






Source-Free Domain Adaptation via Distribution Estimation
问题定义
- 无源领域自适应问题:先使用有标签的源域数据计算交叉熵损失训练源域模型至收敛,然后不访问源域的数据,将源域模型迁移到无标签的目标域数据上。
研究动机
- 通常源域数据具有隐私性,不可访问.
- 如果目标域特征很好地与源域对齐,那么源域分类器自然能适用于目标域数据
- 由于源域数据不可访问,目前的无源领域自适应方法大多都是隐式地对齐目标域与源域数据分布
本文中心论点
- 利用源域模型和目标域数据构建源域代理特征,从而使得目标域数据与源域数据显示地对齐。
相关工作进展
-
由于源域与目标域分布不同,因此存在域偏移问题。许多方法试图对齐两个域的分布;
-
有源问题(略):①减小度量差异;②对抗判别;③对抗生成;④半监督学习
-
无源问题: SHOT通过信息最大化隐式地对齐两个域。MA- SFDA和SFDA- SS使用生成模型生成目标域数
据来得到其分布。A2Net引入新的分类器进行对抗训练来对齐源域。SoFA使用变分自编码器来对目标域
进行编码解码来约束隐空间的特征
介绍本工作相比这些工作有什么不同
- 其他方法使用源域模型的输出来分配伪标签,本文使用更稳健的伪标签策略,即spherical K-means聚类
- 提出源域分布估计(Source Distribution Estimation, SDE)来逼近源域分布,然后从中采样出源域代理特
征,从而使目标域分布能显式地估计的源域分布进行对齐,然后适应于源域模型的分类器
创新点
利用了预训练的源域模型的分类器的权重向量(称为锚点)
利用k-means聚类生成鲁棒伪标签,聚类中心初始化为锚点
利用目标域数据和锚点估计源域数据类条件特征分布,并从估计的分布采样出源域代理特征,以对齐两个域

1 利用锚点的伪标签策略
使用伪标签动机
伪标签携带类别信息,一些方法利用分类器输出的高置信度标签作为伪标签。
但在SFDA问题中,直接使用源域模型产生的预测作为伪标签会存在域偏移的问题,导致分配给目标域数据错误
的伪标签。因此选择spherical k-means来给目标域分配伪标签。
首先,得到源域锚点
由线性分类器可以给出类别预测:
y
^
i
=
arg
max
k
f
i
⊤
w
k
G
,
k
∈
C
=
{
1
,
2
,
⋯
,
K
}
(1)
\hat{y}_{i}=\underset{k}{\arg \max } f_{i}^{\top} \mathbf{w}_{k}^{G}, k \in \mathcal{C}=\{1,2, \cdots, K\}\tag{1}
y^i=kargmaxfi⊤wkG,k∈C={1,2,⋯,K}(1)
- y ^ i ∈ R K \hat{y}_{i} \in R^{K} y^i∈RK是softmax之前的logits vector;
- f = F ( x ) ∈ R m f = F(x) ∈R^m f=F(x)∈Rm为m-dimensinal的特征表示;
- w G ∈ R m × K \mathbf{w}^{G}\in R^{m\times K} wG∈Rm×K为分类器G学习到的权重, w k G \mathbf{w}_{k}^{G} wkG是其第k个权重向量;
- w k G \mathbf{w}_{k}^{G} wkG包含可以代表整个k类别的总体特点,因此将其作为类别k的锚点。
将目标域要进行k-means算法的聚类中心初始化为源域锚点
第k类的数据往往会产生激活G中第k个权重向量的表示,所以第k类的特征应该聚集在
w
k
G
\mathbf{w}_{k}^{G}
wkG附近
A
k
(
0
)
=
w
k
G
\mathcal{A}_{k}^{(0)}=\mathrm{w}_{k}^{G}
Ak(0)=wkG
对目标域数据进行k-means算法,以下两步交替进行直至类中心收敛,以得到伪标签
①计算余弦相似度距离
y
^
i
t
=
arg
min
k
Dist
(
A
k
(
m
)
,
f
i
t
)
\hat{y}_{i}^{t}=\arg \min _{k} \operatorname{Dist}\left(\mathcal{A}_{k}^{(m)}, f_{i}^{t}\right)
y^it=argkminDist(Ak(m),fit)
其中
Dist
(
a
,
b
)
=
1
2
(
1
−
a
⊤
b
∣
a
∣
⋅
∣
b
∣
)
\operatorname{Dist}(\mathbf{a}, \mathbf{b})=\frac{1}{2}\left(1-\frac{\mathbf{a}^{\top} \mathbf{b}}{|\mathbf{a}| \cdot|\mathbf{b}|}\right)
Dist(a,b)=21(1−∣a∣⋅∣b∣a⊤b)

