效率:
- 动态计算 λ actor \lambda_{\text{actor}} λactor增加少量开销,但对长序列的性能提升显著。
- 可通过向量化优化(如NumPy或PyTorch张量操作)加速GAE计算。
5. 效果与意义
长度自适应GAE通过动态调整 λ actor \lambda_{\text{actor}} λactor,解决了固定 λ \lambda λ在异构序列长度下的局限性:
- 短序列: λ actor \lambda_{\text{actor}} λactor较小(如0.8),减少对 r T r_T rT的依赖,降低方差,稳定策略更新。
- 长序列: λ actor \lambda_{\text{actor}} λactor较大(如0.98),保留更多 r T r_T rT信号,减少偏差,提升长期依赖学习。
- 整体效果:VAPO的消融实验表明,移除长度自适应GAE使AIME得分从60降至45,证明其对异构序列优化的关键作用。
这种方法特别适合Long-CoT任务,因为:
- 序列长度差异大(数学推理可能从简短答案到复杂推导)。
- 奖励稀疏(仅末尾评分),需要高效传播信号。
- 模型需同时优化短序列的稳定性(避免震荡)和长序列的准确性(避免长度崩溃)。
6. 总结
长度自适应GAE通过公式 λ actor = 1 − 1 α l \lambda_{\text{actor}} = 1 - \frac{1}{\alpha l} λactor=1−αl1,根据序列长度动态调整GAE的 λ \lambda λ参数,解决了偏差-方差权衡问题:
- 偏差:长序列使用高 λ \lambda λ,减少奖励信号衰减,确保准确性。
- 方差:短序列使用低 λ \lambda λ,减少奖励波动影响,确保稳定性。
- 代码实现:在VC-PPO框架中,通过收集序列长度并动态计算 λ actor \lambda_{\text{actor}} λactor,无缝集成到GAE计算中。
- 意义:提升模型对异构序列的优化能力,避免传统固定 λ \lambda λ导致的性能瓶颈,显著提高Long-CoT任务的表现(如AIME得分提升15点)。
这一方法不仅适用于数学推理,还可推广到其他需要处理变长序列的RL任务,如代码生成、长篇对话等,为RLHF提供了一种灵活而高效的优化策略。
Token级别的loss
我们来详细解释 标记级策略梯度损失(Token-Level Policy Gradient Loss) 的概念,特别是它在 VAPO 中的作用、与传统序列级损失的区别,以及如何通过对所有标记(token)均等加权来解决长序列优化的权重不足问题。我们还会结合 GAE 优势估计的计算,说明为何从序列级平均转向标记级平均能提升长链推理(Long-CoT)任务的性能。
1. 背景:PPO 策略梯度损失与 GAE
在 Proximal Policy Optimization(PPO) 中,策略优化的目标是通过最大化裁剪代理目标(clipped surrogate objective)来更新策略参数 θ \theta θ。PPO 的损失函数通常定义为:
L PPO ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] \mathcal{L}_{\text{PPO}}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right] LPPO(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
- r t ( θ ) r_t(\theta) rt(θ):概率比, r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),表示新策略相对于旧策略的动作概率变化。
- A ^ t \hat{A}_t A^t:优势估计(advantage),衡量动作 a t a_t at 在状态 s t s_t st 下的相对价值,通常通过广义优势估计(GAE)计算。
- ϵ \epsilon ϵ:裁剪参数(如 0.2),限制策略更新的幅度以提高稳定性。
- E t \mathbb{E}_t Et:期望,通常通过对轨迹样本的平均来近似。
1.1 GAE 优势估计
在 Long-CoT 任务中,语言生成被建模为一个标记级 Markov 决策过程(MDP),每个标记是一个动作。GAE 为每个时间步 t t t 的标记计算优势 A ^ t \hat{A}_t A^t:
A ^ t = ∑ i = 0 T − t − 1 ( γ λ ) i δ t + i , δ t + i = r t + i + γ V ( s t + i + 1 ) − V ( s t + i ) \hat{A}_t = \sum_{i=0}^{T-t-1} (\gamma \lambda)^i \delta_{t+i}, \quad \delta_{t+i} = r_{t+i} + \gamma V(s_{t+i+1}) - V(s_{t+i}) A^t=i=0∑T−t−1(γλ)iδt+i,δt+i=rt+i+γV(st+i+1)−V(st+i)
- T T T:序列总长度。
- r t + i r_{t+i} rt+i:即时奖励,在 Long-CoT 中通常只有末尾奖励非零( r T ≠ 0 r_T \neq 0 rT=0,如 r T = 1 r_T = 1 rT=1 或 0 0 0)。
- V ( s t ) V(s_t) V(st):价值模型对状态 s t s_t st 的估值。
- γ \gamma γ:折扣因子,通常为 1.0。
- λ \lambda λ:GAE 参数,控制偏差-方差权衡(如 VAPO 中 λ critic = 1.0 \lambda_{\text{critic}} = 1.0 λcritic=1.0, λ actor \lambda_{\text{actor}} λactor 可动态调整)。
关键点:对于每条轨迹(sample),我们为每个标记 t t t 计算一个优势 A ^ i , t \hat{A}_{i,t} A^i,t,其中 i i i 表示第 i i i 条轨迹, t t t 表示该轨迹中的第 t t t 个标记。优势 A ^ i , t \hat{A}_{i,t} A^i,t 衡量该标记的动作对未来回报的贡献。
1.2 传统序列级损失
在传统 PPO 实现中(如 VC-PPO 或早期的 RLHF),策略梯度损失通常以序列级平均(sample-level averaging)计算。假设一个批次(batch)包含 G G G 条轨迹,每条轨迹 i i i 的长度为 ∣ σ i ∣ |\sigma_i| ∣σi∣(标记数),损失函数为:
L PPO ( θ ) = − 1 G ∑ i = 1 G 1 ∣ σ i ∣ ∑ t = 1 ∣ σ i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \mathcal{L}_{\text{PPO}}(\theta) = -\frac{1}{G} \sum_{i=1}^G \frac{1}{|\sigma_i|} \sum_{t=1}^{|\sigma_i|} \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t} \right) LPPO(θ)=−G1i=1∑G∣σi∣1t=1∑∣σi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)
- 计算步骤:
- 对每条轨迹 i i i 的所有标记 t t t,计算裁剪代理目标 min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min(r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t}) min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)。
- 对轨迹 i i i 内的标记取平均,得到轨迹级损失: 1 ∣ σ i ∣ ∑ t = 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} \sum_{t=1}^{|\sigma_i|} ∣σi∣1∑t=1∣σi∣。
- 对批次中的 G G G 条轨迹再次取平均: 1 G ∑ i = 1 G \frac{1}{G} \sum_{i=1}^G G1∑i=1G。
