






序论
BEV系列的感知算法是指在BEV上进行预测分割,这样对于下游任务更加友好,而BEV算法类别之间最大的区别就是在图像特征到BEV转换这一块(img2bev),根据这一块不同,我们将算法分为三类:
第一类显示转换:根据像素坐标以及模型预测的像素深度分布得到(x,y,z),然后通过相机内外参转换到BEV上得到BEV下的(X,Y,Z)
第二类隐式转换:首先根据BEV上的分辨率进行位置编码同时加上lidar特征,然后让其作为transformer里的Q查询向量往图像特征,图像位置编码和内外参编码组成的KV里面查询,经过交叉注意力机制最终输出查询后得到的BEV特征。
第三类显示逆向转换:显式转换是将图像向BEV转,那我直接先指定好BEV空间的体素位置,根据体素的位置(X,Y,Z)这样根据内外参可以查询得到像素空间的(x,y,z)直接把对应的像素特征赋给BEV的体素。
一、显示转换的BEV感知
1.LSS
论文链接:https://arxiv.org/pdf/2008.05711.pdf
概述:LSS的思想是对每个像素预测一个D维的深度分布,然后HWD与HWC外积,得到一个HWDC的特征,给定一个hwd,我们根据相机内外参可以将其转化到BEV空间里的一个XYZ,这样把所有像素空间的HWD都转到BEV,最终按照体素pooling池化一下,就得到了BEV特征
优点:实现了相机特征到BEV特征的转换
缺点:极度的依赖depth预测的准确性,同时矩阵外积过于耗时,要想在depth维度有较高的精度,HWD计算量特别大。
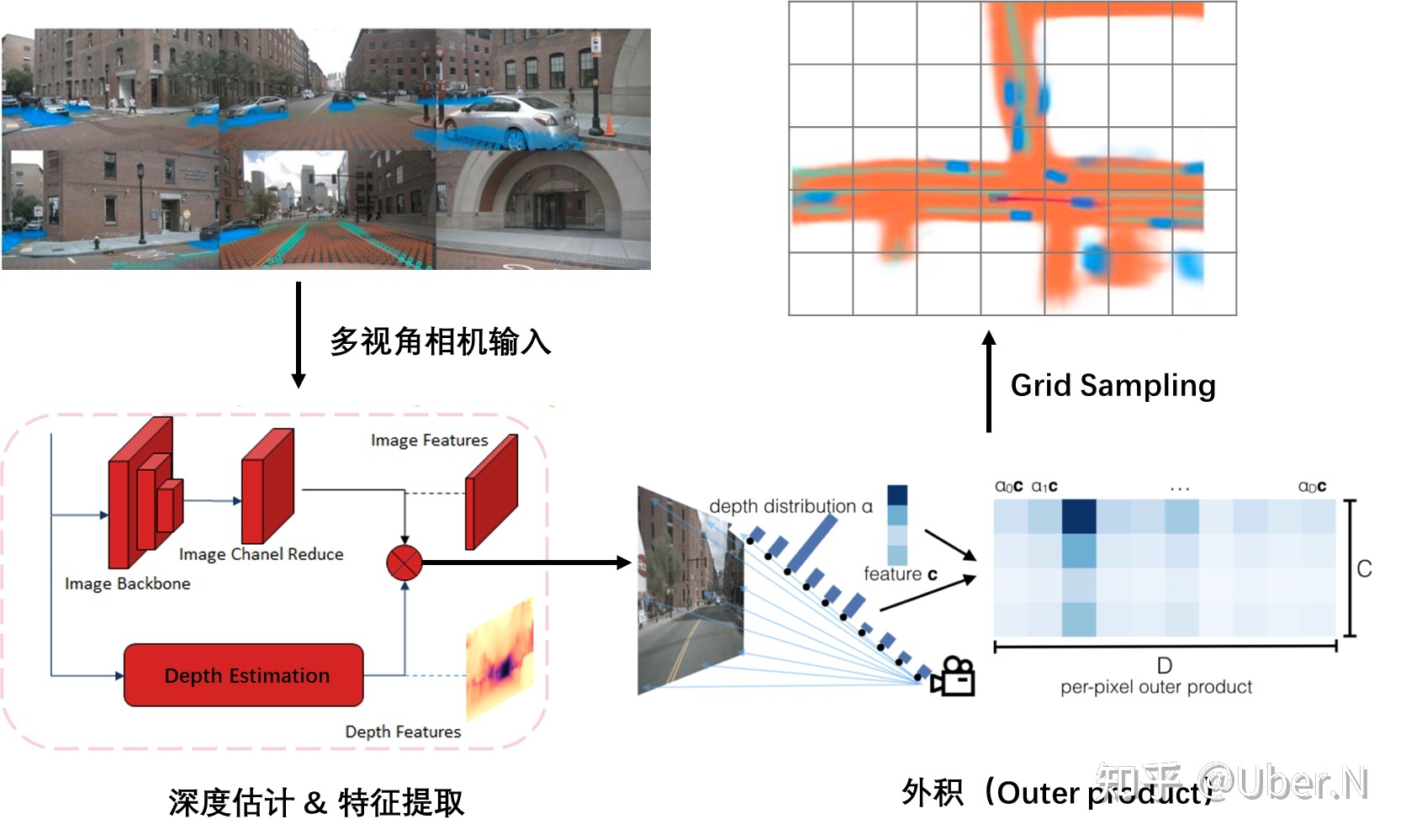
A:Lift操作
LSS中的L表示lift,升维的意思,表示把H*W*C的图像特征升维到H*W*D*C,D表示在每个像素点都预测了一个D维的深度信息,比如D是50维,相当于这个像素点在0-50m里出现的概率。D的一个维度表示在这一米出现的概率。
第一步:get_geometry(得到特征图与3D空间的索引对应)
torch.arange生成D的列表,view加expand变成(D,H,W)的维度
torch.linespace生成特征图长宽HW的列表分布,里面的值是像素坐标,同样view+expand变为(D,H,W),然后用torch.stack将这三个在-1维度拼接。得到(D,H,W,3)的矩阵,相当于给定一个D,H,W的特征点,我们可以得到三维的像素坐标表示,这个像素坐标需要转换到真实车身坐标系。
将图像数据增强进行抵消,同时根据相机内外参矩阵与上面的相乘,得到(D,H,W,3)这个3表示的就是车身坐标系的3D位置。此时我们就可以根据一个D,H,W索引的特征点,得到其在真实空间的位置。这一步是接下来投影的关键。
第二步:get_cam_feats(得到相机的D,H,W型feature)
图像经过骨干网络处理之后,用一个1*1的卷积,将channel变为D+C,在channel维度选取前D维,进行softmax操作,相当于说这个H,W的特征点在D的深度上的分布概率。将(N,1,D)和(N,C,1)做乘法,相当于矩阵外积,得到(N,C,D)的张量,N表示的是H*W,所以我们就得到了(D,H,W,C)的图像特征。
B:Splat操作
splat表示拍平的意思,上一步我们得到了像素空间与真实3D空间的坐标索引,同时也得到了(D,H,W,C)的图像特征高维表示。这一步就是把特征转换到BEV空间中,并拍平为2D,相当于pointpillar的操作。
第一步:预处理操作
传进来的就是geom_feats维度为(D,H,W,3)和X图像高维特征(D,H,W,C),首先geom_feats里3这个维度,里面的值是车身坐标系的3D位置,有正有负,我们先把他变为从0开始的长整形分布,比如x是0-100m,y是0-60m,z是0-5m这样,全为正的表示,相当于做个平移。然后view成(Nprime,3),然后循环batch,用torch.cat以及torch.full生成一个(Nprime,1)的batch索引,再和geom_feats用torch.cat一下,得到新的geom_feats维度为(Nprime,4),里面是真实空间的xyzb,然后用xyz的范围进行过滤一下。
第二步:拍平操作
得到维度为(Nprime,4)的geom_feats,这里说的也不准确,因为过滤了范围外的,第一维度就不再是Nprime,大家理解就行。然后根据BEV分辨率对geom_feats进行排序,geom_feats[:,0]*Y*Z*B+geom_feats[:,1]*Z*B+geom_feats[:,2]*B+geom_feats[:,3],然后argsort排序,对X以及geom_feats进行排序。X维度为(Nprime,C),对其进行cumsum操作,也叫前缀和操作,然后找到网格变化的节点,用当前变化节点减去前面的变化节点,就是中间这个网格的和,起到了一个sum_pooling操作,最后根据geom_feats的索引,把X放入到(B,C,Z,X,Y)里面,再把Z用unbind和cat操作压缩即可。
代码分析
"""
Copyright (C) 2020 NVIDIA Corporation. All rights reserved.
Licensed under the NVIDIA Source Code License. See LICENSE at https://github.com/nv-tlabs/lift-splat-shoot.
