







简 介
XGBoost是一种强大的机器学习算法,它在许多领域都取得了广泛的应用,包括临床医学。本文将介绍XGBoost模型的原理和概念,并通过一些具体的临床医学实例来展示其在这个领域的应用。
XGBoost模型的原理和概念
XGBoost全称为eXtreme Gradient Boosting,是一种基于梯度提升决策树(Gradient Boosting Decision Tree)的集成学习算法。它在GBDT的基础上进行了改进,引入了正则化项和二阶导数信息,提高了模型的性能和泛化能力。
XGBoost模型的核心思想是将多个弱分类器(决策树)组合成一个强分类器。每个决策树都在前一棵树的残差基础上进行训练,通过不断迭代优化损失函数来逐步减小残差。同时,模型通过控制树的复杂度和正则化项来减少过拟合风险。
模型构建的具体步骤
XGBoost模型的构建通常包括以下步骤:
a). 数据预处理:首先,需要对原始数据进行清洗和预处理。这包括处理缺失值、处理异常值、特征选择、数据标准化等操作。
b). 划分训练集和测试集:为了评估模型的性能,需要将数据集划分为训练集和测试集。通常,80%的数据用于训练,20%的数据用于测试。
c). 参数调优:XGBoost模型中有许多参数可以调整,如学习率、树的数量、树的深度等。通过交叉验证和网格搜索等技术,可以找到最优的参数组合。
d). 训练模型:使用训练集进行模型训练。XGBoost模型会根据损失函数的定义逐步优化分类器,生成多个决策树模型。
e). 模型评估:使用测试集对训练好的模型进行评估。常见的评估指标包括准确率、精确率、召回率、F1值等。
f). 模型应用:一旦模型被训练和验证通过,就可以将其应用于实际临床数据中,进行预测和决策支持。
XGBoost在临床医学中的应用
XGBoost算法在临床医学中有着广泛的应用。以下是一些具体的实例:
a). 疾病诊断:XGBoost模型可以使用患者的临床特征和医学检查结果来预测某种疾病的发生概率。例如,可以利用患者的年龄、性别、血液指标等特征,建立一个XGBoost模型来预测心脏病的风险。
b). 药物响应预测:XGBoost可以通过分析患者的基因信息以及其他关键特征,来预测某种药物对患者的治疗效果。这可以帮助医生选择最适合患者的治疗方案,提高治疗成功率。
c). 生存分析:在肿瘤学中,XGBoost模型可以通过分析患者的临床特征和病理学信息,来预测患者的生存期或复发风险。这有助于医生为患者制定个性化的治疗方案。
d). 医疗资源优化:XGBoost模型可以通过分析大量的临床数据,预测患者的住院时间、手术风险等信息,帮助医疗机构进行资源分配和管理。
XGBoost与随机森林的比较
XGBoost和随机森林都是常用的集成学习算法,它们在处理分类和回归问题时都表现出色。下面是它们之间的一些比较和优劣对比:
a). 模型结构:随机森林由多个决策树组成,每个树独立生成。而XGBoost是将多个决策树串联起来,每个树在前一棵树的残差基础上生成。因此,XGBoost模型具有更强的拟合能力和泛化能力。
b). 可解释性:随机森林可以提供特征的重要性排序,便于理解和解释。而XGBoost在模型复杂度较高时,特征的重要性难以解释。
c). 效果:一般情况下,XGBoost相对于随机森林的效果更好。它能更准确地捕捉数据中的非线性关系和交互作用。
d). 计算效率:相对于随机森林,XGBoost模型需要更多的计算资源和时间,特别是在大规模数据集上。因此,对于小规模数据集或者追求快速训练的任务,随机森林可能更合适。
之前我们有介绍过基于机器学习xgboost软件包中的MachineLearning 9. 癌症诊断机器学习之梯度提升算法(Gradient Boosting)
今天介绍R语言中使用xgboost实现生存分析!!!
