







 TableBank是一个基于Word和Latex文档的大型表格检测和识别数据集,通过弱监督方法创建,包含471K高质量标注表格。研究发现,基于深度学习的模型在不同领域泛化能力有限,强调了扩大训练数据集的重要性。TableBank开源并提供了基线模型,有望推动表格分析技术的发展。
TableBank是一个基于Word和Latex文档的大型表格检测和识别数据集,通过弱监督方法创建,包含471K高质量标注表格。研究发现,基于深度学习的模型在不同领域泛化能力有限,强调了扩大训练数据集的重要性。TableBank开源并提供了基线模型,有望推动表格分析技术的发展。
文章目录
【参考文献】: 1. TableBank: Table Benchmark for Image-based Table Detection and Recognition
我们提出TableBank:一个新的使用新颖弱监督从互联网中Word和Latex文档中创建的、基于图像的表格识别和检测的数据集。目前基于图像的表格检测和识别的研究通常是使用几千条人工标注的样本在其他领域预训练的模型上微调,这难以泛化实际应用。
利用包含471K条高质量标注表格的TableBank数据集,我们使用DNN创建几种SOTA基线模型。我们开源TableBank,并希望它能够使更多的机器学习方法应用于表格检测和识别任务。
数据集和模型可从Github获取:https://github.com/doc-analysis/TableBank。
关键词: TableBank,表格检测和识别,弱监督,基于图像的深度学习网络
1 引言
由于表格经常以结构化的方式呈现重要信息,因此在许多文档分析应用中表格识别和检测任务是一个重要任务。由于表格板式多样,这是一个很困难的问题,如图1所示。

在对文档板式分析的基础上,提出了传统的表格分析技术。大多数技术依赖于手工特征,对版式变化鲁棒性低,难以泛化。近些年,深度学习在计算机视觉的快速发展显著促进了数据驱动的基于图像的表格分析方法。
基于图像的表格分析优势在于,它对表格类型具有鲁棒性,并不要求格式是页面扫描图像还是纯数字文档。它可用于多数文档类型,包括PDF、HTML、PowerPoint及其扫描复印件。尽管一些类型的文档包含结构化的表格数据,我们仍需要一种通用的方法在不同类型文档中检测表格。因此,使用大规模端到端深度学习模型获取更好性能成为可能。
目前基于深度学习的表格分析模型通常是使用几千条人工标注的训练样本在预训练目标检测模型上微调,在现实应用中难以扩展。例如,我们发现,在与图1a 1b 1c相似的数据上训练的模型,在图1d数据上表现不好,因为表格版式和颜色十分不同。因此,扩大训练集应该是使用深度学习构建开放领域表格分析模型的唯一方法。
深度学习模型比大多数传统模型复杂的多,许多标准的深度学习模型具有数十亿参数,这要求相当多的训练数据。在实践中,手工标注这种训练集的花费或不灵活性是实际部署深度学习模型的关键瓶颈。
众所周知,两个流行的图像分类和目标检测数据集ImageNet和COCO以众包方式创建,因为创建这种数据集昂贵且耗时,大型基准数据集需要花费数月或数年。幸运的是,互联网中存在大量的Word和Latex源文档,如果能够对这些在线文档应用一些弱监督来标注表格将很有帮助。
为解决对标准开源表格基准数据集的需求,我们提出一种新的弱监督方法用于自动创建TableBank,它比目前人工标注的表格分析数据集大几个数量级。与传统弱监督训练集不同的是,我们的方法获取的训练集不仅规模大而且质量高。
现在,网络中有大量如微软Word (.docx)和Latex (.tex)类型的电子文档。这些互联网文档中的表格在它们源码中具有天然的装饰标签。直觉上,我们可以使用每个文档的修饰语言操作这些源码,向其中加入一些边界框。