Authors: Jonah Philion and Sanja Fidler
"""
import torch
from torch import nn
from efficientnet_pytorch import EfficientNet
from torchvision.models.resnet import resnet18
from .tools import gen_dx_bx, cumsum_trick, QuickCumsum
class Up(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super().__init__()
self.up = nn.Upsample(scale_factor=scale_factor, mode='bilinear',
align_corners=True)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x1, x2):
x1 = self.up(x1)
x1 = torch.cat([x2, x1], dim=1)
return self.conv(x1)
class CamEncode(nn.Module):
def __init__(self, D, C, downsample):
super(CamEncode, self).__init__()
self.D = D
self.C = C
self.trunk = EfficientNet.from_pretrained("efficientnet-b0")
self.up1 = Up(320+112, 512)
self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)
def get_depth_dist(self, x, eps=1e-20):
return x.softmax(dim=1)
def get_depth_feat(self, x):
x = self.get_eff_depth(x)
# Depth
x = self.depthnet(x) #得到(B*N, D+C, fH,fW)
depth = self.get_depth_dist(x[:, :self.D]) #在深度维度进行softmax操作
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2) #(B*N,1,D,fH,fW) *(B*N,C,1,fH,fW)
return depth, new_x #返回维度为 (B*N,C,D,fH,fW)
def get_eff_depth(self, x):
# adapted from https://github.com/lukemelas/EfficientNet-PyTorch/blob/master/efficientnet_pytorch/model.py#L231
endpoints = dict()
# Stem
x = self.trunk._swish(self.trunk._bn0(self.trunk._conv_stem(x)))
prev_x = x
# Blocks
for idx, block in enumerate(self.trunk._blocks):
drop_connect_rate = self.trunk._global_params.drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float(idx) / len(self.trunk._blocks) # scale drop connect_rate
x = block(x, drop_connect_rate=drop_connect_rate)
if prev_x.size(2) > x.size(2):
endpoints['reduction_{}'.format(len(endpoints)+1)] = prev_x
prev_x = x
# Head
endpoints['reduction_{}'.format(len(endpoints)+1)] = x
x = self.up1(endpoints['reduction_5'], endpoints['reduction_4'])
return x
def forward(self, x):
depth, x = self.get_depth_feat(x)
return x
class BevEncode(nn.Module):
def __init__(self, inC, outC):
super(BevEncode, self).__init__()
trunk = resnet18(pretrained=False, zero_init_residual=True)
self.conv1 = nn.Conv2d(inC, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = trunk.bn1
self.relu = trunk.relu
self.layer1 = trunk.layer1
self.layer2 = trunk.layer2
self.layer3 = trunk.layer3
self.up1 = Up(64+256, 256, scale_factor=4)
self.up2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear',
align_corners=True),
nn.Conv2d(256, 128, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, outC, kernel_size=1, padding=0),
)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x1 = self.layer1(x)
x = self.layer2(x1)
x = self.layer3(x)
x = self.up1(x, x1)
x = self.up2(x)
return x
def cumsum_trick(x, geom_feats, ranks):
x = x.cumsum(0) #(N,C) 0表示后面的行累加前面的行。
kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool)
kept[:-1] = (ranks[1:] != ranks[:-1])#当后面一位与前面的值不一样时,为1.相当于得到voxel变化时的边界点
x, geom_feats = x[kept], geom_feats[kept] #得到变化时的特征和坐标映射
x = torch.cat((x[:1], x[1:] - x[:-1]))#后面的减去前面的得到当前voxel的特征和。
return x, geom_feats #此时得到每个voxel的特征和
class LiftSplatShoot(nn.Module):
def __init__(self, grid_conf, data_aug_conf, outC):
super(LiftSplatShoot, self).__init__()
self.grid_conf = grid_conf
self.data_aug_conf = data_aug_conf
dx, bx, nx = gen_dx_bx(self.grid_conf['xbound'],
self.grid_conf['ybound'],
self.grid_conf['zbound'],
)
self.dx = nn.Parameter(dx, requires_grad=False)
self.bx = nn.Parameter(bx, requires_grad=False)
self.nx = nn.Parameter(nx, requires_grad=False)
self.downsample = 16
self.camC = 64
self.frustum = self.create_frustum()
self.D, _, _, _ = self.frustum.shape
self.camencode = CamEncode(self.D, self.camC, self.downsample)
self.bevencode = BevEncode(inC=self.camC, outC=outC)
# toggle using QuickCumsum vs. autograd
self.use_quickcumsum = True
def create_frustum(self):
# make grid in image plane
ogfH, ogfW = self.data_aug_conf['final_dim'] #得到原始图片的分辨率
fH, fW = ogfH // self.downsample, ogfW // self.downsample #得到图片特征图上的分辨率
#预设的深度范围,如4-45m,每隔1m取个点,得到ds维度 [D,fH,fW]
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)
D, _, _ = ds.shape
# 在原始分辨率上取fW个x,fH个y,他们的维度是[D,fH,fW]
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)
# D x H x W x 3
frustum = torch.stack((xs, ys, ds), -1)
return nn.Parameter(frustum, requires_grad=False)
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""Determine the (x,y,z) locations (in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/downsample x W/downsample x 3
"""
B, N, _ = trans.shape
# undo post-transformation
# self.frustum是一个图像像素3D坐标,维度为B x N x D x H x W x 3,B是batch_size,N是相机个数。
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3) #减去数据增强的平移矩阵
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1)) #数据增强旋转矩阵的逆与像素3D坐标相乘
# cam_to_ego 这一块看像素坐标系到车身坐标系的转换公式。λ(x,y,1) = .....
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5)
combine = rots.matmul(torch.inverse(intrins)) #外参旋转矩阵与内参矩阵的逆相乘
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1) #旋转矩阵与内参矩阵的逆与像素坐标相乘
points += trans.view(B, N, 1, 1, 1, 3) #加上外参平移矩阵得到BEV车身坐标系下的xyz
return points
def get_cam_feats(self, x):
"""Return B x N x D x H/downsample x W/downsample x C
"""
B, N, C, imH, imW = x.shape #得到原始图片
x = x.view(B*N, C, imH, imW) #把batch_size和N个相机合并
x = self.camencode(x) #先送入骨干,然后把特征维度变为D+C,前D维softmax,然后外积得到(B*N,C,D,fH,fW)
x = x.view(B, N, self.camC, self.D, imH//self.downsample, imW//self.downsample)
x = x.permute(0, 1, 3, 4, 5, 2)
return x #返回特征维度 [B,N,D,fH,fW,C]
def voxel_pooling(self, geom_feats, x):
B, N, D, H, W, C = x.shape
Nprime = B*N*D*H*W
# flatten x
x = x.reshape(Nprime, C) #将所有的维度压缩在一起,除了C
# B x N x D x H x W x 3将车身坐标系的坐标变为从000开始的
geom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()
geom_feats = geom_feats.view(Nprime, 3)
#得到[Nprime,1]的batch_idx下标。
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,
device=x.device, dtype=torch.long) for ix in range(B)])
#得到(Nprime, 4)里面4维是三维的BEV坐标和一个batch_idx
geom_feats = torch.cat((geom_feats, batch_ix), 1)
# 过滤掉不在BEV范围里的下标。
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
x = x[kept]
geom_feats = geom_feats[kept]
# get tensors from the same voxel next to each other
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3] #得到一个维度为(N)的向量,这个值是他们的下标,在一个voxel里的其ranks是一样的
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] #根据下标进行排序,这样一个voxel的点就在一块。
# cumsum trick
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks) #这个函数进行cumsum操作
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# griddify (B x C x Z x X x Y)
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x #根据投影矩阵B,Z,Y,X将x放入预定义的空的BEV特征上
# collapse Z,使用unbind对Z进行切片,然后在channel层进行cat
final = torch.cat(final.unbind(dim=2), 1)
return final
def get_voxels(self, x, rots, trans, intrins, post_rots, post_trans):
geom = self.get_geometry(rots, trans, intrins, post_rots, post_trans) #得到像素3D坐标和BEV的坐标索引表
x = self.get_cam_feats(x) #得到图像的特征维度 [B,N,D,fH,fW,C]
x = self.voxel_pooling(geom, x) #根据图像特征和索引表,进行池化操作,得到BEV特征。
return x
def forward(self, x, rots, trans, intrins, post_rots, post_trans):
x = self.get_voxels(x, rots, trans, intrins, post_rots, post_trans) #这里是最关键的LSS操作
x = self.bevencode(x)
return x
def compile_model(grid_conf, data_aug_conf, outC):
return LiftSplatShoot(grid_conf, data_aug_conf, outC)2.BEVDet
论文:https://arxiv.org/pdf/2112.11790.pdf
代码:GitHub - HuangJunJie2017/BEVDet: Official code base of the BEVDet series .