- 含义:每条轨迹对总损失的贡献是均等的(权重为 1 G \frac{1}{G} G1),无论轨迹长度如何。轨迹内部的标记贡献通过 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1 归一化。
问题:
- 长序列权重不足:对于长序列( ∣ σ i ∣ |\sigma_i| ∣σi∣ 大),每个标记的贡献被 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1 稀释。例如,一条长度为 500 的轨迹中,每个标记的权重仅为 1 500 \frac{1}{500} 5001,而一条长度为 50 的轨迹中,每个标记权重为 1 50 \frac{1}{50} 501。
- 后果:在 Long-CoT 任务中,长序列往往包含复杂的推理步骤(如数学推导),需要更强的优化信号。但序列级平均导致长序列的标记对总损失的贡献较小,模型难以有效学习长序列中的关键模式,可能导致训练不稳定或“长度崩溃”(模型倾向生成短序列)。
2. 标记级策略梯度损失(Token-Level Policy Gradient Loss)
VAPO 引入了 标记级策略梯度损失,以解决序列级平均对长序列优化的不足。新的损失函数定义为:
L PPO ( θ ) = − 1 ∑ i = 1 G ∣ σ i ∣ ∑ i = 1 G ∑ t = 1 ∣ σ i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \mathcal{L}_{\text{PPO}}(\theta) = -\frac{1}{\sum_{i=1}^G |\sigma_i|} \sum_{i=1}^G \sum_{t=1}^{|\sigma_i|} \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t} \right) LPPO(θ)=−∑i=1G∣σi∣1i=1∑Gt=1∑∣σi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t)
2.1 计算方式
- 步骤:
- 对每条轨迹 i i i 的每个标记 t t t,计算裁剪代理目标 min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ) \min(r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_{i,t}) min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵ,1+ϵ)A^i,t),这与序列级损失相同。
- 将所有轨迹的所有标记的代理目标直接相加: ∑ i = 1 G ∑ t = 1 ∣ σ i ∣ \sum_{i=1}^G \sum_{t=1}^{|\sigma_i|} ∑i=1G∑t=1∣σi∣。
- 用批次中所有标记的总数 ∑ i = 1 G ∣ σ i ∣ \sum_{i=1}^G |\sigma_i| ∑i=1G∣σi∣ 归一化,得到平均损失。
- 含义:
- 每个标记对总损失的贡献是均等的,权重为 1 ∑ i = 1 G ∣ σ i ∣ \frac{1}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣1,与标记所属的轨迹长度无关。
- 长序列的标记数多,因此整体贡献更大,短序列的贡献相应减少。
2.2 与序列级损失的区别
| 特性 | 序列级损失 | 标记级损失 |
|---|---|---|
| 归一化方式 | 先轨迹内平均( 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1),再批次平均( 1 G \frac{1}{G} G1) | 直接对所有标记平均( 1 ∑ i = 1 G ∣ σ i ∣ \frac{1}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣1) |
| 标记权重 | 长序列标记权重低( 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1) | 所有标记权重均等( 1 ∑ i = 1 G ∣ σ i ∣ \frac{1}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣1) |
| 对长序列的优化 | 不足,易忽视长序列问题 | 增强,长序列贡献更大 |
| 训练稳定性 | 长序列问题可能被掩盖,导致不稳定 | 更关注长序列,提升稳定性 |
举例说明:
- 假设批次有 2 条轨迹:
- 轨迹 1:长度 50,标记数 ∣ σ 1 ∣ = 50 |\sigma_1| = 50 ∣σ1∣=50。
- 轨迹 2:长度 500,标记数 ∣ σ 2 ∣ = 500 |\sigma_2| = 500 ∣σ2∣=500。
- 序列级损失:
- 轨迹 1 的总权重: 1 2 \frac{1}{2} 21,每个标记权重: 1 2 ⋅ 1 50 = 0.01 \frac{1}{2} \cdot \frac{1}{50} = 0.01 21⋅501=0.01。
- 轨迹 2 的总权重: 1 2 \frac{1}{2} 21,每个标记权重: 1 2 ⋅ 1 500 = 0.001 \frac{1}{2} \cdot \frac{1}{500} = 0.001 21⋅5001=0.001。
- 结果:轨迹 1 的标记影响是轨迹 2 的 10 倍,尽管轨迹 2 包含更多信息。
- 标记级损失:
- 总标记数: 50 + 500 = 550 50 + 500 = 550 50+500=550。
- 每个标记权重: 1 550 ≈ 0.00182 \frac{1}{550} \approx 0.00182 5501≈0.00182。
- 轨迹 1 的总贡献: 50 ⋅ 1 550 ≈ 0.091 50 \cdot \frac{1}{550} \approx 0.091 50⋅5501≈0.091。
- 轨迹 2 的总贡献: 500 ⋅ 1 550 ≈ 0.909 500 \cdot \frac{1}{550} \approx 0.909 500⋅5501≈0.909。
- 结果:轨迹 2 的贡献占主导(约 90.9%),反映其包含更多标记的事实。
2.3 针对的问题
在 Long-CoT 任务中,长序列通常对应复杂的推理过程(例如 AIME 数学问题需要数百标记的推导),而短序列可能是简单答案或错误响应。序列级损失的问题在于:
- 长序列权重稀释:长序列的每个标记贡献被 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1 压制,导致模型难以学习长序列中的关键推理步骤。
- 训练不稳定:在 RL 探索阶段,模型可能生成过短或错误的序列(“长度崩溃”),而序列级平均掩盖了长序列的优化需求,导致模型无法纠正这些问题。
- 性能瓶颈:长序列包含更多信息(如推理逻辑),但其影响被低估,模型倾向于优化短序列,导致推理能力退化。
标记级损失通过赋予每个标记均等权重,确保长序列的优化信号更强,模型更关注复杂推理中的细节。
3. 代码实现
以下是将标记级策略梯度损失集成到 VC-PPO 代码中的实现,基于之前的框架。我们将修改 train_vc_ppo 函数中的损失计算部分,确保对所有标记统一平均,而不是先进行序列级平均。
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.utils.data import DataLoader, Dataset
import numpy as np
from tqdm import tqdm
import os
# 环境类、模型类、GAE 计算等与之前相同,略去以节省空间
# 假设已有 LongCoTEnvironment, PolicyModel, ValueModel, compute_length_adaptive_gae
class TrajectoryDataset(Dataset):
def __init__(self, states, actions, log_probs, advantages, value_targets):
self.states = states
self.actions = actions
self.log_probs = log_probs
self.advantages = advantages
self.value_targets = value_targets
def __len__(self):
return len(self.states)
