







目录
组学数据(aspera/pdc-client/gdc-cilent)
1. Aspera
Aspera是一种高速数据传输技术,其工作原理可以简单地描述为:将文件分割成多个小块,同时在网络上建立多个连接,利用多线程并发传输每个小块,然后在接收端重新组合成完整的文件。
1)安装
# 使用conda安装
conda install -c hcc aspera-cli
# 测试是否安装成功
ascp -h
2)蛋白组学
用例1. 从iprox下载蛋白组
ascp -d -v -QT -l100m -P 33001 --file-manifest=text -k 2 -o Overwrite=diff user@download.iprox.org:/pid /path
# user替换成自己注册的账户名
# pid替换成下载的项目
# path替换成本地存放路径
-d:如果目标文件夹不存在,则自动创建。
-T:禁用加密以获得最大传输通量。
-q:静音模式(禁用进度显示)。
-v:详细模式(在日志文件中打印连接和身份验证调试信息)。
-l max_rate:设置目标传输速率(默认值:10000 Kbps)。
用例2. 从PX下载蛋白组
ascp -TQ -P33001 -l 100M -i /path/miniconda3/etc/asperaweb_id_dsa.openssh prd_ascp@fasp.ebi.ac.uk:/pride/data/archive/yy/mm/pid /path
