







这是我的第326篇原创文章。
一、引言
- 检索增强生成(Retrieval-Augmented Generation,RAG)
- RAG借助**外挂的知识库**来为大语言模型提供准确和最新的知识,以提升大语言模型生成内容的质量,减少错误内容的产生。RAG允许对新增数据部分使用相同的模型处理,而无需调整及微调模型,从而极大地拓展了大模型的可用性。
- RAG提供了一个有效的方式来解决在特定领域的问答,主要将行业知识转化为向量进行存储和检索,**通过知识检索的结果与用户问题结合形成Prompt**,最后利用大模型生成合适的回答。
- 实现原理
- 加载本地文档 -> 文本分割 -> 文本向量化 -> question向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答
二、实现过程
2.1 文档加载
创建一个PyMuPDFLoader实例,输入为待加载的pdf文档路径:
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")调用PyMuPDFLoader实例的load方法加载整个文档:
pages = loader.load()
print(f'载入后的变量类型为:{type(pages)},', f"该PDF一共包含{len(pages)}页")结果:
![]()
可见pages是一个列表,列表的长度就是pdf文档的页数。我们看一下第一个元素:
page = pages[1]
print(f"每个元素的类型为:{type(page)}",
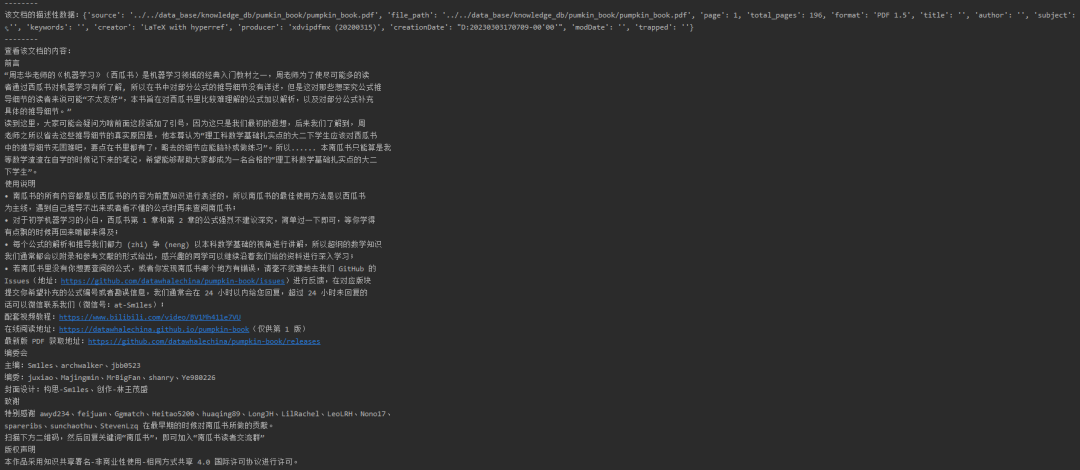
f"该文档的描述性数据:{page.metadata}",
f"查看该文档的内容:\n{page.page_content}",
sep="\n--------\n")列表每个元素的类型是一个langchain.schema.document.Document。第一页的描述性数据和文档内容如下:
2.2 文档分割
声明一个RecursiveCharacterTextSplitter实例:
# 知识库中单段文本长度
CHUNK_SISE = 500
# 知识库中相似文本重合长度
OVERLAP_SIZE = 50
# 声明一个RecursiveCharacterTextSplitter实例
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SISE, chunk_overlap=OVERLAP_SIZE)对整个文档pages进行分割:
split_docs = text_splitter.split_documents(pages)
print(split_docs) # 是一个列表
print(f"分割后的块数:{len(split_docs)}")
print(f"分割后的字符数(可以用来大致评估token数):{sum([len(doc.page_content) for doc in split_docs])}")split_docs是一个列表,每一个元素式分割后的一小块:
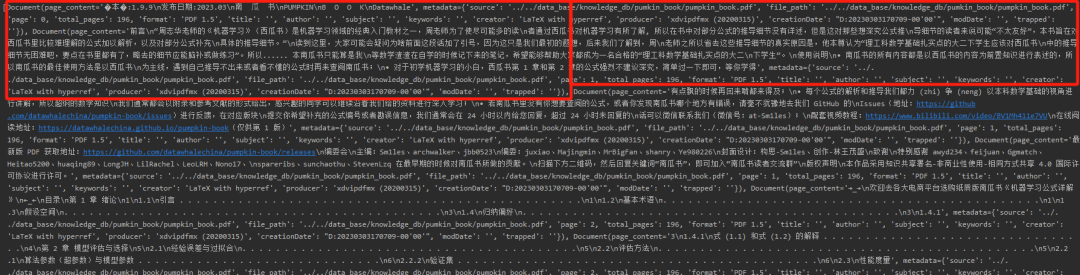
这个文档总共被分割为737块,分割后的总字符数为314699。
![]()
2.3 文档词向量化
对词进行向量化,需要选择一个embeddings模型,这里我们采用HuggingFaceEmbeddings,我们拿两个词来看看如何向量化的,向量化的形式是咋样的:
# 定义Embeddings
embedding = HuggingFaceEmbeddings(model_name="moka-ai/m3e-base")
query1 = '机器学习'
query2 = '强化学习'
emb1 = embedding.embed_query(query1)
emb2 = embedding.embed_query(query2)
print(emb1)
print(emb2)
# 计算两个词向量的相关性
import numpy as np
emb1 = np.array(emb1)
emb2 = np.array(emb2)
print(f"{query1}和{query2}向量之间的点积为:{np.dot(emb1, emb2)}")query1和query2经过embedding分别变为emb1和emb2,变成了一个向量(数组),通过计算向量之间的点积可以判断query1和query2的相关性:
![]()
2.4 构建向量数据库
现在我们对分割后的文档(文本块)进行向量化,并写入保存到向量数据库中:
persist_directory = "../../data_base/vector_db/chroma"
# vectordb = Chroma.from_documents(
# documents=split_docs[:100],
# embedding=embedding,
# persist_directory=persist_directory)
#
# vectordb.persist() # 持久化向量数据库这里,我们只取了前100个文本块进行向量化存储,如果之前已经构建过向量数据库,则可以直接加载:
# 直接加载已经构建好的向量数据库
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
# 查看向量数据库的存储的数量
print(f"存储向量的数量:{vectordb._collection.count()}")结果:这里我们只对前100个文本块进行向量化,因此存储的向量的数量是100。
![]()
2.5 通过向量数据库检索
接下来,我们就可以通过一个prompt,去到向量数据库中检索与之最相关的n条内容:
question = "什么是机器学习?"
sim_docs = vectordb.similarity_search(question, k=3)
print(f"检索到的内容数:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):
print(f"检索到第{i}个内容:\n{sim_doc.page_content[:200]}", end="\n----------\n")这里我的问题是“什么是机器学习?”,去检索向量数据库中与之相近的内容:



2.6 定义大模型
需要创建一个大模型对象,如果我们本地部署了大模型,可以直接调用本地的大语言模型,或者采用api的方式进行调用:
# # 使用huggingfacepipeline本地搭建大语言模型
# model_id = "THUDM/chatglm2-6b-int4"
# tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
# model = AutoModel.from_pretrained(model_id, trust_remote_code=True).half().quantize(4).cuda()
# model = model.eval()
# pipe = pipeline('text2text-generation', model, tokenizer, maxlength=100)
# llm = HuggingFacePipeline(pipeline=pipe)
# 使用OpenAI的大语言模型
# 获取环境变量 OPENAI_API_KEY
# _ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']
# openai.api_key = os.environ['OPENAI_API_KEY']
# llm = OpenAI(model_name="gpt-4", temperature=0)
# 使用智谱AI的大模型
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']
zhipuai.api_key = os.environ['ZHIPUAI_API_KEY']
llm = ZhipuAILLM(model="chatglm_std", temperature=0)2.7 构造检索式问答链
首先声明一个检索问答链:
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectordb.as_retriever())进行问答:
question = '机器学习是什么'
result = qa_chain({"query": question})
print(f'大语言模型的回答为:{result["result"]}')大语言模型的回答为:机器学习是一门研究如何让计算机通过数据学习、提高性能的科学。它涉及到许多领域,如统计学、计算机科学、人工智能等。机器学习的目标是开发新的算法和模型,使计算机能够在没有明确编程的情况下,根据数据自动识别模式、进行预测和决策。
![]()
结合prompt声明一个检索式问答链:
# 建立一个prompt模板
template = """使用以下上下文片段来回答最后的问题。如果你不知道答案,只需说不知道,不要试图编造答案,答案最多使用三个句子。尽量简明扼要地回答。在回答的最后一定要说"感谢您的提问"{context}问题:{question}有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)进行问答:
question = '2025年大语言模型最好的是哪个模型?'
result = qa_chain({"query": question})
print(f'大语言模型的回答为:{result["result"]}')大语言模型的回答为:您提到的章节和内容似乎是关于机器学习的不同主题和方法。然而,关于2025年大语言模型的最佳模型,由于我是一个AI助手,无法预测未来的具体情况。在2025年,可能会有许多新的模型和技术出现,而最佳模型将取决于许多因素,如准确性、性能、适应性和可用性。因此,很难确定哪个模型将是最好的。感谢您的提问。
![]()
2.8 构造对话检索链
声明一个对话检索链需要先声明一个记忆对象,然后将这个对象传入到这个链中:
# 声明一个记忆对象
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 声明一个对话检索链
from langchain.chains import ConversationalRetrievalChain
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectordb.as_retriever(),
memory=memory
)提出一个无历史对话的问题,并查看回答:
question = "我可以学习到关于强化学习的知识嘛?"
result = qa({"question": question})
print(f'大语言模型的回答为:{result["answer"]}')大语言模型的回答为:是的,你可以从南瓜书中学习到关于强化学习的知识。南瓜书是对西瓜书《机器学习》的补充,提供了更详细的公式推导和解析。在第16章,它涵盖了强化学习的相关内容,如任务与奖赏等。你可以在学习强化学习时,结合南瓜书进行查阅和理解。
![]()
基于答案进行下一个问题,并查看回答:
question = "为什么要学习这方面的知识?"
result = qa({'question': question})
print(f'大语言模型的回答为:{result["answer"]}')![]()
大语言模型的回答为:强化学习是一种人工智能的算法,它可以帮助计算机代理在特定环境中根据其行为获得奖励或惩罚,从而学习如何做出最优的决策。学习强化学习的知识可以帮助我们更好地理解这种算法的工作原理,以及如何应用它来解决实际问题。强化学习在很多领域都有应用,比如自动驾驶、游戏控制、推荐系统等,因此学习强化学习的知识对于人工智能的发展和应用具有重要意义。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。


















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











