







在机器学习开发和数据科学领域,在试验特征、标准化技术和超参数的组合时,协作记录、集成和构建模型非常复杂。此外,在不扭曲公司核心目标的情况下,跟踪实验、重现结果、打包部署模型、存储和管理模型是一项完整的任务
由于上述原因,很明显需要改进 ML 开发,使其成为更健壮、可预测、标准化和过滤的软件开发。为了更进一步,许多组织已经开始构建内部机器学习平台来管理 ML 生命周期,但他们仍然面临挑战,因为大多数 ML 平台通常只支持一小部分 ML 库的内置算法,这些算法是绑定到每个公司的基础设施。此外,这些平台通常不是开源的,用户无法轻松利用新的 ML 库或与社区中的其他人分享他们的工作。
管理 ML 实验生命周期也可以称为 MLOps,它是机器学习、开发和操作的组合。机器学习就是关于实验本身、训练、调整和寻找最佳模型。开发是关于开发管道和工具,以集成机器学习模型并将其从开发/实验阶段转移到登台和生产阶段。最后,运维是关于 CI/CD 工具、大规模监控和管理模型的。看看图 3-1,模型生命周期的每个步骤都需要由负责整个 MLOps 的团队支持。
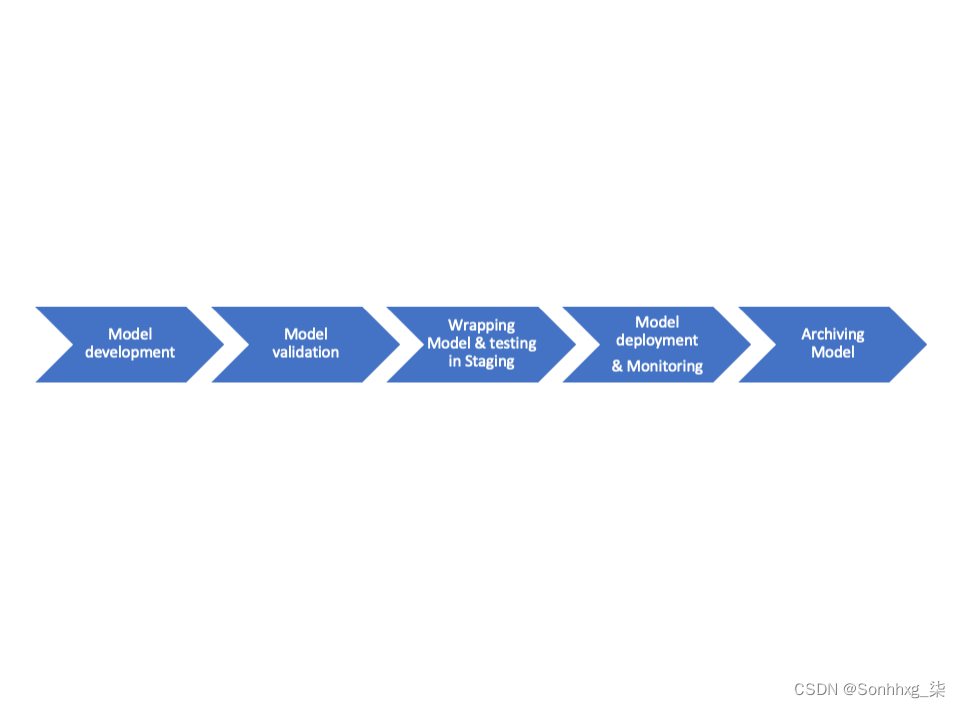
图 3-1。机器学习模型生命周期,从开发到存档
ML 实验是存储在存储库(例如 Git 分支)中的 ML 管道代码。它们包含代码 + 数据 + 模型,是研发软件生命周期不可或缺的一部分。对于本书,我们选择 MLFlow 是因为它是开源的,与 Apache Spark 原生集成,并允许我们通过抽象复杂的功能来管理 ML 实验,同时允许灵活地进行协作和扩展到其他工具。
什么是 MLflow
MLflow 是一个可以简化 ML 生命周期管理的平台。它允许用户及其团队使用标准化结构来管理数据,包括其实验、可重复性、部署和中央模型注册表。
MLflow 重新定义了特征组织并集成了整个 ML 工作流程。从总体实验到单次运行试验再到团队的个别成员,MLflow 允许您有效地跟踪您的过程。每个超参数调整、每个功能更改、每个可能的指标都可以使用 MLflow 记录在一个有组织的位置。它是让您的团队保持同步和相互联系的工具。
从高层次的方法来看,您可以将其拆分为两个主要组件,如图 3-2所示的跟踪服务器和模型注册表,其余是流程的支持组件。模型注册后,团队可以构建自动化作业和 REST 服务以将其移动到下游。请注意,平台本身并不处理模型从暂存到存档的移动,这需要专门的工程工作。
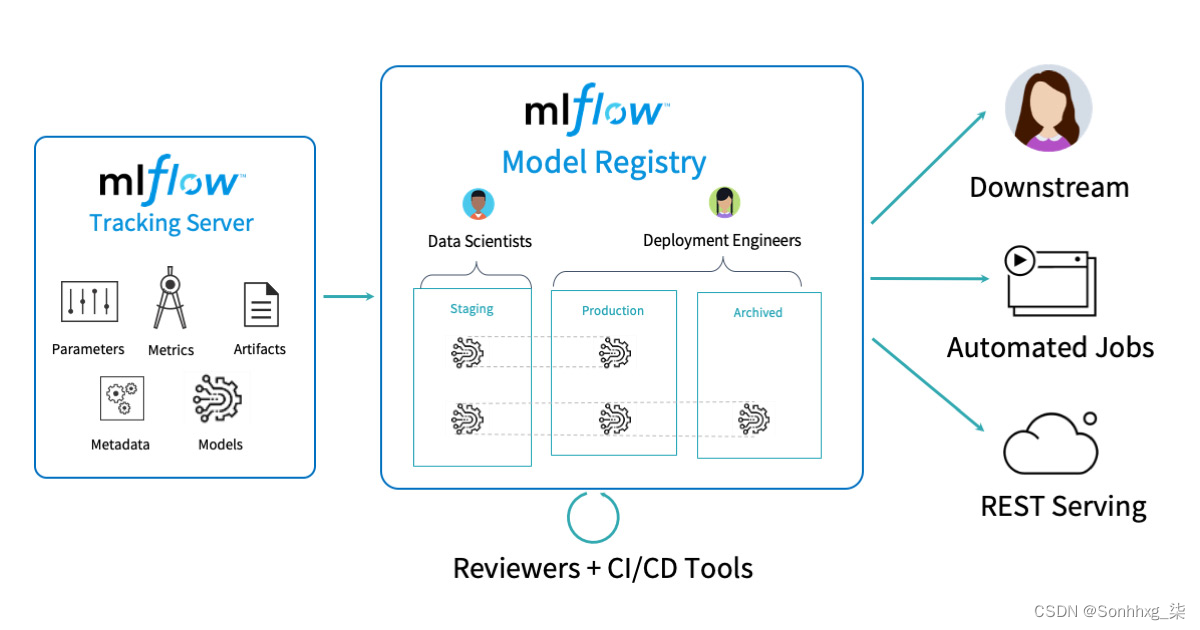
图 3-2。MLflow的数据块图
MLFlow 平台的软件组件
为了更好地理解它的工作原理,让我们看一下它的软件组件,包括存储、后端服务器、前端/UI 组件、API 和 CLI。
贮存
MLflow 支持连接到多种存储类型并利用它们来跟踪 ml 工作流。存储可以是文件、数据库或任何其他存储概念的目录。它包含有关实验、多次运行、参数等的所有信息。
