







How to use gpt-4o-mini by Python
文章目录
1 python环境安装
默认大家都安装了anaconda
若没有安装点击下载 anaconda, Download Now | Anaconda
1.1 anaconda 添加到系统变量
如果在windows进入命令行输入conda,若看到下述的输出结果,说明anaconda已经添加到了系统环境中,可跳过本章节。

如果没有反应,你需要将conda添加到系统环境路径中,如下面的图片进行添加。
一般在安装anaconda的时候,会有一个选择,是否要将conda,添加到系统路径中:|
若当时勾了,它会自动添加到系统路径中,就无需进行下述操作,;
若当时没勾,按照下述提示,把个人自己的anaconda安装地址的路径,添加进环境变量中;
如下图所示,先找到自己电脑上 anaconda的安装路径:

如下图所示,再把anaconda的下述两个文件夹的路径,添加到系统环境变量中。



1.2 anaconda 创建新的python虚拟环境
Python的每个大型的项目都应该使用单独的python环境,从而避免包冲突;
若读者觉得没必要创建新环境,愿意使用原始环境,那么可跳过当前章节;
-
查看当前有哪些python环境
conda env list如下图所示,当前只有一个base环境。
-
init
若是第一次使用conda,请先运行
conda init,然后关闭命令窗口,再开一个新的命令窗口。

-
conda activate base能得到下述结果,说明conda配置成功

-
创建新python环境
因为python的base环境,python是3.11.7版本,新环境的python版本也设置为3.11.7。
新环境的python版本设置为多少,因人而异
创建新的python环境,取名为 llm (large language model 大语言模型简称)
conda create --name llm python=3.11.7
输入 y,然后回车:

输入
conda env list,可发现新环境已添加成功
输入conda activate llm, 激活刚才创建的llm 环境,如下图所示就可发现环境完成了从base到llm的切换。

接下来,就在当前的激活的llm窗口中,完成python包的安装。
2 langchain 与 openai python包安装
对 langchain 感兴趣的,可点击查看langchain的官方文档 How to install LangChain packages | 🦜️🔗 LangChain
直接在命令窗口输入下述装包命令,即可完成包的安装:
pip install langchain langchain-openai langchain-core langchain-community langchain-experimental
如下图所示完成了包的安装:

3 openai API 接入
3.1 第三方API站点
由于OpenAI服务器在海外,且对一些国家不提供服务。出于科研与实验的需要,可使用第三方的服务,由第三方的站点把数据包转发OpenAI服务器。
按需选用,包括且不限于下述的网站:
- https://www.gptapi.us/register?aff=9xEy 充值:1$ = 1¥,API收费与OpenAI一致【推荐】
- https://api.chatfire.cn/register?aff=zJhM 充值:1$ =1¥,API收费略高于OpenAI
- https://api2.aigcbest.top/ 充值:1$ = 2.5¥, API收费与OpenAI一致
本文以 【gptapi】 作为示例:

先添加令牌,再复制密钥,密钥格式:sk-xxx。
可在网站首页查看可使用的模型列表

值得注意的是:gpt-4o-mini 是性价比高的模型。其他的模型都相对比较贵。
运行下述代码即可获得 gpt-4o-mini 的回答:
将 OpenAI API 基础地址 https://api.openai.com/v1 替换为 https://www.gptapi.us/v1,复制下面的密钥即可使用
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
base_url="https://www.gptapi.us/v1",
api_key="sk-xxx", # 在这里填入你的密钥
)
res = llm.invoke("你是谁?请你简要做一下,自我介绍?")
print(res)
下述是大模型返回的内容:
我是GPT-4o mini,一个大型语言模型,由OpenAI训练。我的主要功能是回答问题、提供信息和帮助解决各种语言相关的任务。无论是写作、学习还是日常交流,我都能提供支持。如果你有任何问题,欢迎随时问我!
在运行程序时,可以发现10秒后才出结果。
加快批量处理速度:
- 加钱找客服,要求使用直连的专线,要多出3倍多的钱。
- 使用多线程加速,如果只使用一个令牌会被限速。弄很多个账号,使用很多个令牌构建令牌池,每次发起请求时,随机从令牌池中获取令牌。
3.2 windows配置
在[3.1章节](# 3.1 第三方API站点)中,需要在代码中填入第三方API接口的网址和密钥。
在代码中,填入密钥有泄漏风险(因为代码要云端备份和与人分享),最重要的是要输入网址和密钥很麻烦。
故可以将url和key,添加到系统环境变量中,在后续的代码中就无需填写这两个参数。
若你是Mac系统和Linux系统,执行下述命令:
export OPENAI_API_BASE=https://www.gptapi.us/v1
export OPENAI_API_KEY=sk-xxx
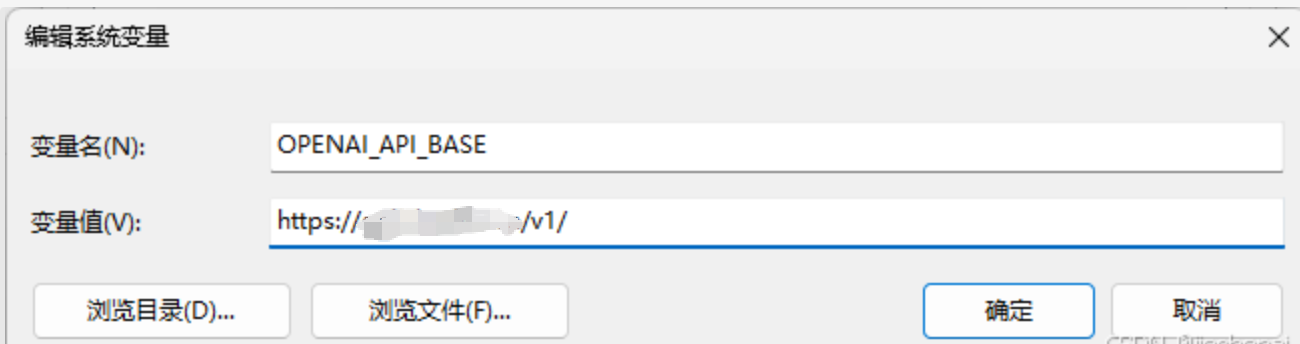
若你是Windows系统,按照下述方式配置系统变量:
与[1.1 anaconda 添加到系统变量](# 1.1 anaconda 添加到系统变量) 一样,打开系统环境变量,与上次不同的是这一次是新建。


from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
)
res = llm.invoke("鲁迅和周树人是同一个人吗?")
print(res)
如下结果所示,无需在代码中填写网址和密钥一样可以获得大模型的输出结果。
content='是的,鲁迅和周树人是同一个人。鲁迅是周树人的笔名,他是中国现代文学的重要作家。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 46, 'prompt_tokens': 24, 'total_tokens': 63}, 'model_name': 'gpt-4o-mini', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-3762857a-6c2a-4fbb-ad5d-524f020eaf7c-0' usage_metadata={'input_tokens': 24, 'output_tokens': 46, 'total_tokens': 63}
3.3 大模型API调用消费估算
下述是大模型的输出结果,不仅给出了文本,还给出了相应的输入和输出耗费的token数。
AIMessage(
content='我是GPT-4o mini,一个大型语言模型,由OpenAI训练。我的主要功能是回答问题、提供信息和帮助解决各种语言相关的任务。无论是写作、学习还是日常交流,我都能提供支持。如果你有任何问题,欢迎随时问我!',
additional_kwargs={'refusal': None},
response_metadata={'token_usage': {'completion_tokens': 96, 'prompt_tokens': 27, 'total_tokens': 116}, 'model_name': 'gpt-4o-mini',
'system_fingerprint': None, finish_reason': 'stop', 'logprobs': None},
id='run-b9964b57-83e4-4a2d-8444-81bc5d21abc1-0',
usage_metadata={'input_tokens': 27, 'output_tokens': 96, 'total_tokens': 116})
根据下图矩行框的高度预估这一次调用消费是大概是 9 x 10-5 $。

下述这张图是该网站关于 gpt-4o-mini 的收费标准:

1M = 1024 x 1024 = 1048576 = 1.04 x 106
大模型输入收费是:0.2249999 / 1M token;
大模型输出收费是:0.899999 / 1M token;
usage_metadata={'input_tokens': 27, 'output_tokens': 96, 'total_tokens': 116})
所以本次的消费金额计算过程如下:
27
×
0.225
+
96
×
0.90
1.04
×
1
0
6
=
8.89
×
1
0
−
5
\frac{27 \times 0.225 + 96 \times 0.90}{1.04 \times 10^{6}} = 8.89 \times 10^{-5}
1.04×10627×0.225+96×0.90=8.89×10−5
我们的计算结果与网站的扣费是一致的。
日常使用时,1个字大概约等于1 token,可使用上述计算过程预估出大致的扣费金额。
4 相关教程
下述是LangChain的官方教程文档:
若要使用大模型,写好提示词至关重要,下述是一些不错的提示词教程:
- ChatGPT提示工程师&吴恩达教你写提示词|prompt engineering【完整中字九集全】 代码教程
- 【45分钟系统学习】ChatGPT Prompt提示词工程 基础>少样本>思维链>联网>认知搜索>ReAct实现ChatGPT插件
重要事项
-
写好提示词
-
给少样的例子,便于大模型学习
few-shot 提示词示例:
prompt = """ 参考下述例子,生成相应的回答,请你从中提取出今年生产总值的预期增长值是多少? 按照下述提供的json格式返回结果。 Input: 孝感市1894年文件节选:主要预期目标是:全市生产总值增长10%以上 Output: {"city":"孝感市", "year":"1894", "GDP_growth":"10%"} Input: 上海市1895年文件节选:初步核算,全市生产总值比上年增长11.1%,\n今年经济社会发展的主要预期目标是:生产总值增长12%,全社会固定资产投资增长20%,' Output: {"city":"上海市", "year":"1895", "GDP_growth":"12%"} Input: {filename}年文件节选:{content} Output: """.strip()相关博客推荐:利用langchain 做大模型 Few-shot Learning 提示,包括固定和向量相似的动态样本筛选
-
让大模型每次只做一件小事,聚焦有利于提高大模型的能力
-
无论大模型的效果看起来有多好,总有一些大模型会生成失败或错误的样本。观察大模型生成 的答案,使用python根据规则找回这些错误的样本进行后处理。
-
让大模型一步一步思考,给出原因,通过大模型生成的原因可以分析大模型得出结论的原因,再逐步修改提示词和示例
从Input中提取出生产总值的预期增长百分数。若没有提及预期生产总值就返回null。 若文本中有预计生产总值和预期生产总值,则应只保留预期生产总值。 针对Input中文本,一步一步地思考,思考过程保存在Reason中,再依据Reason生成Output。 参考下述例子,学习这些例子内在的逻辑。 只能通过当前的Input生成Reason,最终的输出结果Output按照json格式返回。 Input: 抚顺市2004年文件节选:2004年的主要预期目标是:国内生产总值实现360亿元,增长14.5% Reason: 当前年份是2004年,文本中提到2004年国内生产总值预期增长14.5%。 Output: {"city":"抚顺市", "year":"2004", "GDP_growth":"14.5%"} Input: 上海市xxxx年文件节选:初步核算,全市生产总值比上年增长11.1%,农民人均纯收入增长10.2%,年初确定的主要预期目标和各项工作任务全面超额完成\n今年经济社会发展的主要预期目标是:生产总值增长12%,全社会固定资产投资增长20%,' Reason: 全市生产总值比上年增长11.1%,这是去年的总结;生产总值增长12%,这才是今年的预期;所以要返回12%。 Output: {"city":"上海市", "year":"xxxx", "GDP_growth":"12%"} -
让大模型先处理得到结果,再使用提示词创建大模型扮演老师,审核上一个大模型生成的答案,找出做的不对的样本
下一步阅读
- 大模型 API 异步调用优化:高效并发与令牌池设计实践.https://blog.csdn.net/sjxgghg/article/details/143858730
大模型API的调用很慢,需要等待很长时间才能看到结果,该文章使用异步协程的方式并发调用大模型的API,加快大模型API的处理。


















 4044
4044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