def __getitem__(self, idx):
return {
"states": self.states[idx],
"actions": self.actions[idx],
"log_probs": self.log_probs[idx],
"advantages": self.advantages[idx],
"value_targets": self.value_targets[idx]
}
def train_vapo(
model_name="Qwen/Qwen2.5-32B",
value_checkpoint_path="./value_checkpoint/epoch_10/value_checkpoint.pt",
prompts=["Solve the equation x^2 - 5x + 6 = 0"],
num_epochs=10,
num_trajectories=100,
batch_size=4,
num_mini_batches=4,
policy_lr=1e-6,
value_lr=2e-6,
clip_eps=0.2,
alpha=0.05,
lambda_critic=1.0,
max_length=512,
save_path="./vapo_checkpoint",
device="cuda"
):
# 初始化
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
policy_model = PolicyModel(base_model).to(device)
old_policy_model = PolicyModel(base_model).to(device)
old_policy_model.load_state_dict(policy_model.state_dict())
policy_optimizer = optim.Adam(policy_model.parameters(), lr=policy_lr)
value_model = ValueModel(base_model).to(device)
checkpoint = torch.load(value_checkpoint_path)
value_model.load_state_dict(checkpoint["value_model_state_dict"])
value_optimizer = optim.Adam(value_model.parameters(), lr=value_lr)
env = LongCoTEnvironment(tokenizer, policy_model, prompts, max_length)
for epoch in range(num_epochs):
# 收集轨迹
states, actions, log_probs, rewards, values, sequence_lengths = [], [], [], [], [], []
print(f"Epoch {epoch+1}/{num_epochs}: Collecting trajectories...")
for _ in tqdm(range(num_trajectories)):
input_ids, generated_ids, action_ids, action_log_probs, reward = env.generate_trajectory(policy_model)
with torch.no_grad():
value = value_model(generated_ids, attention_mask=(generated_ids != tokenizer.pad_token_id).long())
seq_len = generated_ids.size(1) - input_ids.size(1)
states.append(generated_ids)
actions.append(action_ids)
log_probs.append(action_log_probs)
rewards.append(reward)
values.append(value.cpu().numpy())
sequence_lengths.append(seq_len)
# 计算长度自适应 GAE
advantages_actor, value_targets_critic = compute_length_adaptive_gae(
rewards, values, sequence_lengths, alpha, lambda_critic
)
# 创建数据集
dataset = TrajectoryDataset(states, actions, log_probs, advantages_actor, value_targets_critic)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 小批量更新
policy_model.train()
value_model.train()
total_policy_loss = 0
total_value_loss = 0
for _ in range(num_mini_batches):
for batch in tqdm(dataloader, desc="Mini-batch update"):
state_ids = batch["states"].to(device)
action_ids = batch["actions"].to(device)
old_log_probs = batch["log_probs"].to(device)
advantages = batch["advantages"].to(device)
value_targets = batch["value_targets"].to(device)
# 计算当前策略的 log 概率
logits = policy_model(state_ids, attention_mask=(state_ids != tokenizer.pad_token_id).long())
log_probs = torch.log_softmax(logits, dim=-1)
action_log_probs = torch.gather(log_probs[:, :-1], -1, action_ids.unsqueeze(-1)).squeeze(-1)
# 计算概率比
ratio = torch.exp(action_log_probs - old_log_probs)
# 标记级策略梯度损失
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages
policy_loss = -torch.min(surr1, surr2) # 未平均,保持标记级
policy_loss = policy_loss.mean() # 对所有标记平均
# 计算价值损失
values = value_model(state_ids, attention_mask=(state_ids != tokenizer.pad_token_id).long())
value_loss = ((values - value_targets) ** 2).mean() / 2
# 优化策略
policy_optimizer.zero_grad()
policy_loss.backward()
policy_optimizer.step()
# 优化价值
value_optimizer.zero_grad()
value_loss.backward()
value_optimizer.step()
total_policy_loss += policy_loss.item()
total_value_loss += value_loss.item()
# 更新旧策略
old_policy_model.load_state_dict(policy_model.state_dict())
avg_policy_loss = total_policy_loss / (num_mini_batches * len(dataloader))
avg_value_loss = total_value_loss / (num_mini_batches * len(dataloader))
print(f"Epoch {epoch+1}/{num_epochs}, Policy Loss: {avg_policy_loss:.4f}, Value Loss: {avg_value_loss:.4f}")
