







 本文详细介绍了注意力机制如何处理查询、键和值,从一维空间的直观过程到高维向量的复杂模型,涵盖了加性注意力和缩放点积注意力。此外,文中还探讨了自注意力机制和多头注意力机制,以及为何在softmax中使用特定的缩放系数来避免梯度消失问题。
本文详细介绍了注意力机制如何处理查询、键和值,从一维空间的直观过程到高维向量的复杂模型,涵盖了加性注意力和缩放点积注意力。此外,文中还探讨了自注意力机制和多头注意力机制,以及为何在softmax中使用特定的缩放系数来避免梯度消失问题。
Attention Mechanism
现在给定一组数据,假设包含若干个 特征-值 对
(
K
e
y
,
V
a
l
u
e
)
(Key,Value)
(Key,Value),那么现在我们拿着一个特征
Q
u
e
r
y
Query
Query,要如何利用这组数据确定一个合理的
v
a
l
u
e
value
value?
有一些比较naive的想法,比如取最近邻的对应
V
a
l
u
e
Value
Value,或者取较近的几个
K
e
y
Key
Key,再拿它们的
V
a
l
u
e
Value
Value做个平均啥的。这些想法有其合理性,并且都蕴含一个核心点就是:
我们在尽可能地将注意力集中在与 Q u e r y Query Query相近的 K e y Key Key对应的 V a l u e Value Value上,因为这些 V a l u e Value Value更大概率会与我们要确定的值更加接近
所以就有了 A t t e n t i o n M e c h a n i s m Attention\ Mechanism Attention Mechanism
低维
我们首先在一维空间
R
\mathbb{R}
R下讨论这件事情。下面是一个非常直观的过程.
我们有若干组
(
K
e
y
i
,
V
a
l
u
e
i
)
(Key_i,Value_i)
(Keyi,Valuei),以及一个查询
Q
u
e
r
y
Query
Query,我们的目标是得到
O
u
t
p
u
t
Output
Output.首先我们会让
Q
u
e
r
y
Query
Query与各个
K
e
y
i
Key_i
Keyi做一个
a
a
a运算,得到结果
a
(
Q
u
e
r
y
,
K
e
y
i
)
a(Query,Key_i)
a(Query,Keyi),它表示
Q
u
e
r
y
Query
Query与
K
e
y
i
Key_i
Keyi的相似程度,显然它与我们之后要在
K
e
y
i
,
V
a
l
u
e
i
Key_i,Value_i
Keyi,Valuei上投入的注意力大小成正比,我们就记为注意力评分函数(attention scoring function).然后我们就拿
a
i
=
a
(
Q
u
e
r
y
,
K
e
y
i
)
a_i=a(Query,Key_i)
ai=a(Query,Keyi)转换成概率分布
s
i
s_i
si,再与
V
a
l
u
e
i
Value_i
Valuei相乘并求和得到
O
u
t
p
u
t
=
∑
i
s
i
V
a
l
u
e
i
Output = \sum_i s_iValue_i
Output=i∑siValuei
这就是最后的结果了。
这里
a
i
a_i
ai到
s
i
s_i
si我们简单点,可以直接取
s
i
=
a
i
∑
j
=
1
n
a
j
s_i=\frac{a_i}{\sum_{j=1}^{n} a_j}