后端服务器
负责在数据库/存储、UI、SDK 和 CLI 与其余组件之间传递信息。从实验等中捕获日志。
前端
这是 UI 端,我们可以在这里以可视化的方式交互/跟踪实验和运行,如图 3-2 所示。
API 和命令行界面
我们编写的代码和我们使用 MLFlow 的命令行。
我们可以从 API、CLI 或其 UI 与 MLFlow 平台进行交互。在幕后,它跟踪我们提供给它的所有信息。API/CLI 还生成专用目录,可以将这些目录推送到 git 存储库以实现更好的协作。在图 3-3中,您可以看到一个在实验中管理多个运行的 UI 示例。
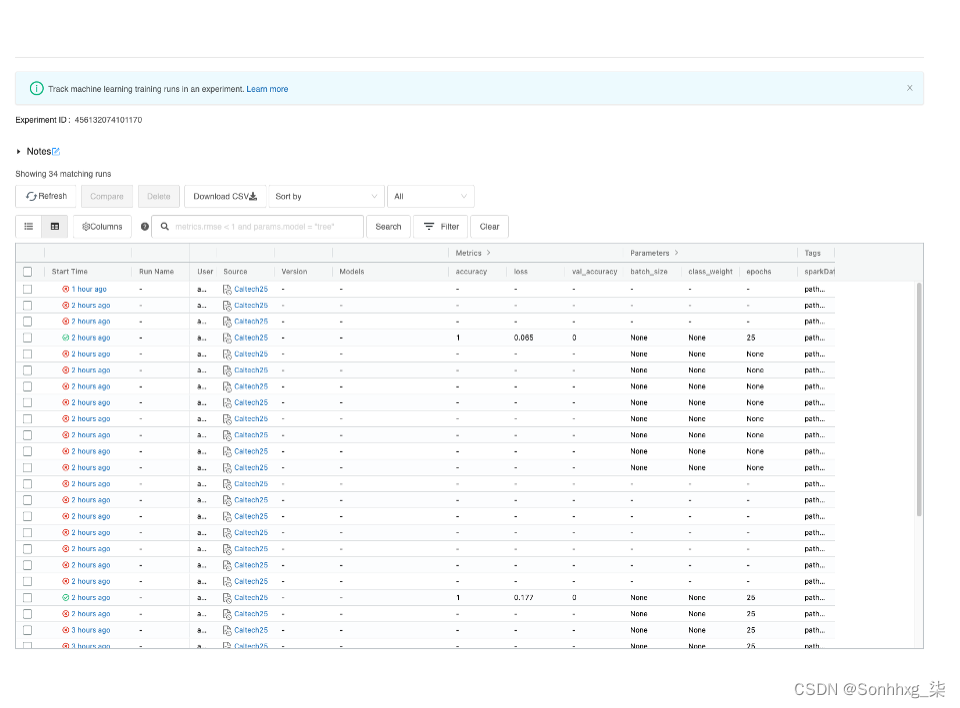
图 3-3。显示多次运行及其跟踪作为实验的一部分
MLflow 在不同组织中的使用
可以想象,许多部分组合在一起来完成生产机器学习和端到端构建生命周期的难题。正因为如此,MLFlow 可用于不同的组织,许多技术角色都将使用它。其中一些角色包括:
个人用户
作为不承担组织责任的个人,您可以使用 MLFlow 在您的机器上本地跟踪实验,组织项目中的代码以供将来使用,并输出您可以稍后在新数据上测试的模型。您也可以用它来组织您的研究工作。
数据科学团队
作为一个团队,处理相同问题并试验不同模型的数据科学家可以通过部署 MLflow Tracking 来比较他们的结果。任何有权访问 git 存储库的人都可以下载并运行其他团队成员的模型。访问 MLflow UI 以跟踪各种参数并更好地了解实验阶段。
组织
从组织的角度来看,您可以打包团队协作的培训和数据准备步骤,并比较从事同一任务的不同团队的结果。例如,工程团队可以轻松地将工作流程从研发转移到暂存到生产。他们可以共享项目、模型和结果,并使用 MLflow 项目运行另一个团队的代码。
机器学习工程师/开发人员
通常,数据科学家会与 ML/AI 工程师一起工作。使用 MLflow,数据科学家和工程师可以将代码以 MLflow 项目格式发布到 GitHub,让任何人都可以轻松运行他们的代码。此外,ML 工程师可以输出 MLflow Model 格式的模型,以自动支持使用 MLflow 内置工具进行部署。ML Engineering 还将与 DevOps 团队合作,围绕 MLFlow 数据库定义 webhooks,以便在开发阶段之间移动模型,从开发、验证、登台、生产和退役。
MLflow 的逻辑组件
MLflow目前提供了四个逻辑组件,tracking,用于捕获与实验相关的参数和信息,一个项目组件,用于捕获文件系统下的整个项目,模型,一个跟踪模型并保存在项目中的逻辑组件,以及最后,注册表抽象了存储,用于捕获与模型的实验和状态相关的信息。让我们详细讨论一下。
MLflow 跟踪