# 保存检查点
checkpoint_dir = os.path.join(save_path, f"epoch_{epoch+1}")
os.makedirs(checkpoint_dir, exist_ok=True)
torch.save({
"policy_model_state_dict": policy_model.state_dict(),
"value_model_state_dict": value_model.state_dict(),
"epoch": epoch + 1,
"policy_loss": avg_policy_loss,
"value_loss": avg_value_loss
}, os.path.join(checkpoint_dir, "vapo_checkpoint.pt"))
print(f"Saved checkpoint to {checkpoint_dir}")
return policy_model, value_model, tokenizer
4. 代码实现详解
4.1 关键修改
-
策略损失计算:
- 原 VC-PPO(序列级):
# 假设每条轨迹单独平均 policy_loss = torch.tensor(0.0, device=device) for i in range(batch_size): surr1_i = ratio[i] * advantages[i] surr2_i = torch.clamp(ratio[i], 1 - clip_eps, 1 + clip_eps) * advantages[i] policy_loss_i = -torch.min(surr1_i, surr2_i).mean() # 轨迹内平均 policy_loss += policy_loss_i / batch_size # 批次平均- 每个轨迹的损失先对标记平均(
.mean()),再对轨迹平均(/ batch_size)。
- 每个轨迹的损失先对标记平均(
- VAPO(标记级):
surr1 = ratio * advantages surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages policy_loss = -torch.min(surr1, surr2) # 未平均 policy_loss = policy_loss.mean() # 直接对所有标记平均- 直接对批次中所有标记的代理目标求和并平均,忽略轨迹边界。
- 原 VC-PPO(序列级):
-
数据处理:
advantages和action_log_probs的形状为[batch_size, seq_len],在计算policy_loss时,mean()操作为所有标记(包括所有轨迹的所有标记)取平均,等价于 1 ∑ i = 1 G ∣ σ i ∣ \frac{1}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣1。
4.2 注意事项
- 填充处理:
- Long-CoT 序列长度不一,需通过
attention_mask过滤填充标记(padding tokens),确保只计算有效标记的损失。 - 代码中已使用
attention_mask=(state_ids != tokenizer.pad_token_id).long()。
- Long-CoT 序列长度不一,需通过
- 批次大小:
- 标记级损失对长序列更敏感,可能增加内存需求。需根据 GPU 容量调整
batch_size(如 4)。
- 标记级损失对长序列更敏感,可能增加内存需求。需根据 GPU 容量调整
- 奖励稀疏性:
- 在 Long-CoT 中,优势 A ^ i , t \hat{A}_{i,t} A^i,t 主要由末尾奖励 r T r_T rT 驱动,标记级损失确保长序列的早期标记也能充分优化。
5. 效果与意义
5.1 解决的问题
标记级策略梯度损失解决了传统序列级损失的以下问题:
- 长序列权重不足:序列级平均使长序列的每个标记贡献被 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1 稀释,模型忽视长序列中的推理步骤。标记级损失赋予每个标记均等权重,长序列的整体贡献( ∣ σ i ∣ ∑ i = 1 G ∣ σ i ∣ \frac{|\sigma_i|}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣∣σi∣)更大。
- 训练不稳定:长序列问题(如推理错误)在序列级损失中被低估,可能导致模型倾向生成短序列(长度崩溃)。标记级损失放大长序列的影响,迫使模型优化复杂推理。
- 性能瓶颈:长序列包含关键信息(如数学推导逻辑),标记级损失确保这些信息得到充分学习,提升模型的推理能力。
5.2 实验证据
VAPO 的消融实验(论文 Table 1)显示:
- 移除标记级损失后,AIME 2024 得分从 60 降至 53,下降 7 分。
- 这表明标记级损失对长序列优化至关重要,尤其在 Long-CoT 任务中,长序列的推理质量直接影响最终答案的正确性。
5.3 对 GAE 的影响
- GAE 计算:GAE 为每个标记计算优势 A ^ i , t \hat{A}_{i,t} A^i,t,这与标记级损失兼容。序列级损失通过 1 ∣ σ i ∣ \frac{1}{|\sigma_i|} ∣σi∣1 平均轨迹内的 A ^ i , t \hat{A}_{i,t} A^i,t,削弱了长序列的信号。标记级损失直接使用所有 A ^ i , t \hat{A}_{i,t} A^i,t,确保优势估计的完整传播。
- 长序列优化:在 Long-CoT 中,末尾奖励 r T r_T rT 通过 GAE 传播到早期标记(尤其当 λ actor \lambda_{\text{actor}} λactor 较高时,如长度自适应 GAE)。标记级损失放大这些标记的优化信号,增强模型对长期依赖的学习。
6. 总结
标记级策略梯度损失通过将 PPO 损失从序列级平均改为标记级平均,解决了长序列优化权重不足的问题:
- 机制:每个标记的代理目标贡献均等,权重为 1 ∑ i = 1 G ∣ σ i ∣ \frac{1}{\sum_{i=1}^G |\sigma_i|} ∑i=1G∣σi∣1,长序列的整体影响更大。
- 与 GAE 的关系:GAE 为每个标记计算优势 A ^ i , t \hat{A}_{i,t} A^i,t,标记级损失直接利用这些优势,避免轨迹内平均的稀释效应。
- 效果:增强长序列的优化信号,模型更关注复杂推理步骤,提升训练稳定性和推理能力(AIME 得分提升 7 分)。
- 代码实现:通过对所有标记的代理目标直接取平均,简洁高效,兼容 VC-PPO 框架。
这一方法特别适合 Long-CoT 任务,因为长序列的推理质量对最终性能至关重要。标记级损失的理念也可推广到其他需要优化变长序列的 RLHF 任务,如代码生成或长篇对话生成。
Clip-Higher
为了详细解答 更高裁剪范围(Clip-Higher) 的问题,我们需要深入探讨 VAPO 中为何将 PPO 的裁剪范围解耦为 ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh,以及与传统 PPO 使用单一 ϵ \epsilon ϵ(例如增大 ϵ \epsilon ϵ)相比,这种解耦方法有何独特优势。我们将从熵崩溃问题、PPO 裁剪机制、解耦裁剪的动机及其效果等方面展开分析,并结合 Long-CoT 任务的稀疏奖励特性,阐明两者的区别。
1. 背景:PPO 裁剪机制与熵崩溃
1.1 PPO 的裁剪机制
在 Proximal Policy Optimization(PPO) 中,策略更新通过最大化裁剪代理目标(clipped surrogate objective)实现,损失函数为:
L PPO ( θ ) = E t [ min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] \mathcal{L}_{\text{PPO}}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right] LPPO(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