si=∑j=1najai
可以看到这个求法还是有一定的合理性的,因为它不仅考虑到了注意力要偏向重点,还考虑到了整体的数据,而不是像之前那样只关注一小部分。接下来还剩下一个问题,就是我们的注意力评分函数
a
(
Q
u
e
r
y
,
K
e
y
i
)
a(Query,Key_i)
a(Query,Keyi)要怎么算。一个方法就是可以使用核回归:
这里我们核函数选择
G
a
u
s
s
Gauss
Gauss核函数
K
(
u
)
=
1
2
π
e
x
p
(
−
u
2
2
)
K(u)=\frac{1}{\sqrt{2\pi}}exp(-\frac{u^2}{2})
K(u)=2π1exp(−2u2)
从而
u
u
u就取
Q
u
e
r
y
−
K
e
y
i
Query-Key_i
Query−Keyi,得到
O
u
t
p
u
t
=
∑
i
e
x
p
(
−
1
2
(
Q
u
e
r
y
−
K
e
y
i
)
2
)
∑
j
e
x
p
(
−
1
2
(
Q
u
e
r
y
−
K
e
y
j
)
2
)
V
a
l
u
e
i
Output = \sum_i\frac{exp(-\frac{1}{2}(Query-Key_i)^2)}{\sum_j exp(-\frac{1}{2}(Query-Key_j)^2)}Value_i
Output=i∑∑jexp(−21(Query−Keyj)2)exp(−21(Query−Keyi)2)Valuei
注意到第一个求和号里面其实就是一个softmax,从而
O
u
t
p
u
t
=
∑
i
s
o
f
t
m
a
x
(
−
1
2
(
Q
u
e
r
y
−
K
e
y
i
)
2
)
V
a
l
u
e
i
Output = \sum_i softmax(-\frac{1}{2}(Query-Key_i)^2)Value_i
Output=i∑softmax(−21(Query−Keyi)2)Valuei
为了给整个模型加入一点可学习的东西,我们可以在softmax里面加入一个参数
w
w
w,得到
O
u
t
p
u
t
=
∑
i
s
o
f
t
m
a
x
(
−
1
2
(
Q
u
e
r
y
−
K
e
y
i
)
2
w
)
V
a
l
u
e
i
Output = \sum_i softmax(-\frac{1}{2}(Query-Key_i)^2w)Value_i
Output=i∑softmax(−21(Query−Keyi)2w)Valuei
这就是最终结果了。
高维
现在不管是
Q
u
e
r
y
,
K
e
y
Query,Key
Query,Key还是
V
a
l
u
e
Value
Value,都从原本的一维数据变成了高维的向量,然后我们再重新审视这个问题。下面这张图是非常形象的。
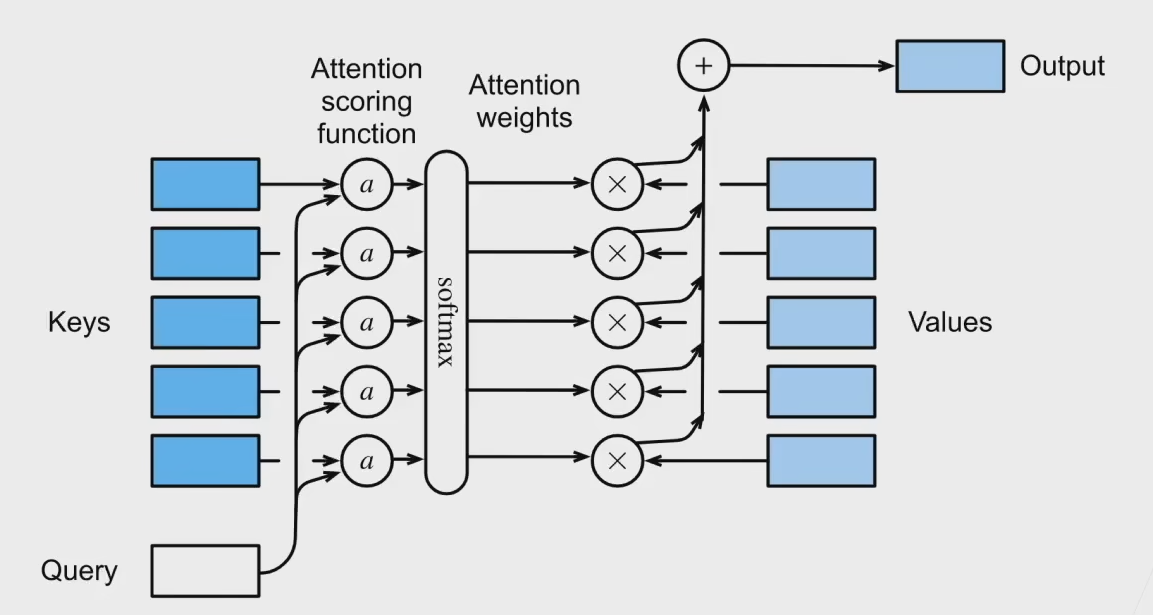
用一个函数
f
f
f来形式化地描述整个过程。有
n
n
n个键值对
k
i
∈
R
k
,
v
i
∈
R
v
\boldsymbol{k_i}\in \mathbb{R}^k,\boldsymbol{v_i}\in \mathbb{R}^v
ki∈Rk,vi∈Rv,给定一个查询
q
∈
R
q
:
\boldsymbol{q}\in \mathbb{R}^q:
q∈Rq:
O
u
t
p
u
t
=
f
(
q
,
(
k
1
,
v
1
)
,
⋯
,
(
k
n
,
v
n
)
)
=
∑
i
=
1
n
α