MLflow Tracking 可以在独立脚本(不绑定到任何特定框架)或笔记本中使用。它提供了一个 API、UI 和 CLI,用于在运行机器学习代码时记录实验参数、代码本身及其版本、ML 指标和输出文件,以便稍后将它们可视化。它还使您能够使用 Python 和其他一些 API 记录和查询实验。
MLflow Tracking 基于运行结束实验的概念,这些实验只不过是执行一些数据科学代码。您可以定义如何记录 MLflow 运行,它可以是本地文件、数据库或远程跟踪服务器。默认情况下,MLflow Python API 日志在本地运行到mlruns目录中的文件。
Runs
一般来说,运行是作为实验的一部分记录和打包的一些数据科学代码的执行。
Experiments
一个实验可以有很多运行。这是运行的主要访问控制。
在您运行代码的任何地方使用 MLflow Python、R、Java 和 REST API 记录运行以供进一步使用和跟踪。您可以在独立程序、远程云计算机或笔记本中使用跟踪功能。作为MLflow 项目的一部分,它在记录的运行中跟踪项目 URI 和源版本。稍后允许您使用Tracking UI或 MLflow API 查询所有记录的运行。
如何使用 MLflow Tracking 记录跑步
假设我们有一个要使用 MLFlow 运行和跟踪的 TensorFlow 实验。我们的第一步是导入mlflow.tensorflow库。之后,我们可以利用自动记录功能或以编程方式记录参数和指标。
要开始运行,在 Python 中我们可以使用with运算符 - 与mlflow.start_run() - 此 API 调用在实验中选择一个新的运行(如果存在)。如果不存在实验,它会自动创建一个新实验。您可以使用API 或 UI创建自己的实验。在运行中,您开发训练代码并利用 log_params 和 log_metric 来跟踪重要信息。最后,您记录您的模型和所有必要的工件(稍后会详细介绍)。查看示例 3-1 中的代码片段以更好地理解流程的工作原理:mlflow.create_experiment()
示例 3-1。示例 3-1
import mlflow
import mlflow.tensorflow
# 启用 mlflow autolog 来记录指标和模型
mlflow.tensorflow.autolog()
with mlflow.start_run():
# 日志参数(键值对)
mlflow.log_param("num_dimensions", 8)
...
# 记录任何浮动指标;指标可以在整个运行过程中更新
mlflow.log_metric("alpha", 0.1)
... some machine learning training code
...
# 日志工件(输出文件)
mlflow.log_artifact("model.pkl")
mlflow.log_model(“ml_model_path”) 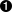
