






Unsupervised Multi-source Domain Adaptation Without Access to Source Data
CVPR 2021 · Sk Miraj Ahmed, Dripta S. Raychaudhuri, Sujoy Paul, Samet Oymak, Amit K. Roy-Chowdhury ·
代码链接:https://github.com/driptaRC/DECISION

上图为论文的问题设置。标准的无监督多源域自适应(UDA)利用源数据以及在源上训练的模型,在目标域上执行自适应。相反,而论文作者引入了一种设置,它可以适应多个模型,而不需要访问源数据。
作者提出的算法:基于伪标签(pseude-labeling)和信息最大化(information maximization)。并使用直观的理论,展现了提出的框架优于最佳可用源,并最小化了负迁移的影响。
为了解决不访问源数据的多源模型自适应问题,作者将信息最大化损失部署在 所有源模型 加权组合上???
主要贡献:解决了多源无监督领域自适应,且不访问源于数据的问题。对于解决此问题,有以下贡献:
- 提出不需要访问源域数据的UDA算法。算法通过优化一个设计好的无监督损失,自动识别最优混合源模型来生成目标模型。
- 在直观的假设下,作者建立了目标模型性能的理论保证,表明它始终至少与部署单一最佳源模型一样好,从而最大限度地减少负迁移
- 通过大量的数值实验展现了方法的优异性。
Related works
Multi-source domain adaptation
多源领域自适应(MSDA)通过合并来自多个源模型的知识,扩展了标准的UDA。
- 隐子空间迁移法旨在通过优化差异度量(discrepancy measure)或对抗性损失(adversarial loss)来对齐不同领域的特征。
- 基于差异的方法通过最小化度量,如最大均值差异(maximum mean discrepancy),瑞丽熵(Renyi-divergence)来对齐域。
- 对抗性方法旨在通过优化GAN loss, H \mathcal{H} H-divergence,Wasserstein distance使多个域的特征无法区分为域鉴别器。
- 域生成方法[36,24]使用某种形式的域转化,如CycleGAN[51],在像素级进行自适应。
所有这些方法都假设在适配期间访问源数据。
Methodology
问题设置
作者解决了在不同领域训练的多个模型联合适应一个新的目标领域的问题,该问题只访问目标域样本,而不需要来自目标域的标注。在此工作中,考虑有
K
K
K类,输入空间为
X
\mathcal{X}
X的分类模型的适应。考虑有一组源域模型
{
θ
S
j
}
j
=
1
n
\{\theta^{j}_{S}\}^{n}_{j=1}
{θSj}j=1n,其中,
j
t
h
j^{th}
jth模型
θ
S
j
:
X
→
R
K
\theta^{j}_{S}:\mathcal{X}\rarr \mathbb{R}^{K}
θSj:X→RK是一个使用源域数据
D
S
i
=
{
x
S
j
i
,
y
S
j
i
}
i
=
1
N
j
\mathcal{D}_{S}^{i}=\{x^{i}_{S_{j}},y^{i}_{S_{j}}\}_{i=1}^{N_{j}}
DSi={xSji,ySji}i=1Nj学习到的分类模型,
N
j
N_{j}
Nj代表数据点,
x
S
j
i
x^{i}_{S_{j}}
xSji和
y
S
j
i
y^{i}_{S_{j}}
ySji分别代表第
i
i
i个源域图像和相应的标签。现在有无标签的目标域数据集
D
T
=
{
x
T
i
}
i
=
1
N
T
\mathcal{D}_{T}=\{x_{T}^{i}\}_{i=1}^{N_{T}}
DT={xTi}i=1NT,目标(问题)是不使用源域的数据,只用学习到的源域模型,去学习分类模型
θ
T
:
X
→
R
K
\theta_{T}:\mathcal{X}\rarr\mathbb{R}^{K}
θT:X→RK。这与文献中的多源领域自适应的方法不同,因为它们在学习目标域模型
θ
T
\theta_{T}
θT的时候,还使用了源域数据。
总体框架
可以将源域模型分解为两个模块:①特征提取器
ϕ
S
i
:
X
→
R
d
i
\phi_{S}^{i}:\mathcal{X}\rarr \mathbb{R}^{d_{i}}
ϕSi:X→Rdi ②分类器
ψ
S
i
:
R
d
i
−
R
K
\psi_{S}^{i}:\mathbb{R}^{d_{i}}-\mathbb{R}^{K}
ψSi:Rdi−RK,此处
