







教程1:在启用安全启动的 Fedora 中安装英伟达驱动
教程2:UEFI安全启动模式下安装Ubuntu的NVIDIA显卡驱动
1. 搜索合适的驱动
Nvidia驱动官网
选择这个
驱动(.run)链接
2. 安装必要的软件依赖
CUDA底层用C++写的,因此导入编译器
sudo apt install update
sudo apt install gcc
sudo apt install g++
sudo apt install make
3. 禁用集成显卡驱动nouveau
编辑系统(etc)的黑名单列表文件
sudo nano /etc/modprobe.d/blacklist.conf
把nouveau加入黑名单
blacklist nouveau
Ctrl+s保存,Ctrl+X退出,重载黑名单
sudo update-initramfs -u
4. 安装nvidia显卡驱动
更改权限,执行驱动安装文件
cd 下载
chmod +x NVIDIA-Linux-x86_64-550.90.07.run
./NVIDIA-Linux-x86_64-550.90.07.run
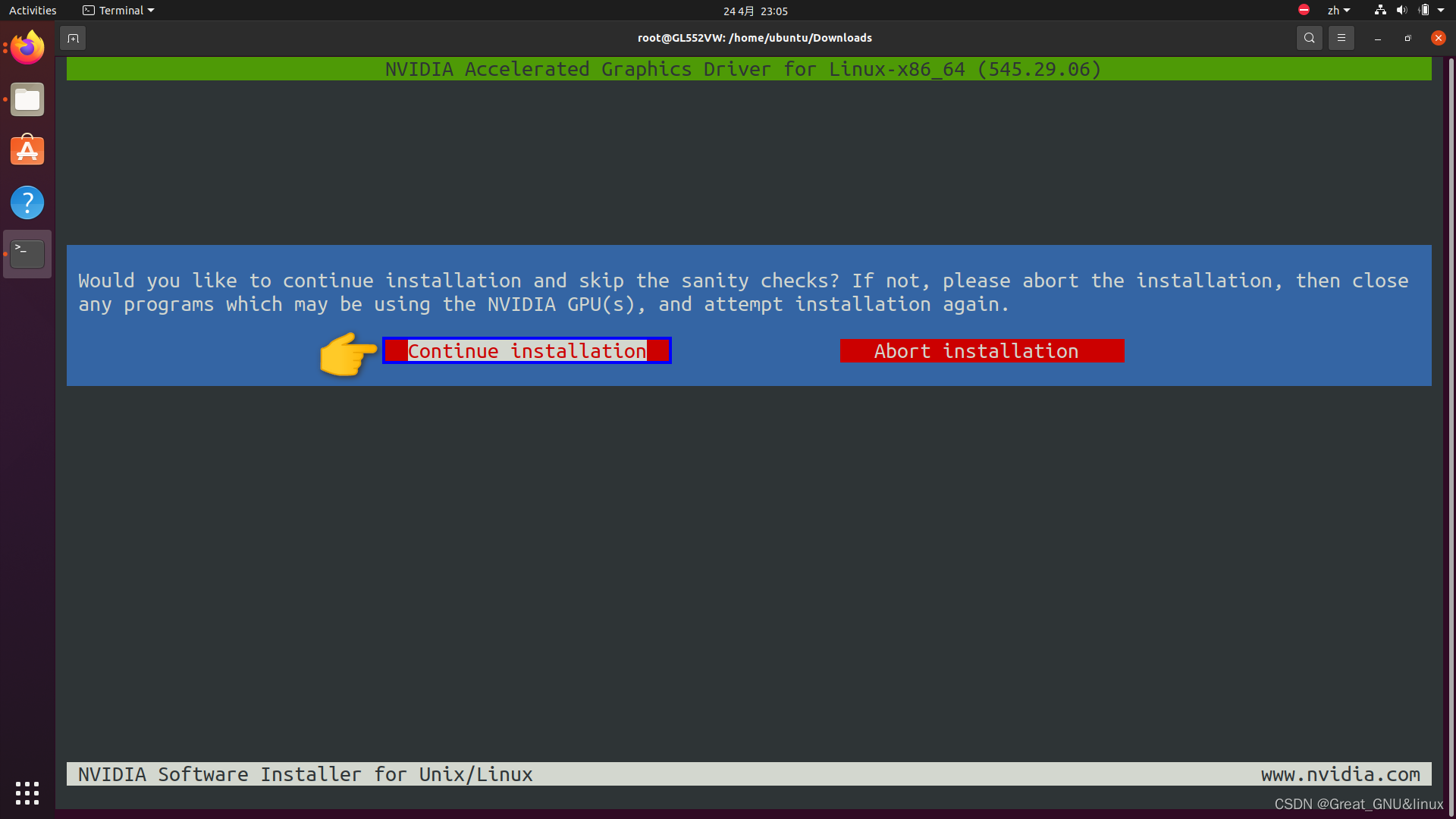
提醒你关闭所有使用NVIDIA GPU的程序防止崩溃:
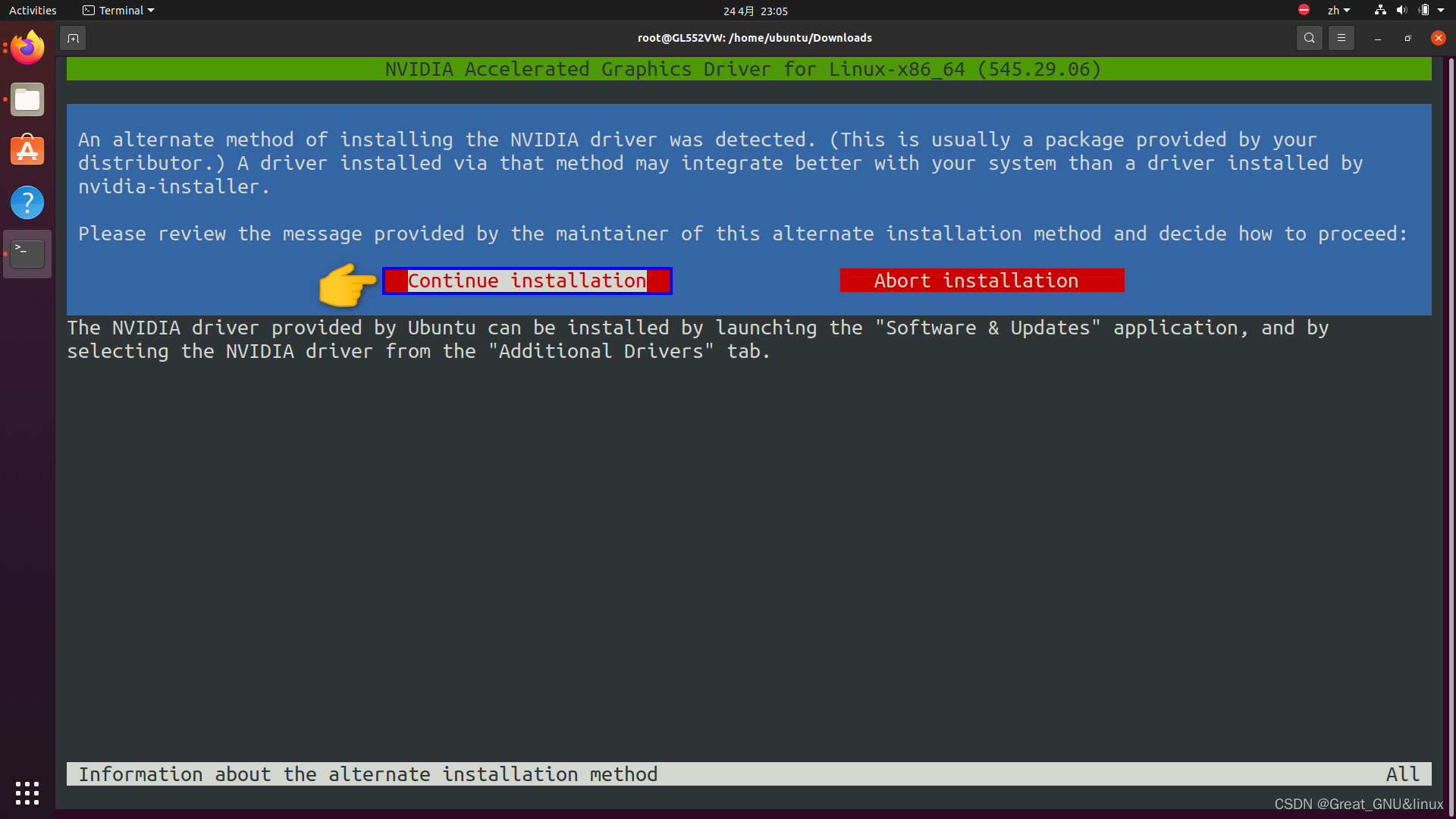
提醒你安装Nvidia驱动的另一种方式:
从"软件和更新"应用中,从附加驱动标签下选择NVIDIA Drivers;
proceeding…

目标内核(Linux内核)支持内核模块(如NVIDIA显卡驱动)加密签名,如果没有有效的签名,内核可能会拒绝工作,要给该内核签名吗?