自动记录指标、参数和工件
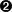
在此实验下启动新运行或启动现有实验(如果有)。

记录我们在 ml 算法中使用的合作伙伴。

记录可在整个运行过程中更新的指标。

记录项目的工件。

记录机器学习模型本身。
在撰写本书时,mlflow.tensorflow.autolog ()是1.20.2版本中的实验方法。它使用 TensorFlow 回调机制将各种功能挂接到训练、评估和预测阶段。
Callbacks
可以将回调传递给拟合、评估和预测等 TensorFlow 方法,以便挂接到模型训练和推理生命周期的各个阶段。例如,您可以利用它们在一个时期结束时停止训练阶段,并在训练达到所需精度时通过在运行期间配置参数来削减计算成本。TensorFlow 中的回调是 Keras 库的一部分`tf.keras.callbacks.Callback`,而在 PyTorch 中,它们是pytorch_lightning.回调的一部分s’. PyTorch 的行为不同,因为回调通常是通过扩展 PyTorch 库完成的,其中最常用的是开源 PyTorch Lightning 库Grid.AI 公司。
Epoch
Epoch 表示机器学习训练算法在整个训练数据集上执行的遍数。一个纪元是遍历整个数据集。在纪元的每个周期中,您可以访问日志并使用回调以编程方式做出决策。
在训练开始时,MLFlow AutoLog 会尝试记录与训练相关的所有配置。之后,在每个纪元周期中,它会捕获日志指标,包括更新整体训练 t。在训练结束时,它使用 mlflow.keras.log_model 功能记录模型。因此,它涵盖了记录整个生命周期,您可以在其中添加您希望使用mlflow.log_param’、` mlflow.log_metric`、 `等丰富功能记录的其他参数和工件mlflow.log_artifact`。
Autolog 也可用于 PyTorch,如示例 3-2 所示。
示例 3-2。示例 3-2
# Auto log all MLflow entities
mlflow.pytorch.autolog()但是,建议您以编程方式将参数、指标、模型和工件记录为一般角色。同样的建议也适用于使用 Spark MLlib。
记录您的数据集路径和版本
对于实验跟踪、再现性和协作,我建议在训练阶段将数据集路径和版本与模型名称和路径一起记录下来。将来,它将允许您在必要时在给定确切数据集的情况下重现模型,并且还可以区分使用相同算法但输入版本不同的模型。
为此,我建议使用 `功能。mlflow.log_param()`
示例 3-3。示例 3-3
dataset_params = {"dataset_name": "twitter-accounts", "dataset_version": 2.1}
# 记录一批参数
with mlflow.start_run():
