







 该专栏专注于强化学习的教学,涵盖单智能体和多智能体的算法原理,包括DDPG、DQN等主流算法的项目实战。此外,还涉及趣味项目如超级玛丽、五子棋等,以及实际应用如无人机调度。文中详细介绍了基于蒙特卡洛树和策略价值网络的深度强化学习五子棋项目,包括训练流程和代码结构,并提供了训练脚本和前端界面代码。
该专栏专注于强化学习的教学,涵盖单智能体和多智能体的算法原理,包括DDPG、DQN等主流算法的项目实战。此外,还涉及趣味项目如超级玛丽、五子棋等,以及实际应用如无人机调度。文中详细介绍了基于蒙特卡洛树和策略价值网络的深度强化学习五子棋项目,包括训练流程和代码结构,并提供了训练脚本和前端界面代码。

【强化学习原理+项目专栏】必看系列:单智能体、多智能体算法原理+项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现

专栏详细介绍:【强化学习原理+项目专栏】必看系列:单智能体、多智能体算法原理+项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现
对于深度强化学习这块规划为:
- 基础单智能算法教学(gym环境为主)
- 主流多智能算法教学(gym环境为主)
- 主流算法:DDPG、DQN、TD3、SAC、PPO、RainbowDQN、QLearning、A2C等算法项目实战
- 一些趣味项目(超级玛丽、下五子棋、斗地主、各种游戏上应用)
- 单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)
本专栏主要方便入门同学快速掌握强化学习单智能体|多智能体算法原理+项目实战。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。
声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)
-
专栏订阅(个性化选择):
实现了基于蒙特卡洛树和策略价值网络的深度强化学习五子棋(含码源)
-
特点
- 自我对弈
- 详细注释
- 流程简单
-
代码结构
- net:策略价值网络实现
- mcts:蒙特卡洛树实现
- server:前端界面代码
- legacy:废弃代码
- docs:其他文件
- utils:工具代码
- network.py:移植过来的网络结构代码
- model_5400.pkl:移植过来的网络训练权重
- train_agent.py:训练脚本
- web_server.py:对弈服务脚本
- web_server_demo.py:对弈服务脚本(移植网络)
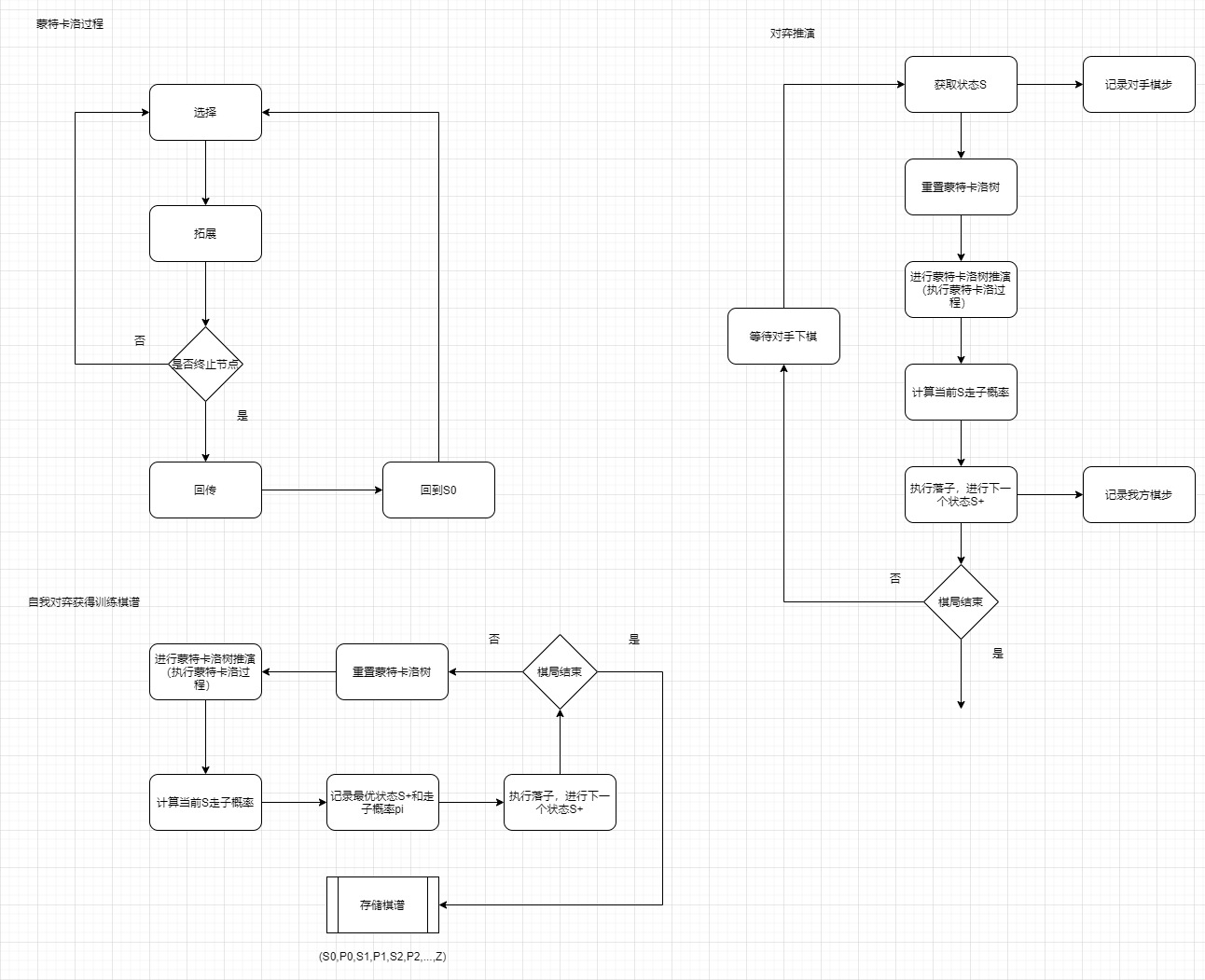
1.1 流程
1.2策略价值网络
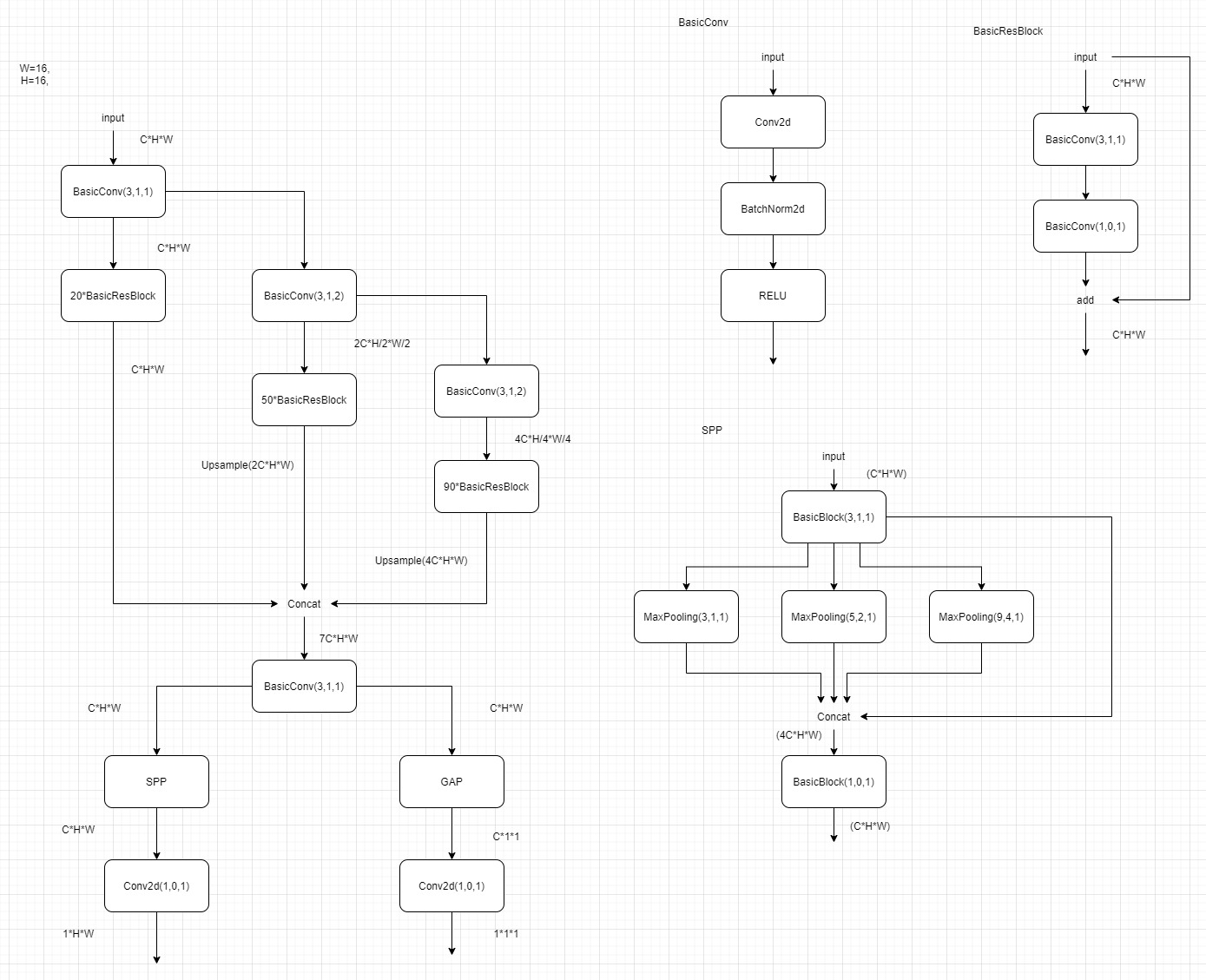
采用了类似ResNet的结构,加入了SPP模块。