论文创新点:
针对LSS在训练时特别容易过拟合,采取了两种数据增强,一种是在图像域,一种是在BEV下。
改进版的scale-NMS,因为在BEV下,有些物体特别小,后处理时没有交集,无法过滤重复预测,如锥桶和行人,在BEV上不到一个分辨率,这样冗余预测也不会有交集,我们就把其scale放大之后再进行iou去冗余。
在图像上采用的数据增强如:翻转,缩放,旋转都可以表示为一个3*3的矩阵,在img2bev的时候再乘以该矩阵的逆,这样图像和BEV空间的位置还是一一对应的,就是相当于无论怎么数据增强,这个图片的BEV位置都是不变的,增强图像特征网络的泛化性能。当然,在BEV上也做了数据增强,这时对于GT也要做相应的处理。
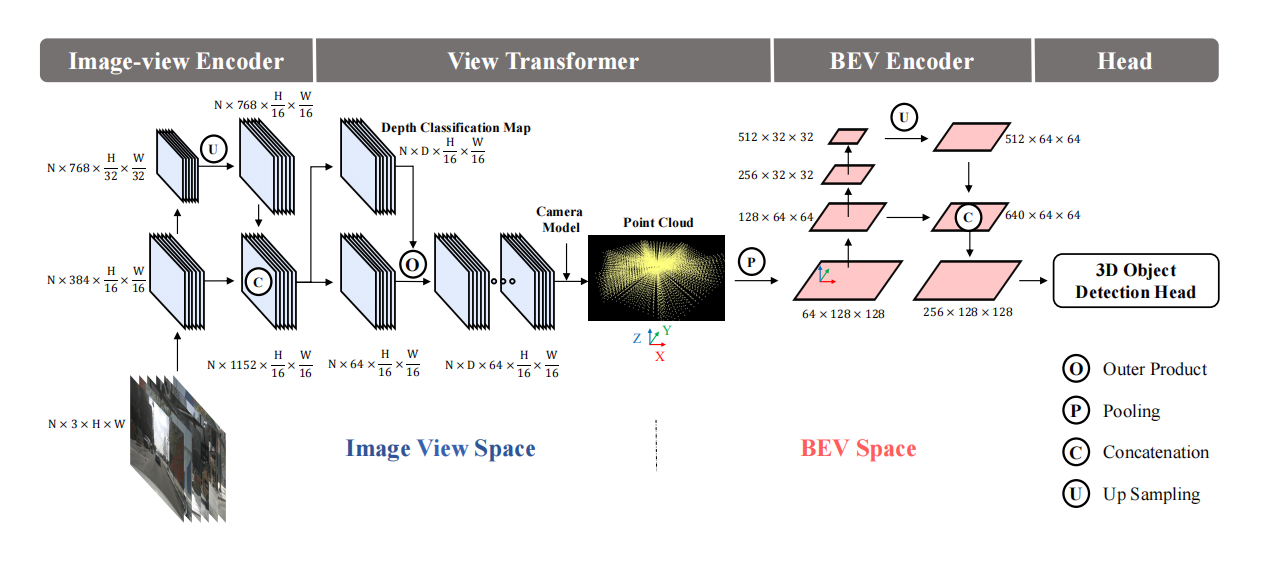
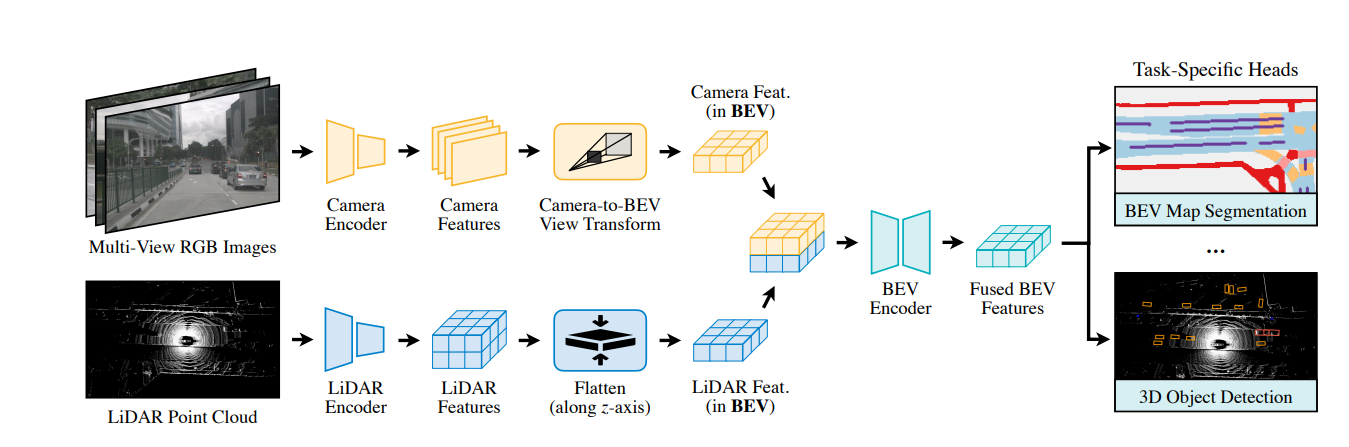
3.BEVFusion
论文:https://arxiv.org/pdf/2205.13542.pdf
论文创新点:
开创性的BEV上的lidar和camer融合框架
针对LSS池化操作过慢,进行了优化处理,大大加快其推理速度。
在图像backbone种有两个选项:Resnet34和swintransformer。而在head部分,一个是centerhead,一个是transfusion,具体的看代码。
针对LSS池化操作的优化有两点:
1.预计算
LSS池化的第一步是将像素空间的3D点与BEV空间的伪点云建立关联,而像素空间的点云坐标位置是固定的,可以预先计算其编码,然后排序,记录下下标,推理时直接对像素空间3D点进行排序。从原先的17ms,优化到4ms
2.间歇降低
LSS池化是对网格里面的点求和聚集特征,用的cumsum操作,前缀和,所有的点都要求前缀和,然后用当前边界的前缀和减去前一个边界前缀和,来得到当前网格的特征sum,这种操作是低效的,而论文中自己编写了一个GPU内核,为每个网格分配了一个GPU的线程,来计算间歇和并返回结果。速度从500ms降到2ms。
@HEADS.register_module()
class TransFusionHead(nn.Module):
def __init__(
self,
num_proposals=128,
auxiliary=True,
in_channels=128 * 3,
hidden_channel=128,
num_classes=4,
# config for Transformer
num_decoder_layers=3,
num_heads=8,
nms_kernel_size=1,
ffn_channel=256,
dropout=0.1,
bn_momentum=0.1,
activation="relu",
# config for FFN
common_heads=dict(),
num_heatmap_convs=2,
conv_cfg=dict(type="Conv1d"),
norm_cfg=dict(type="BN1d"),
bias="auto",
# loss
loss_cls=dict(type="GaussianFocalLoss", reduction="mean"),
loss_iou=dict(
type="VarifocalLoss", use_sigmoid=True, iou_weighted=True, reduction="mean"
),
loss_bbox=dict(type="L1Loss", reduction="mean"),
loss_heatmap=dict(type="GaussianFocalLoss", reduction="mean"),
# others
train_cfg=None,
test_cfg=None,
bbox_coder=None,
):
super(TransFusionHead, self).__init__()
self.fp16_enabled = False
self.num_classes = num_classes
self.num_proposals = num_proposals
self.auxiliary = auxiliary
self.in_channels = in_channels
self.num_heads = num_heads
self.num_decoder_layers = num_decoder_layers
self.bn_momentum = bn_momentum
self.nms_kernel_size = nms_kernel_size
self.train_cfg = train_cfg
self.test_cfg = test_cfg
self.use_sigmoid_cls = loss_cls.get("use_sigmoid", False)
if not self.use_sigmoid_cls:
self.num_classes += 1
self.loss_cls = build_loss(loss_cls)
self.loss_bbox = build_loss(loss_bbox)
self.loss_iou = build_loss(loss_iou)
self.loss_heatmap = build_loss(loss_heatmap)
self.bbox_coder = build_bbox_coder(bbox_coder)
self.sampling = False
# a shared convolution
self.shared_conv = build_conv_layer(
dict(type="Conv2d"),
in_channels,
hidden_channel,
kernel_size=3,
padding=1,
bias=bias,
)
layers = []
layers.append(
ConvModule(
hidden_channel,
hidden_channel,
kernel_size=3,
padding=1,
bias=bias,
conv_cfg=dict(type="Conv2d"),
norm_cfg=dict(type="BN2d"),
)
)
layers.append(
build_conv_layer(
dict(type="Conv2d"),
hidden_channel,
num_classes,
kernel_size=3,
padding=1,
bias=bias,
)
)
self.heatmap_head = nn.Sequential(*layers)
self.class_encoding = nn.Conv1d(num_classes, hidden_channel, 1)
# transformer decoder layers for object query with LiDAR feature
self.decoder = nn.ModuleList()
for i in range(self.num_decoder_layers):
self.decoder.append(
TransformerDecoderLayer(
hidden_channel,
num_heads,
ffn_channel,
dropout,
activation,
self_posembed=PositionEmbeddingLearned(2, hidden_channel),
cross_posembed=PositionEmbeddingLearned(2, hidden_channel),
)
)
# Prediction Head
self.prediction_heads = nn.ModuleList()
for i in range(self.num_decoder_layers):
heads = copy.deepcopy(common_heads)
heads.update(dict(heatmap=(self.num_classes, num_heatmap_convs)))
self.prediction_heads.append(
FFN(
hidden_channel,
heads,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
bias=bias,
)
)
self.init_weights()
self._init_assigner_sampler()
# Position Embedding for Cross-Attention, which is re-used during training
x_size = self.test_cfg["grid_size"][0] // self.test_cfg["out_size_factor"]
y_size = self.test_cfg["grid_size"][1] // self.test_cfg["out_size_factor"]
self.bev_pos = self.create_2D_grid(x_size, y_size)
self.img_feat_pos = None
self.img_feat_collapsed_pos = None
def create_2D_grid(self, x_size, y_size):
meshgrid = [[0, x_size - 1, x_size], [0, y_size - 1, y_size]]
# NOTE: modified
batch_x, batch_y = torch.meshgrid(
*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid]
)
batch_x = batch_x + 0.5
batch_y = batch_y + 0.5
coord_base = torch.cat([batch_x[None], batch_y[None]], dim=0)[None]
coord_base = coord_base.view(1, 2, -1).permute(0, 2, 1)
return coord_base
def init_weights(self):
# initialize transformer
for m in self.decoder.parameters():
if m.dim() > 1:
nn.init.xavier_uniform_(m)
if hasattr(self, "query"):
nn.init.xavier_normal_(self.query)
self.init_bn_momentum()
def init_bn_momentum(self):
for m in self.modules():
if isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):
m.momentum = self.bn_momentum
def _init_assigner_sampler(self):
"""Initialize the target assigner and sampler of the head."""
if self.train_cfg is None:
return
if self.sampling:
self.bbox_sampler = build_sampler(self.train_cfg.sampler)
else:
self.bbox_sampler = PseudoSampler()
if isinstance(self.train_cfg.assigner, dict):
self.bbox_assigner = build_assigner(self.train_cfg.assigner)
elif isinstance(self.train_cfg.assigner, list):
self.bbox_assigner = [
build_assigner(res) for res in self.train_cfg.assigner
]
def forward_single(self, inputs, img_inputs, metas):
"""Forward function for CenterPoint.