对于Word文档,可以修改内部Office XML代码,代码已经指定每个表格的边界线;对于Latex文档,可以修改tex代码,代码已经识别表格的边界框。以这种方式可以创建多种领域的高质量的标注数据,如商业文档、官方文件、研究论文等,这对大规模表格分析任务十分有益。
TableBank数据集共包含多领域的417,234张高质量的标注表格以及它们的原始文档。为验证TableBank数据集的有效性,我们使用SOTA模型和端到端网络创建了几种强大的基线模型,表格检测使用基于不同配置的Faster R-CNN的架构,表格结构识别模型基于image-to-text的编码器-解码器架构。
实验结果显示,版式多样对表格分析任务的准确率具有负面影响,此外,特定领域内训练的模型,在其它领域表现不好。这表明,在TableBank数据集上的建模和学习具有很大改进空间。
2 现有数据集
我们介绍一些现有的公共可用数据集作为基线进行比较:
- ICDAR 2013 Table Competition. 包含纯数字文档中的128个样本,来源于欧盟和美国政府。
- UNLV Table Dataset. 包含扫描图片中的427个样本,来源于多个源如杂志、报纸、商业信函和年报等。
- Marmot Dataset. 包含PDF文档中的2,000页,大多数样本来自于论文。
- DeepFigures Dataset. 包含来自于arXiv.com和PubMed数据库的含有表格和图表的文档,关注于大规模表格和图表检测任务,并不包含表格结构识别数据集(单元格无法区分)。
3 数据收集
基本上,我们使用两种文件类型创建TableBank数据集:Word文档和Latex文档,这两种文件的源码中对表格具有自然的标记。接下来,我们用三步进行详细介绍:获取文档、创建表格检测数据集和表格结构识别数据集。
3.1 获取文档
我们从互联网上爬取Word文档,所有文档的格式是“.docx”,因此我们可以编辑内部Office XML源码,向其加入边界框。由于我们并未过滤文档语言,Word文档包含英文、中文、日文、阿拉伯文和其它语言,这使得数据集在真实应用中更具多样性和鲁棒性。
Latex文档与Word文档不同,因为它们需要将其它源编译进PDF文档,因此,我们不能仅从网络中爬取“.tex”文档。相反,我们使用最大预打印数据库arXiv.org中的文档及源码,我们通过批量数据访问下载2014至2018年arXiv中的Latex源码。Latex文档的主要语言是英语。
3.2 表格检测
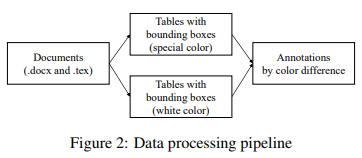
直觉上,我们可以在每个文档中使用相应的标记语言操作源码,向其中加入边界框。处理流水线如图2所示。
对于Word文档,通过编辑每个文档内部Office XML源码加入表格边界框,事实上,每个“.docx“文档是一个压缩文件,在”.docx“文件的压缩目录下包含一个”document.xml“文件。在XML文件中,Word文档表示表格的代码段通常位于’<w:tbl>'和</w:tbl>'之间,如图3所示。
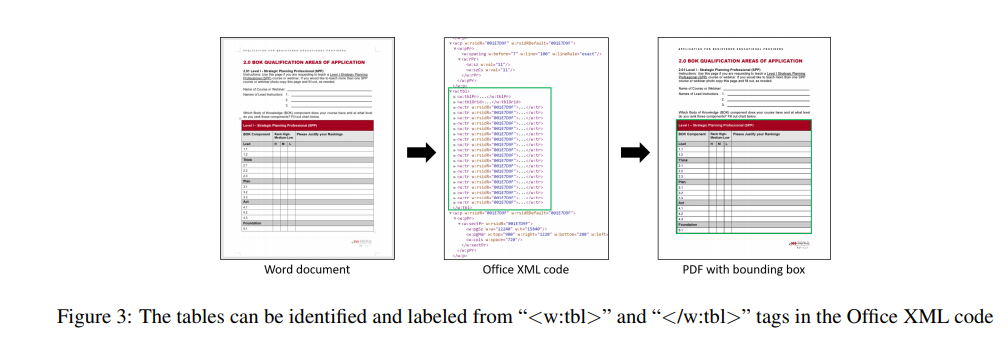
我们修改XML文件的代码,使表格边界的颜色比文档其它部分更具区分性。图3显示我们向PDF中的表格加入了绿色边界框,表格能够完全识别。最后,我们从Word文档中获取每页至少包含一张表格的PDF页。
对于Latex文档,我们在Tex语法’fcolorbox’中使用特殊命令,加入表格边界框。典型地,Latex文档中的表格通常具有以下形式:
\begin{table}[]
\centering
\begin{tabular}{}
....
