







 文章探讨了DDPM生成图像的原理,提出DDIM方法通过减少推理次数,显著提高采样效率,同时保持生成质量。DDIM利用非马尔可夫过程,保持训练目标不变。实验显示DDIM在速度上比传统DDPM快10到50倍,且生成过程具备确定性,适合图像插值应用。
文章探讨了DDPM生成图像的原理,提出DDIM方法通过减少推理次数,显著提高采样效率,同时保持生成质量。DDIM利用非马尔可夫过程,保持训练目标不变。实验显示DDIM在速度上比传统DDPM快10到50倍,且生成过程具备确定性,适合图像插值应用。
1、目的
DDPM生成图像需要模拟Markov链,因此要经过多轮推理(因为条件概率仅仅与系统的当前状态相关),且推理过程是sequentially而不是parallel的
DDIM在不改变DDPM训练的基础上,减少了infer次数,在极大地增加了采样效率的同时,几乎不影响采样效果
2、方法
1)DDPM的一个重要特性是
![]()
![]()
因此目标函数为
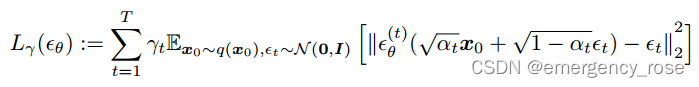
该目标函数只用到,无须
。因此可以选用一些non-Markovian过程,只要符合该边际分布即可。此时,训练objective不变,因此训练过程不变
DDIM选用的non-Markovian分布下,inference过程为
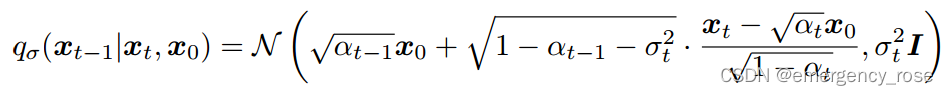 ...... (1)
...... (1)
相应的forward过程可以表示为(但其实我们不需要前传的公式了):
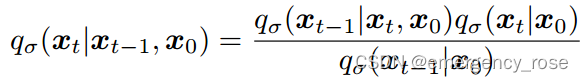
2)具体应用时,给定noisy ,先预测
,
![]() ...... (2)
...... (2)
然后再结合公式1和公式2求解
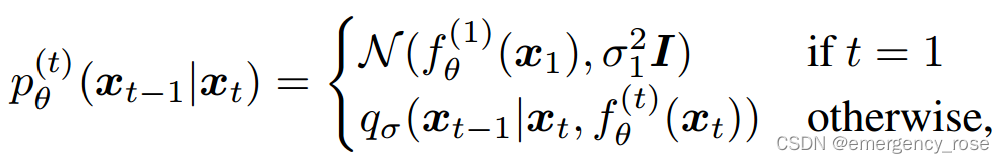
即
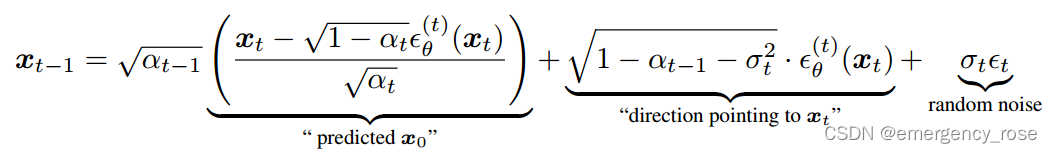
其中,
![]()
当时,是DDPM;当
时,是DDIM (denoising diffusion implicit model)
3)可以假定forward过程不定义在上,而是递增子集{
},并且符合如下边际分布
![]()
![]()
当这个(sampling) trajectory的长度远小于T时,就可以大大提升计算效率
3、效果
1)10 ~ 50X faster

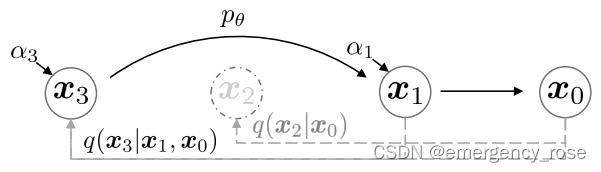
2)生成过程是deterministic的,一旦确定了输入,则输出也是确定的。因此可以进行图像插值


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