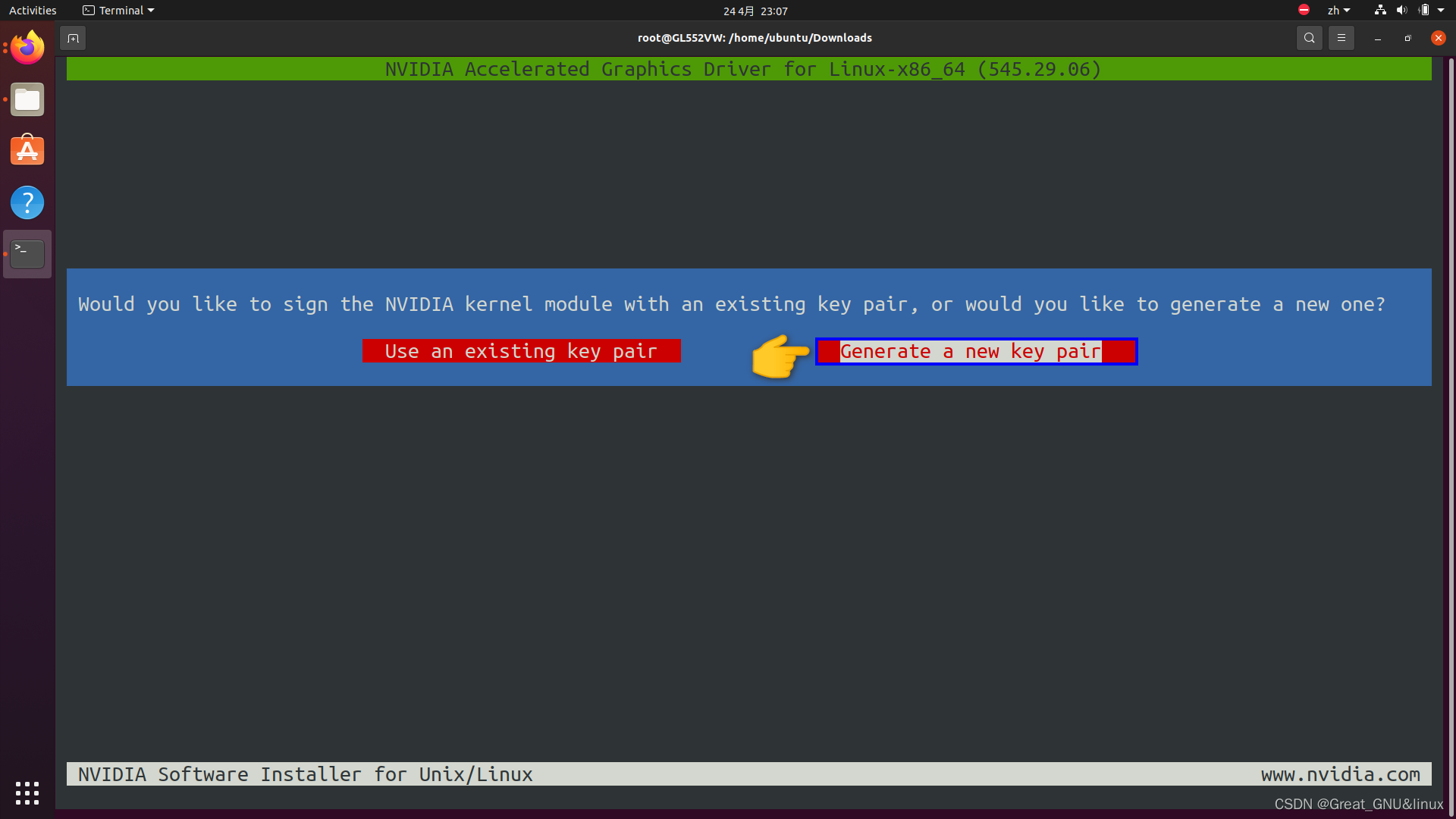
选择签名方式——生成一个新的密钥对,
删除私钥,但保留公钥
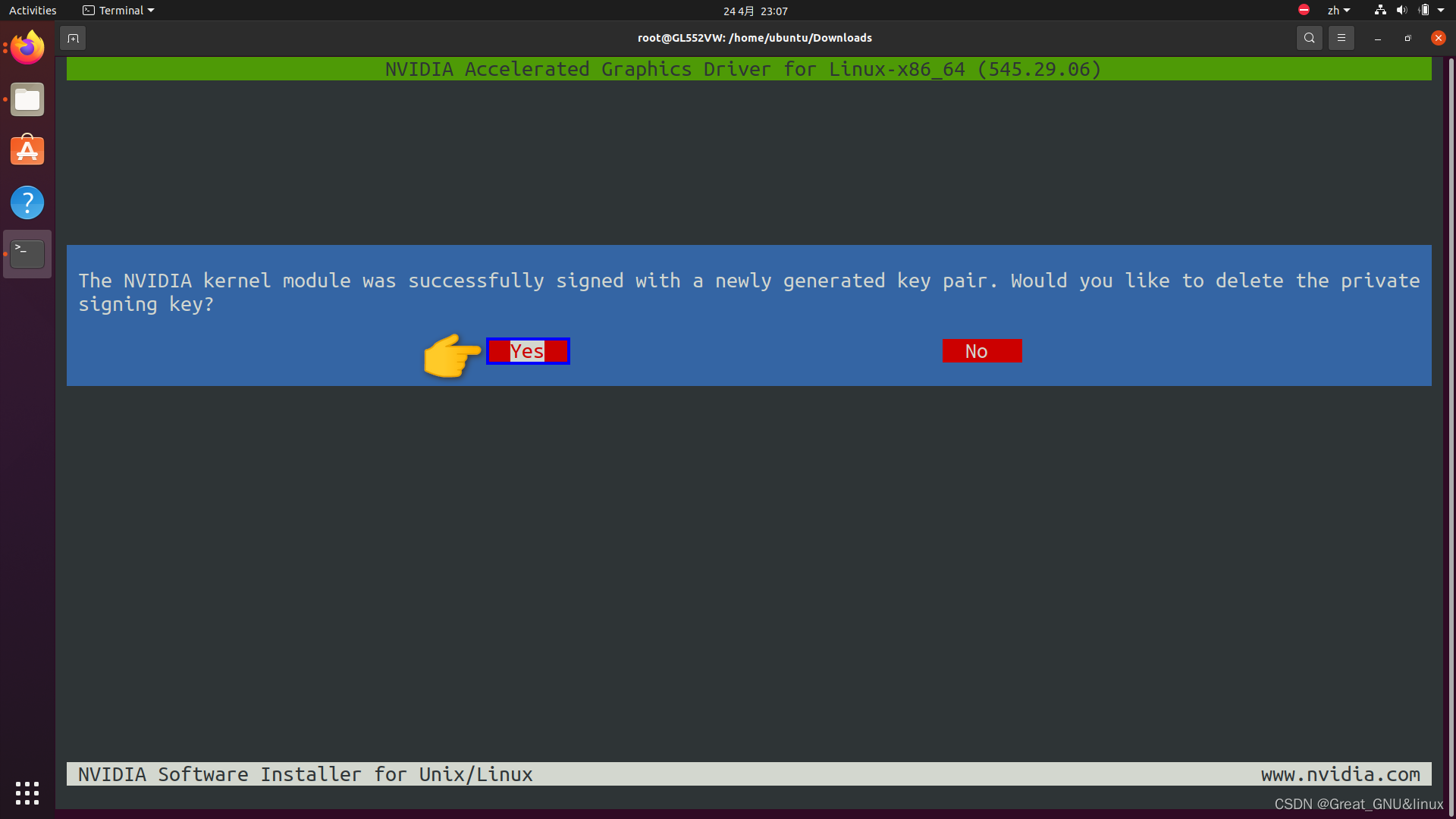
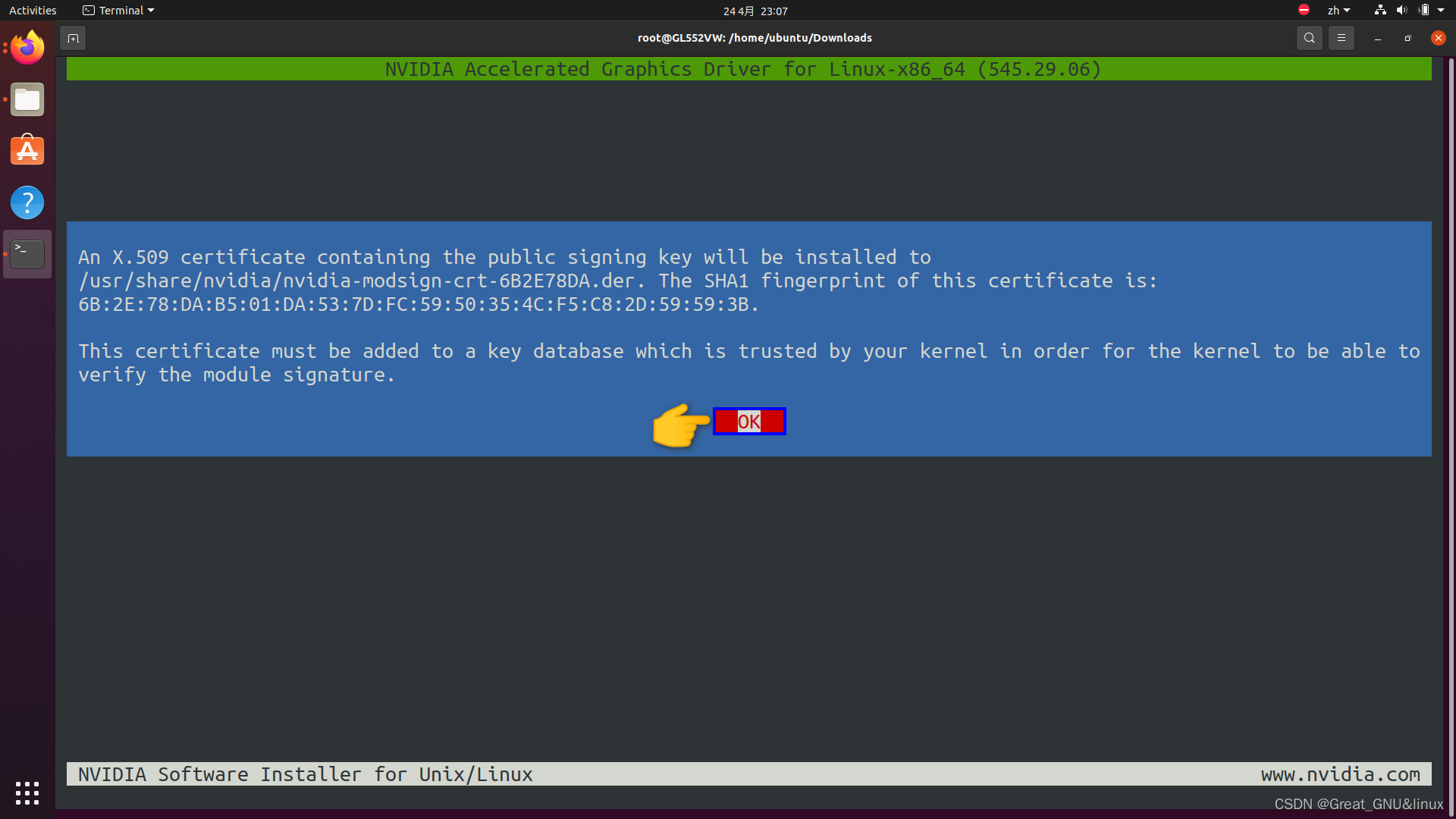
加载证书到内核信任的关键数据库,使得内核能够验证模块签名:
拒绝用DKMS为N卡注册内核模块 ,自动构建一个新的模块(这里选否)。
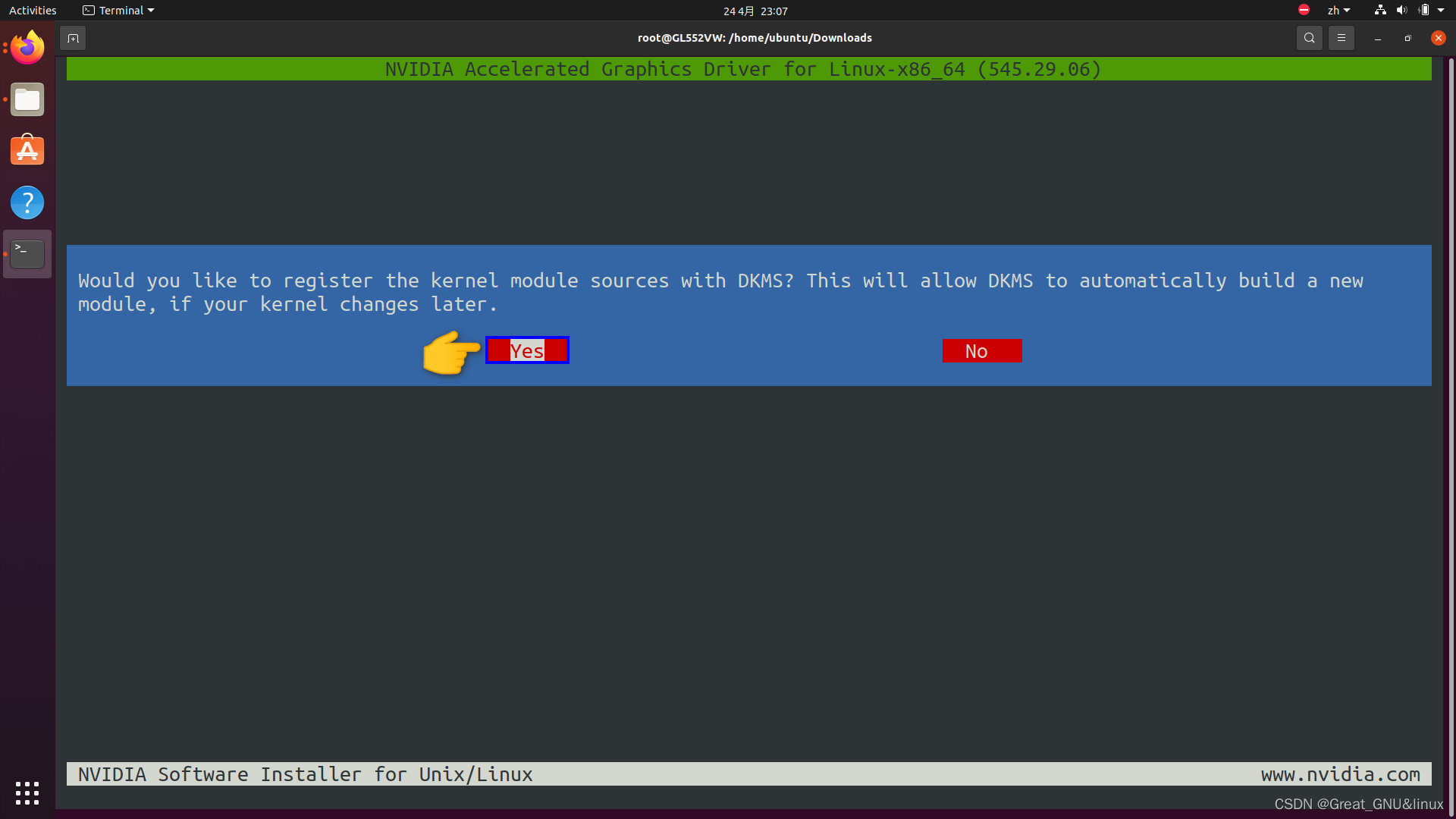
DKMS(dynamic kernel module support)
安装NVIDIA显卡驱动
完成
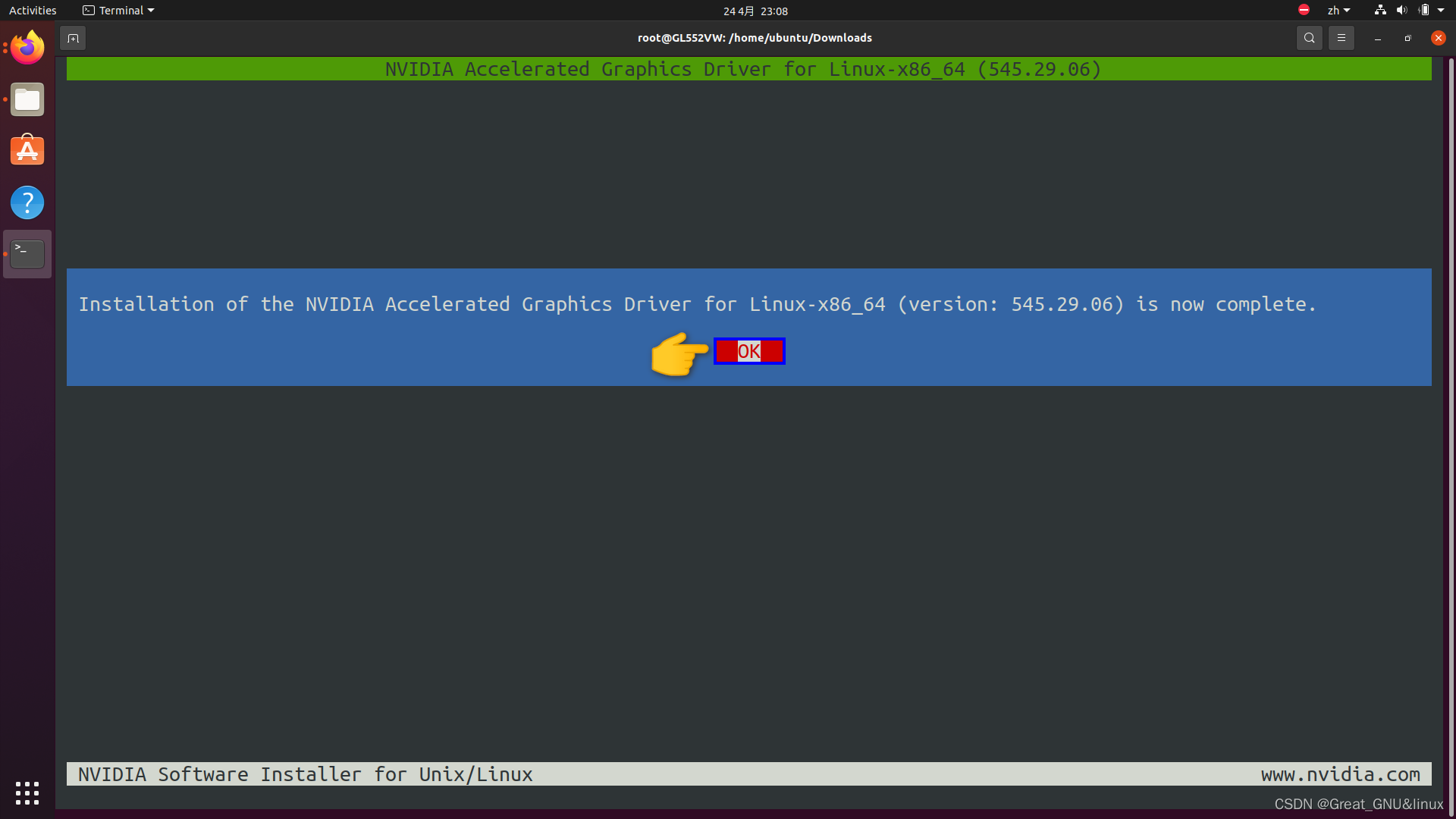