\end{tabular}
\end{table}
我们向表格源码中插入如下’fcolorbox’命令,并重新编译Latex文档。同时,我们同样对边界定义一个具有区分性的特殊的颜色。整个过程与Word文档相似。最后,我们从Latex文档中获取每页至少包含一张表格的PDF页。
\begin{table}[]
\centering
\setlength{\fboxsep}{1pt}
\fcolorbox{bordercolor}{white}{
\begin{tabular}{}
....
\end{tabular}}
\end{table}
为获得真实标签,我们从生成的PDF文档抽取注释。对于每个注释的PDF文档,我们同样在原页面加入白色的表格边界框,使两页面在相同位置对齐。然后,我们在像素级别简单地比较两个页面,从而发现不同像素,获得表格的左上界以及宽高度参数。
以这种方式,我们共从爬取的文档中获取471,264张标注的表格,从数据集中我们随机采样1000张表格人为检查表格边界框,我们发现其中仅5张表格标注错误,证明我们数据集的高质量。图4中给出了弱监督典型的标注错误。

3.3 表格结构识别
表格结构识别的目的在于识别表格的行、列布局结构,尤其是非数字文档如扫描图片。现有表格结构识别模型通常识别版式信息以及单元格文本内容,而文本内容识别非本文重点。
因此,我们定义任务如下:给定图片格式的表格,生成表示行列布局的HTML标签序列以及表格单元格类型。以这种方式,我们可以从Word和Latex源码中自动地创建结构识别数据集。
对于Word文档,我们简单地转换文档原始XML信息为HTML标签序列;对于Latex文档,我们首先利用LatexXML工具包从Latex中生成XML,然后转换XML为HTML。图5为简单示例,其中我们使用’<cell_y>’表示有内容的单元格、’<cell_n>’表示没有内容的单元格。在过滤噪声后,我们从Word和Latex文档中创建145,463个训练样本。
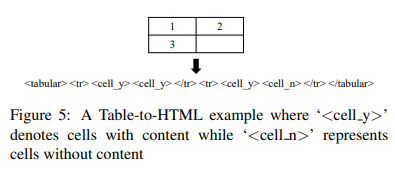
在推理过程中,我们从表格结构识别结果中获取行列结构,以及从OCR结果中获取紧密排列文本块的内容和边界框。假定表格包含N行,利用启发式算法检测OCR边界框之间的行间隙,从而将表格内容块分为N组。最后,我们以从左到右的顺序用N行‘<cell_y>’标签填充这些块。
例如图5中,根据表格结构识别结果表格包含两行,例如HTML标签序列。根据”1“和”3“文本块之间的间隙,我们将其分为两组:<1,2>和<3>,第一组与包含两个’<cell_y>’标签的第一行有关,第二组与包含一个’<cell_n>’标签的第二行有关。
4 基线
4.1 表格检测
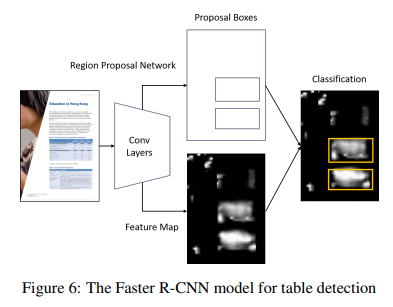
我们使用Faster R-CNN作为基线。由于ImageNet和COCO竞赛的成功,Fatser R-CNN模型已经在计算机视觉领域广泛应用。2003年,RCNN模型首次提出用于解决目标检测问题。之后在2015年,Fast R-CNN模型提升了训练和测试速度以及增加了检测正确率。
两种模型都是使用选择性搜索找到候选区域,而选择性搜索是一种缓慢、耗时的过程,影响网络性能。不同于先前两种方法,Fatser R-CNN模型引入区域候选网络(Region Proposal Network,RPN),与检测网络共享图片卷积特征,因此使得区域候选近乎没有开销。而且,模型将RPN和Fast R-CNN通过共享卷积特征合并为单一网络,使得网络能以端到端方式训练。完整的Fatser R-CNN架构见图6。
4.2 表格结构识别
我们利用image-to-text模型作为基线。Image-to-text模型广泛应用于图片说明、视频描述及许多其它领域应用。典型的image-to-text模型包括以图片作为输入的编码器和以文本作为输出的解码器。本文中,我们使用image-to-markup模型作为基线在TableBank数据集上训练模型。