Args:
inputs (torch.Tensor): Input feature map with the shape of
[B, 512, 128(H), 128(W)]. (consistent with L748)
Returns:
list[dict]: Output results for tasks.
"""
batch_size = inputs.shape[0]
lidar_feat = self.shared_conv(inputs) #[B, 128, 180, 180]
#################################
# image to BEV
#################################
lidar_feat_flatten = lidar_feat.view(
batch_size, lidar_feat.shape[1], -1
) # [B , C, H*W]
bev_pos = self.bev_pos.repeat(batch_size, 1, 1).to(lidar_feat.device)
# 从[1, 32400, 2] ---- [B, 32400, 2]
#################################
# image guided query initialization
#################################
dense_heatmap = self.heatmap_head(lidar_feat) #[B, 10, 180,180]
dense_heatmap_img = None
heatmap = dense_heatmap.detach().sigmoid() #[B, 10, 180,180]
padding = self.nms_kernel_size // 2 # 3//2 = 1
local_max = torch.zeros_like(heatmap)
# equals to nms radius = voxel_size * out_size_factor * kenel_size
local_max_inner = F.max_pool2d(
heatmap, kernel_size=self.nms_kernel_size, stride=1, padding=0
) # [B, 10, 178, 178]
local_max[:, :, padding:(-padding), padding:(-padding)] = local_max_inner #将求完3*3max的值赋给local_max
## for Pedestrian & Traffic_cone in nuScenes
if self.test_cfg["dataset"] == "nuScenes":
local_max[
:,
8,
] = F.max_pool2d(heatmap[:, 8], kernel_size=1, stride=1, padding=0)
local_max[
:,
9,
] = F.max_pool2d(heatmap[:, 9], kernel_size=1, stride=1, padding=0)
elif self.test_cfg["dataset"] == "Waymo": # for Pedestrian & Cyclist in Waymo
local_max[
:,
1,
] = F.max_pool2d(heatmap[:, 1], kernel_size=1, stride=1, padding=0)
local_max[
:,
2,
] = F.max_pool2d(heatmap[:, 2], kernel_size=1, stride=1, padding=0)
heatmap = heatmap * (heatmap == local_max) #根据像素值是否等于max值来找最大值的位置,处理之后不是局部最大值的地方都为0
heatmap = heatmap.view(batch_size, heatmap.shape[1], -1) # [B, 10, 32400]
# top #num_proposals among all classes
top_proposals = heatmap.view(batch_size, -1).argsort(dim=-1, descending=True)[
..., : self.num_proposals
] #将所有的类别heatmap放一块,取前topk [B, k]
top_proposals_class = top_proposals // heatmap.shape[-1] #除以32400看是哪个类 [B,K]
top_proposals_index = top_proposals % heatmap.shape[-1] #看是32400里的哪个位置
query_feat = lidar_feat_flatten.gather(
index=top_proposals_index[:, None, :].expand(
-1, lidar_feat_flatten.shape[1], -1
),
dim=-1,
) #得到[B, C, K] 从32400个特征里查询K个
self.query_labels = top_proposals_class #[B,K]
# add category embedding
one_hot = F.one_hot(top_proposals_class, num_classes=self.num_classes).permute(
0, 2, 1
) #生成独热向量 [B, 10, 200],200个候选框也就是上面的K,每个都有10个类别可选。
query_cat_encoding = self.class_encoding(one_hot.float()) # [B, C, 200]
query_feat += query_cat_encoding #将特征与类别编码特征相加
query_pos = bev_pos.gather(
index=top_proposals_index[:, None, :]
.permute(0, 2, 1)
.expand(-1, -1, bev_pos.shape[-1]),
dim=1,
) #得到200个的位置编码。 [B, 200, 2]
#################################
# transformer decoder layer (LiDAR feature as K,V)
#################################
ret_dicts = []
for i in range(self.num_decoder_layers):
prefix = "last_" if (i == self.num_decoder_layers - 1) else f"{i}head_" #判断是不是最后一层
# Transformer Decoder Layer
# :param query: B C Pq :param query_pos: B Pq 3/6
query_feat = self.decoder[i](
query_feat, lidar_feat_flatten, query_pos, bev_pos
) #查询向量的初始化特征 [B,C,K], 融合特征[B,C,32400] [B, 200, 2] [B, 32400, 2]
# Prediction 上面解码完得到query[B, C, 200]
res_layer = self.prediction_heads[i](query_feat)# 得到一个字典里面是centor[B,2,200],height[B,1,200],dim[B,3,200],rot[B,2,200],heatmap[B,10,200]
res_layer["center"] = res_layer["center"] + query_pos.permute(0, 2, 1) #得到更精细的位置
first_res_layer = res_layer
ret_dicts.append(res_layer)
# for next level positional embedding
query_pos = res_layer["center"].detach().clone().permute(0, 2, 1)
#################################
# transformer decoder layer (img feature as K,V)
#################################
ret_dicts[0]["query_heatmap_score"] = heatmap.gather(
index=top_proposals_index[:, None, :].expand(-1, self.num_classes, -1),
dim=-1,
) # [B, num_classes, num_proposals]得到200个候选框的heatmap评分
ret_dicts[0]["dense_heatmap"] = dense_heatmap #[B, 10, 180,180]sigmoid前的
if self.auxiliary is False:
# only return the results of last decoder layer
return [ret_dicts[-1]]
# return all the layer's results for auxiliary superivison
new_res = {}
for key in ret_dicts[0].keys(): #将多层的解码结果放一块,共同预测在200维度
if key not in ["dense_heatmap", "dense_heatmap_old", "query_heatmap_score"]:
new_res[key] = torch.cat(
[ret_dict[key] for ret_dict in ret_dicts], dim=-1
)
else:
new_res[key] = ret_dicts[0][key]
return [new_res]
def forward(self, feats, metas):
"""Forward pass.
Args:
feats (list[torch.Tensor]): Multi-level features, e.g.,
features produced by FPN.
Returns:
tuple(list[dict]): Output results. first index by level, second index by layer
"""
if isinstance(feats, torch.Tensor):
feats = [feats] #[12, 512, 180, 180]
res = multi_apply(self.forward_single, feats, [None], [metas])
assert len(res) == 1, "only support one level features."
return res
def get_targets(self, gt_bboxes_3d, gt_labels_3d, preds_dict):
"""Generate training targets.
Args:
gt_bboxes_3d (:obj:`LiDARInstance3DBoxes`): Ground truth gt boxes.
gt_labels_3d (torch.Tensor): Labels of boxes.
preds_dicts (tuple of dict): first index by layer (default 1)
Returns:
tuple[torch.Tensor]: Tuple of target including \
the following results in order.
- torch.Tensor: classification target. [BS, num_proposals]
- torch.Tensor: classification weights (mask) [BS, num_proposals]
- torch.Tensor: regression target. [BS, num_proposals, 8]
- torch.Tensor: regression weights. [BS, num_proposals, 8]
"""
# change preds_dict into list of dict (index by batch_id)
# preds_dict[0]['center'].shape [bs, 3, num_proposal]
list_of_pred_dict = []
for batch_idx in range(len(gt_bboxes_3d)):
pred_dict = {}
for key in preds_dict[0].keys():
pred_dict[key] = preds_dict[0][key][batch_idx : batch_idx + 1]
list_of_pred_dict.append(pred_dict)
assert len(gt_bboxes_3d) == len(list_of_pred_dict)
res_tuple = multi_apply(
self.get_targets_single,
gt_bboxes_3d,
gt_labels_3d,
list_of_pred_dict,
np.arange(len(gt_labels_3d)),
)
labels = torch.cat(res_tuple[0], dim=0)
label_weights = torch.cat(res_tuple[1], dim=0)
bbox_targets = torch.cat(res_tuple[2], dim=0)
bbox_weights = torch.cat(res_tuple[3], dim=0)
ious = torch.cat(res_tuple[4], dim=0)
num_pos = np.sum(res_tuple[5])
matched_ious = np.mean(res_tuple[6])
heatmap = torch.cat(res_tuple[7], dim=0)
return (
labels,
label_weights,
bbox_targets,
bbox_weights,
ious,
num_pos,
matched_ious,
heatmap,
)
def get_targets_single(self, gt_bboxes_3d, gt_labels_3d, preds_dict, batch_idx):
"""Generate training targets for a single sample.
Args:
gt_bboxes_3d (:obj:`LiDARInstance3DBoxes`): Ground truth gt boxes.
gt_labels_3d (torch.Tensor): Labels of boxes.
preds_dict (dict): dict of prediction result for a single sample
Returns:
tuple[torch.Tensor]: Tuple of target including \
the following results in order.
