







文章目录
背景
大模型 API 调用速度慢的原因之一在于单次调用对令牌(token)的速度限制。这种限制在处理大批量任务时尤为突出,因此优化 API 调用的效率成为关键。通过使用多个令牌构成令牌池,并采用异步编程(类似多线程),可以显著提高程序运行效率。
本文将详细介绍如何使用 Python 异步编程实现高效的大模型 API 调用。
如下表所示,调用API,使用 async 异步。
| 场景 | 使用方式 | 备注 |
|---|---|---|
| 大量网络请求 | Async | 如爬虫、异步 HTTP 请求 |
| CPU 密集型任务 | 多线程/多进程 | 如图像处理、数学计算 |
| 文件读写 | Async | 异步文件读写提高效率 |
| 简单并发操作 | 多线程 | 如少量任务的快速实现 |
| 多核并行计算 | 多进程 | Python 的 multiprocessing 更适合 |
摘要
本文探讨了大模型 API 调用中速度优化的关键技术。通过结合 Python 的异步编程和令牌池设计,能够显著提高并发任务处理效率,同时避免因频率过高导致封号。文章从基础异步实现、限速机制、进度条展示到多令牌池优化方案,提供了详细的代码示例和实践建议,并应用于大模型四则运算任务中,展示了异步调用的显著性能提升。
大模型API 推荐
-
https://www.gptapi.us/register?aff=9xEy 充值:1$ = 1¥,API收费与OpenAI一致【极力推荐】
我主要用这个进行异步实验 -
https://api2.aigcbest.top/ 充值:1$ = 2.5¥, API收费与OpenAI一致
-
https://api.chatfire.cn/register?aff=zJhM 充值:1$ =1¥,API收费略高于OpenAI
异步协程请求频率高了后,不让我使用4o-mini模型
项目开源

24/11/LLM异步API调用/LLM_API调用/agenerate/llm_api_example.py https://github.com/JieShenAI/csdn/blob/main/24/11/LLM%E5%BC%82%E6%AD%A5API%E8%B0%83%E7%94%A8/LLM_API%E8%B0%83%E7%94%A8/agenerate/llm_api_example.py
- 简单例子: 一个异步协程的简单例子,给出了
py和 jupyter.ipynb的不同写法; - LLM API 调用:
agenerate支持异步 ,对比invoke不支持异步
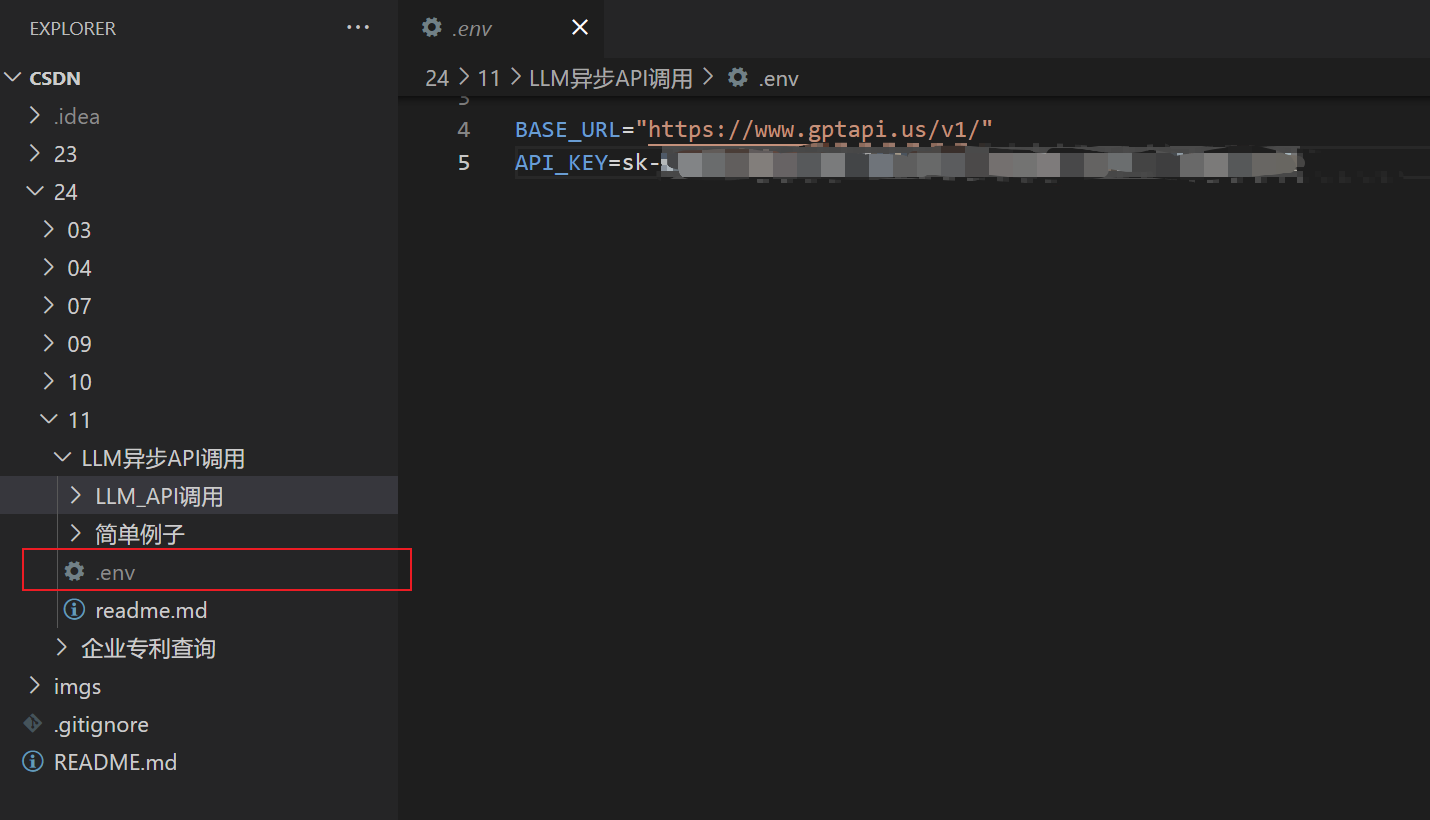
新建一个 .env 文件,在其中存放 BASE_URL 和 API_KEY
基础异步实现
装包
pip install aiolimiter
简单示例代码
以下是一个简单的异步编程 Demo,展示如何通过协程和令牌池并发处理任务:
import random
import asyncio
from uuid import uuid4
from tqdm import tqdm
from dataclasses import dataclass
from aiolimiter import AsyncLimiter
# 创建限速器,每秒最多发出 5 个请求
limiter = AsyncLimiter(10, 1)
@dataclass
class Token:
uid: str
idx: int
cnt: int = 0
# 将 connect_web 改为异步函数
async def llm_api(data):
t = random.randint(0, 2)
# 使用 asyncio.sleep, 模拟API调用
await asyncio.sleep(t)
return data * 10
# 保持 call_api 异步
async def call_api(token, data, rate_limit_seconds=0.5):
token.cnt += 1
async with limiter:
await asyncio.sleep(rate_limit_seconds)
return await llm_api(data)
workders = 1
tokens = [Token(uid=str(uuid4()), idx=i) for i in range(workders)]
async def _run_task_with_progress(task, pbar):
"""包装任务以更新进度条"""
result = await task
pbar.update(1)
return result
# 主函数
async def main():
nums = 100
data = [i for i in range(nums)]
results = [call_api(tokens[int(i % workders)], item) for i, item in enumerate(data)]
# 使用 tqdm 创建一个进度条
with tqdm(total=len(results)) as pbar:
# 使用 asyncio.gather 并行执行任务
results = await asyncio.gather(
*(_run_task_with_progress(task, pbar) for task in results)
)
return results
# 运行程序
result = asyncio.run(main())
print(result)
限速
在使用异步协程时,一定要限速,不然会被封。
limiter = AsyncLimiter(5, 1), 创建限速器,每秒最多发出 5 个请求。
tokens[int(i % workders) 令牌轮转,避免同一个token访问频率过高被封。
假如 AsyncLimiter 限速 每秒15条请求,令牌池中有3个token,那么相当于每个token的请求速度降低到了每秒5(15 / 3)条请求。每个token的频率降低了,但是总的频率还是很高的。
建议:最好使用多个平台的API接口。服务商能够看到我们主机的IP,即便使用了多个token,但是IP是同一个,容易被封IP。目前API的服务器提供商很多,咱们用多个平台的 API 对服务商也好,压力散布到多个服务商,不用只霍霍一家服务商。
进度条
使用 tqdm 与 _run_task_with_progress 结合构建进度条
asyncio.gather 函数用于并行运行多个协程,并在所有协程完成后返回结果。利用asyncio.gather实现一个进度条工具,创建一个协程来更新进度条,同时使用asyncio.gather来跟踪其他协程的完成情况。
使用 tqdm 创建一个进度条对象 pbar,并设置 total 为任务的数量。
使用 asyncio.gather 并行执行所有任务,同时通过 _run_task_with_progress 包装每个任务以更新进度条。
注意事项
-
列表推导式中的协程:
在列表推导式中直接使用await是错误的,正确的做法是构建任务列表,然后通过asyncio.gather并发执行任务。- 错误示例:
result = [await call_api(tokens[int(i % workers)], item) for i, item in enumerate(data)] - 正确示例:
result = [call_api(tokens[int(i % workers)], item) for i, item in enumerate(data)]
- 错误示例:
-
执行效率:通过
asyncio.gather并发运行任务可以充分利用异步特性,缩短总执行时间。
四则运算的LLM API 异步实战
简介
下面的代码展示了如何使用多个 API 密钥组成的令牌池来优化 LLM API 调用。我们以 .env 文件存储 API 密钥为例。
环境准备
创建 .env 文件,存放多个api key 构成令牌池:
API_KEY=sk-xxx,sk-xxx,sk-xxx
完整实现代码
utils.py
import re
import json
import random
import time
from typing import Union, Dict
def generate_arithmetic_expression(num: int):
"""
num: 几个操作符
"""
# 定义操作符和数字范围,除法
operators = ['+', '-', '*']
expression = f"{random.randint(1, 100)} {random.choice(operators)} {random.randint(1, 100)}"
num -= 1
for _ in range(num):
expression = f"{expression} {random.choice(operators)} {random.randint(1, 100)}"
result = eval(expression)
expression = expression.replace('*', 'x')
return expression, result
def re_parse_json(text) -> Union[Dict, None]:
# 提取 JSON 内容
json_match = re.search(r'\{.*?\}', text, re.DOTALL)
if json_match:
json_data = json_match.group(0)
response_data = json.loads(json_data)
return response_data
print(f"异常:\n{text}")
return None
def calculate_time_difference(start_time, end_time):
elapsed_time = end_time - start_time
hours, rem = divmod(elapsed_time, 3600)
minutes, seconds = divmod(rem, 60)
milliseconds = (elapsed_time - int(elapsed_time)) * 1000
print(