mlflow.log_params(dataset_params)另一个推荐的选项是使用运行标签作为 start_run 的一部分。
with mlflow.start_run(tags=dataset_params):MLFlow 提供了灵活的 API。由您决定如何在两个推荐的选项中构建您的实验日志。图 3-4显示了这两个选项在 UI 中的外观。
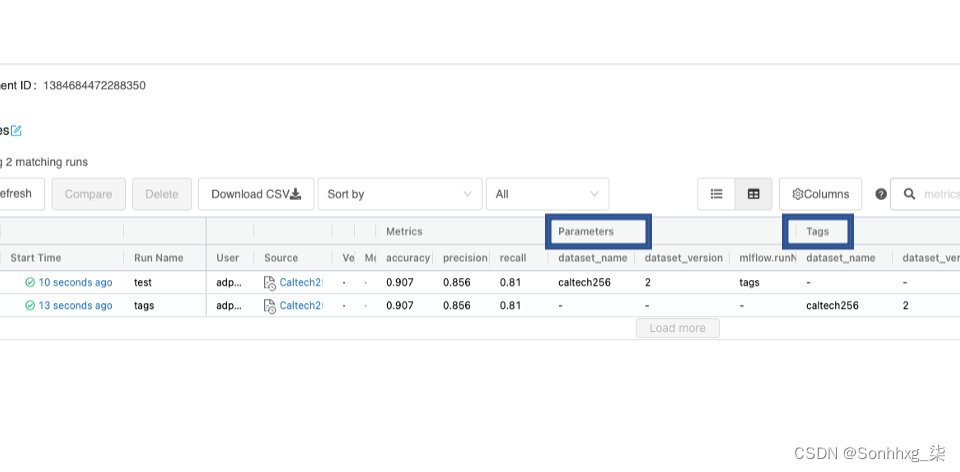
图 3-4。参数与标签
警告
您可能会问自己,为什么不使用mlflow.log_ artifacts ( local_dir , artifact_path =None)。我反对它,因为它会复制给定 `local_dir` 中的所有内容并将其写入 `artifact_path' 中。当我使用大量数据进行训练时,我想避免在没有真正必要的情况下复制数据。
至此,您了解了 MLFlow Tracking 组件的职责是记录项目打包的所有信息。
MLflow 项目
MLflow Projects 是一种用于可重用和可复制包装的标准格式,主要基于数据科学代码的约定。它包括一个 API 和命令行工具,用于执行项目并使将项目链接到工作流中成为可能。
每个项目只不过是一个包含代码或 Git 存储库的目录,并使用描述符文件来指定其依赖项以及如何运行代码。MLflow 项目由一个名为“MLproject”的简单 YAML 文件定义。
来自MLFlow docs:MLflow目前支持以下项目环境:Conda环境、Docker容器环境、系统环境。默认情况下,MLflow 使用系统路径来查找和运行 conda 二进制文件。
您可以通过更改 MLFLOW_CONDA_HOME 环境变量来决定使用不同的 Conda 安装。最重要的是,Docker 容器允许您捕获非 Python 依赖项,例如 Java 库。系统环境在运行时提供,项目的所有依赖项必须在项目执行前安装。MLflow 项目格式提供了共享可重现数据科学代码的结构,因为它是一个开源接口。MLflow Tracking 是 MLFlow 的重要组成部分,它使您能够跟踪您的工作并支持再现性、可扩展性、过滤和实验。
运行上一节中的实验会将运行记录在具有以下大纲的文件夹中:
--- 58dc6db17fb5471a9a46d87506da983f
------- artifacts
------------ model
------------ MLmodel
------------ conda.yaml
------------ input_example.json
------------ model.pkl
------- meta.yaml
------- metrics
------------ training_score
------- params
------------ A
------------ …..