②更新类中心
(2)
A
k
(
m
+
1
)
=
∑
i
=
1
n
t
1
(
y
^
i
t
=
k
)
f
i
t
∑
i
=
1
n
1
(
y
^
i
t
=
k
)
\text { (2) } \mathcal{A}_{k}^{(m+1)}=\frac{\sum_{i=1}^{n_{t}} \mathbb{1}\left(\hat{y}_{i}^{t}=k\right) f_{i}^{t}}{\sum_{i=1}^{n} \mathbb{1}\left(\hat{y}_{i}^{t}=k\right)}
(2) Ak(m+1)=∑i=1n1(y^it=k)∑i=1nt1(y^it=k)fit
设置阈值
τ
∈
(
0
,
1
)
τ∈(0,1)
τ∈(0,1),构建伪标签置信度高的子数据集
D
t
′
=
{
(
x
i
t
,
y
^
i
t
)
∣
Dist
(
f
i
t
,
A
y
^
i
t
)
<
τ
,
y
^
i
t
∈
C
}
i
=
1
n
t
′
(2)
\mathcal{D}_{t}^{\prime}=\left\{\left(x_{i}^{t}, \hat{y}_{i}^{t}\right) \mid \operatorname{Dist}\left(f_{i}^{t}, \mathcal{A}_{\hat{y}_{i}^{t}}\right)<\tau, \hat{y}_{i}^{t} \in \mathcal{C}\right\}_{i=1}^{n_{t}^{\prime}}\tag{2}
Dt′={(xit,y^it)∣Dist(fit,Ay^it)<τ,y^it∈C}i=1nt′(2)
- x i , k t x_{i,k}^t xi,kt代表伪标签为k类的目标域数据
- f i , k t = F ( x i , k t ) f_{i, k}^{t}=\mathbf{F}\left(x_{i, k}^{t}\right) fi,kt=F(xi,kt) 代表特征
- 与以前工作相似,只改变特征提取器,不改变分类器
2 源域分布估计
本文假设源域特征表示服从类条件多元高斯分布
f
i
,
k
s
∼
N
k
s
(
μ
k
s
,
Σ
k
s
)
,
where
f
i
,
k
s
=
F
(
x
i
s
∣
y
i
s
=
k
)
f_{i, k}^{s} \sim \mathcal{N}_{k}^{s}\left(\mu_{k}^{s}, \Sigma_{k}^{s}\right), \text { where } f_{i, k}^{s}=\mathbf{F}\left(x_{i}^{s} \mid y_{i}^{s}=k\right)
fi,ks∼Nks(μks,Σks), where fi,ks=F(xis∣yis=k)
其中
μ
k
s
\mu_{k}^{s}
μks可看作是类别k的中心特征表示,
Σ
k
s
\Sigma_{k}^{s}
Σks可看作是捕获了k个类别特征变化的协方差矩阵,并且包含丰富的语义信息。作者使用一个代理分布来逼近真实的源域分布,记作
N
k
sur
(
μ
^
k
s
,
Σ
^
k
s
)
N_{k}^{\operatorname{sur}}\left(\hat{\mu}_{k}^{s}, \hat{\Sigma}_{k}^{s}\right)
Nksur(μ^ks,Σ^ks)
先估计代理源域均值
由于域偏移,直接使用目标域的均值
f
k
t
‾
=
∑
i
f
i
,
k
t
∑
x
i
t
∈
D
t
′
1
(
y
^
i
t
=
k
)
\overline{f_{k}^{t}}=\frac{\sum_{i} f_{i, k}^{t}}{\sum_{x_{i}^{t} \in \mathcal{D}_{t}^{\prime}} \mathbb{1}\left(\hat{y}_{i}^{t}=k\right)}
fkt=∑xit∈Dt′1(y^it=k)∑ifi,kt作为源域代理均值不合适
根据经验通常有
∥
w
k
G
∥
2
<
∥
f
i
,
k
t
∥
2
≈
∥
f
i
,
k
s
∥
2
\left\|\mathbf{w}_{k}^{G}\right\|_{2}<\left\|f_{i, k}^{t}\right\|_{2} \approx\left\|f_{i, k}^{s}\right\|_{2}
∥∥wkG∥∥2<∥∥∥fi,kt∥∥∥2≈∥∥∥fi,ks∥∥∥2,因此不使用锚点作为均值估计
作者使用锚点来估计代理源域分布的均值