- r t ( θ ) r_t(\theta) rt(θ):概率比,定义为 r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\text{old}}}(a_t|s_t)} rt(θ)=πθold(at∣st)πθ(at∣st),表示新策略相对于旧策略的动作概率变化。
- A ^ t \hat{A}_t A^t:优势估计,衡量动作 a t a_t at 在状态 s t s_t st 下的相对价值(由 GAE 计算)。
-
ϵ
\epsilon
ϵ:裁剪参数(传统 PPO 通常设为 0.2),控制概率比
r
t
(
θ
)
r_t(\theta)
rt(θ) 的变化范围:
- 如果 r t ( θ ) < 1 − ϵ r_t(\theta) < 1-\epsilon rt(θ)<1−ϵ,裁剪到 1 − ϵ 1-\epsilon 1−ϵ。
- 如果 r t ( θ ) > 1 + ϵ r_t(\theta) > 1+\epsilon rt(θ)>1+ϵ,裁剪到 1 + ϵ 1+\epsilon 1+ϵ。
- 作用:
- 当 A ^ t > 0 \hat{A}_t > 0 A^t>0(动作有益),裁剪限制 r t ( θ ) r_t(\theta) rt(θ) 过大(新策略概率上升过多),防止激进更新。
- 当 A ^ t < 0 \hat{A}_t < 0 A^t<0(动作有害),裁剪限制 r t ( θ ) r_t(\theta) rt(θ) 过小(新策略概率下降过多),避免过度抑制。
裁剪机制的核心是限制策略更新幅度,确保新策略 π θ \pi_\theta πθ 不偏离旧策略 π θ old \pi_{\theta_{\text{old}}} πθold 太远,从而提高训练稳定性。
1.2 熵崩溃问题
在 Long-CoT 任务中,奖励信号稀疏(仅末尾提供,如 r T = 1 r_T = 1 rT=1 或 0 0 0),模型需要广泛探索以发现正确答案。然而,传统 PPO 的裁剪机制可能导致 熵崩溃(entropy collapse),即模型过早收敛到某些高概率动作,策略分布的熵(多样性)急剧下降。主要原因包括:
- 稀疏奖励:正确答案的采样概率低,模型可能过度优化少量高回报轨迹,忽视其他潜在动作。
- 对低概率动作的限制:当某个动作 a t a_t at 在旧策略中概率 π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t|s_t) πθold(at∣st) 较低时, r t ( θ ) r_t(\theta) rt(θ) 需要较大( π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st) 显著增加)才能提升其概率。但传统 PPO 的 ϵ \epsilon ϵ(如 0.2)限制 r t ( θ ) ≤ 1 + ϵ = 1.2 r_t(\theta) \leq 1+\epsilon = 1.2 rt(θ)≤1+ϵ=1.2,低概率动作难以快速上升,导致探索不足。
- 对高概率动作的抑制不足:当错误动作在旧策略中概率较高时, r t ( θ ) r_t(\theta) rt(θ) 需变小以降低其概率,但 ϵ \epsilon ϵ 限制可能不够灵活,错误动作未被充分抑制。
熵崩溃的结果是模型生成重复或次优序列(例如短序列或固定模式),在 Long-CoT 任务中表现为“长度崩溃”或推理能力退化。
2. Clip-Higher:解耦 ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh
VAPO 提出 Clip-Higher 方法,将 PPO 的裁剪范围解耦为 ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh,设置 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2, ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28。新的裁剪代理目标为:
L PPO ( θ ) = − 1 ∑ i = 1 G ∣ σ i ∣ ∑ i = 1 G ∑ t = 1 ∣ σ i ∣ min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ϵ low , 1 + ϵ high ) A ^ i , t ) \mathcal{L}_{\text{PPO}}(\theta) = -\frac{1}{\sum_{i=1}^G |\sigma_i|} \sum_{i=1}^G \sum_{t=1}^{|\sigma_i|} \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}(r_{i,t}(\theta), 1-\epsilon_{\text{low}}, 1+\epsilon_{\text{high}}) \hat{A}_{i,t} \right) LPPO(θ)=−∑i=1G∣σi∣1i=1∑Gt=1∑∣σi∣min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i,t)
2.1 解耦设计
-
ϵ low \epsilon_{\text{low}} ϵlow:
- 控制概率比的下界: r t ( θ ) ≥ 1 − ϵ low r_t(\theta) \geq 1-\epsilon_{\text{low}} rt(θ)≥1−ϵlow。
- 当 A ^ t < 0 \hat{A}_t < 0 A^t<0(动作有害), r t ( θ ) < 1 r_t(\theta) < 1 rt(θ)<1(新策略降低动作概率),裁剪确保 r t ( θ ) r_t(\theta) rt(θ) 不低于 1 − ϵ low = 0.8 1-\epsilon_{\text{low}} = 0.8 1−ϵlow=0.8,防止动作概率下降过多。
- 设置 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2(与传统 PPO 一致),保持对高概率错误动作的适度抑制,避免完全消除这些动作(可能阻碍探索)。
-
ϵ high \epsilon_{\text{high}} ϵhigh:
- 控制概率比的上界: r t ( θ ) ≤ 1 + ϵ high r_t(\theta) \leq 1+\epsilon_{\text{high}} rt(θ)≤1+ϵhigh。
- 当 A ^ t > 0 \hat{A}_t > 0 A^t>0(动作有益), r t ( θ ) > 1 r_t(\theta) > 1 rt(θ)>1(新策略提升动作概率),裁剪确保 r t ( θ ) r_t(\theta) rt(θ) 不超过 1 + ϵ high = 1.28 1+\epsilon_{\text{high}} = 1.28 1+ϵhigh=1.28,允许更大范围的概率上升。
- 设置 ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28(高于传统 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2),为低概率动作提供更多上升空间,鼓励探索。
2.2 动机
- 鼓励低概率动作的探索:
- 在稀疏奖励场景(如 Long-CoT),正确答案可能出现在旧策略的低概率动作中(例如复杂的推理步骤)。传统 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2 限制 r t ( θ ) ≤ 1.2 r_t(\theta) \leq 1.2 rt(θ)≤1.2,低概率动作 π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t|s_t) πθold(at∣st) 难以快速提升(需多次更新)。
- 增大 ϵ high \epsilon_{\text{high}} ϵhigh 到 0.28 允许 r t ( θ ) ≤ 1.28 r_t(\theta) \leq 1.28 rt(θ)≤1.28,低概率动作的概率 π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st) 可增加更多( 1.28 × π θ old 1.28 \times \pi_{\theta_{\text{old}}} 1.28×πθold),加快探索正确答案。
- 谨慎抑制高概率动作:
- 高概率的错误动作(常见于训练初期)需通过 r t ( θ ) < 1 r_t(\theta) < 1 rt(θ)<1 降低概率。保持 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2 确保 r t ( θ ) ≥ 0.8 r_t(\theta) \geq 0.8 rt(θ)≥0.8,避免动作概率骤降为零(可能导致熵崩溃)。
- 非对称裁剪( ϵ low < ϵ high \epsilon_{\text{low}} < \epsilon_{\text{high}} ϵlow<ϵhigh)平衡了探索(通过 ϵ high \epsilon_{\text{high}} ϵhigh)与稳定抑制(通过 ϵ low \epsilon_{\text{low}} ϵlow)。
3. 单一 ϵ \epsilon ϵ vs. 解耦 ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh
现在我们比较两种方法:
- 传统 PPO(单一 ϵ \epsilon ϵ):增大 ϵ \epsilon ϵ(例如从 0.2 到 0.28)。
- VAPO Clip-Higher(解耦 ϵ \epsilon ϵ):设置 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2, ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28。
3.1 单一 ϵ \epsilon ϵ 的效果
增大单一 ϵ \epsilon ϵ(如 ϵ = 0.28 \epsilon = 0.28 ϵ=0.28)对 PPO 裁剪的影响是:
- 上界: r t ( θ ) ≤ 1 + ϵ = 1.28 r_t(\theta) \leq 1+\epsilon = 1.28 rt(θ)≤1+ϵ=1.28,允许更大的概率上升,鼓励低概率动作的探索。
- 下界: r t ( θ ) ≥ 1 − ϵ = 0.72 r_t(\theta) \geq 1-\epsilon = 0.72 rt(θ)≥1−ϵ=0.72,允许更大的概率下降,增强对高概率错误动作的抑制。
- 对称性:上界和下界的裁剪幅度相同( ± 0.28 \pm 0.28 ±0.28),对 A ^ t > 0 \hat{A}_t > 0 A^t>0 和 A ^ t < 0 \hat{A}_t < 0 A^t<0 的动作施加等量的约束。
优点:
- 增强探索:更大的 ϵ \epsilon ϵ 允许低概率动作更快上升,缓解熵崩溃,适合稀疏奖励场景。
- 简单性:无需调整多个参数,保持 PPO 的原始设计。
缺点:
- 过度抑制高概率动作:
- 当 A ^ t < 0 \hat{A}_t < 0 A^t<0, r t ( θ ) ≥ 0.72 r_t(\theta) \geq 0.72 rt(θ)≥0.72 比 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2 的 r t ( θ ) ≥ 0.8 r_t(\theta) \geq 0.8 rt(θ)≥0.8 更严格,可能导致高概率动作(即使部分正确)被过度压制。
- 在 Long-CoT 中,某些高概率动作可能是推理链的一部分,过度降低其概率可能破坏序列的连贯性。
- 不稳定性:
- 对称增大裁剪范围可能导致策略更新过于激进,尤其在稀疏奖励下,模型可能在探索和利用之间失衡,引发震荡。
- 缺乏灵活性:
- 单一 ϵ \epsilon ϵ 无法区分“鼓励低概率动作上升”和“谨慎抑制高概率动作”的需求,难以精细优化探索-利用权衡。
3.2 解耦 ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh 的效果
VAPO 的 Clip-Higher 方法通过非对称裁剪( ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2, ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28)实现:
- 上界: r t ( θ ) ≤ 1.28 r_t(\theta) \leq 1.28 rt(θ)≤1.28,与单一 ϵ = 0.28 \epsilon = 0.28 ϵ=0.28 相同,鼓励低概率动作探索。
- 下界: r t ( θ ) ≥ 0.8 r_t(\theta) \geq 0.8 rt(θ)≥0.8,与传统 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2 一致,温和抑制高概率错误动作。
- 非对称性:对 A ^ t > 0 \hat{A}_t > 0 A^t>0 的动作(有益)提供更大自由度(+0.28),对 A ^ t < 0 \hat{A}_t < 0 A^t<0 的动作(有害)保持保守约束(-0.2)。
优点:
- 精准鼓励探索:
- ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28 允许低概率动作更快上升,适合 Long-CoT 任务中寻找稀有正确答案(如复杂推理路径)。
- 例如,若旧策略中某正确动作概率为 0.01, ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28 允许新概率升至 0.01 ⋅ 1.28 = 0.0128 0.01 \cdot 1.28 = 0.0128 0.01⋅1.28=0.0128,比 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2 的 0.01 ⋅ 1.2 = 0.012 0.01 \cdot 1.2 = 0.012 0.01⋅1.2=0.012 更显著。
- 保护高概率动作:
- ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2 限制 r t ( θ ) ≥ 0.8 r_t(\theta) \geq 0.8 rt(θ)≥0.8,防止高概率动作(可能包含部分正确推理)被过度抑制。
- 相比单一 ϵ = 0.28 \epsilon = 0.28 ϵ=0.28 的 r t ( θ ) ≥ 0.72 r_t(\theta) \geq 0.72 rt(θ)≥0.72,更温和的抑制避免了策略分布的剧烈收缩,降低熵崩溃风险。
- 灵活性:
- 解耦允许独立调整探索( ϵ high \epsilon_{\text{high}} ϵhigh)和抑制( ϵ low \epsilon_{\text{low}} ϵlow),更适应稀疏奖励场景的需求。
- 在 Long-CoT 中,探索正确推理路径比快速排除错误路径更关键, ϵ high > ϵ low \epsilon_{\text{high}} > \epsilon_{\text{low}} ϵhigh>ϵlow 优先满足探索需求。
- 稳定性:
- 非对称裁剪在鼓励探索的同时保持保守抑制,减少策略更新的震荡,提升训练稳定性。
缺点:
- 复杂性:需要调优两个参数( ϵ low \epsilon_{\text{low}} ϵlow 和 ϵ high \epsilon_{\text{high}} ϵhigh),相比单一 ϵ \epsilon ϵ 增加超参数选择成本。
- 任务依赖性: ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28 和 ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2 针对 AIME 任务优化,其他任务可能需要重新调整。
3.3 对比分析
| 特性 | 单一 ϵ \epsilon ϵ(如 0.28) | 解耦 ϵ low = 0.2 , ϵ high = 0.28 \epsilon_{\text{low}} = 0.2, \epsilon_{\text{high}} = 0.28 ϵlow=0.2,ϵhigh=0.28 |
|---|---|---|
| 上界 | r t ( θ ) ≤ 1.28 r_t(\theta) \leq 1.28 rt(θ)≤1.28 | r t ( θ ) ≤ 1.28 r_t(\theta) \leq 1.28 rt(θ)≤1.28 |
| 下界 | r t ( θ ) ≥ 0.72 r_t(\theta) \geq 0.72 rt(θ)≥0.72 | r t ( θ ) ≥ 0.8 r_t(\theta) \geq 0.8 rt(θ)≥0.8 |
| 探索能力 | 强(低概率动作可显著上升) | 强(同单一 ϵ = 0.28 \epsilon = 0.28 ϵ=0.28) |
