







NLP论文:Weight tying 笔记
论文
原论文:《Using the Output Embedding to Improve Language Models》
介绍
2016-08发表的文章,该文章将模型的输入embedding和输出embedding tie在一起,即共享一个embedding空间,同一个词在输入embed时和输出embed时会embed成同一个embedding向量。在翻译模型中,如果2种语言的subword共享率非常高,甚至可以实现编码器的输入embedding、解码器的输入embedding和解码器的输出embedding 三者共享。
输出embedding,就是模型最后的特征层 h h h -> 线性层 W o , e m b W_{o,emb} Wo,emb -> softmax层之间的那个线性层,其中 h ∈ R d e m b × 1 , W o , e m b ∈ R C t × d e m b , C t h \in R^{d_{emb}\times 1}, W_{o,emb} \in R^{C_t\times d_{emb}},C_t h∈Rdemb×1,Wo,emb∈RCt×demb,Ct 是目标词汇表(target vocabulary)的大小。
模型结构
文章部分翻译
Abstract
我们研究了神经网络语言模型的最上层的矩阵。我们证明了这个矩阵构成了一个有效的word embedding。在训练语言模型时,我们建议将输入embedding和输出embedding绑定起来。我们分析了产生结果的更新规则,并表明 tied embedding与 untied 模型中的输出embedding的发展方式更为相似,比起输入embedding的的发展方式来说。我们还提供了一种新的正则化输出embedding的方法。我们的方法大大减少了困惑度,并且我们能够在各种神经网络语言模型上展示这一点。最后,我们证明了weight tying可以将神经翻译模型的大小减少到其原始大小的一半以下,而不会损害其性能。
1 Introduction
在一个常见的神经网络语言模型家族中,当前输入词表示为向量 c ∈ R C c\in R^C c∈RC 并使用word embedding矩阵 U U U 将其投影为稠密的表示。然后对word embedding U T c U^Tc UTc 执行一些计算,从而得到激活向量 h 2 h_2 h2。然后,第二个矩阵 V V V 将 h 2 h_2 h2 投影到向量 h 3 h_3 h3,该向量 h 3 h_3 h3 包含每个词汇单词的一个分数: h 3 = V h 2 h_3=Vh_2 h3=Vh2。然后使用softmax函数将分数向量转换为概率值 p p p 向量,表示模型对下一个单词的预测。
例如,在基于LSTM的语言模型(Sundermeyer et al.,2012;Zaremba et al.,2014)中,对于大小为 C C C 的字典,one-hot 编码用于表示输入 c c c 并且 U ∈ R C × H U\in R^{C\times H} U∈RC×H。然后采用LSTM,其产生类似于 U T c U^Tc UTc 的激活向量 h 2 h_2 h2、 也是属于 R H R^H RH。在这种情况下, U U U 和 V V V 的大小完全相同。
我们称 U U U 为输入embedding, V V V 为输出embedding。在这两个矩阵中,我们期望对应于相似的单词的行是相似的:对于输入embedding,我们希望网络对同义词做出相似的反应,而在输出embedding中,我们希望可互换单词的分数是相似的(Mnih和Teh,2012)。
虽然 U U U 和 V V V 都可以作为word embedding,但在那篇文献中,只有前者起到了这个作用。在本文中,我们比较了输入embedding和输出embedding的质量,并表明后者可用于改进神经网络语言模型。我们的主要结果如下:(i)我们发现在word2vec skip-gram模型中,输出embedding仅略低于输入embedding。这是通过使用常用于测量embedding质量的度量来展示。(ii)在基于RNN的语言模型中,输出embedding优于输入embedding。(iii)通过将两个embedding tie在一起,即强制 U = V U=V U=V,联合embedding以更类似于 untied 模型中的输出embedding的方式发展,而非输入embedding的方式。(iv)将输入和输出embedding tie起来,可以改善各种语言模型的复杂性。无论是使用dropout还是不使用dropout,都是如此。(v) 当不使用dropout时,我们建议在 V V V 之前添加一个额外的投影 P P P,并对 P P P 应用正则化。(vi)神经翻译模型中的 weight tying 可以将其大小(参数数量)减少到其原始大小的一半以下,而不会损害其性能。
