









David Silver《Reinforcement Learning》课程解读—— Lecture 5: Model-Free Control
上次课谈到了在给定policy的情况下求解未知environment的MDP问题,称之为Model-Free Prediction问题。本节则是解决未知policy情况下未知environment的MDP问题,也就是Model-Free Control问题,这个问题实际上是最常见的强化学习问题。由于这种问题中未知policy,那么就有两种思路来获得policy,一种称为on-policy learning是基于某个policy做出一些action然后评估这个policy效果如何,一种称为off-policy learning是从一些已知的policy中学习policy,比如机器人在学习走路时,可以从人控制机器人走路的sample中来学习,但不是完全的跟sample走的action完全一样,在sample中尝试去走不同的一步看是否有更好reward。
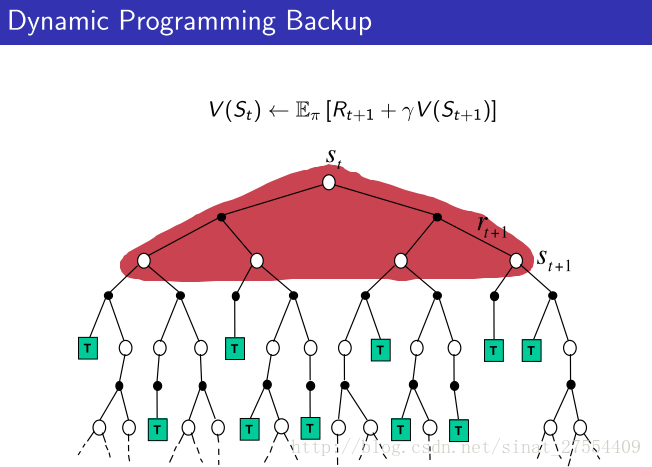
DP动态规划能够解决已知environment的MDP问题,即已知 S,A,P,R,γ ,根据是否已知policy又将问题划分为prediction和control的问题。本质上来说这种known MDP问题已知environment即转移矩阵与reward函数。
但是很多问题中environment未知,不清楚做出了某个action之后会变到哪个state,也不知道这个action好不好,即说不清environment体现的model是什么。
这种情况下需要解决的prediction和control问题即model-free prediction和model-free control。<该问题只能从与environment交互得到的experience中获取信息>
本节即针对未知environment的policy evaluation,在给定policy下,求取state的value function是多少?
episode:从某个状态开始执行到终止状态的一次遍历 S1,A1,R2,⋅⋅⋅,Sk 称为episode,已知很多episodes。
目录:
- Introduction
- On-Policy Monto-Carlo Control
- On-Policy Temporal-Difference
- Off-Policy Learning
- Summary
1. Introduction
- 分类
- Model-Free Prediction
estimate the value function of an unknown MDP,即已知policy求解未知environment的MDP问题。 - Model-Free Control
optimize the value function of an unknown MDP,即未知policy求解未知environment的MDP问题。
- Model-Free Prediction
- Model-Free Control中获取policy的2中思路:
- on-policy Learning:基于某个policy做出一些action然后评估其效果。
- off-policy Learning:从已知policy中学习新的policy
2. On-policy Monte-Carlo Control
组成 即一种新的策略迭代方法
policy evaluation + ϵ -Greedy Policy ImprovementGeneralised Policy Iteration