用例3. 从SRA下载转录组
(1)借助 SRA Explorer 获取下载网址。
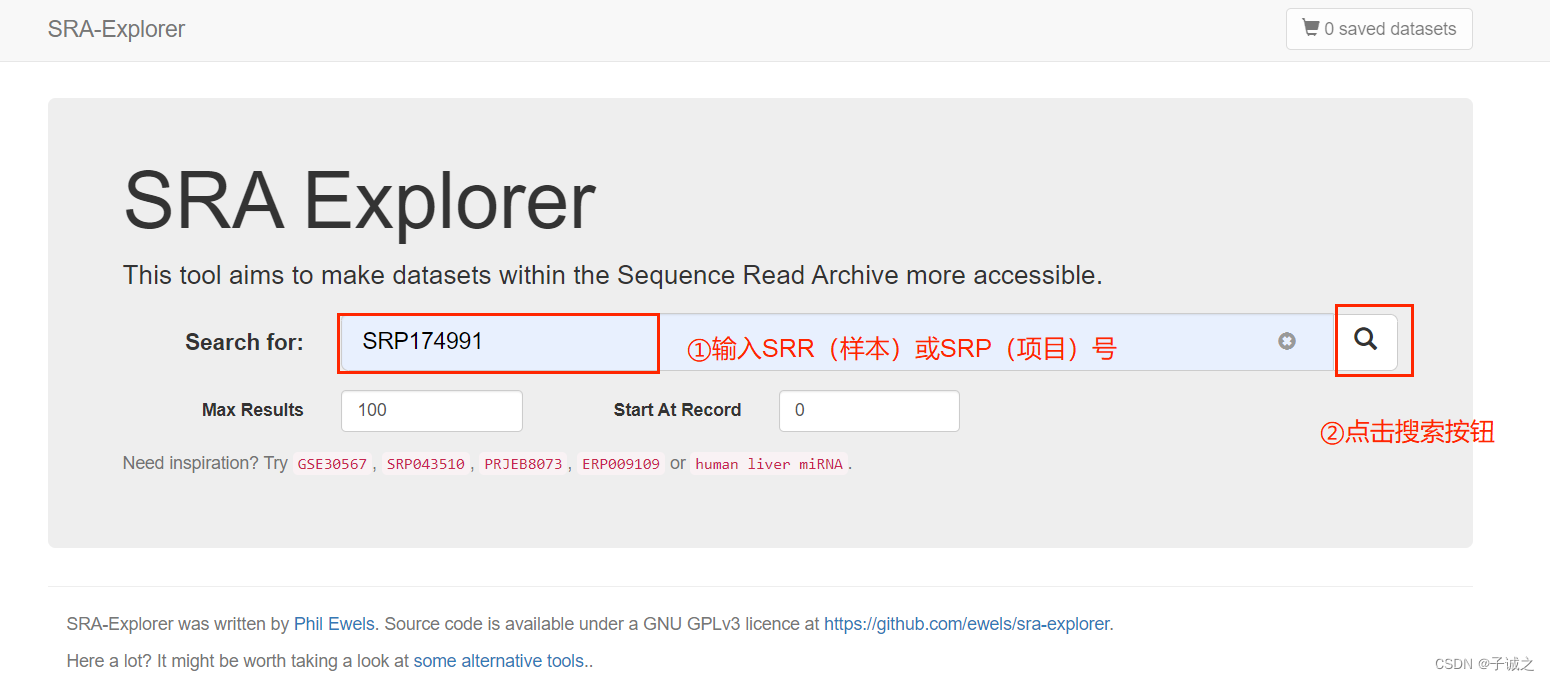
页面1
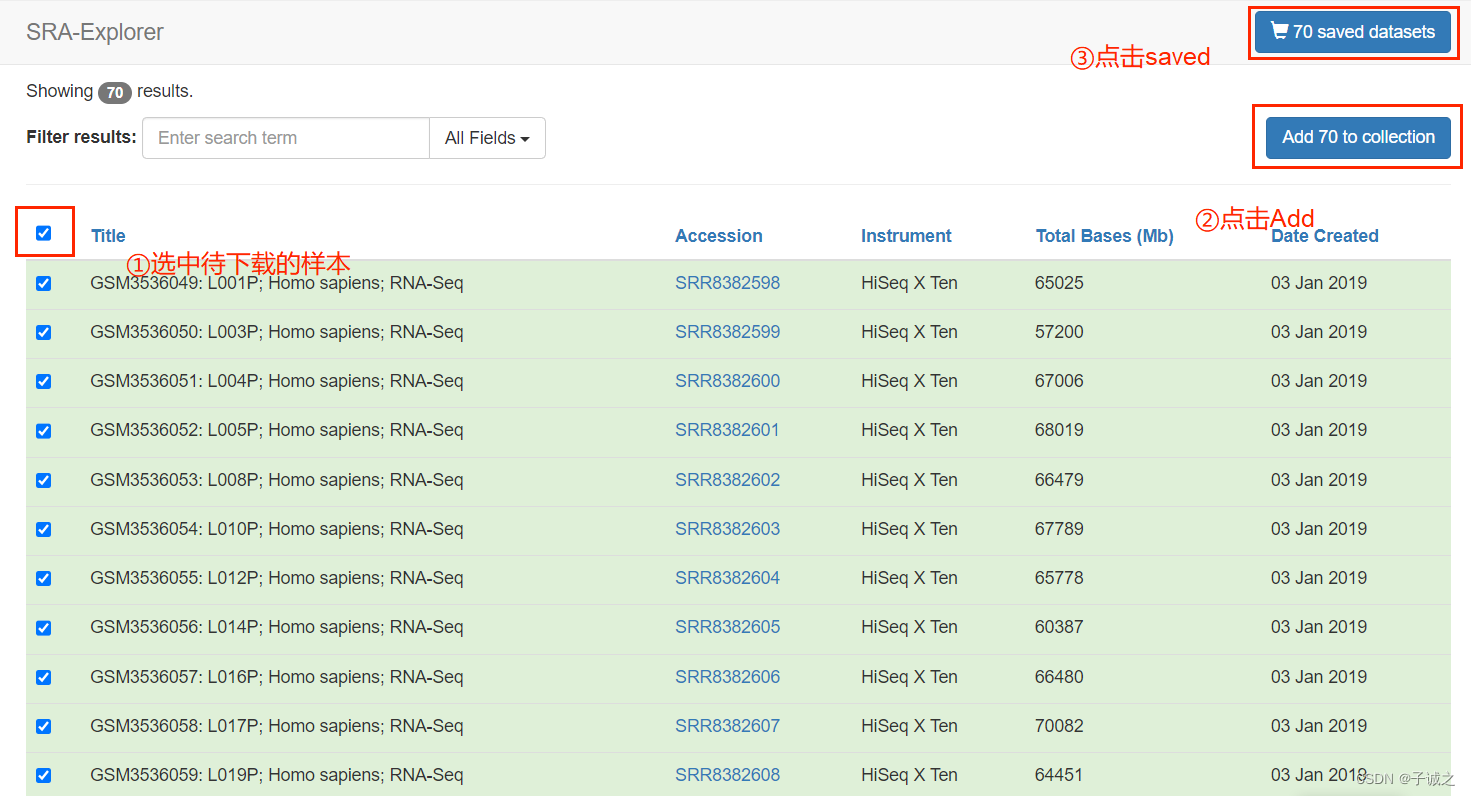
页面2
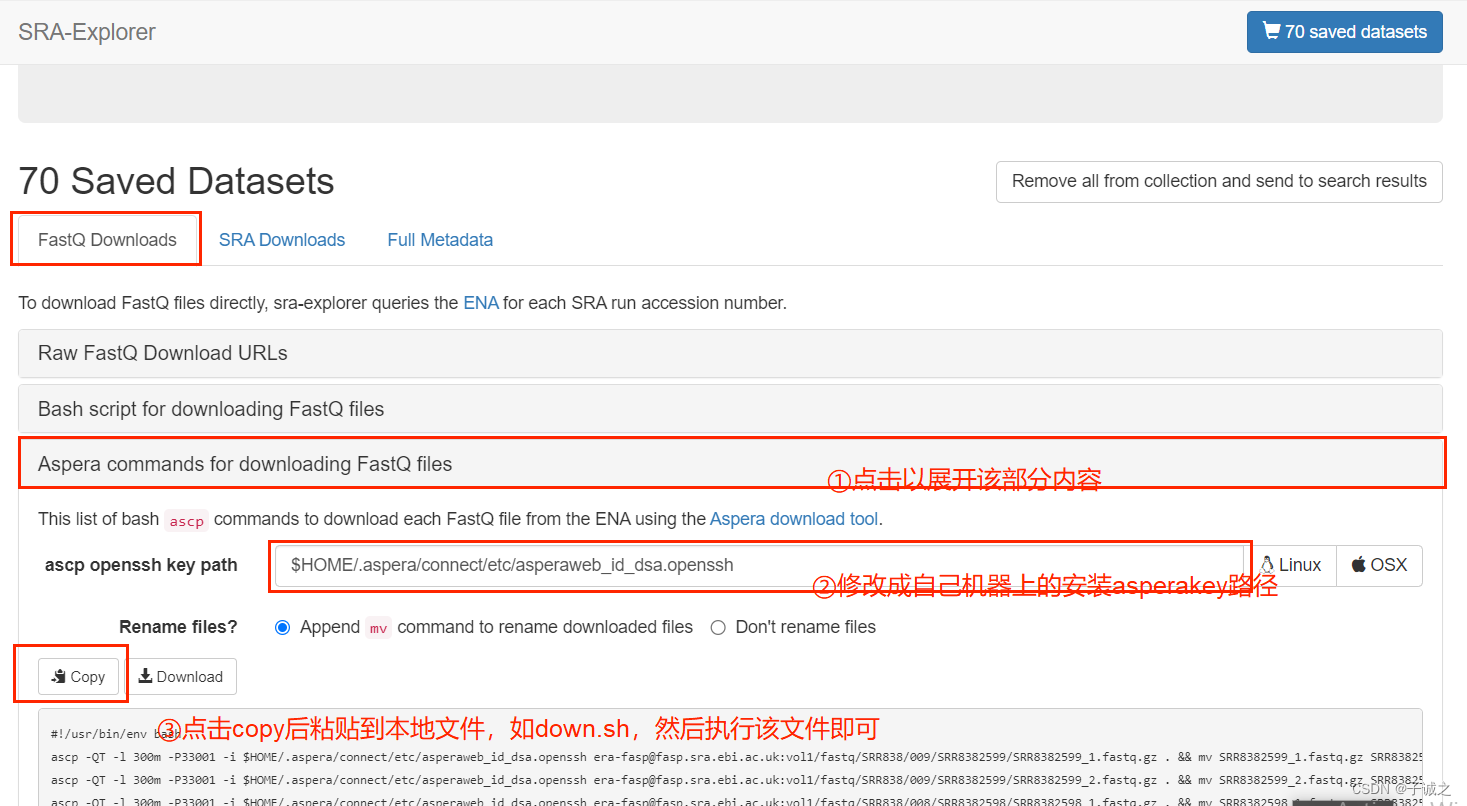
页面3
(2)在本地新建脚本,如down.sh,将内容粘贴到脚本中,然后执行nohup sh down.sh > down.o 2>down.e &。
2. PDC Client
PDC 主要共享基于质谱的蛋白质组数据。PDC 门户网站支持在线数据探索和可视化。所有数据(包括原始数据和衍生数据)均可开放获取。
| Data Category | File Type | File Format |
|---|---|---|
| Raw Mass Spectra | Proprietary | Vendor-specific |
| Processed Mass Spectra | Open Standard | mxML |
| Peptide Spectral Matches | Text, Open Standard | TSV, mzIdentML |
| Protein Assembly | Text | TSV |
| Quality Metrics | Web | HTML |