(
q
,
k
i
)
v
i
∈
R
v
Output = f(\boldsymbol{q},(\boldsymbol{k_1},\boldsymbol{v_1}),\cdots,(\boldsymbol{k_n},\boldsymbol{v_n}))=\sum_{i=1}^{n}\alpha(\boldsymbol{q},\boldsymbol{k_i})\boldsymbol{v_i}\in \mathbb{R}^v
Output=f(q,(k1,v1),⋯,(kn,vn))=i=1∑nα(q,ki)vi∈Rv
其中
α
(
q
,
k
i
)
=
e
x
p
(
a
(
q
,
k
i
)
)
∑
j
=
1
n
e
x
p
(
a
(
q
,
k
j
)
)
\alpha(\boldsymbol{q,k_i})=\frac{exp(a(\boldsymbol{q,k_i}))}{\sum_{j=1}^{n}exp(a(\boldsymbol{q,k_j}))}
α(q,ki)=∑j=1nexp(a(q,kj))exp(a(q,ki))
由于把核函数的一部分抽象成了softmax操作,所以在低维情况下我们的
a
(
q
,
k
i
)
a(q,k_i)
a(q,ki)函数实际对应的是
−
1
2
(
q
−
k
i
)
2
-\frac{1}{2}(q-k_i)^2
−21(q−ki)2
而在高维向量情况下,我们有对
a
a
a一般有两种处理方式
加性注意力
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。此时给定
q
∈
R
q
,
k
∈
R
k
\boldsymbol{q}\in \mathbb{R}^q,\boldsymbol{k}\in \mathbb{R}^k
q∈Rq,k∈Rk,有
a
(
q
,
k
)
=
w
v
T
t
a
n
h
(
W
q
q
+
W
k
k
)
a(\boldsymbol{q,k})=\boldsymbol{w}_v^T\ tanh(\boldsymbol{W}_q\boldsymbol{q+\boldsymbol{W}_k\boldsymbol{k}})
a(q,k)=wvT tanh(Wqq+Wkk)
其中
W
q
∈
R
h
×
q
,
W
k
∈
R
h
×
k
,
w
v
∈
R
h
\boldsymbol{W}_q\in \mathbb{R}^{h\times q},\boldsymbol{W}_k\in \mathbb{R}^{h\times k},\boldsymbol{w}_v\in \mathbb{R}^{h}
Wq∈Rh×q,Wk∈Rh×k,wv∈Rh都是可学习的参数,而
h
h
h是作为一个可以调整的超参数,tanh就是一个激活函数。仔细观察一下就是,括号里面将
q
\boldsymbol{q}
q和
k
\boldsymbol{k}
k都转化成了一个
h
h
h维向量,然后再与外面的
w
v
T
\boldsymbol{w}_v^T
wvT一乘,就得到了一个实数作为最终结果
缩放点积注意力
当查询和键的长度相同时,我们就可以不必这么麻烦,把它们统一转化成一个长度的向量了。我们可以直接做向量内积,从而有
q
,
k
∈
R
d
\boldsymbol{q,k}\in \mathbb{R}^d
q,k∈Rd,
a
(
q
,
k
)
=
q
T
k
a(\boldsymbol{q},\boldsymbol{k})=\boldsymbol{q}^T\boldsymbol{k}