(目前,由于训练太耗时间了,连续跑了三个多星期,才跑了2000多个自我对弈的棋谱,经过实验,这个策略网络的表现,目前还是不行,可能育有还没有训练充分)
同时移植了另一个开源的策略网络以及其训练权重(network.py、model_5400.pkl),用于进行仿真演示效果。
1.3 训练
根据注释调整train_agent.py文件,并运行该脚本
部分代码展示:
if __name__ == '__main__':
conf = LinXiaoNetConfig()
conf.set_cuda(True)
conf.set_input_shape(8, 8)
conf.set_train_info(5, 16, 1e-2)
conf.set_checkpoint_config(5, 'checkpoints/v2train')
conf.set_num_worker(0)
conf.set_log('log/v2train.log')
# conf.set_pretrained_path('checkpoints/v2m4000/epoch_15')
init_logger(conf.log_file)
logger()(conf)
device = 'cuda' if conf.use_cuda else 'cpu'
# 创建策略网络
model = LinXiaoNet(3)
model.to(device)
loss_func = AlphaLoss()
loss_func.to(device)
optimizer = torch.optim.SGD(model.parameters(), conf.init_lr, 0.9, weight_decay=5e-4)
lr_schedule = torch.optim.lr_scheduler.StepLR(optimizer, 1, 0.95)
# initial config tree
tree = MonteTree(model, device, chess_size=conf.input_shape[0], simulate_count=500)
data_cache = TrainDataCache(num_worker=conf.num_worker)
ep_num = 0
chess_num = 0
# config train interval
train_every_chess = 18
# 加载检查点
if conf.pretrain_path is not None:
model_data, optimizer_data, lr_schedule_data, data_cache, ep_num, chess_num = load_checkpoint(conf.pretrain_path)
model.load_state_dict(model_data)
optimizer.load_state_dict(optimizer_data)