------- tags
------------ mlflow.source.type
------------ mlflow.user
------- meta.yaml输出的第一行`58dc6db17fb5471a9a46d87506da983f`是实验标识也称为实验`UUID`,128位标签通用唯一标识符。
在目录的根目录下,有一个名为“meta.yaml”的 YAML 文件,其中包含有关实验的元数据。这样,我们就已经拥有了广泛的可追溯性信息,并为继续实验奠定了坚实的基础。此文件夹包含重现实验所需的所有信息。
您的项目可能有多个入口点,用于使用命名参数调用运行。由于 mlflow 项目支持 Conda,您可以通过利用 MLFlow CLI 的 Conda 环境指定代码依赖项:
mlflow run example/project -P alpha=0.5使用“-P”参数运行实验会覆盖我们在应用程序代码中描述的参数。` mlflow.log_metric("alpha", 0.1)<4>`。这使我们可以灵活地使用 CLI 工具更改参数。
MLflow 模型
MLflow Models 组件用于以多种格式打包 ML 模型,称为flavors。Flavors 部署工具可用于理解模型并编写可与来自任何 ML 库的模型一起使用的工具,而无需将每个工具与每个库集成。MLflow 模型有几种内置部署工具支持的标准风格,例如描述如何将模型作为 Python 函数运行的 Python 函数风格。
python_functionflavor 可以部署到基于 Docker 的 REST 服务器、云,并作为用户定义的函数。MLflow 还将自动记住您使用 Tracking API 将 MLflow 模型输出为工件的项目并运行它们。
如上所述,每个 MLflow 模型都是一个包含任意文件的目录,其中包含一个MLmodel文件,可以定义一个模型可以在其中使用的多种风格。
让我们看一下MLmodel描述符文件,其中列出了它可以使用的风格。
[source, yaml]
{todo:}在此示例中,模型可以与支持`tesnorflow`或python_function模型风格的工具一起使用。
MLflow 注册表
MLflow 注册表通过提供一组 API 和专用 UI 来抽象集中存储和模型状态。它还允许我们通过 CLI 管理 MLflow 模型的整个生命周期。您可以将其视为一个存储,用于存储模型,一个用于与模型阶段/状态交互、查询等的 API,一个用于模型沿袭的版本(保留给定模型的历史),以及一个用于可视化的 UI。注册表是 MLflow 组件的重要组成部分,这些组件相互连接并协同工作,为 ML 数据规则和结构提供过滤平台。在实验过程中,我们会生成多个模型,每个模型都会收到一个版本、阶段、状态和注释。所有这些都可以由 MLflow 模型注册表处理。
