







今天想说一下对过拟合与正则化的理解
上次说过我们把非线性的数据通过函数
ϕ(x)
映射到另一个空间会达到线性可分的效果,但是相应的特征值也会增加,也就是维度增加,使得
Ein,Eout
有比较大的差距。在特征很多的情况下,我们可能很容易的学得一个较小的
Ein
,但是
Eout
很大,这时候就会发生过拟合
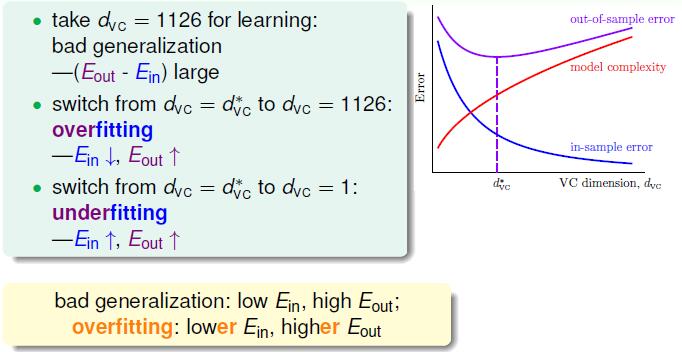
如上图就是对应的过拟合和欠拟合的特征。
实际上过拟合被哪几方面因素影响呢?
一共有四方面,噪音数据太多,数据资料量太少,过高的维度,还有资料本身就很复杂。
我们一一说明这些条件。
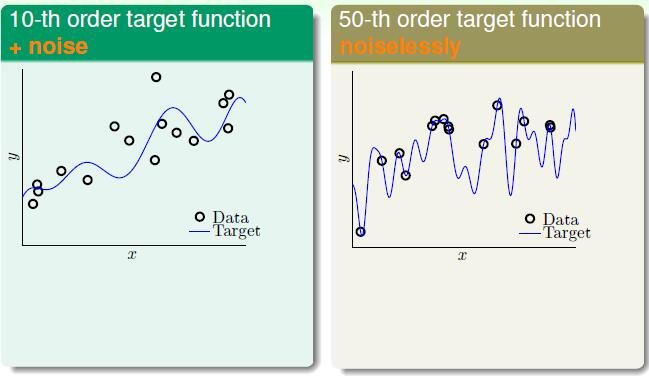
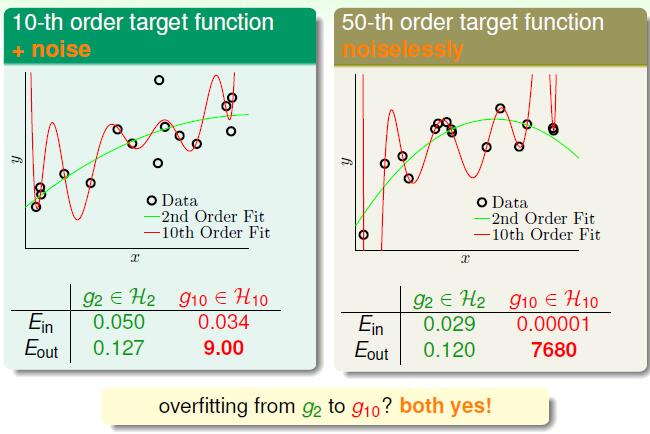
上图说了一件什么事呢,左右两个资料的生成方式不同,左面这个是由一个10次的目标函数加上一些噪音生成的一系列的数据点。右边的是由50次的目标函数没有加噪音生成的点。然后我们分别用一个二次方函数和一个10次方函数在这两个数据集上去做拟合,结果发现在两个数据集上二次方函数的效果都要好一些,虽然在 Ein 上二次方比不上十次方,但是十次方函数的 Eout 都很大。
我们先看左面的图,为什么本身由于10次方目标函数生成的点用10次方函数去拟合的时候效果会差呢,那是因为有噪音的关系,在数据量不够多的情况下,10次方函数强大的拟合能力会让函数更加接近噪音。对于右面的图为什么也不行呢,是因为目标函数是50次函数本身就是一个很复杂的函数,很难被学习出来,所以她本身就相当于一些噪音的存在。想一想因为数据量不够,所以有一些点的变化10次方函数是体现不出来的,所以还不如二次方来的好。二次方泛化能力更强一些
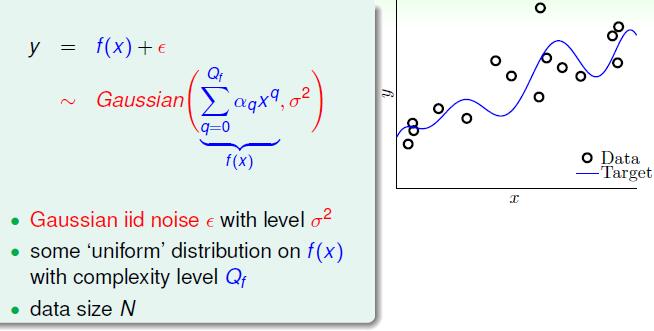
