









1.
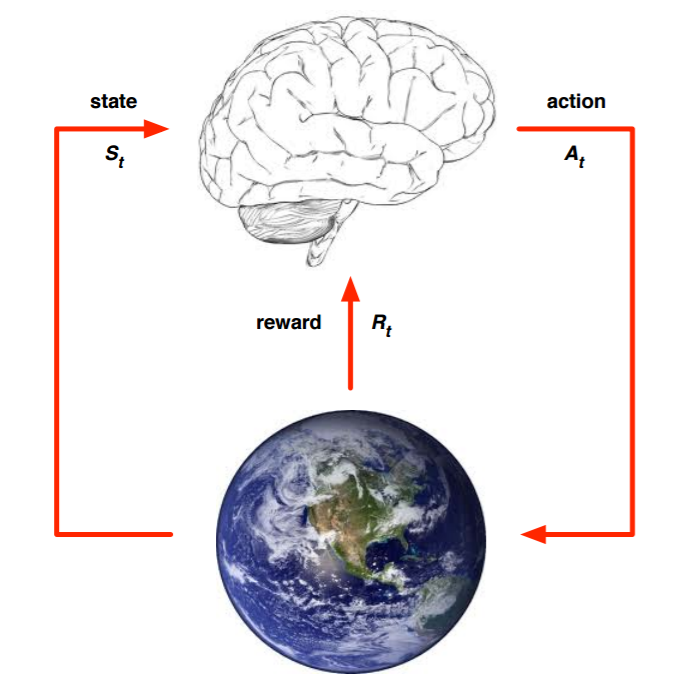
上面的大脑代表我们的算法执行个体,我们可以操作个体来做决策,即选择一个合适的动作(Action)AtAt。下面的地球代表我们要研究的环境,它有自己的状态模型,我们选择了动作AtAt后,环境的状态(State)会变,我们会发现环境状态已经变为St+1St+1,同时我们得到了我们采取动作AtAt的延时奖励(Reward)Rt+1Rt+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会变,又有新的奖励值。。。这就是强化学习的思路。
那么我们可以整理下这个思路里面出现的强化学习要素。
第一个是环境的状态S, t时刻环境的状态StSt是它的环境状态集中某一个状态。
第二个是个体的动作A, t时刻个体采取的动作AtAt是它的动作集中某一个动作。
第三个是环境的奖励R,t时刻个体在状态StSt采取的动作AtAt对应的奖励Rt+1Rt+1会在t+1时刻得到。
下面是稍复杂一些的模型要素。
第四个是个体的策略(policy)ππ,它代表个体采取动作的依据,即个体会依据策略ππ来选择动作。最常见的策略表达方式是一个条件概率分布π(a|s)π(a|s), 即在状态ss时采取动作aa的概率。即π(a|s)=P(At=a|St=s)π(a|s)=P(At=a|St=s).此时概率大的动作被个体选择的概率较高。
第五个是个体在策略ππ和状态ss时,采取行动后的价值(value),一般用vπ(s)vπ(s)表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励Rt+1Rt&#

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 2013
2013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