建议重启,来重载NVIDIA模块。
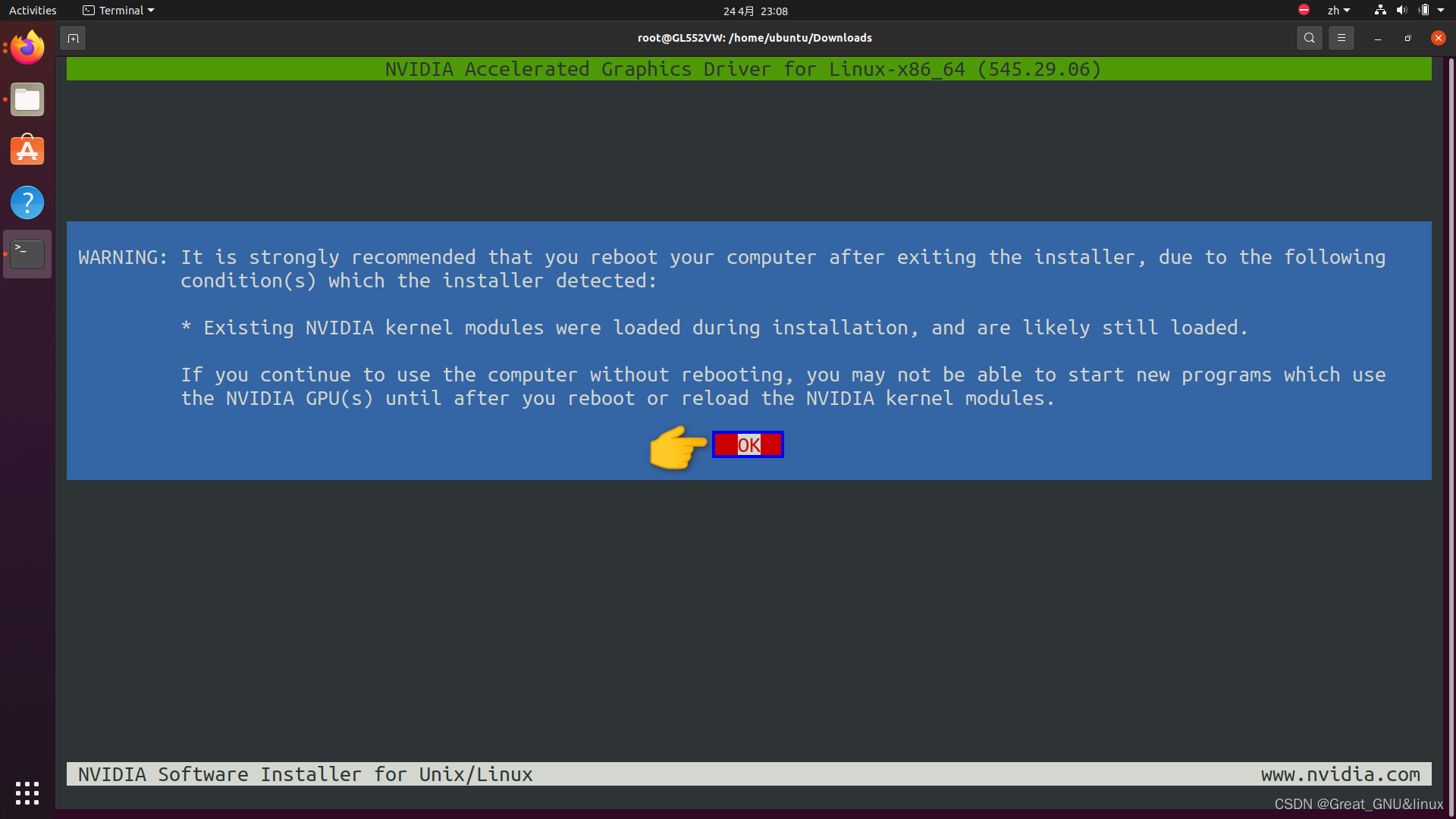
5. 重启
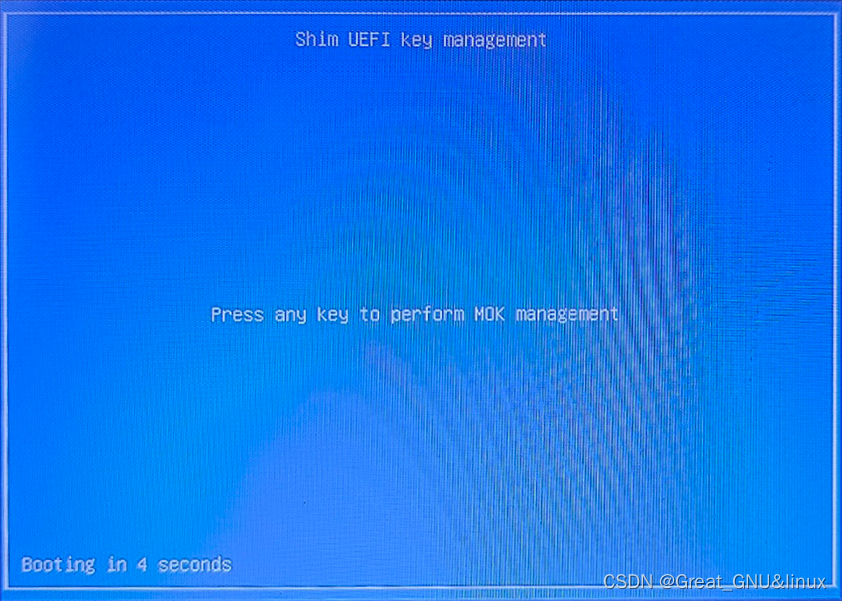
进入NVIDIA模块
cd /usr/share/nvidia
ls
mokutil导入公钥到内核的信任列表中