Image-to-text模型的整体框架如图7所示。
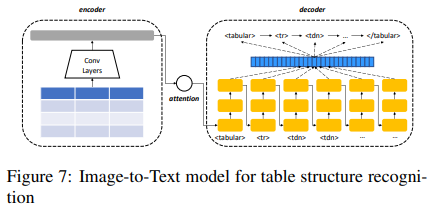
5 实验
5.1 数据和评价指标
表1为TableBank的统计信息。
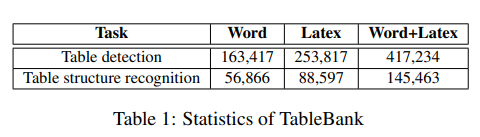
为评估表格检测,我们从Word和Latex文档中各自采样2,000张文档图片,其中1,000张图片用于训练、1,000张图片用于测试。每张采样图片至少包含一张表格。这意味着,我们可以在ICDAR 2013数据集评估我们的模型,验证TableBank的有效性。
为评估表格结构识别,我们从Word和Latex文档中各自采样500张图片用于验证和测试。用于表格检测和表格结构识别的训练集大小各自是415,234和144,463。整个训练集和测试集已开源。
对于表格检测,我们以与 (Gilani et al., 2017)相同的方式评估精度、召回和F1,这里所有文档评价指标的计算是对重叠区域、预测和真值求和。
定义如下:

对于表格结构识别,我们使用4-gram BLEU分数作为单个推理的评估指标,4-gram具有计算速度快、代价低和容易理解的优点。
5.2 设置
对于表格检测,我们使用开源框架Detectron在TableBank上训练模型。Detectron对于目标检测研究具有高质量、高性能的代码库,支持许多SOTA算法,它由Python编写,并由Caffe2深度学习框架提供支持。在这个任务中,我们使用Faster R-CNN算法和ResNeXt作为网络骨架,其参数已在ImageNet数据集上预训练。
使用4块NVIDIA P100 GPUs训练所有基线方法,使用数据并行同步SGD优化算法,batch size为16。对于其它参数,我们使用Detectron中的默认值。在测试时,设定生成边界框的置信度为90%。
对于表格结构识别,我们使用开源框架OpenNMT训练image-to-text模型。OpenNMT是用于神经网络机器翻译和神经网络序列学习的开源生态系统,其支持许多encoder-decoder框架。
本任务中,我们在OpenNMT中使用image-to-text的方式训练我们的模型,模型同样使用4块NVIDIA P100 GPUs训练,其中学习率为0.1、batch size为24。本任务中,输出空间的词典大小很小,仅包含:<tabular>, </tabular>, <thead>, </thead>, <tbody>, </tbody>, <tr>, </tr>, <td>, </td>, <cell_y>, <cell_n>。对于其它参数,我们使用OpenNMT中的默认值。
5.3 结果
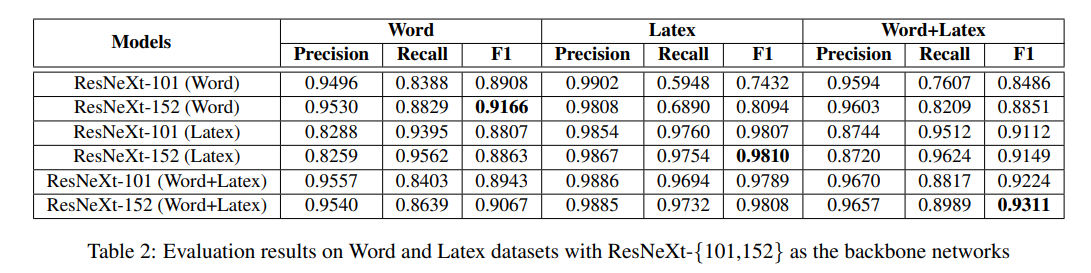
表2为表格检测模型的评估结果。我们观察到模型在相同领域表现好,例如,在Word文档上训练的ResNeXt-152模型,在Word文档中获得的F1分数为0.9166,高出在Latex文档的F1分数0.8094许多。同样地,在Latex文档上训练的ResNeXt-152模型,在Latex数据集上的F1分数为0.9810,高于在Word测试数据集上获得的F1分数0.8863。
这意味着,不同类型文档中的表格具有不同的外观。因此,我们不能仅依赖于迁移学习技术使用小规模的训练数据来获得好的目标检测模型。
当将Word和Latex结合作为训练数据时,大模型的准确率与在相同领域训练的模型相当,但在Word+Latex数据集上表现更好,证明在大数据量下训练的模型在不同领域具有更好的泛化,阐明创建大基准数据集的重要性。
此外,我们同样在ICDAR 2013表格竞赛数据集评估我们的模型,结果如表3所示。