μ
^
k
s
=
∥
f
ˉ
k
t
∥
2
⋅
w
k
G
∥
w
k
G
∥
2
,
k
∈
C
(3)
\hat{\mu}_{k}^{s}=\left\|\bar{f}_{k}^{t}\right\|_{2} \cdot \frac{\mathbf{w}_{k}^{G}}{\left\|\mathbf{w}_{k}^{G}\right\|_{2}}, k \in \mathcal{C}\tag{3}
μ^ks=∥∥fˉkt∥∥2⋅∥∥wkG∥∥2wkG,k∈C(3)
估计代理源域的分布方差
作者假设源域和目标域类内语义信息是一致的,因此从目标特征的统计量中得出源协方差的估计量
Σ
^
k
s
=
γ
⋅
Σ
k
t
=
γ
⋅
f
k
t
⋅
f
k
t
⊤
∑
x
i
t
∈
D
t
′
1
(
y
^
i
t
=
k
)
,
(4)
\hat{\Sigma}_{k}^{s}=\gamma \cdot \Sigma_{k}^{t}=\gamma \cdot \frac{\mathbf{f}_{k}^{t} \cdot \mathbf{f}_{k}^{t^{\top}}}{\sum_{x_{i}^{t} \in \mathcal{D}_{t}^{\prime}} \mathbb{1}\left(\hat{y}_{i}^{t}=k\right)},\tag{4}
Σ^ks=γ⋅Σkt=γ⋅∑xit∈Dt′1(y^it=k)fkt⋅fkt⊤,(4)
其中
f
k
t
=
[
f
1
,
k
t
−
f
ˉ
k
t
,
⋯
,
f
i
,
k
t
−
f
ˉ
k
t
,
⋯
]
\mathbf{f}_{k}^{t}=\left[f_{1, k}^{t}-\bar{f}_{k}^{t}, \cdots, f_{i, k}^{t}-\bar{f}_{k}^{t}, \cdots\right]
fkt=[f1,kt−fˉkt,⋯,fi,kt−fˉkt,⋯]是一个矩阵,其列是中第k类的中心化后的目标域特征
利用锚点和目标域数据,得到K个类的条件代理分布
N
k
s
u
r
(
∥
f
ˉ
k
t
∥
2
w
k
G
∥
w
k
G
∥
2
,
γ
⋅
f
k
t
⋅
f
k
t
⊤
∑
x
i
t
∈
D
t
′
1
(
y
^
i
t
=
k
)
)
,
k
∈
C
,
(5)
\mathcal{N}_{k}^{s u r}\left(\left\|\bar{f}_{k}^{t}\right\|_{2} \frac{\mathbf{w}_{k}^{G}}{\left\|\mathbf{w}_{k}^{G}\right\|_{2}}, \frac{\gamma \cdot \mathbf{f}_{k}^{t} \cdot \mathbf{f}_{k}^{t^{\top}}}{\sum_{x_{i}^{t} \in \mathcal{D}_{t}^{\prime}} \mathbb{1}\left(\hat{y}_{i}^{t}=k\right)}\right), k \in \mathcal{C},\tag{5}
Nksur(∥∥fˉkt∥∥2∥∥wkG∥∥2wkG,∑xit∈Dt′1(y^it=k)γ⋅fkt⋅fkt⊤),k∈C,(5)
从中可以采样出代理特征来模拟真实源域特征
f
k
s
u
r
∼
N
k
s
u
r
(
μ
^
k
s
,
Σ
^
k
s
)
f_{k}^{s u r} \sim \mathcal{N}_{k}^{s u r}\left(\hat{\mu}_{k}^{s}, \hat{\Sigma}_{k}^{s}\right)
fksur∼Nksur(μ^ks,Σ^ks)
3 无源领域自适应
采用Contrastive Domain Discrepancy (CDD) introduced by Kang et al. [17]来显式地对齐两个域的数据
每次随机选取类别
C
′
∈
C
,
C
=
1
,
2
,
.
.
.
,
K
C'∈C,C = {1,2,... ,K}
C′∈C,C=1,2,...,K对于每个类别
k
∈
C
′
k∈C'
k∈C′,从有伪标签的目标域数据集中选择
n
b
n_b
nb个数
据
{
{
(
x
i
t
,
y
^
i
t
=
k
)
}
i
=
1
n
b
∣
k
∈
C
′
}
\left\{\left\{\left(x_{i}^{t}, \hat{y}_{i}^{t}=k\right)\right\}_{i=1}^{n_{b}} \mid k \in \mathcal{C}^{\prime}\right\}