软件包安装
if(!require(xgboost))
install.packages("xgboost")数据读取
library(xgboost)
library(survival)
library(survminer)
library(sampling)
head(lung)
## inst time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
## 1 3 306 2 74 1 1 90 100 1175 NA
## 2 3 455 2 68 1 0 90 90 1225 15
## 3 3 1010 1 56 1 0 90 90 NA 15
## 4 5 210 2 57 1 1 90 60 1150 11
## 5 1 883 2 60 1 0 100 90 NA 0
## 6 12 1022 1 74 1 1 50 80 513 0
table(lung$status)
##
## 1 2
## 63 165
lung$status <- ifelse(lung$status == 2, 1, 0)
lung <- na.omit(lung) # 去掉NA
set.seed(123)
# 每层抽取70%的数据
train_id <- strata(lung, "status", size = rev(round(table(lung$status) * 0.7)))$ID_unit
# 训练数据
trainData <- lung[train_id, ]
# 测试数据
testData <- lung[-train_id, ]实例操作
数据格式要设置为xgboost的专用格式,生存分析要注意因变量的设置。直接用Surv是不行的,xgboost中会把生存时间为负值的当做是删失,所以我们设置y时要如下设置:
# 准备预测变量和结果变量
train.x <- as.matrix(trainData[, c("age", "sex", "ph.ecog", "ph.karno", "pat.karno")])
# 设置y,把删失的改成负值
train.y <- ifelse(trainData$status == 1, trainData$time, -trainData$time)
# 放进专用的格式中
trainMat <- xgb.DMatrix(data = train.x, label = train.y)
trainMat
## xgb.DMatrix dim: 117 x 5 info: label colnames: yes选择参数的值
设置xgboost的参数,生存分析需要设置两个主要的参数:
objective = "survival:cox";
eval_metric = "cox-nloglik"。
参数设置可以参考在线说明:https://xgboost.readthedocs.io/en/latest/parameter.html
param <- list(objective = "survival:cox",
booster = "gbtree",
eval_metric = "cox-nloglik",
eta = 0.03,
max_depth = 3,
subsample = 1,
colsample_bytree = 1,
gamma = 0.5)模型构建
构建模型,并在测试集上,计算风险分数:
set.seed(1)
xgb.fit <- xgb.train(params = param, data = trainMat, nrounds = 1000, watchlist = list(val2 = trainMat),
early_stopping_rounds = 50)
## [1] val2-cox-nloglik:3.804010
## Will train until val2_cox_nloglik hasn't improved in 50 rounds.
riskScore <- predict(xgb.fit, newdata = train.x) # newdata如果是训练集可以获取训练集的风险分数