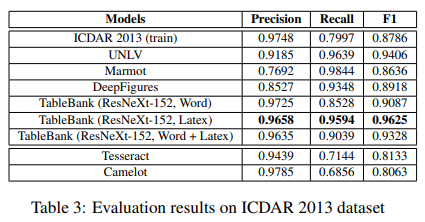
对于所有在TableBank上训练的模型,Latex ResNeXt152模型获得最好的F1分数0.9625。进一步,我们将我们的模型与在ICDAR、UNLV、Marmot和DeepFigures上训练的模型比较,验证了我们TableBank数据集的巨大潜能。
这也阐明了我们不仅需要大规模的训练数据,同样需要高质量的数据。我们同样与Tesseract3、Camelot4开源工具包(基于线信息)比较,结果显示,基于图像的深度学习模型显著好于传统方法。
表4为表格结果识别的验证结果。
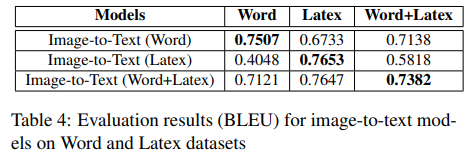
我们观察到,image-to-text模型在相同领域同样表现很好。在Word文档上训练的模型,在Word测试集上的性能优于在Latex测试集,反之亦然。相似地,Word+Latex模型的准确率与各自在Word和Latex上训练的其它模型相当,但在混合领域性能更好。这说明,混合领域模型在真实应用中可能泛化性更好。
5.4 分析
对于表格检测,我们从Word和Latex文档的评估数据中采样一些错误样本用于个案研究。图8给出了三种典型的检测结果错误。

第一种错误类型是partial-detection,仅识别表的一部分,其它信息丢失。第二种错误类型是un-detection,文档中的一些表无法识别。第三种错误类型是mis-detection,文档中的图片和文本块被识别为表格。
以Word+Latex ResNeXt-152模型作为例子,第二类型错误有164个,与2,525个正确标注相比,错误率为6.5%。同时,第三类型错误有86个,与总计2,450个预测表格相比,错误率为3.5%。最后,第一类型错误为57个,部分检测率为2.3%。这说明检测模型仍有很大的提升空间,尤其是第二、三类型错误。
我们发现在交叉领域测试时,一些实验结果准确率很低。在Latex模型上测试Word和Word+Latex模型不能令人满意。同时,Word模型在所有测试集上的召回率都很低,混合模型在Word和Word+Latex数据集上的召回率较差。这说明,TableBank数据集有很大提升空间。尤其是研究一些在交叉领域下表现质量差的个例。
对于表格结构识别,我们观察到模型准确率随着模型输出长度的增加而下降。以Word+Latex image-to-text模型作为例子,模型输出与正确标注准确匹配的数量如表5所示。
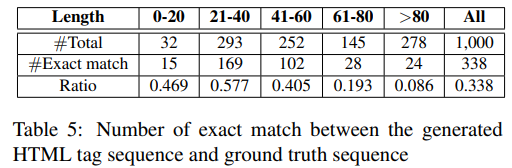
我们可以发现,当输出HTML序列的长度小于40时,准确匹配率约50%。随着输出token数量的增加,准确匹配率下降至8.6%,这暗示着识别大的复杂表很困难。总之,模型对338张表有正确输出。
为避免训练数据长度偏差的影响,我们计算了训练数据的长度分布,见表6。
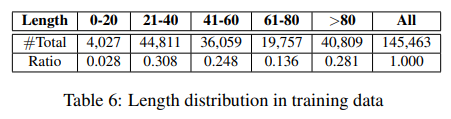
我们相信增加训练数据将促进提升当前模型,尤其对于具有复杂行列布局的表,这是我们下一步努力的方向。
6 相关工作
6.1 表格检测
表格检测旨在用边界框定位文档中的表格。表格检测的研究可以追溯至1990s早期。Itonori在1993年提出一种基于规则的方法,利用文本块布局和控制线位置检测表格结构。在当时,Chandran和Kasturi基于水平、垂直线以及元素块设计了一种表格结构检测方法。
在这些工作之后,有大量的研究工作关注于提升基于规则的方法。尽管这些方法在一些文档中表现良好,当有时候在其他源中的文档泛化失败时,它们需要大量人力**想出 (figure out) **更好的规则。因此,在表格检测中利用统计学方法称为必然趋势。
为解决泛化需求,提出统计机器学习方法缓解这些问题。早在1998年,首次提出一种无监督学习方法用于表格检测任务。他们的识别过程与先前方法差异很大,它对给定的单词段自底向上聚类,而传统的表格结构识别器完全依赖于检测一些分隔符,如轮廓或有意义的白空格,从上至下分析页面。
