







这篇讲解很详细,可以参考:https://zhuanlan.zhihu.com/p/634573765
附上苏神的讲解:生成扩散模型漫谈(二十二):信噪比与大图生成(上) - 科学空间|Scientific Spaces
其中,autoencoder的学习可以参考:https://juejin.cn/post/7238769796351639612
1、目的
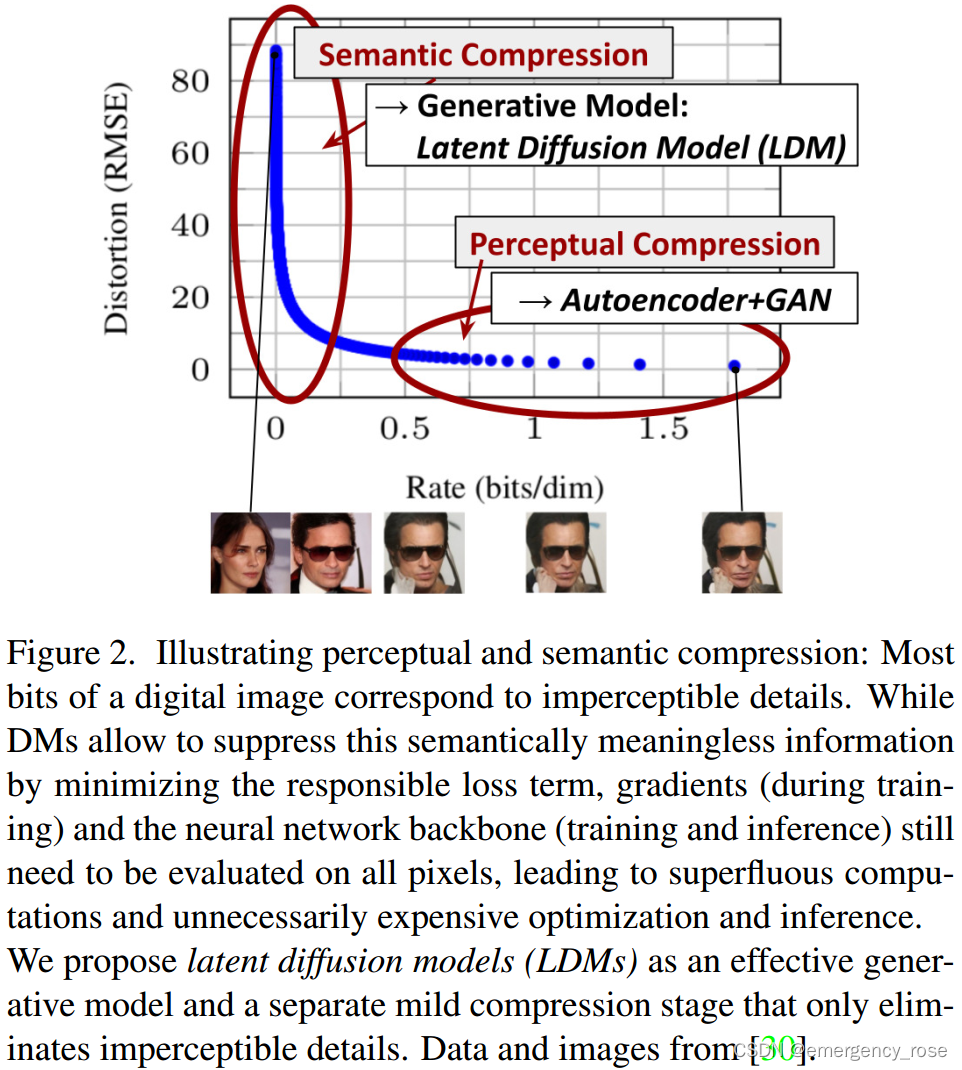
DM的train和infer均需大量的时间和显存
2、方法
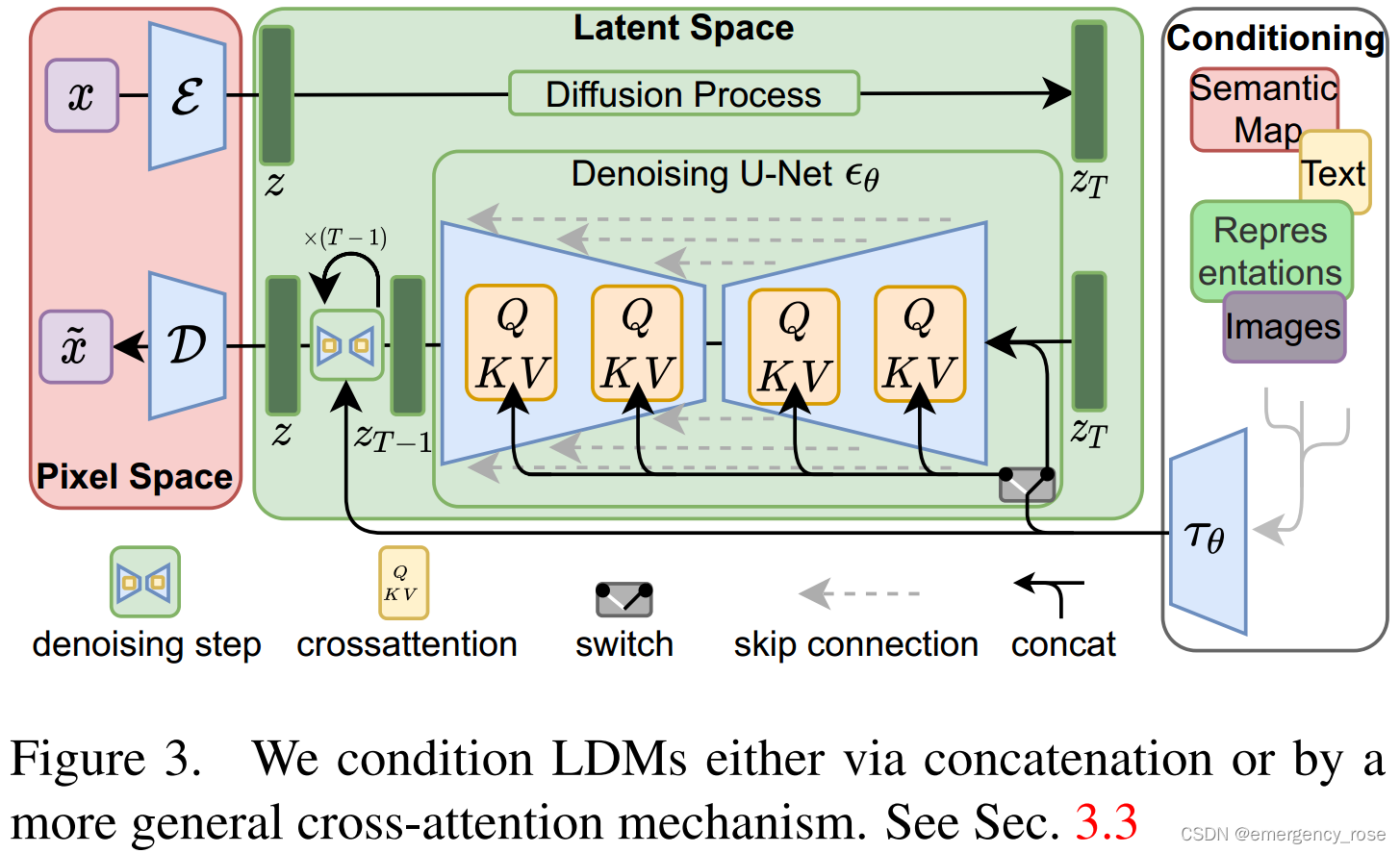
1)autoencoder
-> 将数据映射到感知上等效的、低维度的表示空间
-> 只需训练一次,就可以被应用到多个DM训练过程中,也可以用于其他下游任务 (如single-image CLIP-guided synthesis)
-> 压缩程度可选
-> perceptual loss + patch-based adversarial objective
-> encoder ,
-> decoder D,
-> ,
,下采样
。LDM-1对应着pixel-based DM,LDM-4和-8最优
-> 为了避免潜空间的方差过高,可以采用两种正则化:KL-reg和VQ-reg
2)在潜空间上训练DM,即Latent Diffusion Models (LDMs)
-> ![]()
-> :time-conditional UNet
3)cross-attention
-> 用于多模态条件输入
-> : domain specific encoder,将y映射为中间表示
-> ![]()
![]()
![]() 为UNet应用
为UNet应用后(flattened) intermediate representation
![]()
![]() 均为learnable映射矩阵
均为learnable映射矩阵
-> ![]() ,同步优化
,同步优化和
,其中
可以根据domain-specific experts来参数化
3、应用
convolutional fashion,~px
1)unconditional
2)conditional (text,bounding boxes,high-resolution synthesis,...)
-> inpainting
-> stochastic super-resolution
-> semantic synthesis
-> class-conditional
-> text-to-image
-> layout-to-image















 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