hist(riskScore)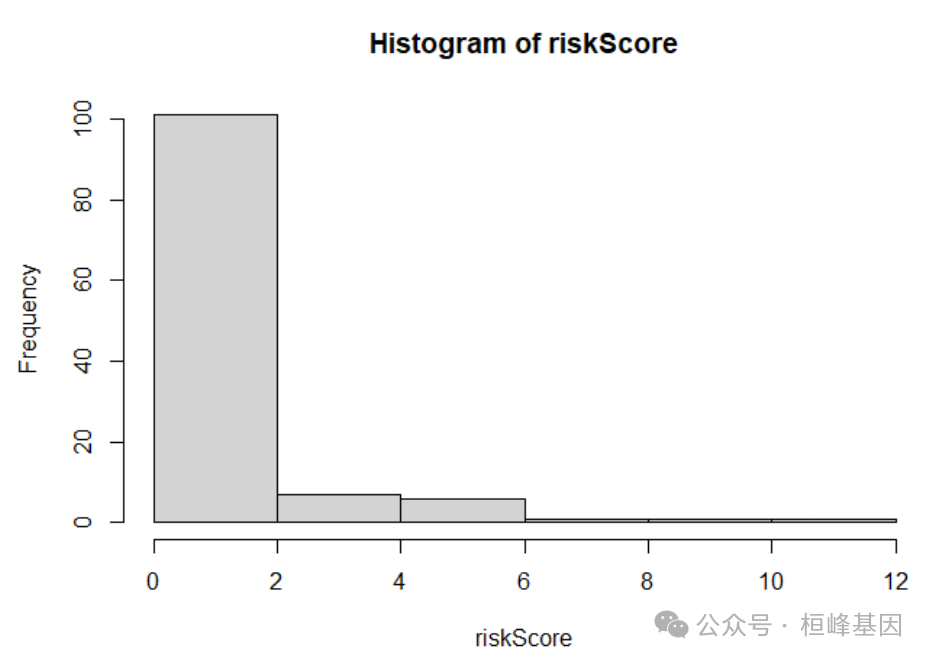
生存分析
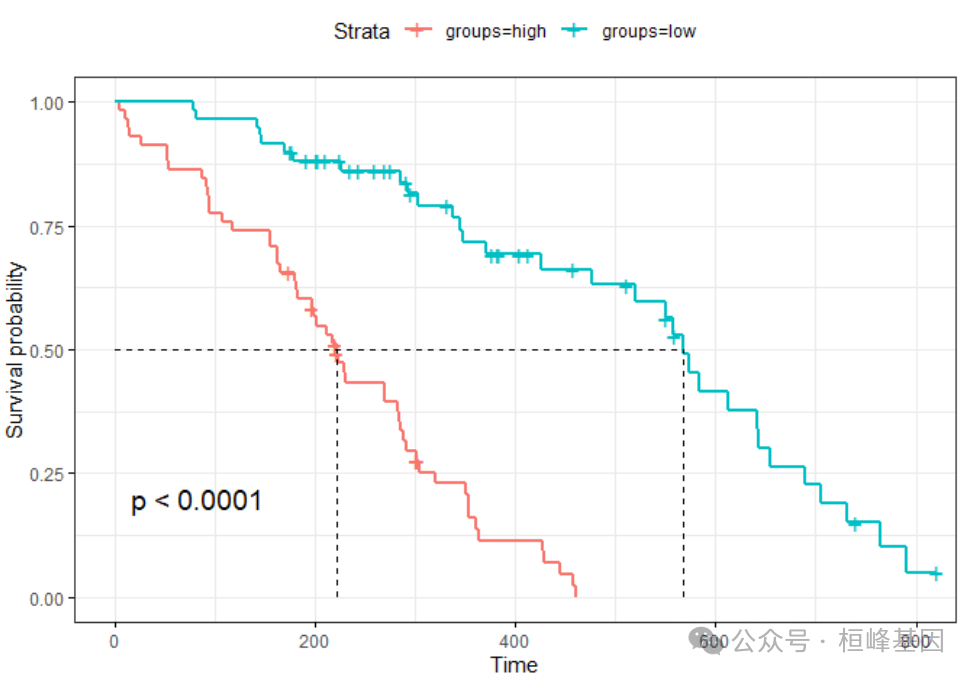
根据风险分数,将其分为两组,并进行生存分析:
# 根group建立生存函数
groups <- ifelse(riskScore>median(riskScore),"high","low")
f <- survfit(Surv(trainData$time, trainData$status) ~ groups)
f
## Call: survfit(formula = Surv(trainData$time, trainData$status) ~ groups)
##
## n events median 0.95LCL 0.95UCL
## groups=high 58 52 222 183 285
## groups=low 59 32 567 477 655
ggsurvplot(f,
data = trainData,
surv.median.line = "hv",
#legend.title = "Risk Group",
#legend.labs = c("Low Risk", "High Risk"),
pval = TRUE,
ggtheme = theme_bw()
)
计算一致性 C-Index
library(Hmisc)
rcorr.cens(as.numeric(riskScore), Surv(trainData$time, trainData$status))
## C Index Dxy S.D. n missing
## 1.952494e-01 -6.095013e-01 5.288494e-02 1.170000e+02 0.000000e+00
## uncensored Relevant Pairs Concordant Uncertain
## 8.400000e+01 1.014600e+04 1.981000e+03 3.416000e+03可视化变量
从图上我们可以出前几个重要的变量占比几乎达到0.3,这个阈值是在之前grid网格中设置:eta = c(0.01, 0.1, 0.3), #0.3 is default。
impMatrix <- xgb.importance(feature_names = dimnames(train.x)[[2]], model = xgb.fit)
impMatrix
## Feature Gain Cover Frequency
## 1: age 0.4117109 0.4324245 0.50605536
## 2: sex 0.1811799 0.1422414 0.10986159
## 3: ph.karno 0.1690779 0.1238643 0.09083045
## 4: pat.karno 0.1221485 0.1650383 0.19809689
## 5: ph.ecog 0.1158828 0.1364314 0.09515571
xgb.plot.importance(impMatrix, main = "Gain by Feature")
模型性能评估
test.x <- as.matrix(testData[, c("age","sex","ph.ecog","ph.karno","pat.karno")])
riskScore <- predict(xgb.fit, newdata = test.x) # newdata如果是训练集可以获取训练集的风险分数
hist(riskScore)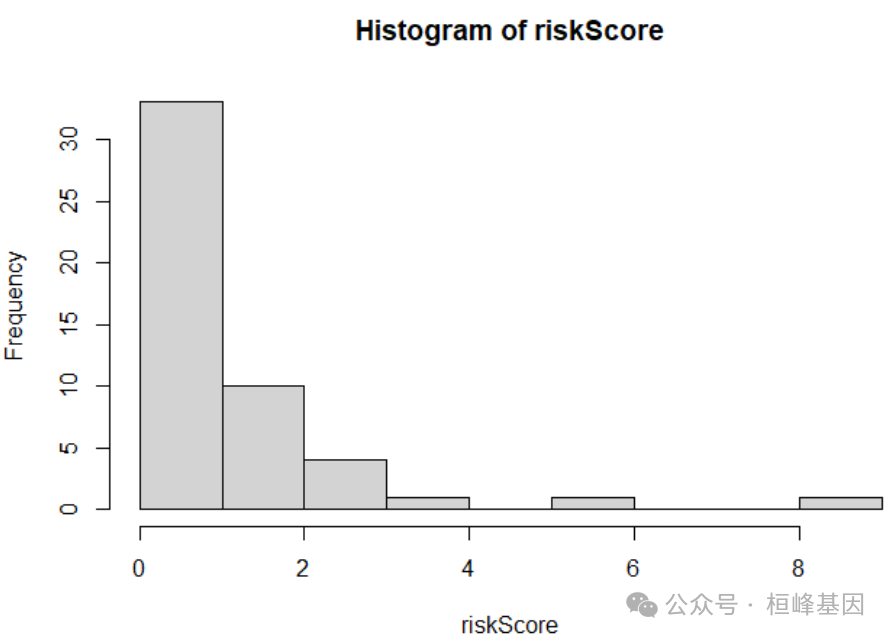
最后就是模型的准确性评估,这里我们使用的是ROCR软件包绘制ROC曲线,如下:
testData$predProb <- predict(xgb.fit, newdata = test.x, type = "prob")