mokutil --import nvidia-modsign-crt-6B2E78DA.der
mokutil是一个Linux命令,它用于管理UEFI Secure Boot中的机密所有者键(MOK)。UEFI Secure Boot是一种安全功能,可以防止未经授权的操作系统或驱动程序加载到计算机上。MOK是用于验证操作系统或驱动程序签名的密钥。mokutil命令可以用来查看、添加、删除和更新MOK密钥,以及启用或禁用Secure Boot。
接下来会提示输入公钥的访问密码,两次输入后重启系统,
通过上下键选择,Enter键确认。
在perform MOK mangement界面选择enroll mok。
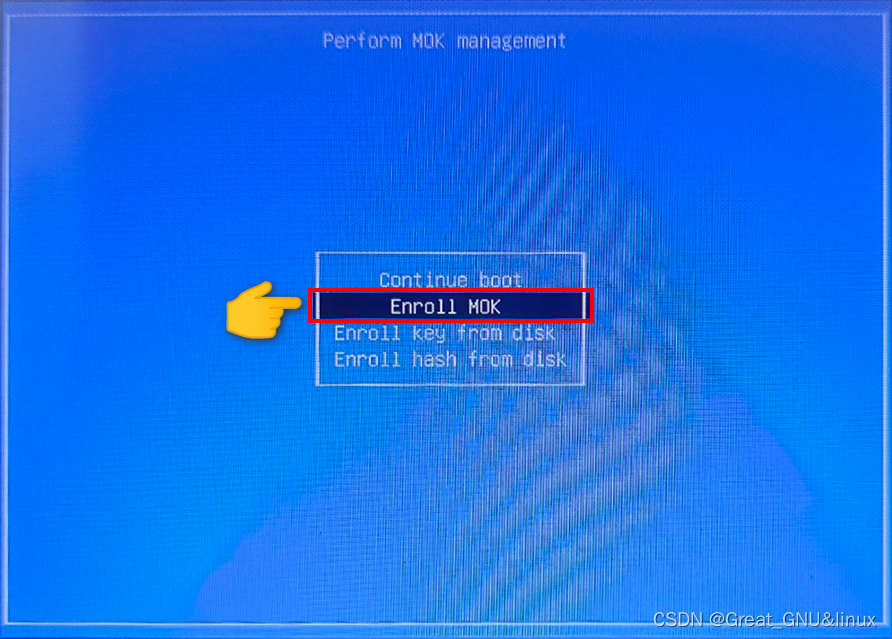
选择continue(enroll mok界面),yes,输入公钥访问密码,