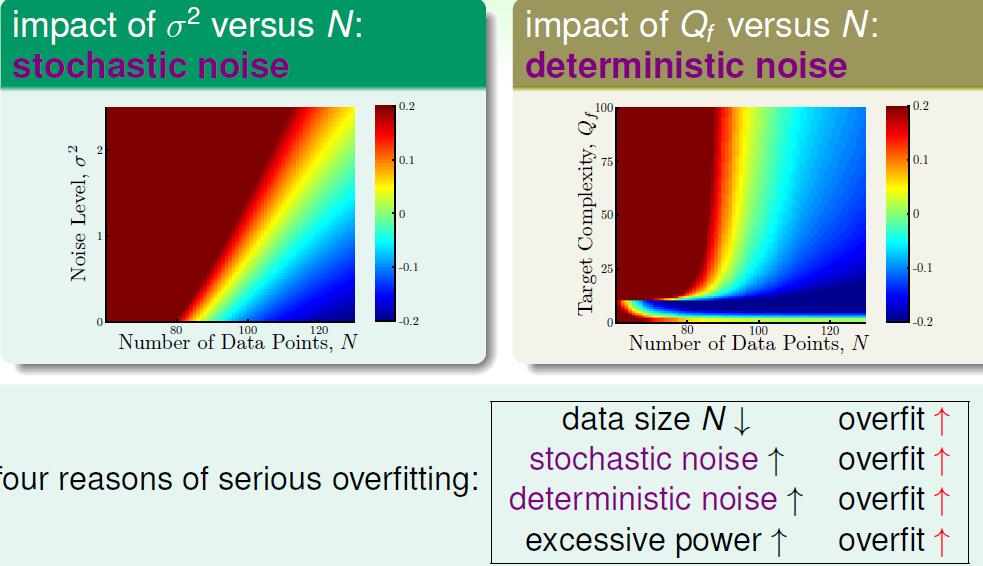
我们看一组更加详细的实验。
目标函数如图 Qf 代表了最高次数,代表了目标函数的复杂度。 σ2 反应了噪音的强度。那么对应的两个图的意思就显而易见了,左面这个图,我们确定了 Qf=20 右面的图我们固定了 σ2=0.1 红色反映了过拟合程度。那么对过拟合影响的属性就显而易见了。stochastic noise表示了随机噪音,deterministic noise表明了由目标函数的复杂度引起的噪音。
正则化
显而易见的两种解决策略。 去除噪音,增加数据量,这里就不说了。接下来详细说说正则化。
我们为什么要用正则化,是因为发生了过拟合也就是我们用的函数的次数太高了。本来用二次函数解决的问题我们用了10次函数,结果过分的拟合了噪音使得函数泛化能力降低。那么我们就想让10次函数退回到2次函数,正好之前也学过,高次函数其实是包含低次函数的。
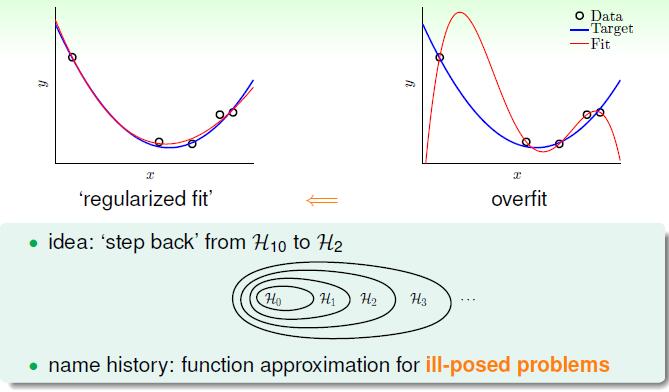
那么如何退回去呢,我们当然是希望 w3,...,w10 都等于0才好。

那么也就是我们希望在求最小化 Ein 的时候能加上一个限定条件 ∑10q=0[wq≠0]≤3 但是我们讲求解个数这种问题并不好求解,那换一个想法,也就是我们希望 ∑10q=0w2q≤C

所有现在的目标就变成了 min { Ein(w)+λNwTw }
λ 这里叫做‘weight-delay’,这个值越大,说明我们对w的惩罚越大,也就是要就C越小。所以如果发生过拟合的时候,我们要降低函数的次数,就要适当的增大 λ















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