d
i
d_{i}
di表示第i个模型的特征维度,
K
K
K代表类别数。目标是通过只结合来自给定源模型的知识来估计目标模型
θ
T
\theta_{T}
θT,同时自动剔除与目标域无关的源域模型。
论文框架的核心是一个模型聚合方案,即学习一组对应于每个源域模型的权重值
{
α
i
}
i
=
1
n
\{\alpha_{i}\}_{i=1}^{n}
{αi}i=1n。这些权重表示源域中的概率质量函数(probability mass function),值越高,表示该特定领域的可转移性越高,并据此组合源假设。然而,与之前的工作不同的是,论文联合适应每个单独的模型,同时通过使用未标记的目标实例来学习这些权重。
Weighted Information Maximization
由于无法访问已标记的源域或目标域的数据标签,作者选择固定源分类器
{
ψ
S
i
}
i
=
1
n
\{\psi_{S}^{i}\}_{i=1}^{n}
{ψSi}i=1n,因为它包含源域的类分布信息,并通过信息最大化的原则,它只适应于特征映射
{
ϕ
S
i
}
i
=
1
n
\{\phi_{S}^{i}\}_{i=1}^{n}
{ϕSi}i=1n。作者的自适应过程背后的动机来源于半监督学习中的聚类假设[5],据该假设,决策边界就应该尽量通过数据较为稀疏的地方,从而避免把稠密的聚类中的数据点分到决策边界两侧。在这一假设下,大量未标记示例的作用就是帮助探明示例空间中数据分布的稠密和稀疏区域,从而指导学习算法对利用有标记示例学习到的决策边界进行调整,使其尽量通过数据分布的稀疏区域。为了达到这个目的,作者最小化条件熵(conditional entropy):
L
ent
=
−
E
x
T
∈
D
T
[
∑
j
=
1
K
δ
j
(
θ
T
(
x
T
)
)
log
(
δ
j
(
θ
T
(
x
T
)
)
)
]
(1)
\mathcal{L}_{\text {ent }}=-\mathbb{E}_{x_{T} \in \mathcal{D}_{T}}\left[\sum_{j=1}^{K} \delta_{j}\left(\theta_{T}\left(x_{T}\right)\right) \log \left(\delta_{j}\left(\theta_{T}\left(x_{T}\right)\right)\right)\right] \tag{1}
Lent =−ExT∈DT[j=1∑Kδj(θT(xT))log(δj(θT(xT)))](1)
Weighted Pseudo-labeling
由于领域漂移(domain shift),信息最大化可能会导致某些实例被错误的类集群所绑定由于领域的转移,信息最大化可能会导致某些实例被错误的类集群所绑定。这些错误的预测会在训练过程中得到强化,并导致一种被称为确认偏差(confirmation bias)的现象。作者为了抑制这种效果,采用了一种自监督聚类策略,该策略灵感来自于DeepCluster技术。
首先,计算每个源模型对整个目标数据集的聚类中心:
μ k j ( 0 ) = ∑ x T ∈ D T δ k ( θ ^ S j ( x T ) ) ϕ ^ S j ( x T ) ∑ x T ∈ D T δ k ( θ ^ S j ( x T ) ) (4) \mu_{k_{j}}^{(0)}=\frac{\sum_{x_{T} \in \mathcal{D}_{T}} \delta_{k}\left(\hat{\theta}_{S}^{j}\left(x_{T}\right)\right) \hat{\phi}_{S}^{j}\left(x_{T}\right)}{\sum_{x_{T} \in \mathcal{D}_{T}} \delta_{k}\left(\hat{\theta}_{S}^{j}\left(x_{T}\right)\right)} \tag{4} μkj(0)=∑xT∈DTδk(θ^Sj(xT))∑xT∈DTδk(θ^Sj(xT))ϕ^Sj(xT)(4)
其中,由源 j j j 在迭代 i i i 处得到的类 k k k 的簇心记为 μ k j ( i ) \mu_{k_j}^{(i)} μkj(i), θ ^ S j = ( ψ S j ◦ ϕ S j ) \hatθ_{S}^{j} = (ψ_{S}^{j}◦\phi^{j}_{S}) θ^Sj=(ψSj◦ϕSj)表示前一次迭代的源。
根据每个源模型的当前聚合权值,这些特定于源的中心将进行组合:
μ
k
(
0
)
=
∑
j
=
1
n
α
j
μ
k
j
(
0
)
(5)
\mu_{k}^{(0)}=\sum_{j=1}^{n} \alpha_{j}\mu_{k_{j}}^{(0)}\tag{5}