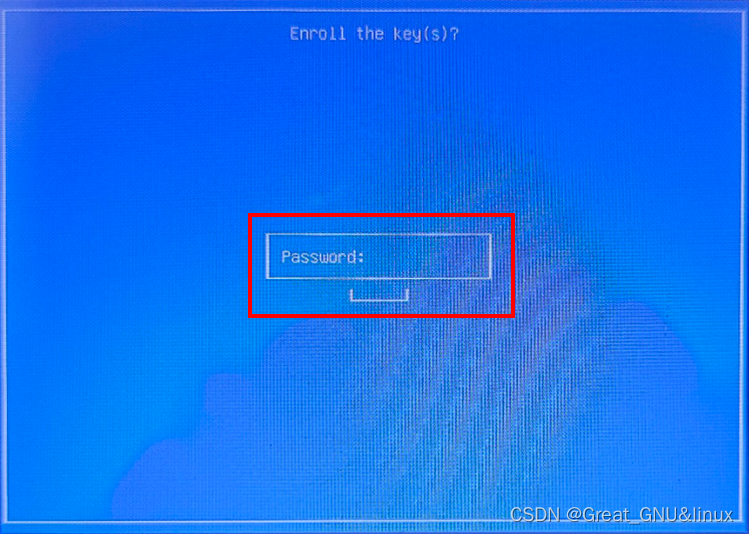
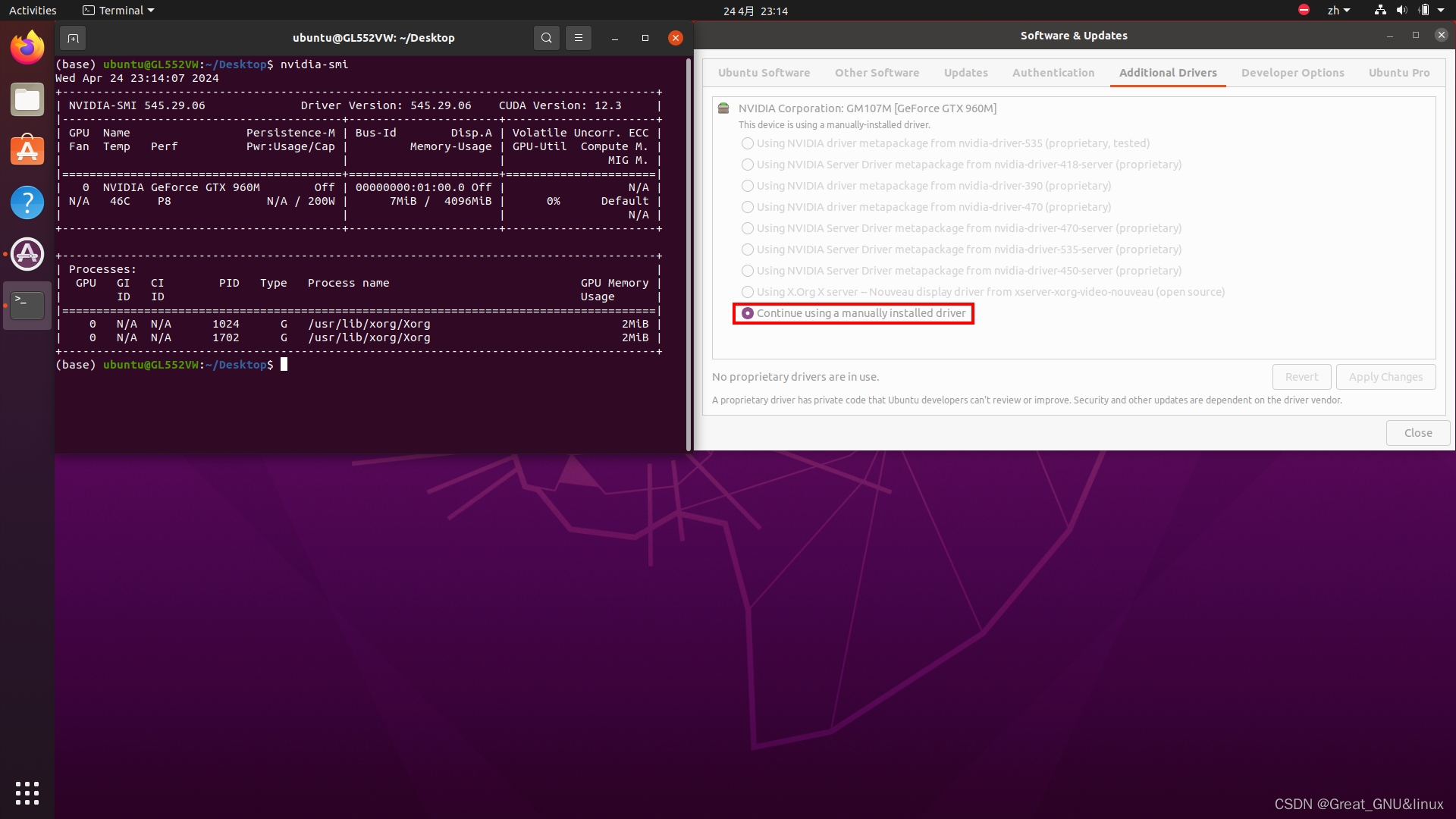
boot即可,nvidia-smi即可看到显卡信息。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