使用相应模型风格的log_model API记录模型后(如代码示例 3-4 所示),它会收到一个状态 - None。记录模型后,您可以将阶段从状态为“无”的“跟踪”状态更改为具有多个状态的“注册”状态。Model Registry 还负责在Staging、Production 和 Archived之间更改模型状态。
在运行期间注册模型
在训练周期中,我们会生成多个模型以选择最合适的模型。
就像您已经在跟踪部分中读到的那样,可以使用 autolog 隐式记录模型,也可以使用log_model模型函数显式记录模型。
示例 3-8。示例 3-4
mlflow.keras.log_model(keras_model=model, registered_model_name='tfmodel', artifact_path="path",)此代码片段为模型提供了STAGE_NONE(“无”),这意味着该模型已在开发阶段登录。
过渡模型阶段
在高级机器学习开发中有 4 个阶段:开发、暂存、生产和归档。由于我们的工作是使用 MLFlow 跟踪和打包的,它允许我们连接到 CI/CD(持续集成、持续部署)以在阶段之间转换模型。为此,我们需要编写专门的脚本来监听模型状态并在更新中触发所需的脚本。您还可以利用 webhooks 或您喜欢的其他机制。
要将模型从开发阶段提升到数据库中的暂存阶段,请使用 MLFlow 客户端 API:
client = MlflowClient()
Model_version = client.transition_model_version_stage(
name='tfmodel',,
version=3,
stage="Staging"
)MlflowClient是与跟踪服务器交互的 python 客户端。transition_model_version_stage功能允许我们更新模型阶段并调用所需的 CI/CD 脚本。stage参数接受以下值:Staging|Archived|Production|None。
此时,在给定一个跟踪模型状态的配置环境的情况下,从None移动到 staging 将打开一个请求,将模型从“None ”状态转换为“Staging”状态,以便在 Staging 环境中进行集成测试。我们将在第 10 章中更详细地讨论它。
了解大规模的 MLFlow 跟踪服务器
从 MLflow 配置中,我们可以为不同的任务选择多个存储。使用 MLFlow 项目本身,您可以决定将实验工件保存到何处。如果您在本地计算机上工作,则可以将其保存在本地,或者如果您在云或其他远程服务器上的笔记本上工作,则可以将项目保存在那里。MLflow 跟踪服务器(帮助我们跟踪实验信息)有两个我们需要熟悉的不同存储组件:后端存储和工件存储。参见图 3-5。
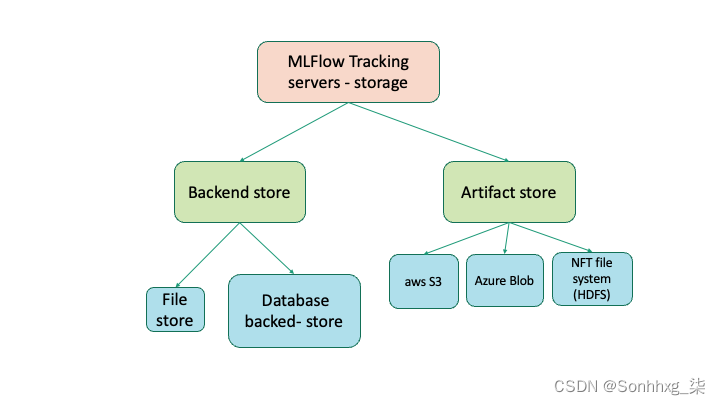
图 3-5。存储服务器选项