- torch.Tensor: classification target. [1, num_proposals]
- torch.Tensor: classification weights (mask) [1, num_proposals]
- torch.Tensor: regression target. [1, num_proposals, 8]
- torch.Tensor: regression weights. [1, num_proposals, 8]
- torch.Tensor: iou target. [1, num_proposals]
- int: number of positive proposals
"""
num_proposals = preds_dict["center"].shape[-1]
# get pred boxes, carefully ! donot change the network outputs
score = copy.deepcopy(preds_dict["heatmap"].detach())
center = copy.deepcopy(preds_dict["center"].detach())
height = copy.deepcopy(preds_dict["height"].detach())
dim = copy.deepcopy(preds_dict["dim"].detach())
rot = copy.deepcopy(preds_dict["rot"].detach())
if "vel" in preds_dict.keys():
vel = copy.deepcopy(preds_dict["vel"].detach())
else:
vel = None
boxes_dict = self.bbox_coder.decode(
score, rot, dim, center, height, vel
) # decode the prediction to real world metric bbox
bboxes_tensor = boxes_dict[0]["bboxes"]
gt_bboxes_tensor = gt_bboxes_3d.tensor.to(score.device)
# each layer should do label assign seperately.
if self.auxiliary:
num_layer = self.num_decoder_layers
else:
num_layer = 1
assign_result_list = []
for idx_layer in range(num_layer):
bboxes_tensor_layer = bboxes_tensor[
self.num_proposals * idx_layer : self.num_proposals * (idx_layer + 1), :
]
score_layer = score[
...,
self.num_proposals * idx_layer : self.num_proposals * (idx_layer + 1),
]
if self.train_cfg.assigner.type == "HungarianAssigner3D":
assign_result = self.bbox_assigner.assign(
bboxes_tensor_layer,
gt_bboxes_tensor,
gt_labels_3d,
score_layer,
self.train_cfg,
)
elif self.train_cfg.assigner.type == "HeuristicAssigner":
assign_result = self.bbox_assigner.assign(
bboxes_tensor_layer,
gt_bboxes_tensor,
None,
gt_labels_3d,
self.query_labels[batch_idx],
)
else:
raise NotImplementedError
assign_result_list.append(assign_result)
# combine assign result of each layer
assign_result_ensemble = AssignResult(
num_gts=sum([res.num_gts for res in assign_result_list]),
gt_inds=torch.cat([res.gt_inds for res in assign_result_list]),
max_overlaps=torch.cat([res.max_overlaps for res in assign_result_list]),
labels=torch.cat([res.labels for res in assign_result_list]),
)
sampling_result = self.bbox_sampler.sample(
assign_result_ensemble, bboxes_tensor, gt_bboxes_tensor
)
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
assert len(pos_inds) + len(neg_inds) == num_proposals
# create target for loss computation
bbox_targets = torch.zeros([num_proposals, self.bbox_coder.code_size]).to(
center.device
)
bbox_weights = torch.zeros([num_proposals, self.bbox_coder.code_size]).to(
center.device
)
ious = assign_result_ensemble.max_overlaps
ious = torch.clamp(ious, min=0.0, max=1.0)
labels = bboxes_tensor.new_zeros(num_proposals, dtype=torch.long)
label_weights = bboxes_tensor.new_zeros(num_proposals, dtype=torch.long)
if gt_labels_3d is not None: # default label is -1
labels += self.num_classes
# both pos and neg have classification loss, only pos has regression and iou loss
if len(pos_inds) > 0:
pos_bbox_targets = self.bbox_coder.encode(sampling_result.pos_gt_bboxes)
bbox_targets[pos_inds, :] = pos_bbox_targets
bbox_weights[pos_inds, :] = 1.0
if gt_labels_3d is None:
labels[pos_inds] = 1
else:
labels[pos_inds] = gt_labels_3d[sampling_result.pos_assigned_gt_inds]
if self.train_cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = self.train_cfg.pos_weight
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# # compute dense heatmap targets
device = labels.device
gt_bboxes_3d = torch.cat(
[gt_bboxes_3d.gravity_center, gt_bboxes_3d.tensor[:, 3:]], dim=1
).to(device)
grid_size = torch.tensor(self.train_cfg["grid_size"])
pc_range = torch.tensor(self.train_cfg["point_cloud_range"])
voxel_size = torch.tensor(self.train_cfg["voxel_size"])
feature_map_size = (
grid_size[:2] // self.train_cfg["out_size_factor"]
) # [x_len, y_len]
heatmap = gt_bboxes_3d.new_zeros(
self.num_classes, feature_map_size[1], feature_map_size[0]
)
for idx in range(len(gt_bboxes_3d)):
width = gt_bboxes_3d[idx][3]
length = gt_bboxes_3d[idx][4]
width = width / voxel_size[0] / self.train_cfg["out_size_factor"]
length = length / voxel_size[1] / self.train_cfg["out_size_factor"]
if width > 0 and length > 0:
radius = gaussian_radius(
(length, width), min_overlap=self.train_cfg["gaussian_overlap"]
)
radius = max(self.train_cfg["min_radius"], int(radius))
x, y = gt_bboxes_3d[idx][0], gt_bboxes_3d[idx][1]
coor_x = (
(x - pc_range[0])
/ voxel_size[0]
/ self.train_cfg["out_size_factor"]
)
coor_y = (
(y - pc_range[1])
/ voxel_size[1]
/ self.train_cfg["out_size_factor"]
)
center = torch.tensor(
[coor_x, coor_y], dtype=torch.float32, device=device
)
center_int = center.to(torch.int32)
# original
# draw_heatmap_gaussian(heatmap[gt_labels_3d[idx]], center_int, radius)
# NOTE: fix
draw_heatmap_gaussian(
heatmap[gt_labels_3d[idx]], center_int[[1, 0]], radius
)
mean_iou = ious[pos_inds].sum() / max(len(pos_inds), 1)
return (
labels[None],
label_weights[None],
bbox_targets[None],
bbox_weights[None],
ious[None],
int(pos_inds.shape[0]),
float(mean_iou),
heatmap[None],
)
@force_fp32(apply_to=("preds_dicts"))
def loss(self, gt_bboxes_3d, gt_labels_3d, preds_dicts, **kwargs):
"""Loss function for CenterHead.
Args:
gt_bboxes_3d (list[:obj:`LiDARInstance3DBoxes`]): Ground
truth gt boxes.
gt_labels_3d (list[torch.Tensor]): Labels of boxes.
preds_dicts (list[list[dict]]): Output of forward function.
Returns:
dict[str:torch.Tensor]: Loss of heatmap and bbox of each task.
"""
(
labels,
label_weights,
bbox_targets,
bbox_weights,
ious,
num_pos,
matched_ious,
heatmap,
) = self.get_targets(gt_bboxes_3d, gt_labels_3d, preds_dicts[0])
if hasattr(self, "on_the_image_mask"):
label_weights = label_weights * self.on_the_image_mask
bbox_weights = bbox_weights * self.on_the_image_mask[:, :, None]
num_pos = bbox_weights.max(-1).values.sum()
preds_dict = preds_dicts[0][0]
loss_dict = dict()
# compute heatmap loss
loss_heatmap = self.loss_heatmap(
clip_sigmoid(preds_dict["dense_heatmap"]),
heatmap,
avg_factor=max(heatmap.eq(1).float().sum().item(), 1),
)
loss_dict["loss_heatmap"] = loss_heatmap
# compute loss for each layer
for idx_layer in range(self.num_decoder_layers if self.auxiliary else 1):
if idx_layer == self.num_decoder_layers - 1 or (
idx_layer == 0 and self.auxiliary is False
):
prefix = "layer_-1"
else:
prefix = f"layer_{idx_layer}"
layer_labels = labels[
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
].reshape(-1)
layer_label_weights = label_weights[
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
].reshape(-1)
layer_score = preds_dict["heatmap"][
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
]
layer_cls_score = layer_score.permute(0, 2, 1).reshape(-1, self.num_classes)
layer_loss_cls = self.loss_cls(
layer_cls_score,
layer_labels,
layer_label_weights,
avg_factor=max(num_pos, 1),
)
layer_center = preds_dict["center"][
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
]
layer_height = preds_dict["height"][
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
]
layer_rot = preds_dict["rot"][
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
]
layer_dim = preds_dict["dim"][
...,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
]
preds = torch.cat(
[layer_center, layer_height, layer_dim, layer_rot], dim=1
).permute(
0, 2, 1
) # [BS, num_proposals, code_size]
if "vel" in preds_dict.keys():
layer_vel = preds_dict["vel"][
...,
idx_layer
* self.num_proposals : (idx_layer + 1)
* self.num_proposals,
]
preds = torch.cat(
[layer_center, layer_height, layer_dim, layer_rot, layer_vel], dim=1
).permute(
0, 2, 1
) # [BS, num_proposals, code_size]
code_weights = self.train_cfg.get("code_weights", None)
layer_bbox_weights = bbox_weights[
:,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
:,
]
layer_reg_weights = layer_bbox_weights * layer_bbox_weights.new_tensor(
code_weights
)
layer_bbox_targets = bbox_targets[
:,
idx_layer * self.num_proposals : (idx_layer + 1) * self.num_proposals,
:,
]
layer_loss_bbox = self.loss_bbox(
preds, layer_bbox_targets, layer_reg_weights, avg_factor=max(num_pos, 1)
)
# layer_iou = preds_dict['iou'][..., idx_layer*self.num_proposals:(idx_layer+1)*self.num_proposals].squeeze(1)
# layer_iou_target = ious[..., idx_layer*self.num_proposals:(idx_layer+1)*self.num_proposals]
# layer_loss_iou = self.loss_iou(layer_iou, layer_iou_target, layer_bbox_weights.max(-1).values, avg_factor=max(num_pos, 1))
loss_dict[f"{prefix}_loss_cls"] = layer_loss_cls
loss_dict[f"{prefix}_loss_bbox"] = layer_loss_bbox
# loss_dict[f'{prefix}_loss_iou'] = layer_loss_iou
loss_dict[f"matched_ious"] = layer_loss_cls.new_tensor(matched_ious)
return loss_dict
def get_bboxes(self, preds_dicts, metas, img=None, rescale=False, for_roi=False):
"""Generate bboxes from bbox head predictions.
Args:
preds_dicts (tuple[list[dict]]): Prediction results.