| Other Metadata | Document | PDF, DOC, XLSX, TSV |
pdc-client 是用于下载PDC数据的客户端工具。
1)pdc-client安装
通过 官网 下载对应版本,本文使用Linux的命令行/CL版本。
如果出现 GLIBC_2.29 not found ... 错误,且无法更新时,可以尝试 patchelf 更改命令文件的GLIBC路径,具体见之前的博文。2)蛋白组
用例1. 下载蛋白组数据
1)网站获取待下载数据清单(manifest)
配置和应用FILTERS后,点击Files标签,勾选需要下载的文件,点击Export File Manifest(下图)。得到的清单文件中包含每个文件的下载URL,需要注意:①URL的有效期为7天;②同一IP对同一文件在24h内可以重复下载10次。
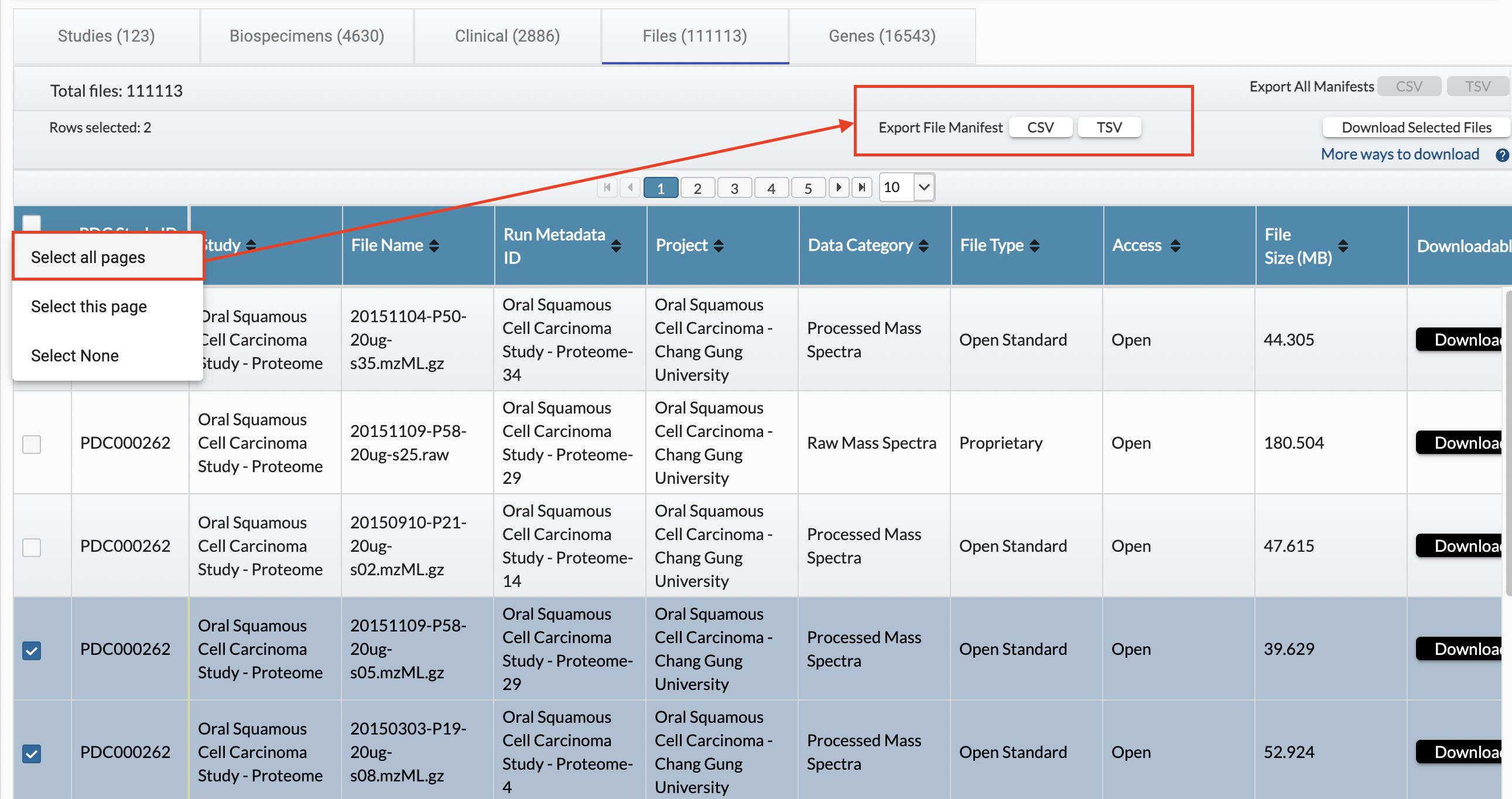
(2)使用PDC客户端下载数据
# 查看配置文件中设置的选项
./pdc-client settings download --config nothing > my_config.dtt
vi my_config.dtt
#[download]
#dir = . #下载目录,默认为当前目录。同-d参数。
#save_interval = 1073741824 #刷新状态文件的块数。值越小,打印频率越高,性能越低。
