







一、引言
前文回顾:
【Python机器学习系列】一文彻底搞懂机器学习中表格数据的输入形式(理论+源码)
【Python机器学习系列】一文带你了解机器学习中的Pipeline管道机制(理论+源码)
【Python机器学习系列】一文搞懂机器学习中的转换器和估计器(附案例)
【Python机器学习系列】一文讲透机器学习中的K折交叉验证(源码)
【Python机器学习系列】拟合和回归傻傻分不清?一文带你彻底搞懂它
【Python机器学习系列】建立决策树模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立支持向量机模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立逻辑回归模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立KNN模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立随机森林模型预测心脏疾病(完整实现过程)
【Python机器学习系列】建立梯度提升模型预测心脏疾病(完整实现过程)
对于表格数据,一套完整的机器学习建模流程如下:

针对不同的数据集,有些步骤不适用即不需要做,其中橘红色框为必要步骤,由于数据质量较高,本文有些步骤跳过了,跳过的步骤将单独出文章总结!同时欢迎大家关注翻看我之前的一些相关文章。
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。XGBoost通过集成多个决策树模型来进行预测,并通过梯度提升算法不断优化模型的性能。XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。本文利用xgboost实现了基于心脏疾病数据集建立XGBoost分类模型对心脏疾病患者进行分类预测的完整过程。
# pip install xgboost
from xgboost.sklearn import XGBClassifier二、实现过程
1、准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)df:
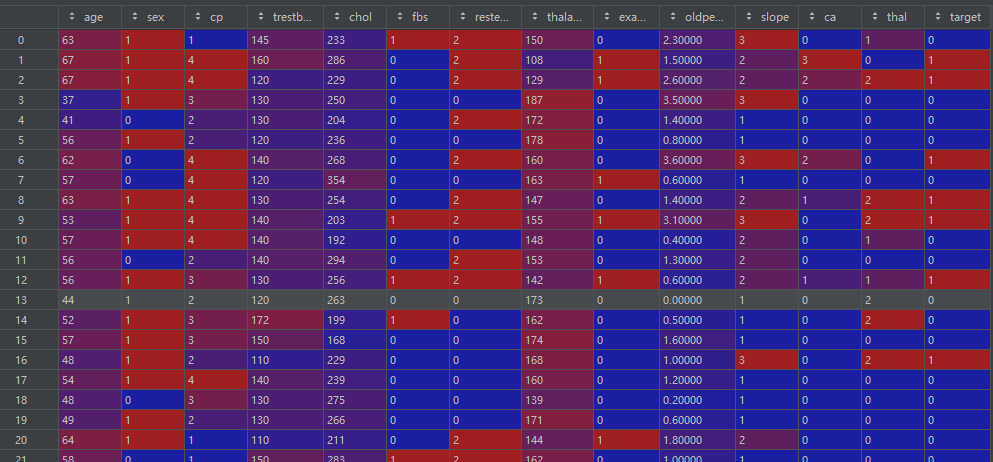
数据基本信息:
print(df.head())
print(df.info())
print(df.shape)
print(df.columns)
print(df.dtypes)
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名2、提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts()) # 顺便查看一下样本是否平衡3、数据集划分
# df = shuffle(df)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)4、模型的构建与训练
# 模型的构建与训练
model = xgb.XGBClassifier(n_estimators=100, max_depth=10)
model.fit(X_train, y_train)参数详解:
import xgboost as xgb
# 参数
class XGBModel(XGBModelBase):
# pylint: disable=too-many-arguments, too-many-instance-attributes, missing-docstring
def __init__(
self,
max_depth: Optional[int] = None,
max_leaves: Optional[int] = None,
max_bin: Optional[int] = None,
grow_policy: Optional[str] = None,
learning_rate: Optional[float] = None,
n_estimators: int = 100,
verbosity: Optional[int] = None,
objective: _SklObjective = None,
booster: Optional[str] = None,
tree_method: Optional[str] = None,
n_jobs: Optional[int] = None,
gamma: Optional[float] = None,
min_child_weight: Optional[float] = None,
max_delta_step: Optional[float] = None,
subsample: Optional[float] = None,
sampling_method: Optional[str] = None,
colsample_bytree: Optional[float] = None,
colsample_bylevel: Optional[float] = None,
colsample_bynode: Optional[float] = None,
reg_alpha: Optional[float] = None,
reg_lambda: Optional[float] = None,
scale_pos_weight: Optional[float] = None,
base_score: Optional[float] = None,
random_state: Optional[Union[np.random.RandomState, int]] = None,
missing: float = np.nan,
num_parallel_tree: Optional[int] = None,
monotone_constraints: Optional[Union[Dict[str, int], str]] = None,
interaction_constraints: Optional[Union[str, Sequence[Sequence[str]]]] = None,
importance_type: Optional[str] = None,
gpu_id: Optional[int] = None,
validate_parameters: Optional[bool] = None,
predictor: Optional[str] = None,
enable_categorical: bool = False,
feature_types: FeatureTypes = None,
max_cat_to_onehot: Optional[int] = None,
max_cat_threshold: Optional[int] = None,
eval_metric: Optional[Union[str, List[str], Callable]] = None,
early_stopping_rounds: Optional[int] = None,
callbacks: Optional[List[TrainingCallback]] = None,
**kwargs: Any,
) -> None:5、模型的推理与评价
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc
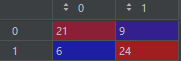
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
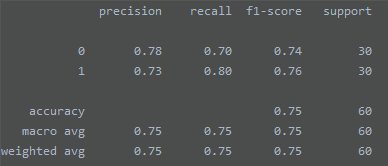
cr = classification_report(y_test, y_pred) # 分类报告
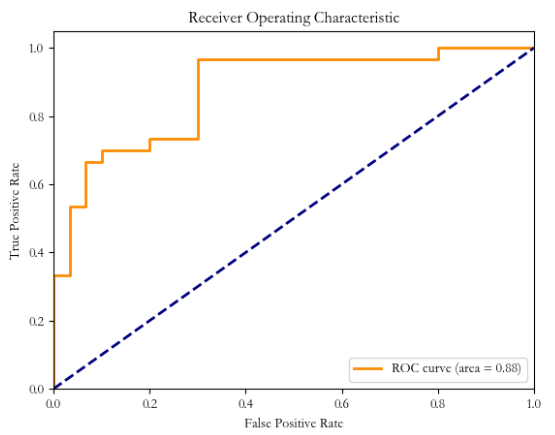
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()cm:
cr:
ROC:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。















 7028
7028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