lr_schedule.load_state_dict(lr_schedule_data)
logger()('successfully load pretrained : {}'.format(conf.pretrain_path))
while True:
logger()(f'self chess game no.{chess_num+1} start.')
# 进行一次自我对弈,获取对弈记录
chess_record = tree.self_game()
logger()(f'self chess game no.{chess_num+1} end.')
# 根据对弈记录生成训练数据
train_data = generate_train_data(tree.chess_size, chess_record)
# 将训练数据存入缓存
for i in range(len(train_data)):
data_cache.push(train_data[i])
if chess_num % train_every_chess == 0:
logger()(f'train start.')
loader = data_cache.get_loader(conf.batch_size)
model.train()
for _ in range(conf.epoch_num):
loss_record = []
for bat_state, bat_dist, bat_winner in loader:
bat_state, bat_dist, bat_winner = bat_state.to(device), bat_dist.to(device), bat_winner.to(device)
optimizer.zero_grad()
prob, value = model(bat_state)
loss = loss_func(prob, value, bat_dist, bat_winner)
loss.backward()
optimizer.step()
loss_record.append(loss.item())
logger()(f'train epoch {ep_num} loss: {sum(loss_record) / float(len(loss_record))}')
ep_num += 1
if ep_num % conf.checkpoint_save_every_num == 0:
save_checkpoint(
os.path.join(conf.checkpoint_save_dir, f'epoch_{ep_num}'),
ep_num, chess_num, model.state_dict(), optimizer.state_dict(), lr_schedule.state_dict(), data_cache
)
lr_schedule.step()
logger()(f'train end.')