Returns:
list[list[dict]]: Decoded bbox, scores and labels for each layer & each batch
"""
rets = []
for layer_id, preds_dict in enumerate(preds_dicts):
batch_size = preds_dict[0]["heatmap"].shape[0]
batch_score = preds_dict[0]["heatmap"][..., -self.num_proposals :].sigmoid()
# if self.loss_iou.loss_weight != 0:
# batch_score = torch.sqrt(batch_score * preds_dict[0]['iou'][..., -self.num_proposals:].sigmoid())
one_hot = F.one_hot(
self.query_labels, num_classes=self.num_classes
).permute(0, 2, 1)
batch_score = batch_score * preds_dict[0]["query_heatmap_score"] * one_hot
batch_center = preds_dict[0]["center"][..., -self.num_proposals :]
batch_height = preds_dict[0]["height"][..., -self.num_proposals :]
batch_dim = preds_dict[0]["dim"][..., -self.num_proposals :]
batch_rot = preds_dict[0]["rot"][..., -self.num_proposals :]
batch_vel = None
if "vel" in preds_dict[0]:
batch_vel = preds_dict[0]["vel"][..., -self.num_proposals :]
temp = self.bbox_coder.decode(
batch_score,
batch_rot,
batch_dim,
batch_center,
batch_height,
batch_vel,
filter=True,
)
if self.test_cfg["dataset"] == "nuScenes":
self.tasks = [
dict(
num_class=8,
class_names=[],
indices=[0, 1, 2, 3, 4, 5, 6, 7],
radius=-1,
),
dict(
num_class=1,
class_names=["pedestrian"],
indices=[8],
radius=0.175,
),
dict(
num_class=1,
class_names=["traffic_cone"],
indices=[9],
radius=0.175,
),
]
elif self.test_cfg["dataset"] == "Waymo":
self.tasks = [
dict(num_class=1, class_names=["Car"], indices=[0], radius=0.7),
dict(
num_class=1, class_names=["Pedestrian"], indices=[1], radius=0.7
),
dict(num_class=1, class_names=["Cyclist"], indices=[2], radius=0.7),
]
ret_layer = []
for i in range(batch_size):
boxes3d = temp[i]["bboxes"]
scores = temp[i]["scores"]
labels = temp[i]["labels"]
## adopt circle nms for different categories
if self.test_cfg["nms_type"] != None:
keep_mask = torch.zeros_like(scores)
for task in self.tasks:
task_mask = torch.zeros_like(scores)
for cls_idx in task["indices"]:
task_mask += labels == cls_idx
task_mask = task_mask.bool()
if task["radius"] > 0:
if self.test_cfg["nms_type"] == "circle":
boxes_for_nms = torch.cat(
[
boxes3d[task_mask][:, :2],
scores[:, None][task_mask],
],
dim=1,
)
task_keep_indices = torch.tensor(
circle_nms(
boxes_for_nms.detach().cpu().numpy(),
task["radius"],
)
)
else:
boxes_for_nms = xywhr2xyxyr(
metas[i]["box_type_3d"](
boxes3d[task_mask][:, :7], 7
).bev
)
top_scores = scores[task_mask]
task_keep_indices = nms_gpu(
boxes_for_nms,
top_scores,
thresh=task["radius"],
pre_maxsize=self.test_cfg["pre_maxsize"],
post_max_size=self.test_cfg["post_maxsize"],
)
else:
task_keep_indices = torch.arange(task_mask.sum())
if task_keep_indices.shape[0] != 0:
keep_indices = torch.where(task_mask != 0)[0][
task_keep_indices
]
keep_mask[keep_indices] = 1
keep_mask = keep_mask.bool()
ret = dict(
bboxes=boxes3d[keep_mask],
scores=scores[keep_mask],
labels=labels[keep_mask],
)
else: # no nms
ret = dict(bboxes=boxes3d, scores=scores, labels=labels)
ret_layer.append(ret)
rets.append(ret_layer)
assert len(rets) == 1
assert len(rets[0]) == 1
res = [
[
metas[0]["box_type_3d"](
rets[0][0]["bboxes"], box_dim=rets[0][0]["bboxes"].shape[-1]
),
rets[0][0]["scores"],
rets[0][0]["labels"].int(),
]
]
return res
4.BEVDepth
论文:https://arxiv.org/pdf/2206.10092.pdf
代码: GitHub - Megvii-BaseDetection/BEVDepth: Official code for BEVDepth.
论文认为LSS对于深度估计的准确度不够高,导致指标不高
论文创新点:
1.使用lidar作为精确的深度监督
2.将相机内外参作为输入传入DepthNet
3.使用深度细化模块对预测的深度进行细化
4.使用更高效的体素池化
5.多帧融合(代码里只是单纯的将不同帧之间的BEV特征沿着维度方向cat)
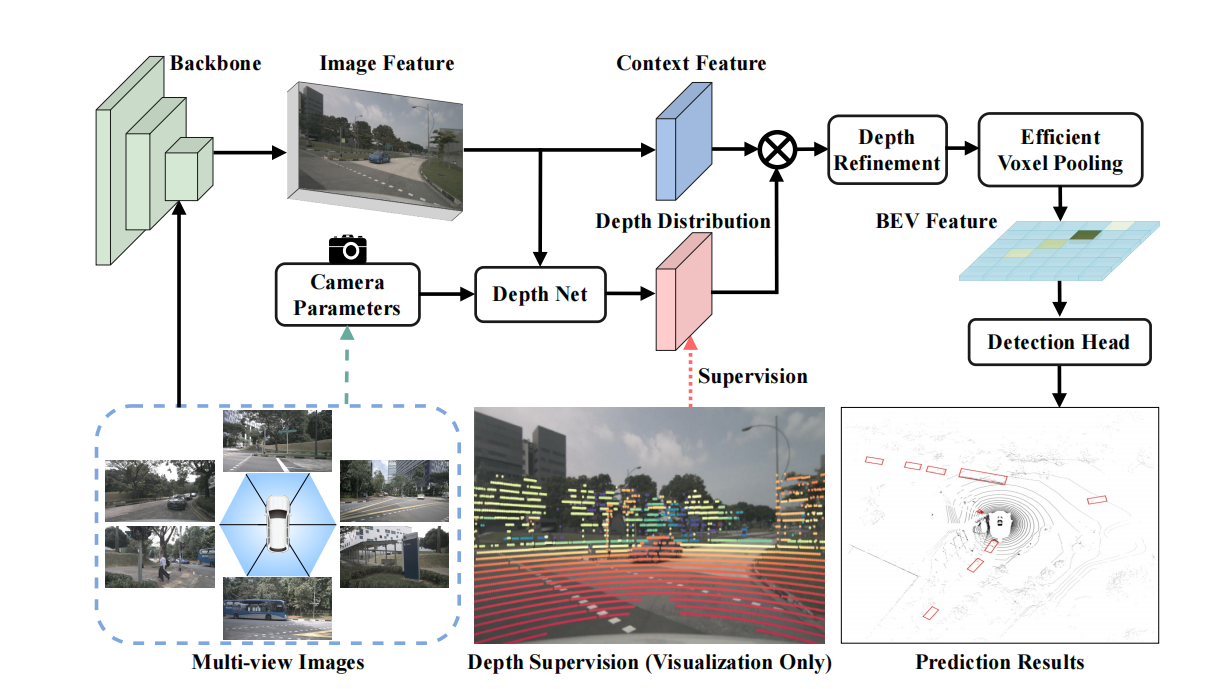
1.lidar作为精确的深度监督
首先将点云从lidar坐标系转到camer坐标系,获取其Z的深度信息,然后再转到像素坐标系,得到每个点在像素平面的u,v坐标,同时去掉不在图像范围里的以及深度太小的,然后将图像的数据增强矩阵也乘上,让他们同步,把u,v整形化,把N个点放入[H,W]的图像平面上,值为深度信息。监督的时候,把其缩放到特征图大小,每一块都采用最小值池化,把不在范围里面的点赋0,现在的维度是[B*N,H,W],然后根据深度值生成独热向量,去掉D为0的,得到[B*N,H,W,D],然后计算二值交叉熵损失。
2.相机深度预测DepthNet
将相机的内外参以及IDA和BDA(数据增强矩阵)组成27维的特征,经过MLP升到和图像特征X一样的维度,得到两个SE(一个深度注意力,一个特征注意力),然后sigmoid,与图像特征相乘,对于深度模块,出来之后还要再经过空洞特征金字塔网络(ASPP)和DCN可变形卷积来增大深度模块的感受野,从而使深度预测的更加精确。然后对深度softmax,与特征外积得到[C,D,H,W].