| 抑制高概率动作 | 较强(可能过度压制) | 温和(保护潜在正确动作) |
| 熵崩溃缓解 | 部分缓解(但下界严格) | 更有效(非对称鼓励探索) |
| 稳定性 | 可能降低(激进更新) | 更高(平衡探索与抑制) |
| 灵活性 | 较低(对称约束) | 更高(独立调整上下界) |
核心区别:
- 单一 ϵ \epsilon ϵ 对概率上升和下降施加对称约束,增大 ϵ \epsilon ϵ 同时增强探索和抑制,可能导致高概率动作被过度压制,破坏推理连贯性。
- 解耦 ϵ \epsilon ϵ 通过 ϵ high > ϵ low \epsilon_{\text{high}} > \epsilon_{\text{low}} ϵhigh>ϵlow 优先鼓励低概率动作的探索,同时温和抑制错误动作,精细平衡探索-利用权衡,特别适合稀疏奖励的 Long-CoT 任务。
4. 代码实现
以下是将 Clip-Higher 集成到 VC-PPO 代码中的实现,基于之前的框架。我们修改 train_vapo 函数中的策略损失计算,加入非对称裁剪范围
ϵ
low
\epsilon_{\text{low}}
ϵlow 和
ϵ
high
\epsilon_{\text{high}}
ϵhigh。
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.utils.data import DataLoader, Dataset
import numpy as np
from tqdm import tqdm
import os
# 假设已有 LongCoTEnvironment, PolicyModel, ValueModel, TrajectoryDataset, compute_length_adaptive_gae
def train_vapo(
model_name="Qwen/Qwen2.5-32B",
value_checkpoint_path="./value_checkpoint/epoch_10/value_checkpoint.pt",
prompts=["Solve the equation x^2 - 5x + 6 = 0"],
num_epochs=10,
num_trajectories=100,
batch_size=4,
num_mini_batches=4,
policy_lr=1e-6,
value_lr=2e-6,
epsilon_low=0.2, # 新增:下界裁剪参数
epsilon_high=0.28, # 新增:上界裁剪参数
alpha=0.05,
lambda_critic=1.0,
max_length=512,
save_path="./vapo_checkpoint",
device="cuda"
):
# 初始化
tokenizer = AutoTokenizer.from_pretrained(model_name)
base_model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
policy_model = PolicyModel(base_model).to(device)
old_policy_model = PolicyModel(base_model).to(device)
old_policy_model.load_state_dict(policy_model.state_dict())
policy_optimizer = optim.Adam(policy_model.parameters(), lr=policy_lr)
value_model = ValueModel(base_model).to(device)
checkpoint = torch.load(value_checkpoint_path)
value_model.load_state_dict(checkpoint["value_model_state_dict"])
value_optimizer = optim.Adam(value_model.parameters(), lr=value_lr)
env = LongCoTEnvironment(tokenizer, policy_model, prompts, max_length)
for epoch in range(num_epochs):
# 收集轨迹
states, actions, log_probs, rewards, values, sequence_lengths = [], [], [], [], [], []
print(f"Epoch {epoch+1}/{num_epochs}: Collecting trajectories...")
for _ in tqdm(range(num_trajectories)):
input_ids, generated_ids, action_ids, action_log_probs, reward = env.generate_trajectory(policy_model)
with torch.no_grad():
value = value_model(generated_ids, attention_mask=(generated_ids != tokenizer.pad_token_id).long())
seq_len = generated_ids.size(1) - input_ids.size(1)
states.append(generated_ids)
actions.append(action_ids)
log_probs.append(action_log_probs)
rewards.append(reward)
values.append(value.cpu().numpy())
sequence_lengths.append(seq_len)
# 计算长度自适应 GAE
advantages_actor, value_targets_critic = compute_length_adaptive_gae(
rewards, values, sequence_lengths, alpha, lambda_critic
)
# 创建数据集
dataset = TrajectoryDataset(states, actions, log_probs, advantages_actor, value_targets_critic)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 小批量更新
policy_model.train()
value_model.train()
total_policy_loss = 0
total_value_loss = 0
for _ in range(num_mini_batches):
for batch in tqdm(dataloader, desc="Mini-batch update"):
state_ids = batch["states"].to(device)
action_ids = batch["actions"].to(device)
old_log_probs = batch["log_probs"].to(device)
advantages = batch["advantages"].to(device)
value_targets = batch["value_targets"].to(device)
# 计算当前策略的 log 概率
logits = policy_model(state_ids, attention_mask=(state_ids != tokenizer.pad_token_id).long())
log_probs = torch.log_softmax(logits, dim=-1)
action_log_probs = torch.gather(log_probs[:, :-1], -1, action_ids.unsqueeze(-1)).squeeze(-1)
# 计算概率比
ratio = torch.exp(action_log_probs - old_log_probs)
# 标记级策略梯度损失 + Clip-Higher
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - epsilon_low, 1 + epsilon_high) * advantages # 非对称裁剪