chess_num += 1
save_chess_record(
os.path.join(conf.checkpoint_save_dir, f'chess_record_{chess_num}.pkl'),
chess_record
)
# break
pass
1.4 仿真实验
根据注释调整web_server.py文件,加载所用的预训练权重,并运行该脚本
浏览器打开网址:http://127.0.0.1:8080/ 进行对弈
部分代码展示
# 用户查询机器落子状态
@app.route('/state/get/<state_id>', methods=['GET'])
def get_state(state_id):
global state_result
state_id = int(state_id)
state = 0
chess_state = None
if state_id in state_result.keys() and state_result[state_id] is not None:
state = 1
chess_state = state_result[state_id]
state_result[state_id] = None
ret = {
'code': 0,
'msg': 'OK',
'data': {
'state': state,
'chess_state': chess_state
}
}
return jsonify(ret)
# 游戏开始,为这场游戏创建蒙特卡洛树
@app.route('/game/start', methods=['POST'])
def game_start():
global trees
global model, device, chess_size, simulate_count
tree_id = random.randint(1000, 100000)
trees[tree_id] = MonteTree(model, device, chess_size=chess_size, simulate_count=simulate_count)
ret = {
'code': 0,
'msg': 'OK',
'data': {
'tree_id': tree_id
}
}
return jsonify(ret)
# 游戏结束,销毁蒙特卡洛树
@app.route('/game/end/<tree_id>', methods=['POST'])