#http_chunk_size = 1048576 #HTTP块大小(字节)
#no_segment_md5sums = False #重启时不计算inbound segment md5值或不验证md5值
#no_file_md5sum = False #下载后不验证md5值
#no_verify = False #执行不安全的SSL连接和传输
#no_related_files = False #不下载相关文件
#no_auto_retry = False #下载重试前询问
#retry_amount = 1 #重试次数
#wait_time = 5.0 #重试前等待的秒数
#not_retain_pdc_download_path = False #将每个文件下载到独立的目录中
#server = https://pdc.cancer.gov/graphql #TCP服务地址
#n_processes = 6 #客户端连接数
# 下载
nohup ./pdc-client download -m manifest.csv --config my_config.dtt > mf.log 2>mf.err &
①通过-m指定文件清单文件。
②下载文件的默认目录结构为 PDC Study ID/Study Version Number/Data Category/Run Metadata ID(if applicable)/File Format。用户也可以通过--not-retain-pdc-download-path选项,将每个文件下载到独立的目录中。只有该选项启用时,可以通过--dir指定路径,这将把所有下载文件放到指定位置,而不会为每个文件创建单独的文件夹。
③下载重试:如果文件下载失败,目标文件夹中将出现扩展名为**.partial**文件。要完成这些文件下载,请使用相同的目标路径和包含失败/丢失文件的清单重复下载命令。PDC客户端将识别并下载不完整文件,清单中已成功下载的文件将自动跳过。需要注意的是,PDC允许24小时内对指定文件进行最多10 次重试。
④文件完整性检查:PDC客户端默认计算下载文件的MD5并与清单中的值进行验证。使用--no-file-md5sum选项运行下载命令将跳过这一验证步骤。
3. GDC Client
GDC的使命是为癌症研究团体提供一个统一的储存库和癌症知识库,使癌症基因组学研究能够共享数据,支持精准医疗。
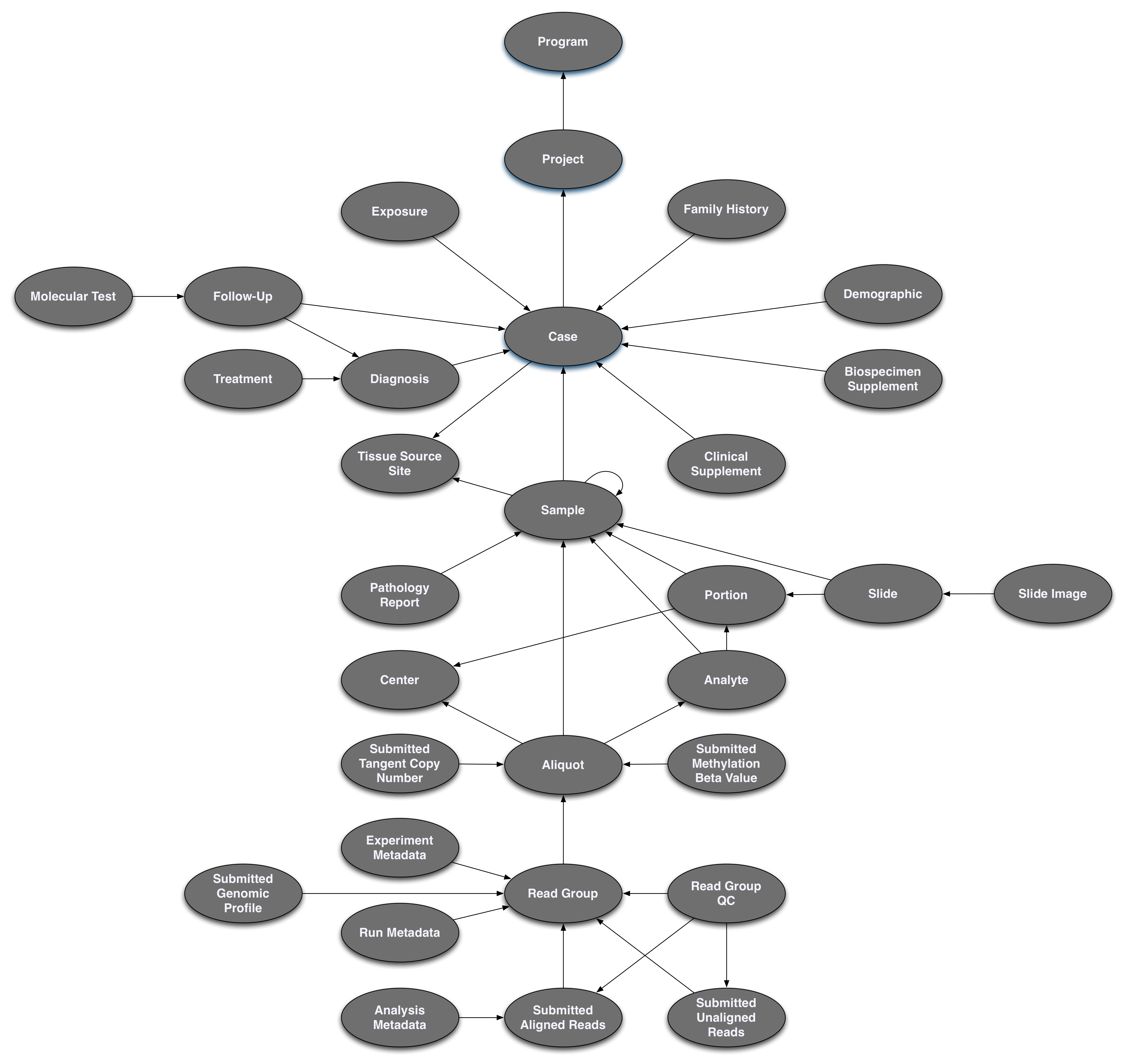
GDC Data Model
1)gdc-client安装
通过 官网 下载对应版本,本文使用Linux的命令行/CL版本。
2)多组学
用例1. 从GDC下载RNA-seq数据
(1)获取数据清单。首先在Cohort Builder页面根据项目、癌种等初步筛选数据;然后在Repository页面根据数据类型等进一步筛选数据;使用Add All files to Cart将选择文件添加到购物车;跳转到Cart页面,依次点击Download Cart > Mainfest。