- Model-Free Policy Iteration with Monte-Carlo Evaluation
先通过贪婪算法来确定当前的policy,再通过蒙特卡洛policy evaluation来评估当前的policy好不好,再更新policy。
- Model-Free Policy Iteration using Action-Value Function
如果在已知environment情况下policy improvement更新方式是 π′=argmaxa∈ARas+Pass′V(s′) ,可以看出它的解决方案是通过状态转移矩阵把所有可能转移到的状态得到的值函数都计算出来,从中来选择最大的。但未知environment则没有状态转移矩阵,因此只能通过最大化动作值函数来更新policy即 π′(s)=argmaxa∈AQ(s,a) 。由于improvement的过程需要动作值函数,那么在policy evaluation的过程中针对给定的policy需要计算的 V(s) 也替换成 Q(s,a) 。
- Model-Free Policy Iteration with Monte-Carlo Evaluation
-
ϵ
-Greedy Exploration
常规策略迭代的改进算法,在上面greedy基础上有一定概率 ϵ 地选择一个随机action。假设有m个action,那么有 ϵ 的概率随机选择一个action(包括greedy action),从而可以得到更新的policy为:
12
由于每一步的reward都知道,则意味着每一步的returnGt 都可以计算出来。因此,通过反复测试,这样很多状态就会被遍历到,而且不止一次,那么每次就可以把在状态下的return求取平均值。当episode无限大时,得到的数据也就接近于真实的数据。Monte-Carlo方法就是使用统计学的方法来取代Bellman方法的计算方法。
- 有两种访问次数的记录方式,一种是在一个episode中只记录第一次访问到的s,一种是一个episode中每次访问到s都记录下来。
- First-Visit MC Policy Evaluation,每一次的episode中state只使用第一次到达的t来计算return
- Every-Visit MC Policy Evaluation,每一次的episode中state只要访问到就计算return求平均
特点:可以看到蒙特卡洛方法是极其简单的。但是缺点也是很明显的,需要尽可能多的反复测试,而且需要到每一次测试结束后才来计算,需要耗费大量时间。“AlphaGo就是使用蒙特卡洛的思想。不是蒙特卡洛树搜索,而是说在增强学习中使用蒙特卡洛方法的思想。AlphaGo每次也是到下棋结束,而且只使用最后的输赢作为return。所以这也是非常神奇的事,只使用最后的输赢结果,竟然能够优化每一步的走法。”
Incremental Monte-Carlo
Incremental Mean
序列 {x1,x2,⋅⋅⋅} 的均值 {u1,u2,⋅⋅⋅} 可以增量式增加
uk====1k∑j=1kxj1k⎛⎝xk+∑j=1k−1xj⎞⎠1k(xk+(k−1)uk−1)uk−1+1k(xk−uk−1)Incremental Monte-Carlo Updates
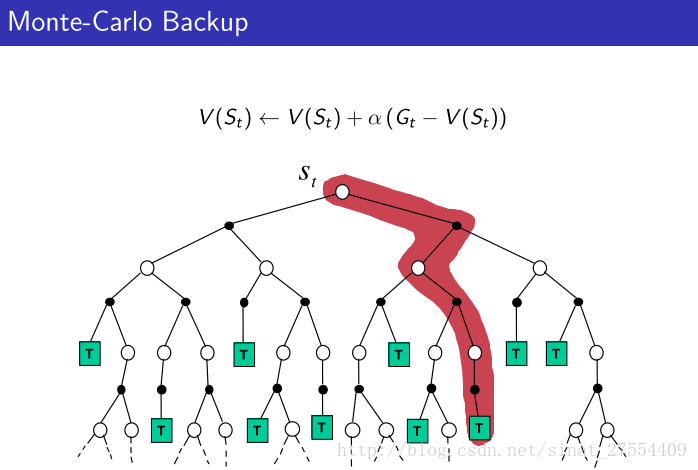
- Updates V(s) incrementally after episode S1,A1,R2,⋅⋅⋅,ST 。
- 针对每一次新的访问,先次数加1, N(St)=N(St)+1 ,然后更新 V(St)=V(St)+1N(St)(Gt−V(St))
- 在解非固定问题时,可以将 1N(St) 设置为一个常数 α ,即 V(St)=V(St)+α(Gt−V(St)) .