def game_end(tree_id):
global trees
tree_id = int(tree_id)
trees[tree_id] = None
ret = {
'code': 0,
'msg': 'OK',
'data': {}
}
return ret
if __name__ == '__main__':
app.run(
'0.0.0.0',
8080
)
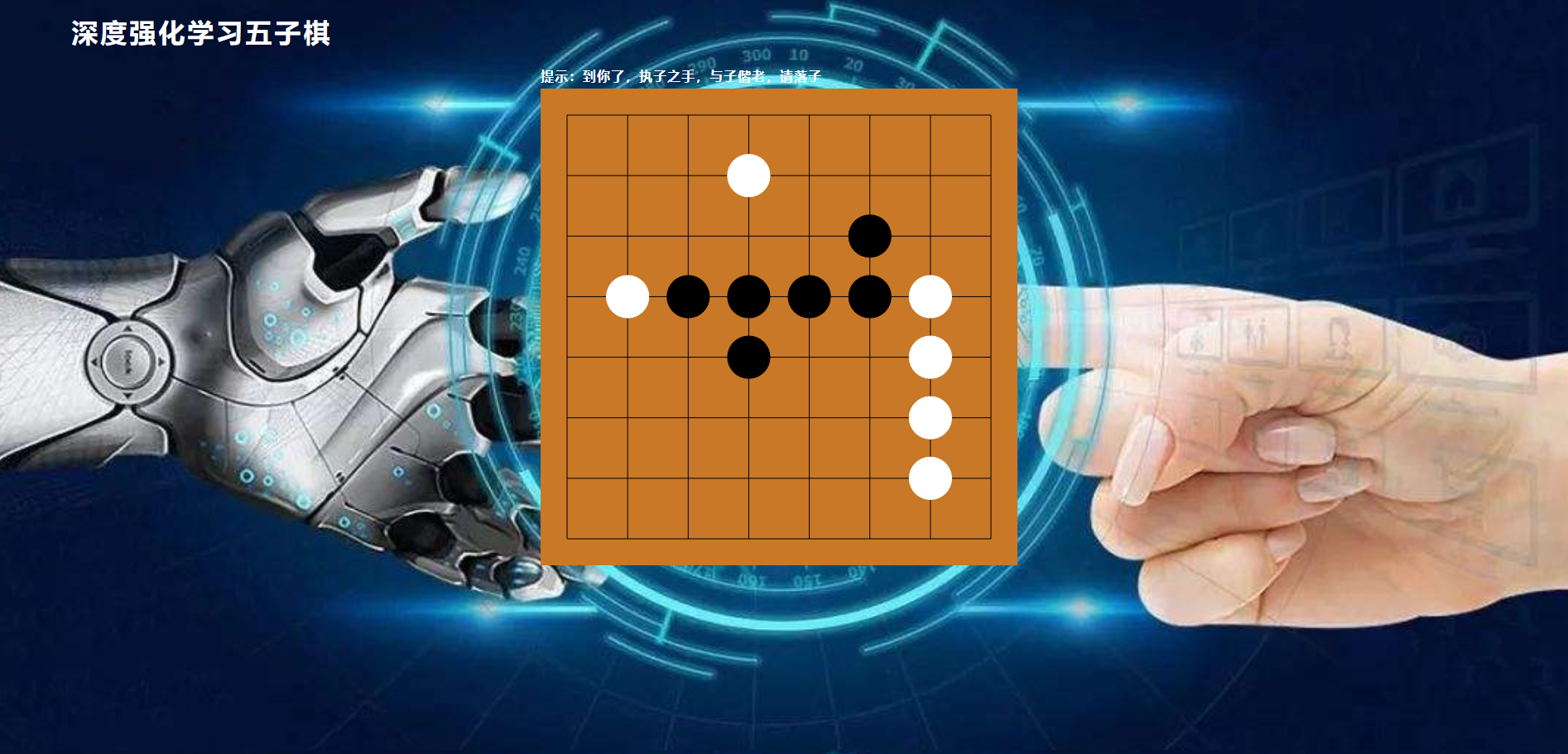
1.5 仿真实验(移植网络)
运行脚本:python web_server_demo.py
浏览器打开网址:http://127.0.0.1:8080/ 进行对弈
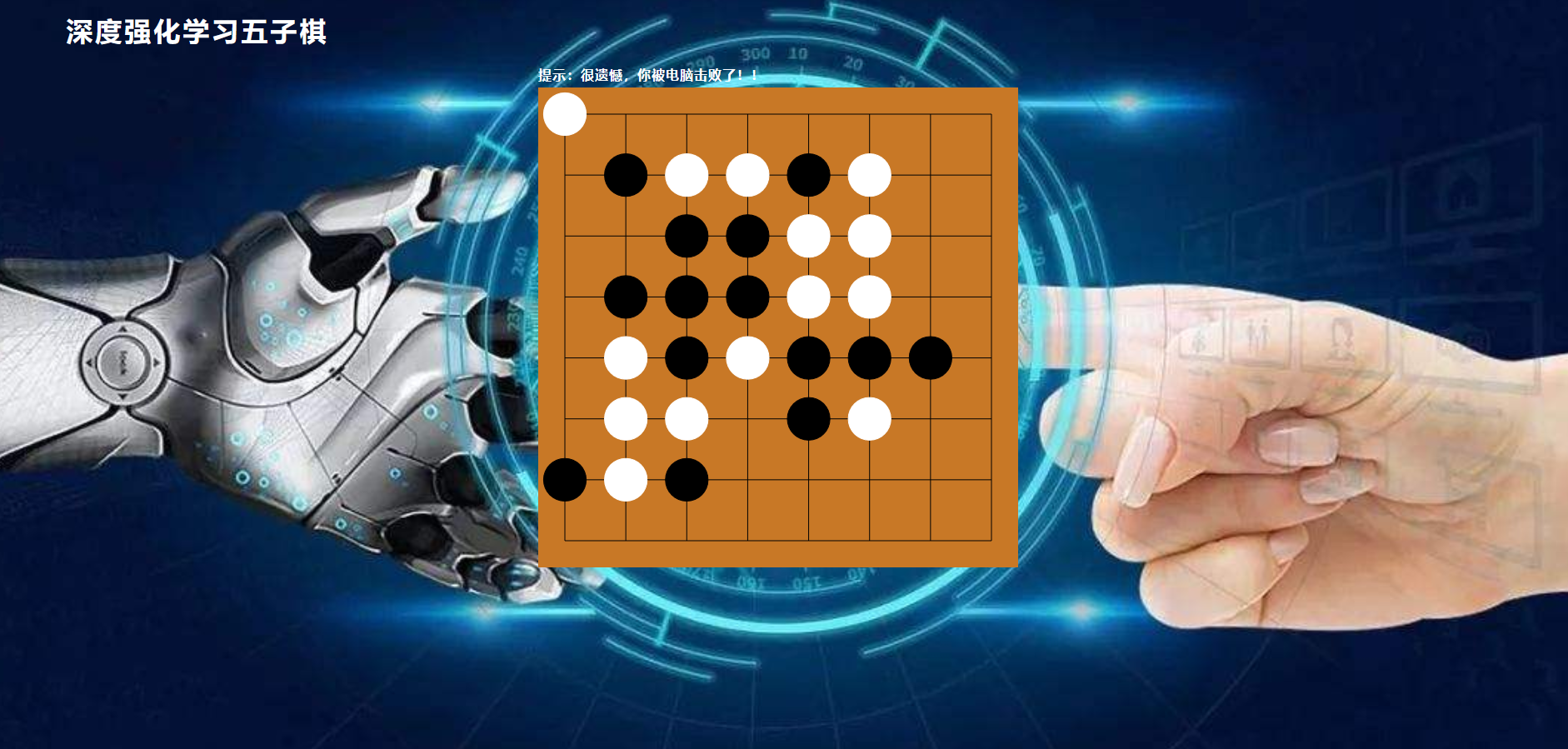
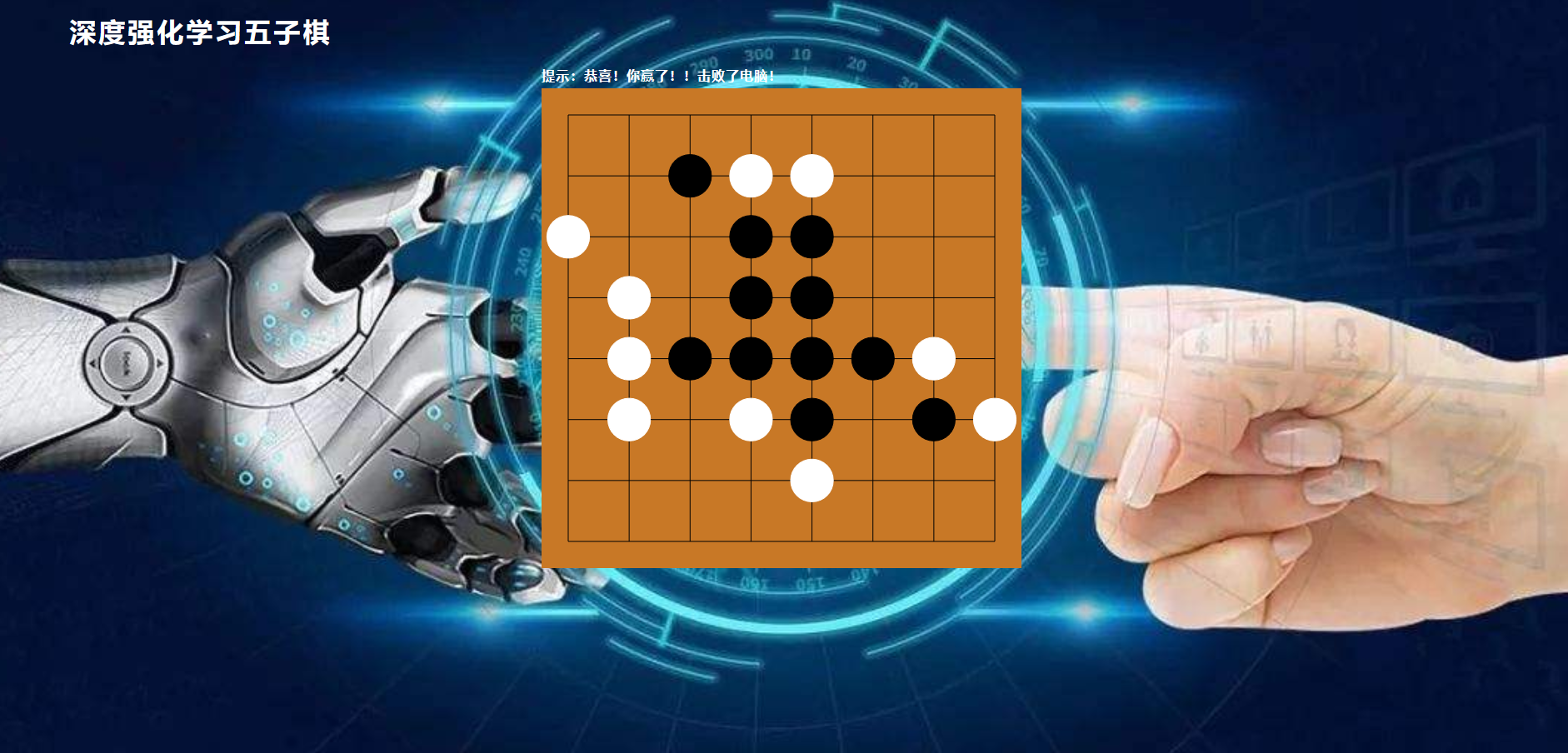
- 参考文档


















 2541
2541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