f"executed in {int(hours):02}:{int(minutes):02}:{int(seconds):02}.{int(milliseconds):03} (h:m:s.ms)"
)
def time_logger(func):
def wrapper(*args, **kwargs):
start_time = time.time() # 记录开始时间
result = func(*args, **kwargs) # 执行目标函数
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time
hours, rem = divmod(elapsed_time, 3600)
minutes, seconds = divmod(rem, 60)
milliseconds = (elapsed_time - int(elapsed_time)) * 1000
print(
f"Function '{func.__name__}' executed in {int(hours):02}:{int(minutes):02}:{int(seconds):02}.{int(milliseconds):03} (h:m:s.ms)")
return result
return wrapper
# 测试生成
if __name__ == "__main__":
expr, res = generate_arithmetic_expression(4)
print(f"生成的运算表达式: {expr}")
print(f"计算结果: {res}")
异步协程核心代码:
import asyncio
import os
import time
from tqdm import tqdm
from dataclasses import dataclass, field
from typing import List, Tuple, TypedDict
from aiolimiter import AsyncLimiter
# 创建限速器,每秒最多发出 5 个请求
limiter = AsyncLimiter(5, 1)
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from utils import (
generate_arithmetic_expression,
re_parse_json,
calculate_time_difference,
)
@dataclass
class LLMAPI:
"""
大模型API的调用类
"""
base_url: str
api_key: str # 每个API的key不一样
uid: int
cnt: int = 0 # 统计每个API被调用了多少次
llm: ChatOpenAI = field(init=False) # 自动创建的对象,不需要用户传入
def __post_init__(self):
# 初始化 llm 对象
self.llm = self.create_llm()
def create_llm(self):
# 创建 llm 对象
return ChatOpenAI(
model="gpt-4o-mini",
base_url=self.base_url,
api_key=self.api_key,
)
async def agenerate(self, text):
self.cnt += 1
res = await self.llm.agenerate([text])
return res
async def call_llm(llm: LLMAPI, text: str):
# 异步协程 限速
async with limiter:
res = await llm.agenerate(text)
return res
async def _run_task_with_progress(task, pbar):
"""包装任务以更新进度条"""
result = await task
pbar.update(1)
return result
async def run_api(llms: List[LLMAPI], data: List[str]) -> Tuple[List[str], List[LLMAPI]]:
results = [call_llm(llms[i % len(llms)], text) for i, text in enumerate(data)]
# 使用 tqdm 创建一个进度条
with tqdm(total=len(results)) as pbar:
# 使用 asyncio.gather 并行执行任务
results = await asyncio.gather(
*[_run_task_with_progress(task, pbar) for task in results]
)
return results, llms
if __name__ == "__main__":
load_dotenv()
# 四则运算提示词模板
prompt_template = """
请将以下表达式的计算结果返回为 JSON 格式:
{{
"expression": "{question}",
"infer": ?