testData$predicted = predict(xgb.fit, test.x)
library(ROCR)
pred = prediction(testData$predicted, testData$status)
perf = performance(pred, measure = "fpr", x.measure = "tpr")
plot(perf, lwd = 2, col = "blue", main = "ROC")
abline(a = 0, b = 1, col = 2, lwd = 1, lty = 2)
text(0.5, 0.5, "C-Index=0.628")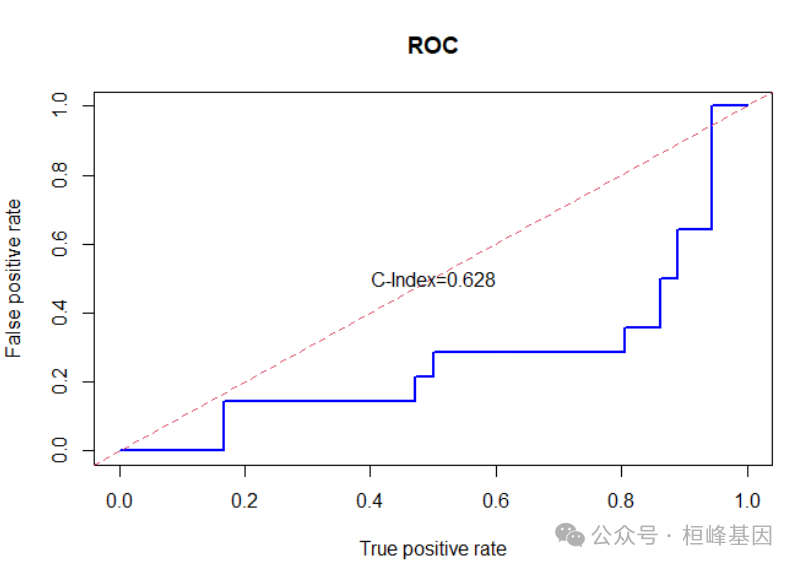
Reference
Tianqi Chen and Carlos Guestrin, "XGBoost: A Scalable Tree Boosting System", 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, 2016, https://arxiv.org/abs/1603.02754
基于机器学习构建临床预测模型
MachineLearning 2. 因子分析(Factor Analysis)
MachineLearning 3. 聚类分析(Cluster Analysis)
MachineLearning 4. 癌症诊断方法之 K-邻近算法(KNN)
MachineLearning 5. 癌症诊断和分子分型方法之支持向量机(SVM)
MachineLearning 6. 癌症诊断机器学习之分类树(Classification Trees)
MachineLearning 7. 癌症诊断机器学习之回归树(Regression Trees)
MachineLearning 8. 癌症诊断机器学习之随机森林(Random Forest)
MachineLearning 9. 癌症诊断机器学习之梯度提升算法(Gradient Boosting)
MachineLearning 10. 癌症诊断机器学习之神经网络(Neural network)
MachineLearning 11. 机器学习之随机森林生存分析(randomForestSRC)
MachineLearning 12. 机器学习之降维方法t-SNE及可视化(Rtsne)
MachineLearning 13. 机器学习之降维方法UMAP及可视化 (umap)
MachineLearning 14. 机器学习之集成分类器(AdaBoost)
MachineLearning 15. 机器学习之集成分类器(LogitBoost)
MachineLearning 16. 机器学习之梯度提升机(GBM)
MachineLearning 17. 机器学习之围绕中心点划分算法(PAM)
MachineLearning 18. 机器学习之贝叶斯分析类器(Naive Bayes)
MachineLearning 19. 机器学习之神经网络分类器(NNET)
MachineLearning 20. 机器学习之袋装分类回归树(Bagged CART)
号外号外,桓峰基因单细胞生信分析免费培训课程即将开始快来报名吧!
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
桓峰基因官网正式上线,请大家多多关注,还有很多不足之处,大家多多指正!http://www.kyohogene.com/
桓峰基因和投必得合作,文章润色优惠85折,需要文章润色的老师可以直接到网站输入领取桓峰基因专属优惠券码:KYOHOGENE,然后上传,付款时选择桓峰基因优惠券即可享受85折优惠哦!https://www.topeditsci.com/


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