3.深度细化模块
对于出来的[C,D,H,W]特征,我们沿着W,D维度进行二维卷积,不断地聚集沿着深度方向的信息,即使我们一开始深度预测的不是很精确,但是随着在深度方向的特征聚集以及感受野的扩大,深度预测精度可以得到一个很好的优化。
二、隐式转换的BEV感知
1.CVT(cross view transformer)
论文:https://arxiv.org/abs/2205.02833
论文创新点:
1.将lidar和图像特征进行融合做BEV感知
2.在img2bev模块使用transformer进行隐式转换
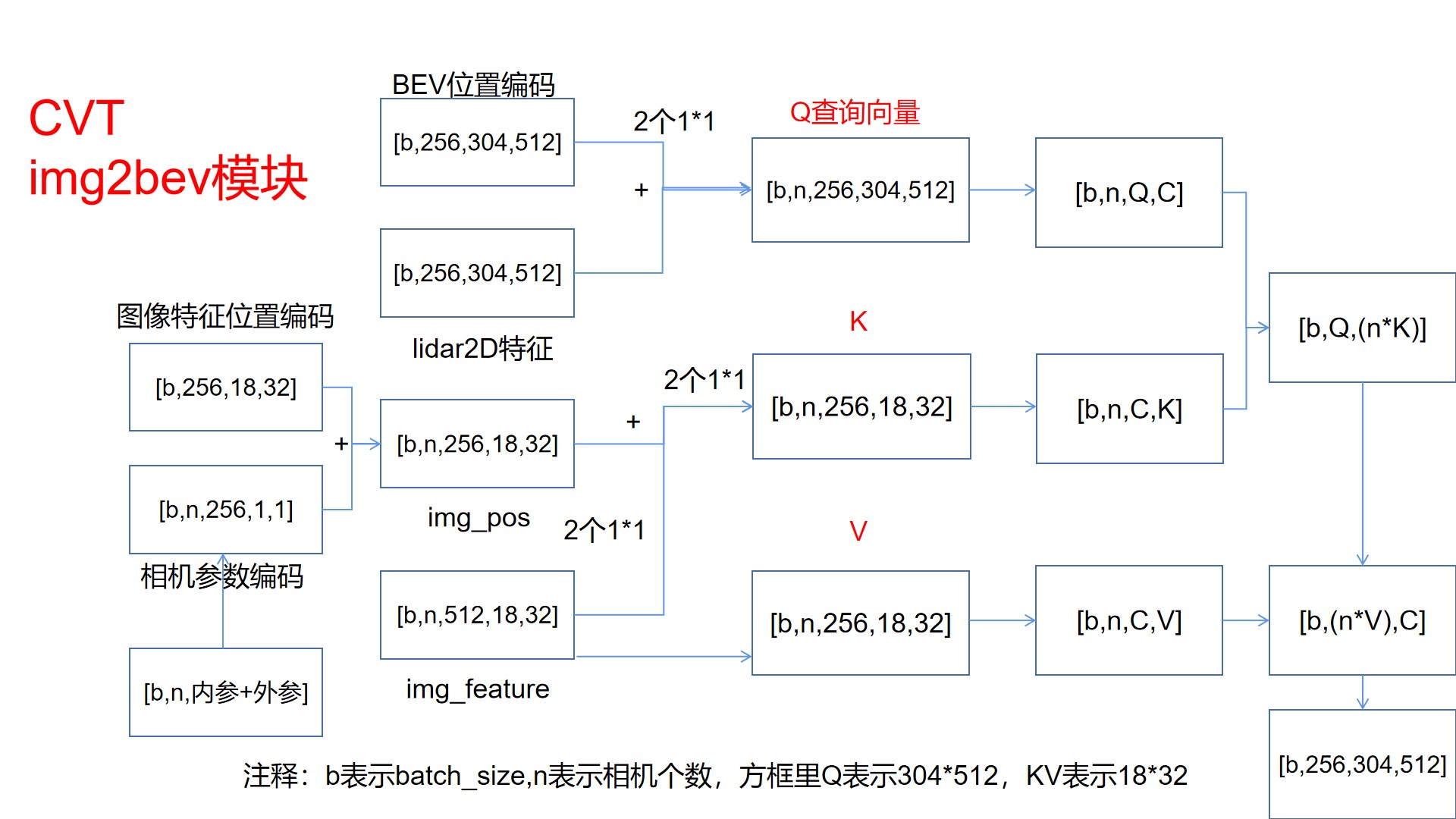
上图是一个cross view attention模块,论文里使用了多次这个模块,具体操作是,骨干网络得到不同分辨率的图像特征图,比如(500*500,400*400,300*300)先把500送入这个交叉注意力机制里,可以看到上图最终输出的特征与Q查询向量一样尺度,此时这个输出特征当作下一阶段的Q查询向量,然后再查询400和300的图像特征,这样就可以叠加多次操作。提升最终的模型效果。
三、显示逆向转换
1.Fast-BEV
代码:GitHub - Sense-GVT/Fast-BEV: Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline
论文创新点:
1.轻量级img2bev模块设计
2.多尺度图像编码(感觉效果不是很好)
3.高效BEV编码(平平无奇)
4.数据增强(仿照BEVDet)
5.多帧时序融合(仿照BEVDet4D和BEVFormer)
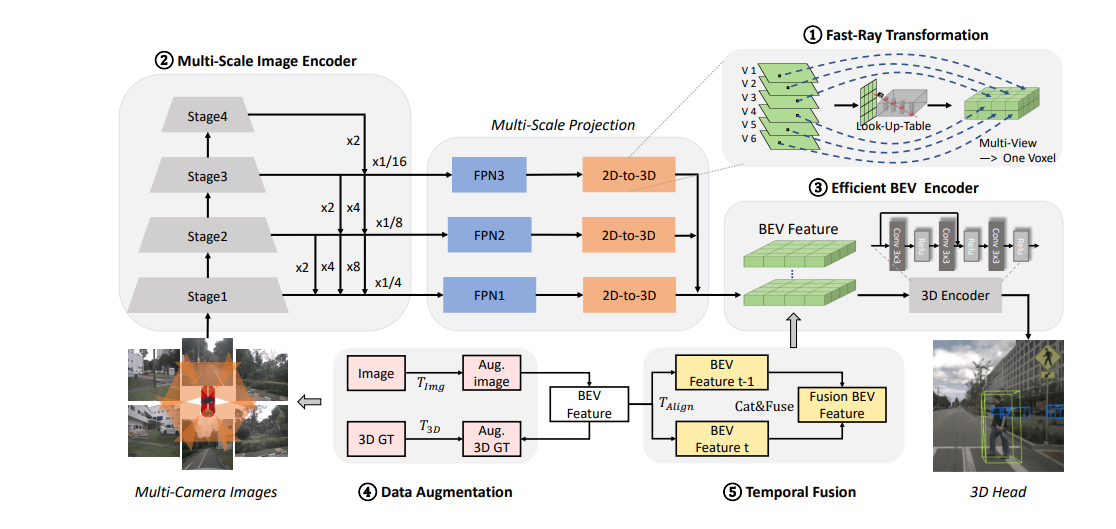
1.快速高效的img2bev模块
本论文最主要的创新点,主要是创建一个三维体素空间到二维像素空间的映射索引。
第一步:构建Look-up-Table,这一步是训练前就搞好的

我们先遍历BEV空间中的体素单元,然后根据其XYZ和不同相机的内外参,得到像素平面的xyz,如果得到的像素xyz是合理的(在图像里),则保存到LUT中。只要找到一个xyz合理就跳出,不会再继续遍历6个图片
此处有个疑惑:一个体素就只有一个图像像素特征,会不会太少了,具体后面看代码再说。
第二步:推理时的查找

推理时,我们遍历每个体素,然后查询LUT表,获得其对应的img,x,y的像素特征,然后填充到体素中去。
2.多尺度编码和高效BEV编码
得益于高效的img2bev模块,我们可以使用多尺度的操作,图像特征得到三个尺度的特征图,然后快速投影到三个不同分辨率的BEV空间体素上。1/4,1/8,1/16特征图到BEV200,150,100的分辨率。BEV上的编码则是将他们三个上采样的一样的200分辨率,然后连同时序和z的高度,在特征维度进行concat。
3.数据增强
与BEVDet相似,图像域采用随机翻转,旋转缩放,此时相机的内参也要同步变化,这样才能对齐图像与BEV的特征。而在BEV领域,进行同样的数据增强,其可以由相机的外参来控制,相应的GT也要做变化,来进行同步变换。
4.多帧时序融合
我们这里提取了历史的三帧进行融合,每个间隔0.5s,在空间对齐之后(如何对齐要看代码),进行串联操作,训练时我们在线提取历史帧的特征,测试的时候我们离线保存历史帧特征,然后直接提取出来加速推理。
5.消融实验的结论
图像的分辨率越大,指标越好。
2D编码对于结果的影响远大于3D编码
多尺度特征对于结果影响不大
数据增强这两个对于指标都有很大提升
时序融合其实融一帧的时候提升最大,再多效果没有那么明显,且耗时。
6.代码流程解析
送入Fast_bev的是6个相机和4个时序图像,张量形状为[b,n_cam*four_time,3,256,704],图像分辨率可以变这里只是举个例子。送入backbone和FPN,论文中得到不同分辨率的特征图,但是效果提升不大,我们这里就不用了,只得到[b, n_cam*for_time, 64, 64, 176]相当于降采样了4倍,然后对时序遍历,下面对batch_size遍历,得到[n_cam, 64, 64, 176]的特征,我们这里读出相机内外参,对内参的fx和fy除以特征图降采样倍数4(后续是特征图与BEV对应,而内外参是图片与BEV对应)得到projects,然后用torch.meshgrid和torch.stack生成BEV上的三维voxel坐标[3,200,200,6]称之为points,根据points和projects我们得到[6,3,240000]这个3表示的是BEVvoxel反投影到特征像素坐标,我们判断这个特征像素坐标是否在特征图范围里。for循环6张图,对在范围里的特征进行BEV体素填充,如果多张图在一个BEVvoxel都有投影则自动覆盖,只保留一个。然后BEV上,将时序和高度这两个维度与特征通道合并,并进行卷积,最终分辨率再降低一倍,变为[b,256,100,100]
2. BEVFormer
BEVformer的img2bev的转换方式是一种介于FastBEV和transformer之间的一种方式,他先在BEV上找一个点,然后把他投影到图片上,因为内外参的误差等,这个映射点可能不是很准,有可能是投影点边上的点才是BEV上需要的,所以他会在这个投影点附近使用一个可变性注意力机制。他和FastBEV对比,主要就是鲁棒性更强。对比CVT而言,他的计算量更少,一个BEV上的点并不是和所有的像素点计算相关性,而是和投影点附近相关的点计算相关性。
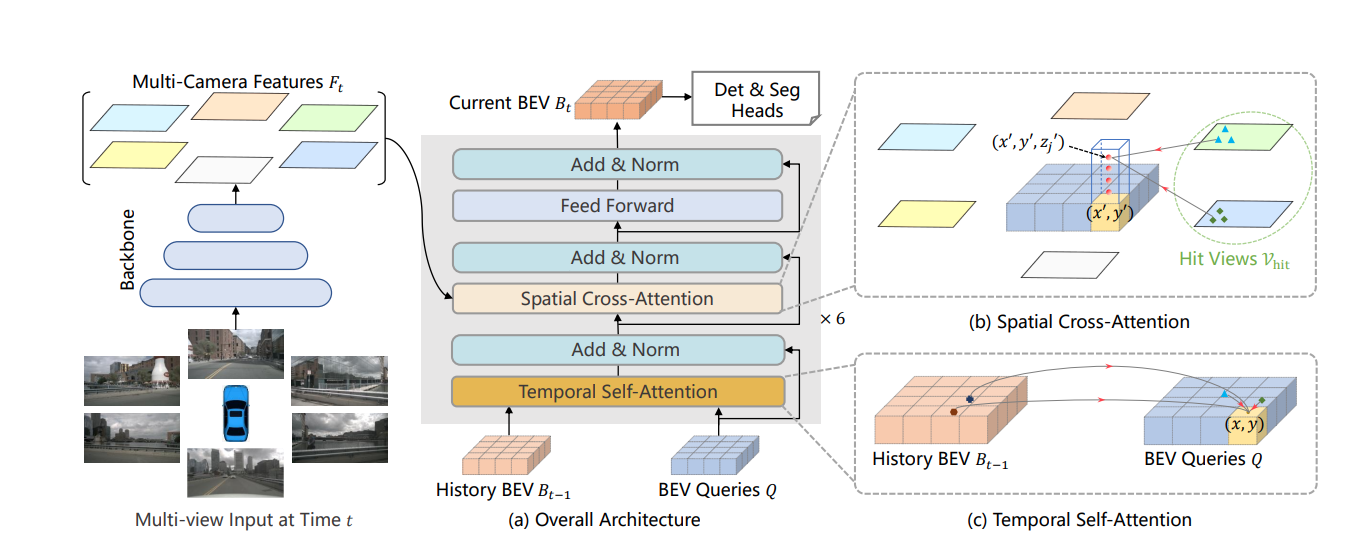
上图可知:图片经过backbone和FPN之后得到六张图片四个尺度的特征图。然后进入BEVFormer的Encoder层,一共叠加了六次,encoder层由三部分组成,首先是时序自注意力机制,通过融合过去帧的BEV特征信息来初始化当前帧的BEV query,在此基础上再进入第二部分空间交叉注意力机制,用于从六张图片四个尺度的特征图里提取信息。再经过一个feed forwad。
在这里补充一下,可变性注意力机制和与transformer注意力机制的差别就是:transformer是先q和k做内积运算,得到相关性再乘V,而可变性注意力机制是通过Q得到一个参考点的偏移量以及权重,只对几个采样点采样
1.TSA时序自注意力机制
该模块主要需要以下几个重要的自变量参数。