μk(0)=j=1∑nαjμkj(0)(5)
接下来,通过将每个样本分配到特征空间中最接近的聚类中心来计算其伪标签:
y
^
T
(
0
)
=
arg
min
k
∥
θ
^
T
(
x
T
)
−
μ
k
(
0
)
∥
2
2
(6)
\hat{y}_{T}^{(0)}=\arg \min _{k}\left\|\hat{\theta}_{T}\left(x_{T}\right)-\mu_{k}^{(0)}\right\|_{2}^{2}\tag{6}
y^T(0)=argkmin∥∥∥θ^T(xT)−μk(0)∥∥∥22(6)
重复这个过程以获得更新后的中心和伪标签:
μ
k
j
(
1
)
=
∑
x
T
∈
D
T
1
{
y
^
T
(
0
)
=
k
}
ϕ
^
S
j
(
x
T
)
∑
x
T
∈
D
T
1
(
y
t
^
0
=
k
)
(7)
\mu_{k_{j}}^{(1)}=\frac{\sum_{x_{T} \in \mathcal{D}_{T}} \mathbb{1}\left\{\hat{y}_{T}^{(0)}=k\right\} \hat{\phi}_{S}^{j}\left(x_{T}\right)}{\sum_{x_{T} \in \mathcal{D}_{T}} \mathbb{1}\left(y^{\hat{t}_{0}}=k\right)}\tag{7}
μkj(1)=∑xT∈DT1(yt^0=k)∑xT∈DT1{y^T(0)=k}ϕ^Sj(xT)(7)
μ k ( 1 ) = ∑ j = 1 n α j μ k j ( 1 ) (8 ) \mu_{k}^{(1)}=\sum_{j=1}^{n} \alpha_{j}\mu_{k_{j}}^{(1)}\tag{8 } μk(1)=j=1∑nαjμkj(1)(8 )
y ^ T ( 1 ) = arg min k ∥ θ ^ T ( x T ) − μ k ( 1 ) ∥ 2 2 (9) \hat{y}_{T}^{(1)}=\arg \min _{k}\left\|\hat{\theta}_{T}\left(x_{T}\right)-\mu_{k}^{(1)}\right\|_{2}^{2}\tag{9} y^T(1)=argkmin∥∥∥θ^T(xT)−μk(1)∥∥∥22(9)
其中 1(·) 是一个指示函数,当自变量为真时给出值为1。虽然这种计算集群中心和伪标签的交替过程可以重复多次,以获得固定的伪标签,但一次就足够了。然后得到了这些伪标签的交叉熵损失
L
p
l
(
Q
T
,
θ
T
)
=
−
E
x
T
∈
D
T
∑
k
=
1
K
1
{
y
^
T
=
k
}
log
δ
k
(
θ
T
(
x
T
)
)
(10)
\mathcal{L}_{\mathrm{pl}}\left(Q_{T}, \theta_{T}\right)=-\mathbb{E}_{x_{T} \in \mathcal{D}_{T}} \sum_{k=1}^{K} \mathbb{1}\left\{\hat{y}_{T}=k\right\} \log \delta_{k}\left(\theta_{T}\left(x_{T}\right)\right)\tag{10}
Lpl(QT,θT)=−ExT∈DTk=1∑K1{y^T=k}logδk(θT(xT))(10)
在第5节中讨论的特定次数的迭代之后,伪标签会定期更新.
Optimization
总结下来,给定 n 个源域假设
{
θ
^
S
j
}
j
=
1
n
=
{
ψ
S
j
◦
ϕ
S
j
}
j
=
1
n
\{\hatθ_{S}^{j}\}^{n}_{j=1} = \{ψ_{S}^{j}◦\phi^{j}_{S}\}_{j=1}^{n}
{θ^Sj}j=1n={ψSj◦ϕSj}j=1n和目标域数据
D
T
=
{
x
T
i
}
n
=
1
n
T
\mathcal{D}_{T}=\{x_{T}^{i}\}_{n=1}^{n_{T}}
DT={xTi}n=1nT,我们固定来自于每个sourced 分类器,并优化参数
{
ϕ
S
j
}
j
=
1
n
\{\phi _{S}^{j}\}_{j=1}^{n}
{ϕSj}j=1n和聚合的权重
{
α
j
}
j
=
1
n
\{α_j\}^n_{j=1}
{αj}j=1n.最终的目标函数如下:
L
t
o
t
=
L
e
n
t
−
L
d
i
v
+
λ
L
p
l
(11)
\mathcal{L}_{tot}=\mathcal{L}_{\mathrm{ent}}- \mathcal{L}_{\mathrm{div}}+ \lambda\mathcal{L}_{\mathrm{pl}}\tag{11}