{{(xit,y^it=k)}i=1nb∣k∈C′},对应特征为
{
{
f
i
,
k
t
=
F
(
x
i
t
∣
y
^
i
t
=
k
)
}
i
=
1
n
b
∣
k
∈
C
′
}
\left\{\left\{f_{i, k}^{t}=\mathbf{F}\left(x_{i}^{t} \mid \hat{y}_{i}^{t}=k\right)\right\}_{i=1}^{n_{b}} \mid k \in \mathcal{C}^{\prime}\right\}
{{fi,kt=F(xit∣y^it=k)}i=1nb∣k∈C′}。
对于源域,选取 n b n_b nb个代理特征 { { f j , k sur ∼ N k sur } j = 1 n b ∣ k ∈ C ′ } \left\{\left\{f_{j, k}^{\text {sur }} \sim \mathcal{N}_{k}^{\text {sur }}\right\}_{j=1}^{n_{b}} \mid k \in \mathcal{C}^{\prime}\right\} {{fj,ksur ∼Nksur }j=1nb∣k∈C′}。
带有类别条件的MMD可写作如下形式
L
M
M
D
k
1
,
k
2
=
∑
i
=
1
n
b
∑
j
=
1
n
b
k
(
f
i
,
k
1
s
u
r
,
f
j
,
k
1
s
u
r
)
n
b
⋅
n
b
+
∑
i
=
1
n
b
∑
j
=
1
n
b
k
(
f
i
,
k
2
t
,
f
j
,
k
2
t
)
n
b
⋅
n
b
−
2
∑
i
=
1
n
b
∑
j
=
1
n
b
k
(
f
i
,
k
1
s
u
r
,
f
j
,
k
2
t
)
n
b
⋅
n
b
(6)
\mathcal{L}_{\mathrm{MMD}}^{k_{1}, k_{2}}=\sum_{i=1}^{n_{b}} \sum_{j=1}^{n_{b}} \frac{\mathbb{k}\left(f_{i, k_{1}}^{s u r}, f_{j, k_{1}}^{s u r}\right)}{n_{b} \cdot n_{b}}+\sum_{i=1}^{n_{b}} \sum_{j=1}^{n_{b}} \frac{\mathbb{k}\left(f_{i, k_{2}}^{t}, f_{j, k_{2}}^{t}\right)}{n_{b} \cdot n_{b}}-2 \sum_{i=1}^{n_{b}} \sum_{j=1}^{n_{b}} \frac{\mathbb{k}\left(f_{i, k_{1}}^{s u r}, f_{j, k_{2}}^{t}\right)}{n_{b} \cdot n_{b}}\tag{6}
LMMDk1,k2=i=1∑nbj=1∑nbnb⋅nbk(fi,k1sur,fj,k1sur)+i=1∑nbj=1∑nbnb⋅nbk(fi,k2t,fj,k2t)−2i=1∑nbj=1∑nbnb⋅nbk(fi,k1sur,fj,k2t)(6)
则最小化CDD损失函数(最小化类内域差异,最大化类间域差异)
L
C
D
D
=
∑
k
∈
C
′
L
M
M
D
k
,
k
∣
C
′
∣
−
∑
k
1
∈
C
′
∑
k
2
∈
C
′
k
1
≠
k
2
L
M
M
D
k
1
,
k
2
∣
C
′
∣
(
∣
C
′
∣
−
1
)
,
(7)
\mathcal{L}_{\mathrm{CDD}}=\frac{\sum_{k \in \mathcal{C}^{\prime}} \mathcal{L}_{\mathrm{MMD}}^{k, k}}{\left|\mathcal{C}^{\prime}\right|}-\frac{\sum_{k_{1} \in \mathcal{C}^{\prime}} \sum_{k_{2} \in \mathcal{C}^{\prime}}^{k_{1} \neq k_{2}} \mathcal{L}_{\mathrm{MMD}}^{k_{1}, k_{2}}}{\left|\mathcal{C}^{\prime}\right|\left(\left|\mathcal{C}^{\prime}\right|-1\right)},\tag{7}
LCDD=∣C′∣∑k∈C′LMMDk,k−∣C′∣(∣C′∣−1)∑k1∈C′∑k2∈C′k1=k2LMMDk1,k2,(7)
CDD意义