![这里写图片描述]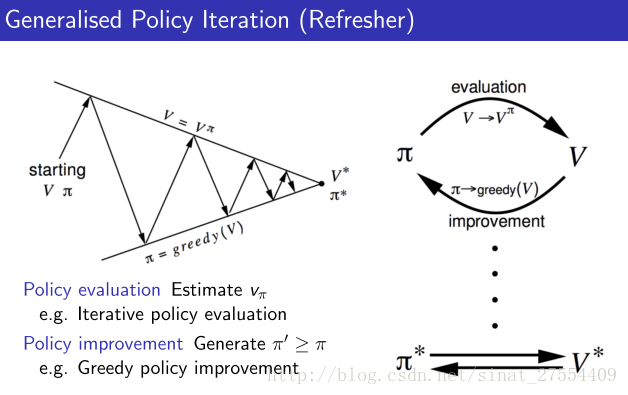
![这里写图片描述]![策略迭代方式]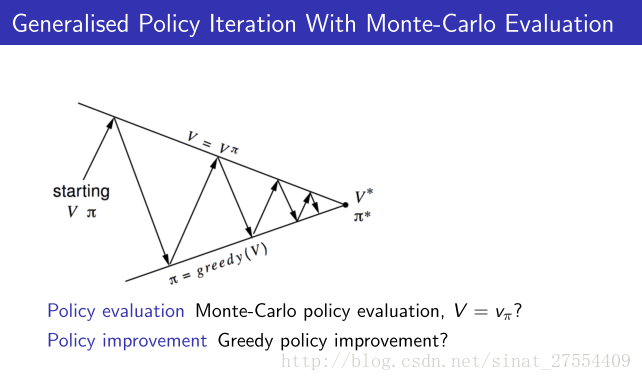
![这里写图片描述]![策略迭代方式]![这里写图片描述]
![这里写图片描述]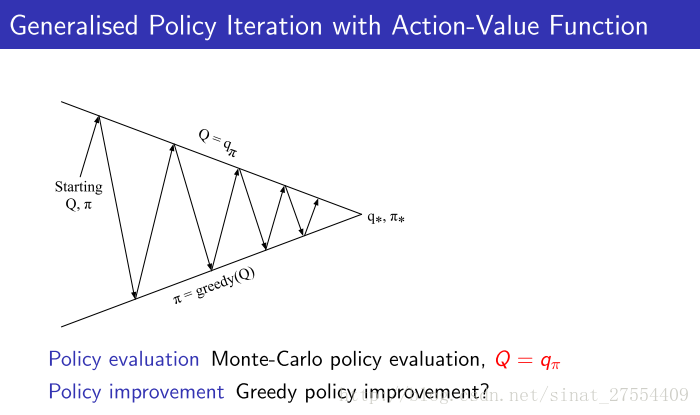


3. Temporal-Difference Learning
- 思想
基于Bootstrapping思想,即在中间状态中会估计当前获得的return值,并更新之前状态能获得的return,因此它不需要走完一个episode的全部流程。而前面分析的蒙特卡洛方法,其一个特点就是需要运行完整个episode从而获得准确的result。但是往往很多场景下要运行完整个episode是很费时间的 - 特点
- 直接从experience的episode中学习
- 不需要MDP的transitions、rewards
- 通过bootstrapping从不完整的episode中学习
bootstraping。即通过估计的方法来引导计算。那么蒙特卡罗不使用bootstraping,而TD使用bootstraping。 - 每一步都可以更新,这是显然,也就是online learning,学习快
- 从一个猜测更新到另一个猜测
- 可以面对没有结果的场景,应用范围广
- TD vs MC
- 目标:learn vπ online from experience under policy π .
- Incremental every-visit Monte-Carlo
根据真实的 reward Gt 更新 V(St) :
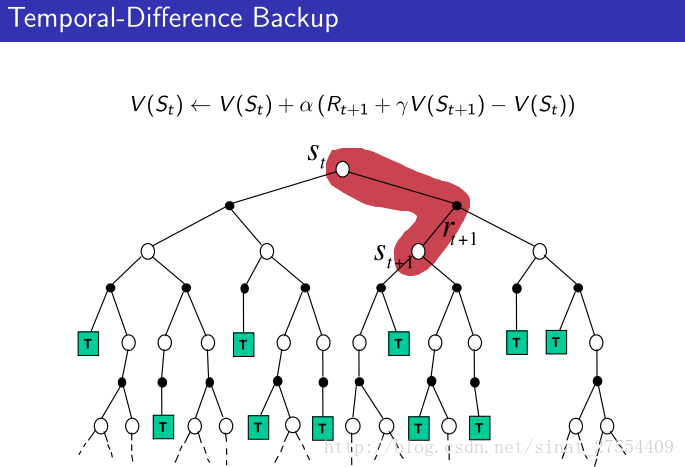
V(St)=V(St)+α(Gt−V(St)) - Simplest temporal-difference learning algorithm: TD(0)
根据估计的return更新 V(st) , 估计return: Rt+1+γV(St+1) :
V(St)=V(St)+α(Rt+1+γV(St+1)−V(St))
其中, Rt+1+γV(St+1) 是 TD target,
δt=Rt+1+γV(St+1)−V(St) 是 TD error, 代表了估计前后return的差值 - 平衡Bias/Variance是机器学习比较经典的一个问题,bias是指预测结果与真实结果的差值,variance是指训练集每次预测结果之间的差值,bias过大会导致欠拟合它衡量了模型是否准确,variance过大会导致过拟合衡量了模型是否稳定。