Ltot=Lent−Ldiv+λLpl(11)
利用上述目标求解以下优化问题
{
ϕ
S
j
}
j
=
1
n
,
{
α
j
}
j
=
1
n
L
t
o
t
subject to
α
j
≥
0
,
∀
j
∈
{
1
,
2
,
…
,
n
}
∑
j
=
1
n
α
j
=
1
(12)
\begin{array}{cl}\left\{\phi_{S}^{j}\right\}_{j=1}^{n},\left\{\alpha_{j}\right\}_{j=1}^{n} & \mathcal{L}_{t o t} \\\text { subject to } & \alpha_{j} \geq 0, \forall j \in\{1,2, \ldots, n\} \\& \sum_{j=1}^{n} \alpha_{j}=1\end{array}\tag{12}
{ϕSj}j=1n,{αj}j=1n subject to Ltotαj≥0,∀j∈{1,2,…,n}∑j=1nαj=1(12)
当θT = Pn j=1 αj (ψSj φj S)时,得到了φj S和αj的最优集。为了解决优化(12),作者遵循算法(1)的步骤如下所述。
一旦得到了最优集 ϕ S j ∗ \phi_{S}^{j*} ϕSj∗和 α j ∗ \alpha_{j}^{*} αj∗,最优target hypothesis可以使用 θ T = ∑ j = 1 n α j ∗ ( ψ S j ◦ ϕ S j ∗ ) \theta_{T}=\sum_{j=1}^{n}\alpha_{j}^{*}(\psi_{S}^{j}◦\phi_{S}^{j*}) θT=∑j=1nαj∗(ψSj◦ϕSj∗).
为了解决优化Eq.12,遵循算法(1)的步骤如下所述.
4.Theoretical Insights
本方法背后的理论动机 此算法的目标是找到每个源的最优权值 { α j } j = 1 n \{α_j\}^n_{j=1} {αj}j=1n,并对源预测器进行凸组合,得到目标预测器。在这里,作者将表明,在对源和目标分布的直观假设下,存在一个简单的目标预测器选择,该预测器的性能优于或等于直接应用于目标数据的最佳源模型。
形式上,让
L
L
L 是一个损失函数,它将一对 模型预测的标签 和 真实标签 映射到一个标量。使用源预测的第k个源域分布
Q
S
k
Q_{S}^{k}
QSk的期望损失记为
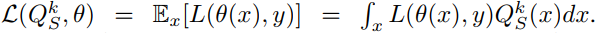
现在让
θ
S
k
\theta_{S}^{k}
θSk为最优的源域预测器,由
θ
S
k
=
a
r
g
m
i
n
θ
L
(
Q
S
k
,
θ
)
∀
1
≤
k
≤
n
\theta_{S}^{k}=arg\ min_{\theta} L(Q_S^k,\theta)\ \forall\ 1≤k≤n
θSk=arg minθL(QSk,θ) ∀ 1≤k≤n.此外还假设目标域的分布在源域分布的跨度里。通过将目标分布表示为源分布的仿射组合来形式化这一点, i.e.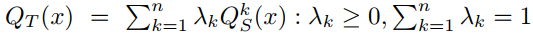
在此假设下,如果将目标域预测器表示为
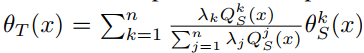
则可以建立Lemma 1.
Lemma 1. 假设损失
L
(
θ
(
x
)
,
y
)
L(\theta(x),y)
L(θ(x),y)是在第一个参数时为凸,并且存在
λ
∈
R
n
,
λ
≥
0
λ
T
1
=
1
\lambda\in \mathbb{R}^{n},\lambda ≥0 \lambda^T \mathbb{1}=1
λ∈Rn,λ≥0λT1=1,则目标域分布等于源域分布的混合,如
∑
i
=
1
n
λ
i
Q
S
i
\sum_{i=1}^{n}\lambda_{i}Q_{S}^{i}
∑i=1nλiQSi.设定目标预测为 最优源域预测的凸组合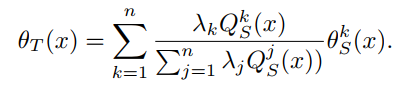 回想一下伪标签损失(10)。在目标分布上,伪标签引起的非监督损失和监督损失均小于或等于最佳源预测器引起的损失,特别地
回想一下伪标签损失(10)。在目标分布上,伪标签引起的非监督损失和监督损失均小于或等于最佳源预测器引起的损失,特别地
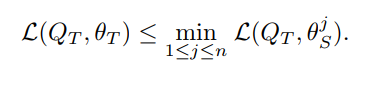














 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