(1) 对所有的类别,目标域的样本分布要分别与源域相同类别的样本分布在某一层特征空间中拉近;
(2)对于所有的类别,目标域的某个类别c的样本分布要与源域所有不同类别c的样本分布都拉开距离(最大化差异)。
实验结果

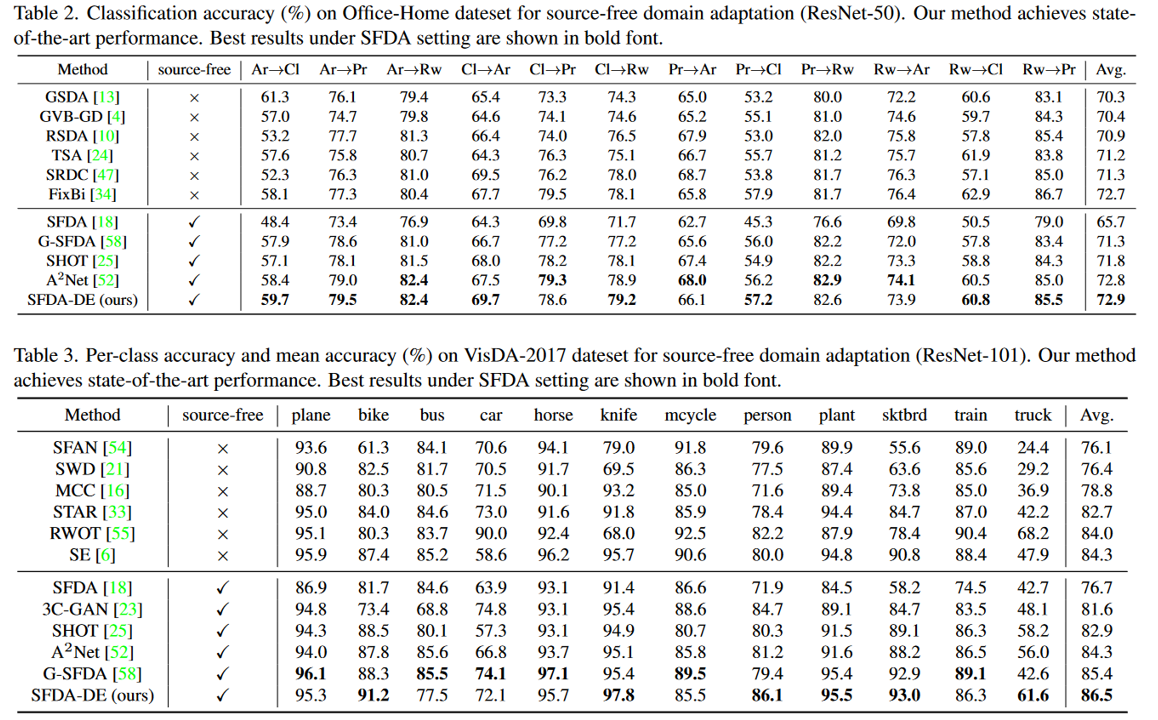
消融分析
-
聚类中心

-
使用最大概率值得到的伪标签进行训练的结果

参数敏感性分析
- 高斯分布中,协方差的缩放因子

- 使用spherical k- means聚类,并设置信心阈值,并在模型进行适应之前就选择好了打上伪标签的子数据集,红绿线对应左侧竖坐标准确率,蓝线对应右侧竖坐标选择出的伪标签数量x100

可视化&收敛性分析

















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