- TD算法的相对缺点:因为TD target是估计值,估计是有误差的,这就会导致更新得到value是有偏差的。很难做到无偏估计。
- TD算法的相对优点:TD target 是每一个 step 进行估计的,仅最近的动作对其有影响,而 MC 的 result 则受到整个时间片中动作的影响,因此 TD target 的方差 variance 会比较低,也就是波动性小。
- 具体对比如下图所示:
- 在David Silver的课件中,有三张图,很直观地对比了MC,TD以及DP的不同:
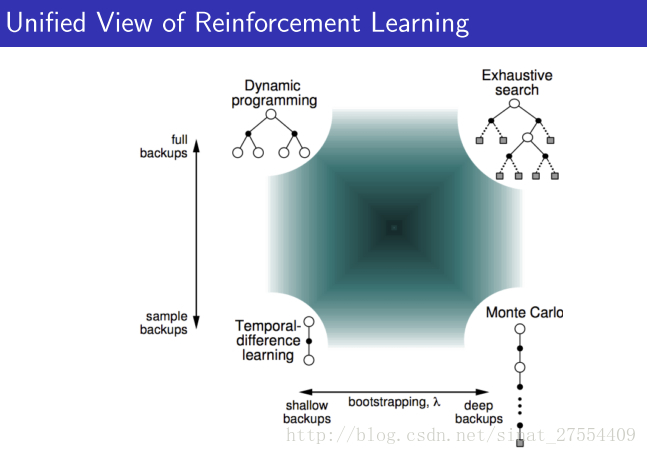
从上面可以很清楚的看到三者的不同。DP就是理想化的情况,遍历所有。MC现实一点,TD最现实,但是TD也最不准确。但是没关系,反复迭代之下,还是可以收敛的。 - 整个增强学习算法也都在上面的范畴里:
- 上面的图是用Policy Evaluation解决强化学习问题的一些算法的区别与相关性,最左边的竖线表示如果考虑了所有的可能发生的情况那么就是动态规划,如果只考虑了部分采样那么就是时序差分。下面的横线表示如果考虑了一次episode中全部的动作就是Monte-Carlo,如果只考虑部分动作就是时序差分。如果又考虑全部情况又考虑每一种情况的全部动作就是穷举。

4. TD (λ)
- 思想
-
TD(0)
: 在某个状态
S
下执行某个动作后转移到下一个状态
S′ 时,估计 S′ 的return再更新S。 - 若
S
之后执行2次动作转移到
S′′ 时再返回来更新 S 的值函数,那么就是另外一种形式,从而根据step的长度n可以扩展TD到不同形式,当step的长度达到episode的终点时就变成了MC,从而得到统一公式如下:
Gn=Rt+1+γRt+2+⋅⋅⋅+γn−1Rt+n+rnV(St+n)
-
TD(0)
: 在某个状态
S
下执行某个动作后转移到下一个状态
-
-
TD(λ)
: 若将不同的n对应的return平均一下,就能获得更加鲁邦的结果,而为了有效地将不同return结合起来,对每个return都赋予了一个权重
1−λ,(1−λ)lambda,⋅⋅⋅,(1−λ)λn
,参数是
lambda
,这样又可以得到一组更新value function公式:
Gλt=(1−λ)∑n=1∞λn−1Gnt
-
TD(λ)
: 若将不同的n对应的return平均一下,就能获得更加鲁邦的结果,而为了有效地将不同return结合起来,对每个return都赋予了一个权重
1−λ,(1−λ)lambda,⋅⋅⋅,(1−λ)λn
,参数是
lambda
,这样又可以得到一组更新value function公式:















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









