







1. 核心思想:
有一定的XGBoost原理理解基础的同学,首推下面这篇博客简单易理解的树模型建立过程:
简单例子说明XGBoost中树模型的构建过程_xgboost建树过程_热爱生活的菇凉的博客-CSDN博客
其中注意:贪心算法 先排序 再确定切分点
2. 原理和代码实现:
数学原理讲述很清楚的推荐:
XGBoost超详细推导,终于有人讲明白了!_文文学霸的博客-CSDN博客
节点分裂原理:

上述博客是我看到的最详细最易懂的博客
树类算法之--XGBoost算法原理&代码实战_小小的天和蜗牛的博客-CSDN博客
【DSW Gallery】 XGBoost:如何使用XGBoost解决回归问题-阿里云开发者社区
3.什么是线性回归?
线性回归模型的两种实现:
XGBoost线性回归工控数据分析实践案例(原生篇)_肖永威的博客-CSDN博客_xgboost 线性回归
XGBoost线性回归工控数据分析实践案例(Sklearn接口篇)_肖永威的博客-CSDN博客_xgboost 线性回归
xgboost回归预测模型_XGBoost模型(3)--球员身价预测_weixin_39628180的博客-CSDN博客
sklearn性能评估:
sklearn中的回归器性能评估方法 - nolonely - 博客园
评估回归模型的指标:MSE、RMSE、MAE、R2、偏差和方差_悦光阴的博客-CSDN博客
4.案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
#load_boston在1.2被移除
# 加载数据集,此数据集时做回归的
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X, y = data, target
# Xgboost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=22)
# 算法参数
params = {
'booster': 'gbtree',
'objective': 'reg:gamma',
'gamma': 0.01,
'max_depth': 6,
'silent': 1,
'lambda': 3,
'subsample': 0.8,
'colsample_bytree': 0.8,
'min_child_weight': 3,
'slient': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 800
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算mse
mse = mean_squared_error(y_true=y_test, y_pred=y_pred)
print('mse:', mse)
# 显示重要特征
plot_importance(model)
plt.show()
5.判断模型过拟合方法:绘制学习曲线
XGBoost学习曲线经典文章:
https://blog.csdn.net/together_cz/article/details/115325115
- 原生接口下的学习曲线绘制
- sklearn接口:曲线绘制
6.根据学习曲线调整XGBoost参数的具体方法:
通过学习曲线调整XGBoost性能_梯度下降法优化xgboost参数_Together_CZ的博客-CSDN博客
7.一个完整XGBoost机器学习案例
Xgboost实现UCI蘑菇数据集分类 - 飞桨AI Studio
8.XGBoost数据预处理
机器学习——XGboost进行分类预测,模型优化的实战_xgboost 数据预处理_熙熙丫的博客-CSDN博客
9.划分数据集以及数据的加载:
python机器学习 train_test_split()函数用法解析及示例 划分训练集和测试集 以鸢尾数据为例 入门级讲解_侯小啾的博客-CSDN博客_train_test_split
还有这篇文章,解析的很清楚:
总之,就是
dtrain = xgb.DMatrix(data,label)
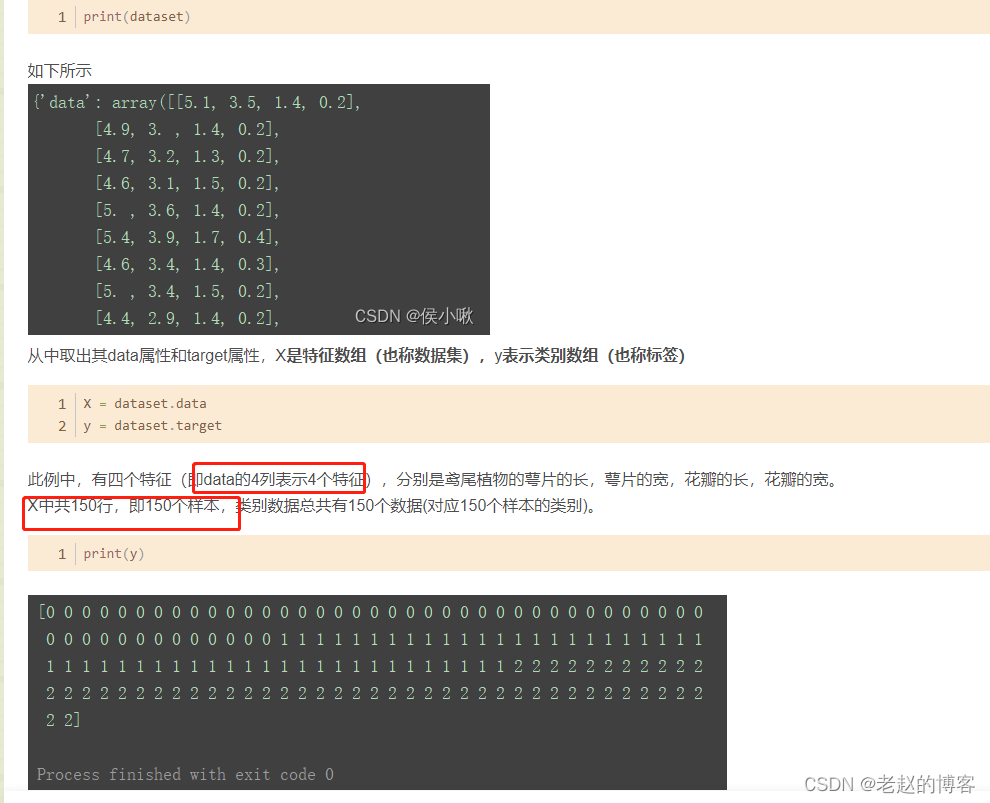
中的label,摘抄第一个链接为例:原始二维numpy数据,列表示有多少特征,行表示有多少样本
















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