后端存储是 MLflow Tracking Server 存储实验的地方-运行元数据和参数、指标和标签表,请参见图 3-6以了解表的列和关系。
图 3-6。MLFlow 跟踪服务器 SQL 表层次结构
后端存储支持两种类型:文件存储和数据库支持的存储。让我们讨论一个分布式架构选项,其中跟踪服务器、后端存储和工件存储驻留在远程主机上,因为分布式架构通常比在localhost上运行更好地支持规模和团队协作。
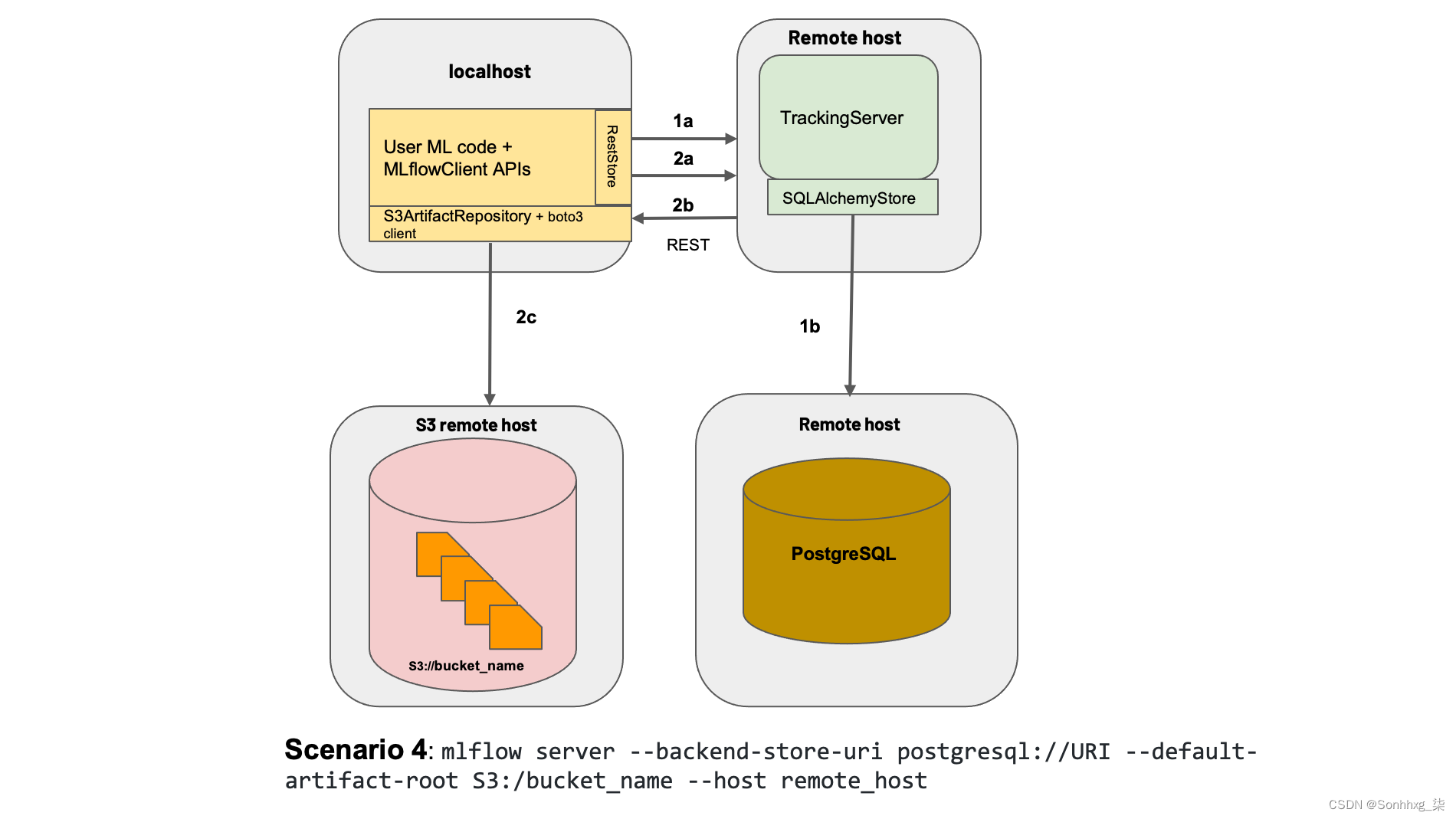
图 3-7。文档中的分布式跟踪服务器示例
从图 3-7可以看出,可能有多个主机。主要组件位于localhost和Tracking Server itself中,Storage和 Tracking Server 存储位于远程。
由于后端存储可以是文件存储或数据库后备存储,对于可扩展方法示例,我们将使用 PostgreSQL。PostgreSQL 是一个开源数据库,得到了社区的大力支持,为了使用 python 连接 itm,MLflow 使用 SQLAlchemayStore 工具。SQLAlchemayStore是 Python SQL 工具包和对象关系映射器,使开发人员能够使用 Python 直接与 PostgreSQL 交互。
对于我们的可扩展解决方案,工件存储位置应该是适合大数据的位置,因为这是我们存储可能很大的模型的地方。为此,我们需要使用 artifact-root 参数对其进行配置。
机器学习实验反模式
开发人员和数据科学家之间通常存在巨大的知识鸿沟;前几位是构建软件的专家,其他则是构建机器学习模型和解决业务问题的专家。这有时会在编码最佳实践和数据科学最佳实践之间造成不协调,从而导致通用软件反模式,尤其是在处理大规模数据或复杂系统时。例如,如果给我们一个相对较小的数据集 - 100MB,我们可以将数据集与 ML 实验代码一起保存,并在需要时将其本身输出到 Git 存储库中。然而,通常在组织合规性范围内,当我们想要完成机器学习的生产阶段时,我们需要使用可扩展的存储来满足一项或多项要求,例如隐私、GDPR、访问控制、和别的。为此,通常最好使用可扩展的存储服务。这些通常被称为对象存储服务,例如 Azure Blob、AWS S3 和公共云中的其他服务。
概括
此时,您对 MLFlow 是什么有了更好的了解,并且知道如何管理实验。使用数据、代码和模型管理 ML Pipelines 生命周期是一项重要任务,也是学习机器学习与实际将其用作组织研发生命周期的一部分之间的区别。虽然 MLFlow 允许我们管理整个实验,但我们将在第 10 章中再次讨论部署。在下一章中,我们将深入探讨数据处理、机器学习管道本身、摄取、预处理、工程等。



















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