policy_loss = -torch.min(surr1, surr2).mean() # 标记级平均
# 计算价值损失
values = value_model(state_ids, attention_mask=(state_ids != tokenizer.pad_token_id).long())
value_loss = ((values - value_targets) ** 2).mean() / 2
# 优化策略
policy_optimizer.zero_grad()
policy_loss.backward()
policy_optimizer.step()
# 优化价值
value_optimizer.zero_grad()
value_loss.backward()
value_optimizer.step()
total_policy_loss += policy_loss.item()
total_value_loss += value_loss.item()
# 更新旧策略
old_policy_model.load_state_dict(policy_model.state_dict())
avg_policy_loss = total_policy_loss / (num_mini_batches * len(dataloader))
avg_value_loss = total_value_loss / (num_mini_batches * len(dataloader))
print(f"Epoch {epoch+1}/{num_epochs}, Policy Loss: {avg_policy_loss:.4f}, Value Loss: {avg_value_loss:.4f}")
# 保存检查点
checkpoint_dir = os.path.join(save_path, f"epoch_{epoch+1}")
os.makedirs(checkpoint_dir, exist_ok=True)
torch.save({
"policy_model_state_dict": policy_model.state_dict(),
"value_model_state_dict": value_model.state_dict(),
"epoch": epoch + 1,
"policy_loss": avg_policy_loss,
"value_loss": avg_value_loss
}, os.path.join(checkpoint_dir, "vapo_checkpoint.pt"))
print(f"Saved checkpoint to {checkpoint_dir}")
return policy_model, value_model, tokenizer
5. 代码实现详解
5.1 关键修改
- 参数添加:
- 函数签名新增
epsilon_low=0.2和epsilon_high=0.28,替换原clip_eps。
- 函数签名新增
- 裁剪逻辑:
- 原 VC-PPO:
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages - VAPO Clip-Higher:
surr2 = torch.clamp(ratio, 1 - epsilon_low, 1 + epsilon_high) * advantages - 使用非对称裁剪范围: 1 − ϵ low = 0.8 1-\epsilon_{\text{low}} = 0.8 1−ϵlow=0.8, 1 + ϵ high = 1.28 1+\epsilon_{\text{high}} = 1.28 1+ϵhigh=1.28。
- 原 VC-PPO:
- 损失计算:
- 保持标记级平均(与之前的修改一致),确保长序列优化不受影响。
- 裁剪后的代理目标直接对所有标记平均。
5.2 注意事项
- 超参数选择:
- ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2 和 ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28 基于 AIME 任务优化,可能需根据任务调整(例如 ϵ high ∈ [ 0.25 , 0.3 ] \epsilon_{\text{high}} \in [0.25, 0.3] ϵhigh∈[0.25,0.3])。
- 数值稳定性:
- 确保
ratio计算中避免数值溢出(通过exp的对数运算已处理)。
- 确保
- 与 GAE 的兼容性:
- Clip-Higher 不影响 GAE 计算,优势 A ^ i , t \hat{A}_{i,t} A^i,t 的正负号决定裁剪方向( A ^ i , t > 0 \hat{A}_{i,t} > 0 A^i,t>0 用 ϵ high \epsilon_{\text{high}} ϵhigh, A ^ i , t < 0 \hat{A}_{i,t} < 0 A^i,t<0 用 ϵ low \epsilon_{\text{low}} ϵlow)。
6. 效果与意义
6.1 实验证据
VAPO 的消融实验(论文 Table 1)显示:
- 移除 Clip-Higher 后,AIME 2024 得分从 60 降至 46,下降 14 分。
- 这表明非对称裁剪对缓解熵崩溃和提升探索能力至关重要。
6.2 单一 ϵ \epsilon ϵ vs. 解耦 ϵ \epsilon ϵ 的效果
- 单一
ϵ
=
0.28
\epsilon = 0.28
ϵ=0.28:
- 增强探索,但可能过度抑制高概率动作,导致推理链断裂或不稳定。
- 在 Long-CoT 中,模型可能生成不连贯的短序列,难以优化复杂推理。
- 解耦
ϵ
low
=
0.2
,
ϵ
high
=
0.28
\epsilon_{\text{low}} = 0.2, \epsilon_{\text{high}} = 0.28
ϵlow=0.2,ϵhigh=0.28:
- 优先鼓励低概率动作(如正确推理步骤)快速上升,同时保护高概率动作(如部分正确的推理路径)。
- 提升探索效率,减少熵崩溃风险,生成更长、更连贯的序列。
- 实验表明,VAPO 的熵曲线(Figure 2c)在后期较低但稳定,表明探索充分且性能未受损。
6.3 Long-CoT 任务的适配性
在 Long-CoT 任务中:
- 稀疏奖励:正确答案稀有,需通过低概率动作探索。 ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28 加速这一过程。
- 长序列连贯性:推理链需保持逻辑一致, ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2 避免破坏高概率动作。
- 结果:Clip-Higher 帮助模型生成更长的推理序列(Figure 2a),提升 AIME 得分。
7. 总结
Clip-Higher 通过解耦 PPO 的裁剪范围( ϵ low = 0.2 \epsilon_{\text{low}} = 0.2 ϵlow=0.2, ϵ high = 0.28 \epsilon_{\text{high}} = 0.28 ϵhigh=0.28),解决了稀疏奖励下的熵崩溃问题:
- 与单一
ϵ
\epsilon
ϵ 的区别:
- 单一 ϵ \epsilon ϵ(如 0.28)对称增强探索和抑制,可能过度压制高概率动作,导致不稳定。
- 解耦 ϵ \epsilon ϵ 非对称鼓励低概率动作探索( ϵ high \epsilon_{\text{high}} ϵhigh),同时温和抑制错误动作( ϵ low \epsilon_{\text{low}} ϵlow),更灵活地平衡探索-利用。
- 效果:
- 提升探索能力,加速发现正确推理路径(AIME 得分提升 14 分)。
- 保持训练稳定性,避免长度崩溃,适合 Long-CoT 的稀疏奖励场景。
- 代码实现:
- 简单修改裁剪逻辑,替换
clip_eps为epsilon_low和epsilon_high,无缝集成到 VC-PPO。
- 简单修改裁剪逻辑,替换
这一方法展示了非对称裁剪在强化学习中的潜力,不仅适用于 Long-CoT 任务,还可推广到其他稀疏奖励的 RLHF 场景,如代码生成或复杂对话优化。
后记
2025年4月15日于上海,在grok 3大模型辅助下完成。

















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









