







1 DDPG简介
DDPG吸收了Actor-Critic让Policy Gradient 单步更新的精华,而且还吸收让计算机学会玩游戏的DQN的精华,合并成了一种新算法,叫做Deep Deterinistic Policy Gradient。那DDPG到底是什么样的算法呢,我们就拆开来分析,我们将DDPG分成’Deep’和’Deterministic Policy Cradient’又能被细分为’Deterministic’和’Policy Gradient’,接下来,我们开始一个一个分析。
1.1 Deep和DQN
Deep顾名思义,就是走向更深层次,DQN就是使用一个记忆库和两套结构相同,但参数更新频率不同的神经网络能有效促进学习。那我们也把这种思想运用到DDPG当中,使DDPG也具备这种优良行式。但是DDPG的神经网络行式却比DQN的要复杂一点点。需要回顾DQN可以点击这里:https://blog.csdn.net/shoppingend/article/details/124379079?spm=1001.2014.3001.5502阅读【强化学习】Deep Q Network深度Q网络(DQN)一文回顾。
1.2 Deterministic Policy Gradient
Policy Gradient相比于其他强化学习算法,它能被用来在连续动作上进行动作的筛选。而且筛选的时候使根据所学习的动作分布随机进行筛选,而Deterministic有点看不下去,Deteriministic会让Policy Gradient在做动作的时候没有必要那么不确定,那么犹豫,反正最后都要输出一个动作值,没有必要随机。所以Deterministic就改变了输出动作的过程,斩钉截铁的直在连续的动作上输出一个动作值。
1.3 DDPG神经网络
DDPG神经网络其实和我们之前提到的Actor-Critic行式差不多,也需要基于策略Policy的神经网络和基于价值的Value神经网络,但是为了体现DQN和思想,每种神经网络我们都需要再细分为两个,Policy Gradient这边,我们由估计网络和现实网络,估计网络用来输出实时的动作,供actor在现实中实行。而现实网络则是用来更新价值网络系统的。所以我们再来看看价值系统这边,我们也有现实网络和估计网络,他们在输出这个状态的价值,而输入端却有不同,状态现实网络这边会拿着从动作加上状态的观测值加以分析,而状态估计网络则是拿着当时Actor施加的动作当作输入。在实际运用中,DDPG的这种做法的确带来了更有效的学习过程。
2 DDPG算法
2.1 要点
一句话概括DDPG:Google DeepMind提出的一种使用Actor-Critic 结构,但是输出的不是行为的概率,而是具体的行为,用于连续动作(continuous action)的预测。DDPG结合了之前获得成功的DQN结构,提到了Actor-Critic的稳定性和收敛性。Actor-Critic不完全清楚的可以点这里https://blog.csdn.net/shoppingend/article/details/124341639?spm=1001.2014.3001.5502了解一下。
2.2 算法
DDPG的算法实际上就是一种Actor-Critic,关于Actor部分,他的参数更新同样会涉及到Critic。
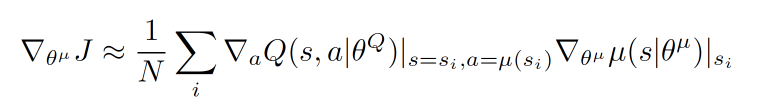
上面是关于Actor参数的更新,它的前半部分grad[Q]是从Critic来的,这是在说:这次Actor的动作要怎么移动,才能获得更大的Q,而后半部分grad[μ]是从Actor来的,这是在说:Actor要怎么样修改自身参数,使得Actor更有可能做这个动作。所以两者合起来就是在说:Actor要朝着更有可能获取大Q的方向修改动作参数了。
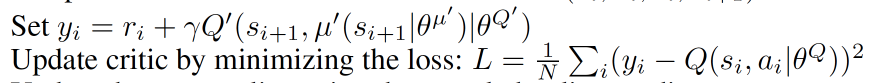