3 Weight Tying
在这篇论文中,我们采用了三种不同的模型类别:NNLMs、word2vec skip-gram模型和NMT模型。weight tying同样适用于所有模型。对于翻译模型,我们还提出了一种三向 weight tying 方法。
NNLM模型包含一个输入embedding矩阵、两个LSTM层( h 1 h_1 h1 和 h 2 h_2 h2)、一个隐藏 scores/logits 第三层 h 3 h_3 h3 和一个softmax层。训练过程中使用的损失函数是没有任何正则化项的交叉熵损失函数。
根据(Zaremba等人,2014年),我们采用了两种模型:大模型和小模型。大型模型使用 dropout 进行正则化。小模型不使用正则化。因此,我们提出以下正则化方案。投影矩阵 P ∈ R H × H P\in R^{H\times H} P∈RH×H 在输出前插入,即 h 3 = V P h 2 h_3=VPh_2 h3=VPh2。随后将正则项 λ ∣ ∣ P ∣ ∣ 2 \lambda ||P||_2 λ∣∣P∣∣2 添加到小模型的损失函数中。在我们所有的实验中, λ = 0.15 \lambda=0.15 λ=0.15。
投影矩阵正则化允许我们使用相同的embedding(同时作为输入/输出embedding)并有着正则化下的一些自适应。因此,它特别适用于WT。
在训练一个普通的 untied NNLM 时,在时间步 t t t,使用当前输入词序列 i 1 : t = [ i 1 , … , i t ] i_{1:t}=[i_1,…,i_t] i1:t=[i1,…,it] 和当前目标输出词 o t o_t ot ,负对数似然损失函数为: L t = − log p t ( o t ∣ i 1 : t ) L_t=-\log p_t(o_t|i_{1:t}) Lt=−logpt(ot∣i1:t),其中 p t ( o t ∣ i 1 : t ) = e x p ( V o t T h 2 ( t ) ) ∑ x = 1 C e x p ( V x T h 2 ( t ) ) . p_t(o_t|i_{1:t})=\frac{exp(V_{o_t}^Th_2^{(t)})}{\sum_{x=1}^Cexp(V_x^Th_2^{(t)})}. pt(ot∣i1:t)=∑x=1Cexp(VxTh2(t))exp(VotTh2(t)). U k U_k Uk 是 U U U 的第 k k k 行, V k V_k Vk 是 V V V 的第 k k k 行,对应于单词 k k k, h 2 ( t ) h_2^{(t)} h2(t) 是最顶层LSTM层输出在 t t t 时刻的激活向量。为了简化,我们假设在每一个时间步 t t t, i t ≠ o t i_t\neq o_t it=ot。采用随机梯度下降法对模型进行优化。
输入embedding的
k
k
k 行的更新为:
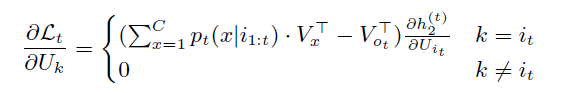

对于输出embedding,第
k
k
k 行的更新为:
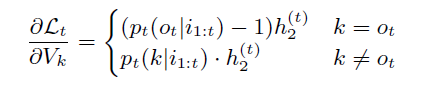

因此,在 untied 模型中,在每个时间步,输入embedding中唯一更新的行是表示当前输入字的行 U i t U_{i_t} Uit。这意味着表示稀有词的向量只会更新少量的次数。输出embedding在每个时间步更新每一行。
在 tied NNLMs 中,我们设置 U = V = S U=V=S U=V=S。 S S S 中每一行的更新是 S S S 分别作为输入embedding和输出embedding所获得的更新的总和。
行 k ≠ i t k\neq i_t k=it 的更新类似于 untied NNLM 输出embedding中行 k k k 的更新(唯一的区别是 U U U 和 V V V 都被一个单独的矩阵 S S S 替换)。在这种情况下,没有来自S的输入embedding参与的更新。
行 k = i t k=i_t k=it 的更新由输入embedding的一项( k = i t k=i_t k=it 的情况)和输出embedding的一项( k ≠ o t k\neq o_t k=ot 的情况)组成。第二项随 p t ( i t ∣ i 1 : t ) p_t(i_t | i_{1:t}) pt(it∣i1:t) 线性增长,预计几乎等于零,因为单词很少在输入端和输出端同时出现(网络中的低概率也通过实验验证)。因此,在这种情况下发生的更新主要受 S S S 的输入embedding参与的更新的影响。