参数 bev_query
完全由nn.embedding生成的初始化BEV查询向量,维度为[200, 200, 256] 表示BEV长宽和特征维度。
参数 bev_pose
这个参数是BEV平面的位置编码,具体是先生成一个xy的数组,然后用nn.embedding生成,cat到一块.维度为[bs, 256, 200, 200]
参数 ref_point(指当前BEV空间与前一帧BEV空间的对应关系)
对于这个参数有两种形式:首先是有pre_bev的情况,这时ref_point = ref_2d + shift。其次当没有pre_bev时,如第一帧,这时ref_point = ref_2d。这里面的ref_2d就是一个BEV上均匀分布的网格坐标点,shift是由can_bus里面的车辆的移动得到的,包括平移和旋转。
参数 value
该参数就是BEV_query去查询的特征。这个参数也有两种情况,首先包含pre_bev时,value = 【pre_bev,bev_query】,对应的参考点为ref_point = 【ref_2d + shift, ref_2d】。当不包含pre_bev时,value = [bev_query,bev_query],对应的参考点为ref_point = [ref_2d,ref_2d]。
流程:
先根据bev_query和pre_bev得到value,bev_query加上bev位置编码得到新的bev_query。然后bev_query = torch.cat(pre_bev, bev_query),相当于最终的bev_query包含了历史信息以及原始bev_query和bev的位置编码这么多信息。而value里面只有历史信息和原始bev_query,相当于没有bev位置编码。然后把最终bev_query送入两个linear再view一下,得到可变性注意力机制的偏移量和weight,这里的偏移量是绝对量,需要做一个normalize。最终将上述参数送入多尺度可变性注意力机制函数里,源代码里用的cuda实现。
多尺度可变形注意力机制MultiScaleDeformableAttention
"""
输入参数的shape与含义
1.value (2, 40000, 8, 32) #2表示前一时刻的bev特征和当前时刻的bev特征,40000表示bev上的每个位置,8是多头注意力机制的头数,32是每个头的维度。
2.sample_shape (200,200)方便将归一化的偏移位置反归一化。
3.level_start_index 0,表示不同分辨率特征图的起点,这里只有一个200*200所以只有一个0
4.sample_locations (2, 40000, 8, 1, 4, 2) 2,40000,8对应value的含义,1表示一个尺度,4表示与四个点做注意力操作,2表示每个点的偏移量
"""
output = MultiScaleDeformableAttnFunction.apply(value,
spatial_shapes,
level_start_index,
sampling_locations,
attention_weights,
self.im2col_step)
#最终输出的output维度为(2,40000,8,32)在第一维度做一个平均,送到SCA2.SCA空间交叉注意力机制
利用TSA输出的bev_query,对多尺度的环视图像特征进行查询。具体参数解释:
参数 bev_query(来自于TSA)
参数 value
因为transformer是对序列进行处理的,所以我们要先把多尺度图像特征在H*W维度进行flatten操作,然后再将不同的尺度聚集在一起,方便之后查询。得到维度为(num_cam, sum(H*W),bs, channel).sum是指对多尺度特征拼接。
参数 ref_point
首先说一下ref_3d,他是在BEV空间中生成的三维空间规则网格点,同时在Z轴上人为选择了4个高度点。然后使用lidar_to_img的参数,与ref_3d相乘,得到refrence_points_cam (batch_size, num_cam, 40000, 4, 2)4表示Z上的4个点,2表示uv坐标和bev_mask(b, num_cam, 40000, 4),因为有些BEV的点投到图像上可能不存在,所以会有一个mask。
参数 queries_rebatch
并不是每个BEV上的三维点都会映射到每个图象上,而只会映射到其中几张里。所以对bev_query进行了整合。根据bev_mask和bev_query得到query_rebatch
参数 reference_points_rebatch
与产生query_rebatch的原因相同,获得映射到二维图像的有效位置,对原有reference_points进行重新整合。
流程:
同TSA一样,根据queries_rebatch生成偏移和权重。将参数送入多尺度可变形注意力模块中。
"""
1.value (cam_num, sum(H*w) = 30825, head = 8, dim = 32)
2.spatial_shape ([116, 200], [58, 100], [29, 50], [15, 25])
3. level_start_index [0, 23200, 29000, 30450]
4.sampling_locations (6, max_len, 8 = 多头, 4 = 四个尺度, 8 = 8个点,Z上4个,一个z找两个偏移点, 2)
5.attention (6, max_len, 8, 4, 8)
"""
output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations, attention_weights, self.im2col_step)
#output (6, max_len, 8, 32)
#将一个BEV上的3维点得到的特征求一个平均,比如有些点得到的3张图的特征,有些得到1张图的特征。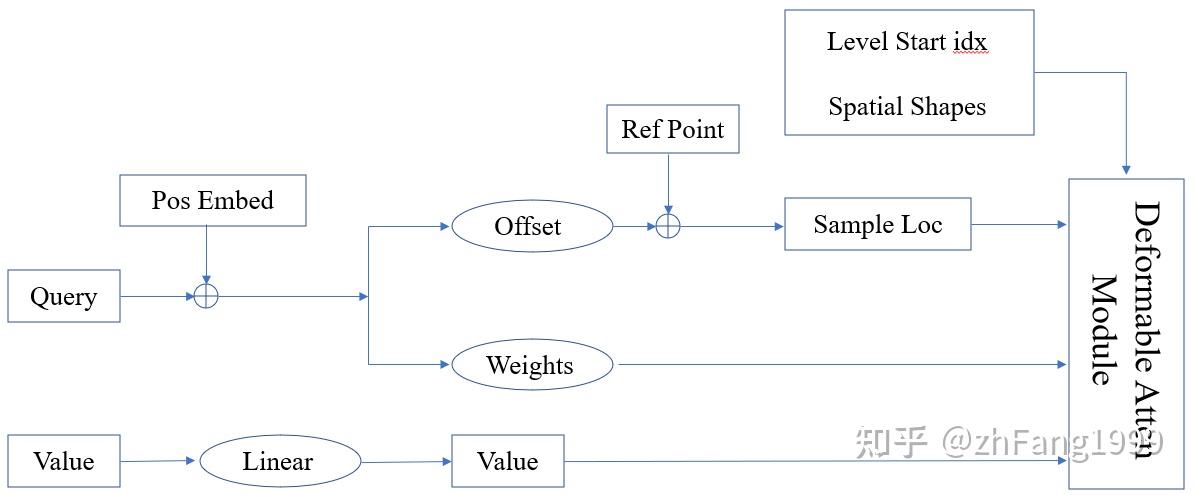
















 4879
4879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