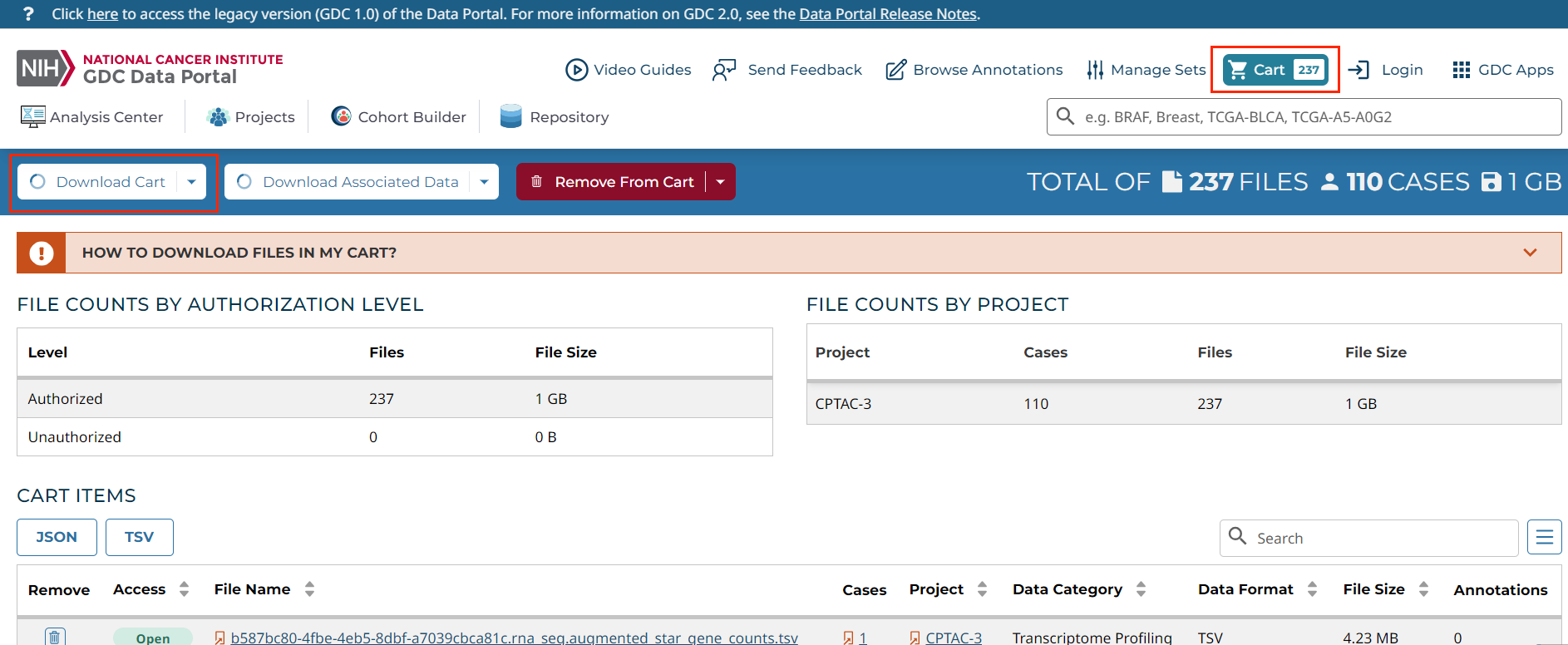
(2)使用gdc-client下载数据。
./gdc-client settings download > gdc_setting_download.cfg
vi gdc_setting_download.cfg
#[download]
#dir = .
#save_interval = 1073741824
#http_chunk_size = 1048576
#no_segment_md5sums = False
#no_file_md5sum = False
#no_verify = False
#no_related_files = False
#no_annotations = False
#no_auto_retry = False
#retry_amount = 1
#wait_time = 5.0
#latest = False
#server = https://api.gdc.cancer.gov
#n_processes = 8
./gdc-client download -m pdc_mainfest.txt --config gdc_setting_download.cfg
①通过 manifest(-m)或 UUIDs 指定下载文件。
②要恢复中断下载,在和初次下载相同的文件夹中重复下载 manifest 或 UUIDs。失败的下载将以 .partial扩展名出现在目标文件夹中。此功能可让用户快速识别下载中断的位置。对于大批量下载,该功能可让用户识别下载中断的位置,并对清单进行相应编辑。
③下载文件的目录将包括以文件 UUID 命名的文件夹。在这些文件夹中,除了数据和压缩格式的meta或索引文件外,还有一个logs文件夹。日志文件夹包含的状态文件可确保下载的准确性,并允许恢复失败或过早停止的下载。
blastDB
简介
①下载网址:https://ftp.ncbi.nlm.nih.gov/blast/db/
②资源:
- 预格式化数据库,如n[tr]*tar.gz等,推荐优先使用。
- FASTA序列,可以从格式化数据库提取。
- …
下载
# 需要人工确认number范围和格式
for i in {00..92} # 需要人工确认number范围和格式
do
wget -c https://ftp.ncbi.nlm.nih.gov/blast/db/nr.${i}.gz .
...
done
附录. tmux的简单用法
tmux new -s aspera
#ascp ... > o.log &
#Ctrl+b d # 退出
#tmux attach -t aspera # 进入















 2182
2182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