综上所述,在 tied NNLM 中,在每次迭代期间都会更新 S S S 的每一行,对于除一行之外的所有行,此更新类似于 untied 模型 的输出embedding的更新。这意味着 tied embedding 与 untied 模型 的输出embedding的相似程度大于其输入embedding的相似程度。
为了简洁起见,上述分析侧重于NNLMs。在 word2vec 中,更新规则类似,只是 h 2 ( t ) h_2^{(t)} h2(t) 被类似的函数替换。正如(Goldberg and Levy,2014)所述,在这种情况下,weight tying 是不合适的,因为如果 p t ( i t ∣ i 1 : t ) p_t(i_t | i_{1:t}) pt(it∣i1:t) 接近于零,那么embedding的范数也是如此。自从LSTM层会导致输入和输出嵌入的解耦,这种说法不适用于NNLMs。
最后,我们评估了 weight tying 在神经翻译模型中的作用。在此模型中: p t ( o t ∣ i 1 : t , r ) = e x p ( V o t T G ( t ) ) ∑ x = 1 C t e x p ( V x T G ( t ) ) , p_t(o_t | i_{1:t},r)=\frac{exp(V_{o_t}^TG^{(t)})}{\sum_{x=1}^{C_t}exp(V_x^TG^{(t)})}, pt(ot∣i1:t,r)=∑x=1Ctexp(VxTG(t))exp(VotTG(t)),其中 r = ( r 1 , . . . , r N ) r=(r_1,...,r_N) r=(r1,...,rN) 是源句子中的一组词, U U U 和 V V V 是解码器的输入和输出embedding, W W W 是编码器的输入embedding(在翻译模型中, U , V ∈ R C t × H , W ∈ R C s × H U,V\in R^{C_t\times H},W\in R^{C_s\times H} U,V∈RCt×H,W∈RCs×H ,其中 C s / C t C_s/C_t Cs/Ct 是源/目标词汇表的大小)。 G ( t ) G^{(t)} G(t) 是解码器,它接收上下文向量、输入词( i t i_t it)在 U U U 中的embedding以及它在每个时间步的先前状态。 c t c_t ct 是时间步 t t t 的上下文向量, c t = ∑ j ∈ r a t j h j c_t=\sum_{j\in r}a_{tj}h_j ct=∑j∈ratjhj,其中 a t j a_{tj} atj 是时刻 t t t 给予第 j j j 个 annotation 的权重: a t j = e x p ( e t j ) ∑ k ∈ r e x p ( e i k ) , a_{tj}=\frac{exp(e_{tj})}{\sum_{k\in r}exp(e_{ik})}, atj=∑k∈rexp(eik)exp(etj),并且 e i k = a t ( h j ) e_{ik}=a_t(h_j) eik=at(hj),其中 a a a 是匹配模型。 F F F 是产生 annotation 序列 ( h 1 , … , h N ) (h_1,…,h_N) (h1,…,hN)的编码器。
然后使用输出embedding将解码器的输出投影到分数向量: l t = V G ( t ) l_t=VG^{(t)} lt=VG(t)。然后使用softmax函数将分数转换为概率值。
在我们的 weight tied 翻译模型中,我们 tie 了解码器的输入和输出embedding。
我们观察到,在预处理 ACL WMT 2014 EN→FR 1 ^1 1 和 WMT 2015 EN→DE 2 ^2 2 数据集使用BPE时,许多子词出现在源语言和目标语言的词汇表中。标签1显示,英语和法语(德语)之间的BPE subwords 共享率高达90%(85%)。
基于这一观察,我们提出了三向 weight tying(TWWT),其中解码器的输入embedding、解码器的输出embedding和编码器的输入embedding都被 tie 起来。该模型的源/目标词汇表是源词汇表和目标词汇表的联合。在该模型中,无论是在编码器还是解码器中,所有 subword 都 embed 在相同的双语言空间中。
相关视频
相关的笔记
[论文阅读]Using the Output Embedding to Improve Language Models















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