2002年,开始利用基于MXY树的分层表示的监督学习方法。该算法通过最大化训练集性能,来适用于识别不同特征的表。之后,一系列不同的机器学习开始应用于表格检测任务,如序列标注、基于SVM的特征工程、以及模型集成如朴素贝叶斯、逻辑回归和SVM。应用机器学习方法显著提升了表格检测的正确率。
最近,计算机视觉领域深度学习的快速发展,对基于图像的数据驱动的表格检测影响深远。基于图像的表格检测有两点优势:首先,由于未对格式是页面扫描图片还是纯数字文档做限制,对表格类型具有鲁棒性;其次,它降低了传统机器学习中的手工特征。
2016年首次使用CNN用于表格检测,利用一些宽限的规则选择一些类似表格区域,然后创建调整、精调卷积网络判定选择区域是否是表格。此外,Faster R-CNN模型也用于表格检测。
2017提出一种完全基于数据驱动的系统,不需要任何启发及检测元数据,在ICDAR 2013数据集上识别表格结构。与此同时,Faster R-CNN斩获UNLV数据集SOTA。
尽管这些深度学习模型取得了成功,这些模型中的大多数是使用几千条人工标注的样本在领域外预训练的模型进行微调,在真实应用中实践起来仍然困难。
直到现在,仍没有任何同时用于表格检测和结构识别的标准的基准数据集,因此我们创建了开源TableBank数据集,希望它能够发挥深度学习方法的更多力量。
6.2 表格结构识别
表格检测旨在学习一张表格的行列布局信息。表格结构识别的研究包括基于规则的方法、机器学习方法和深度学习方法。
2003年,Ramel等人开发了一种使用图表线检测和提取表格的方法。之后,2005年,Yildiz等人使用”pdftohtml“工具召回PDF文件中的所有文本元素,并通过计算文本的水平重叠度识别列。2007年,Hassan和Baumgartner根据表格是否具有水平和垂直控制线,将表格分为三组,然后他们开发了启发式算法检测这些表格。不向其它为特定表设计规则的方法,Shigarov在2016年提出一种更通用的基于规则的方法应用于多个领域。
对于基于机器学习的方法,Hu等人在2000年通过层次聚类,然后利用空间和语义准则分类表头,同时通过设计一种新的范式”random graph probing“也解决评估问题。
最近,Schreiber在2017年使用基于深度学习的目标检测方法,并结合预处理,识别ICDAR 2013数据集的行列结构。类似地,对于这个任务,现有方法通常不使用任何训练数据,或仅有小规模训练数据。
与现有研究的区别在于,我们使用TableBank数据集验证数据驱动的端到端结构识别模型。据我们所知,TableBank数据集是第一个同时应用与表格检测和识别任务的大规模数据集。
7 结论
为促进文档分析中表格检测和结构识别的研究,我们提出TabelBank数据集,它是一种由互联网Word和Latex文档创建的、新的基于图像的表格分析数据集。
我们使用Faster R-CNN模型和image-to-text模型作为评估TableBank性能的基线模型,此外,我们也各自从Word和Latex文档中创建测试集,使得模型可在不同领域评估。
实验表明,基于图像的表格检测和识别深度学习是有前景的方向。我们希望TableBank数据集能够释放深度学习在表格分析任务中的力量,同时希望,能够创建更多的自定义网络结构在该任务上取得实质进展。
在未来研究中,我们将用更多领域内高质量的数据扩增TableBank数据集,而且,我们计划创建一个多标签数据集,如表格、图表、标题、子标题、文本块等。以这种方式,可能获取细粒度模型,能区分文件的不同部分。

















 5541
5541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