上面这个是关于Critic的更新, 它借鉴了DQN和Double Q-Learning的方式,有两个计算Q的神经网络,Q_target中依据下一状态,用Actor来选择动作,而这时的Actor也是一个Actor_target(有着Actor很久之前的参数)。使用这种方法获得的Q_target能像DQN那样切断相关性,提高收敛性。
2.3 代码主结构
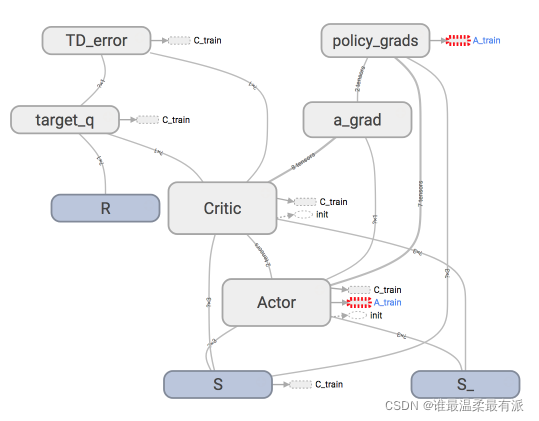
我们用Tensorflow搭建神经网络,主结构可以见这个tensorboard的出来的图。
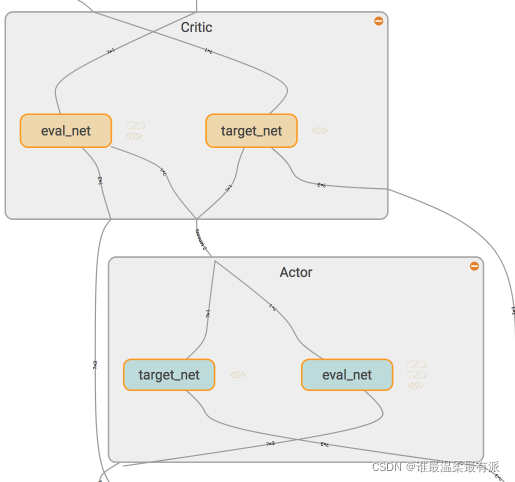
单独看Actor和Critic中各有什么结构
其搭建的代码部分在这:
class Actor(object):
def __init__(self):
...
with tf.variable_scope('Actor'):
# 这个网络用于及时更新参数
self.a = self._build_net(S, scope='eval_net', trainable=True)
# 这个网络不及时更新参数, 用于预测 Critic 的 Q_target 中的 action
self.a_ = self._build_net(S_, scope='target_net', trainable=False)
...
class Critic(object):
def __init__(self):
with tf.variable_scope('Critic'):
# 这个网络是用于及时更新参数
self.a = a # 这个 a 是来自 Actor 的, 但是 self.a 在更新 Critic 的时候是之前选择的 a 而不是来自 Actor 的 a.
self.q = self._build_net(S, self.a, 'eval_net', trainable=True)
# 这个网络不及时更新参数, 用于给出 Actor 更新参数时的 Gradient ascent 强度
self.q_ = self._build_net(S_, a_, 'target_net', trainable=False)
2.4 Actor-Critic
有了Actor-Critic每个里面各两个神经网络结构的了解,我们再来看看他们是如何进行交流,传递信息的。我们从Actor的学习更新方式开始说起。
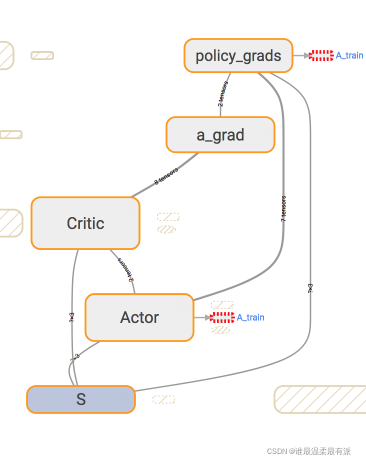
这张图一眼就能看穿Actor的更新到底基于了那些东西。可以看出,它使用了两个eval_net,所以Actor class中用于train的代码我们这样写:
with tf.variable_scope('policy_grads'):
# 这是在计算 (dQ/da) * (da/dparams)
self.policy_grads = tf.gradients(
ys=self.a, xs=self.e_params, # 计算 ys 对于 xs 的梯度
grad_ys=a_grads # 这是从 Critic 来的 dQ/da
)
with tf.variable_scope('A_train'):
opt = tf.train.AdamOptimizer(-self.lr) # 负的学习率为了使我们计算的梯度往上升, 和 Policy Gradient 中的方式一个性质
self.train_op = opt.apply_gradients(zip(self.policy_grads, self.e_params)) # 对 eval_net 的参数更新
同时下面也提到的传送给Actor的a_grad应该用Tensorflow怎么计算。这个a_grad是Critic class里面的,这个a是来自Actor根据s计算而来的:
with tf.variable_scope('a_grad'):
self.a_grads = tf.gradients(self.q, self.a)[0] # dQ/da
而在Critic中,我们用的东西简单一点。
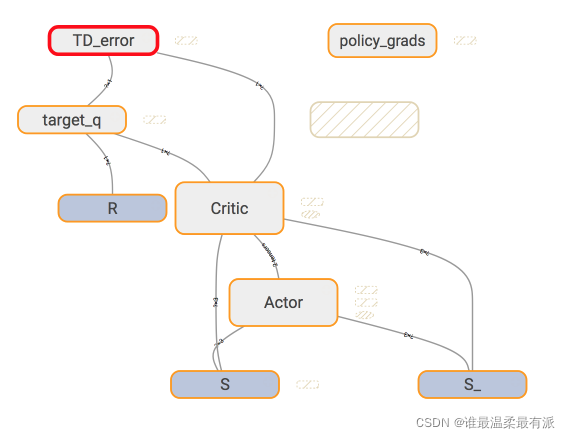
下面就是Critic的更新代码。
# 计算 target Q
with tf.variable_scope('target_q'):
self.target_q = R + self.gamma * self.q_ # self.q_ 根据 Actor 的 target_net 来的
# 计算误差并反向传递误差
with tf.variable_scope('TD_error'):
self.loss = tf.reduce_mean(tf.squared_difference(self.target_q, self.q)) # self.q 又基于 Actor 的 target_net
with tf.variable_scope('C_train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(self.loss)
最后我们建立并把Actor和Critic融合在一起的时候是这样写的。
actor = Actor(...)
critic = Critic(..., actor.a, actor.a_) # 将 actor 同它的 eval_net/target_net 产生的 a/a_ 传给 Critic
actor.add_grad_to_graph(critic.a_grads) # 将 critic 产出的 dQ/da 加入到 Actor 的 Graph 中去
2.5 记忆库Memory
以下是关于类似于DQN的记忆库代码,我们用了一个class来建立。
class Memory(object):
def __init__(self, capacity, dims):
"""用 numpy 初始化记忆库"""
def store_transition(self, s, a, r, s_):
"""保存每次记忆在 numpy array 里"""
def sample(self, n):
"""随即从记忆库中抽取 n 个记忆进行学习"""
2.6 每回合算法
这里的回合算法只提到了最重要的部分,省掉了一些没必要的
var = 3 # 这里初始化一个方差用于增强 actor 的探索性
for i in range(MAX_EPISODES):
...
for j in range(MAX_EP_STEPS):
...
a = actor.choose_action(s)
a = np.clip(np.random.normal(a, var), -2, 2) # 增强探索性
s_, r, done, info = env.step(a)
M.store_transition(s, a, r / 10, s_) # 记忆库
if M.pointer > MEMORY_CAPACITY: # 记忆库头一次满了以后
var *= .9998 # 逐渐降低探索性
b_M = M.sample(BATCH_SIZE)
... # 将 b_M 拆分成下面的输入信息
critic.learn(b_s, b_a, b_r, b_s_)
actor.learn(b_s)
s = s_
if j == MAX_EP_STEPS-1:
break
文章来源:莫凡强化学习https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/
















 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