}}
"""
questions = []
labels = []
for _ in range(10000):
question, label = generate_arithmetic_expression(2)
questions.append(prompt_template.format(question=question))
labels.append(label)
start_time = time.time()
# for jupyter
# results, llms = await run_api(api_keys, questions)
api_keys = os.getenv("API_KEY").split(",")
base_url = os.getenv("BASE_URL")
# 创建LLM
llms = [LLMAPI(base_url=base_url, api_key=key, uid=i) for i, key in enumerate(api_keys)]
results, llms = asyncio.run(run_api(llms, questions))
right = 0 # 大模型回答正确
except_cnt = 0 # 大模型不按照json格式返回结果
not_equal = 0 # 大模型解答错误
for q, res, label in zip(questions, results, labels):
res = res.generations[0][0].text
try:
res = re_parse_json(res)
if res is None:
except_cnt += 1
continue
res = res.get("infer", None)
if res is None:
except_cnt += 1
continue
res = int(res)
if res == label:
right += 1
else:
not_equal += 1
except Exception as e:
print(e)
print(f"question:{q}\nresult:{res}")
print("accuracy: {}%".format(right / len(questions) * 100))
end_time = time.time()
calculate_time_difference(start_time, end_time)
print(right, except_cnt, not_equal)
上述是大模型进行四则运算实战的代码,虽然写的内容有点多了,但是相信大家看完还是会有所收获的。
如果大家想直接将其应用到自己的代码中,建议浏览 run_api 函数。仿照上述类似的流程完成代码的编写即可实现。
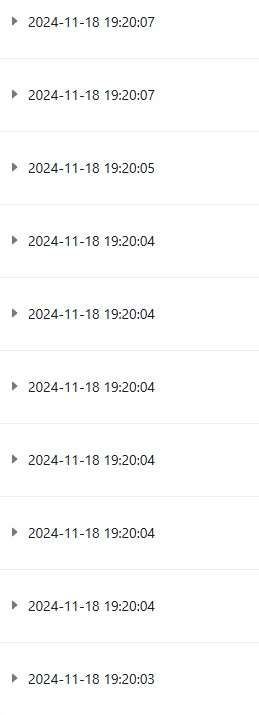
如下图是API调用的网页后台数据,其在短时间内,发出了多个请求。如果不使用协程,则必须收到上一个请求的结果后,才能发送下一个请求。
实验
速度
在异步协程不限速时,在90条四则运算进行推理,对比花费的时间:
| 1个key | 3个key | |
|---|---|---|
| invoke | 5分半 | / |
| agenerate | 15秒 | 15秒 |
invoke不支持异步,agenerate支持异步。
在异步协程不限速的情况下,发现使用1个key和多key的运行时间是一样的。这是因为不限速的情况下,会在第一时间把所有的请求发出去,令牌池效果体现不出来。
只有在对异步协程限速的情况下,才能体现出令牌池的效果。在上文的限速部分进行了细致的举例说明。
若只使用一个令牌,对它限速,确保不让服务商封号,使用异步协程保持在一个恰当的速度,比较省事。注册很多账号,也很磨人。
大模型计算结果
上图是运行程序输出的结果:
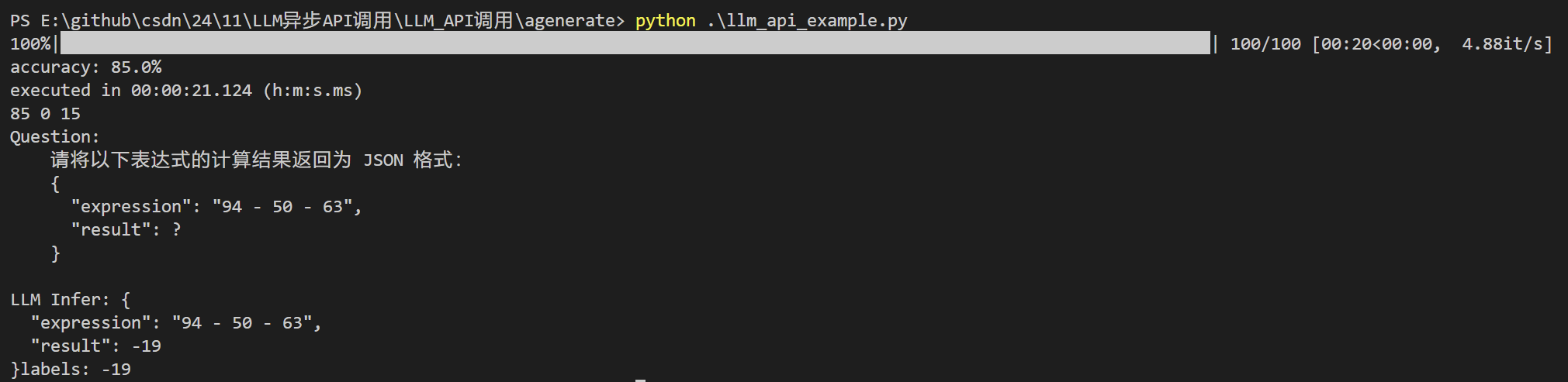
如上图的进度条所示,20秒跑完100条数据,平均每秒处理4.88条数据,大模型计算四则运算的准确率 85%(只在100条数据上实验,会有波动)。
print(right, except_cnt, not_equal)的输出结果是 85 0 15,大模型计算正确85条数据,异常0条,计算错误15条。
Question是输入到大模型的提示词,LLM Infer是大模型生成的答案,label 是真实的结果。
提示词改进
在实验中发现,上述提示词让大模型做四则运算的准确率不够高。本文更新了一版提示词后,准确率达到98%。
我不想琢磨提示词的编写,故提示词也是让大模型自己生成的。

你是一名擅长数学运算的助手,负责逐步推理并解决四则运算问题。请按照以下步骤进行:
1. 阅读并理解问题。
2. 分步计算,逐步解决问题。
3. 给出最终的结果。
4. 按照 JSON 格式输出结果,包括:
- reason: 详细的推理过程。
- infer: 最终的计算结果。
问题:{问题描述}
请给出分析和结果。
使用上述提示词后,准确率达到98%。
总结
通过异步编程结合令牌池的设计,可以显著提高大模型 API 的调用效率。关键在于:
- 使用
asyncio管理异步任务。 - 异步协程限速
- 合理分配令牌以实现负载均衡。
- 将多个协程任务交由
asyncio.gather并发执行。
这一思路可以应用于需要高并发的场景,例如自然语言处理、实时数据处理等,助力开发者构建高效的 AI 应用系统。
相关文章推荐
附录 AsyncLLMAPI 封装
为了方便大家便捷使用LLM API 进行异步调用,将上文的异步操作与限速封装入AsyncLLMAPI工具类。
import asyncio
from tqdm import tqdm
from dataclasses import dataclass, field
from typing import List
from aiolimiter import AsyncLimiter
from langchain_openai import ChatOpenAI
@dataclass
class AsyncLLMAPI:
"""
大模型API的调用类
"""
base_url: str
api_key: str # 每个API的key不一样
uid: int
cnt: int = 0 # 统计每个API被调用了多少次
llm: ChatOpenAI = field(init=False) # 自动创建的对象,不需要用户传入
num_per_second: int = 6 # 限速每秒调用6次
def __post_init__(self):
# 初始化 llm 对象
self.llm = self.create_llm()
# 创建限速器,每秒最多发出 5 个请求
self.limiter = AsyncLimiter(self.num_per_second, 1)
def create_llm(self):
# 创建 llm 对象
return ChatOpenAI(
model="gpt-4o-mini",
base_url=self.base_url,
api_key=self.api_key,
)
async def __call__(self, text):
# 异步协程 限速
self.cnt += 1
async with self.limiter:
return await self.llm.agenerate([text])
@staticmethod
async def _run_task_with_progress(task, pbar):
"""包装任务以更新进度条"""
result = await task
pbar.update(1)
return result
@staticmethod
def run_data_async(llms: List["AsyncLLMAPI"], data: List[str]):
async def _sync_run(llms, data):
results = [llms[i % len(llms)](text) for i, text in enumerate(data)]
# 使用 tqdm 创建一个进度条
with tqdm(total=len(results)) as pbar:
# asyncio.gather 并行执行任务
results = await asyncio.gather(
*[
AsyncLLMAPI._run_task_with_progress(task, pbar)
for task in results
]
)
return results, llms
return asyncio.run(_sync_run(llms, data))
在封装完成后,调用代码就变得很简洁:
llms = [
AsyncLLMAPI(base_url=base_url, api_key=key, uid=i)
for i, key in enumerate(api_keys)
]
results, llms = AsyncLLMAPI.run_data_async(llms, questions)
把异步的函数调用与限速封装在 AsyncLLMAPI.run_data_async 中,让用户无需关注这些异步的操作。


















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