a(q,k)=qTk
但是这样其实有一个问题。因为我们的结果
a
(
q
,
k
)
a(\boldsymbol{q},\boldsymbol{k})
a(q,k)是要拿去做softmax的,而softmax由于是由指数函数实现的,当指数差距过大时,概率的偏差就会变的极大,从而失去参考价值。所以我们可以统一除以一个
d
\sqrt{d}
d来减少差距,至于为什么是
d
\sqrt{d}
d,我们在最后讨论一下
以上都是考虑样本数为1的情况,实际情况中有多个样本,多个数据,记为查询 Q ∈ R m × d \boldsymbol{Q}\in \mathbb{R}^{m\times d} Q∈Rm×d,键值 K ∈ R n × d , V ∈ R n × v \boldsymbol{K}\in \mathbb{R}^{n\times d},\boldsymbol{V}\in \mathbb{R}^{n\times v} K∈Rn×d,V∈Rn×v,就有
f
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
∈
R
m
×
v
f=softmax(\frac{\boldsymbol{QK}^T}{\sqrt{d}})\boldsymbol{V}\in \mathbb{R}^{m \times v}
f=softmax(dQKT)V∈Rm×v
这里softmax操作就是对每一行进行softmax操作的意思
总体可以用这一张图表示
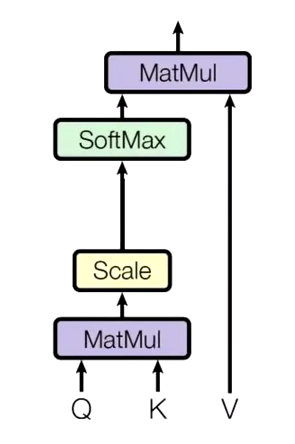
首先
Q
,
K
\boldsymbol{Q,K}
Q,K做内积,然后放缩(除以
d
\sqrt{d}
d),然后做softmax,最后与
V
\boldsymbol{V}
V点乘
Self-Attention Mechanism
说是叫self-attention,不过我觉得这里的self更多的应该是指一个集合本身,而不是集合中的某一个元素
回忆一下Attention Mechanism:有
m
m
m个长度为
d
d
d的查询向量
q
1
,
q
2
,
.
.
.
q
n
\boldsymbol{q_1,q_2,...q_n}
q1,q2,...qn,就记为行向量好了,它们组成一个矩阵
Q
∈
R
m
×
d
\boldsymbol{Q\in \mathbb{R}^{m\times d}}
Q∈Rm×d,同理有n个键行向量组成的矩阵
K
∈
R
n
×
d
\boldsymbol{K}\in \mathbb{R}^{n\times d}
K∈Rn×d,以及
n
n
n个值行向量组成的矩阵
V
∈
R
n
×
v
\boldsymbol{V}\in \mathbb{R}^{n\times v}
V∈Rn×v
(这里为了方便我们就只讨论查询向量与键值向量的长度相等的情况了,然后就直接用Scaled Dot-Product Attention来处理了,另一种情况的处理显然也会是类似的)
然后就有结果矩阵
f
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
∈
R
m
×
v
f=softmax(\frac{\boldsymbol{QK}^T}{\sqrt{d}})\boldsymbol{V}\in \mathbb{R}^{m \times v}
f=softmax(dQKT)V∈Rm×v
这里有几点要指出:
- f的行大小是与 Q Q Q相同的,它相当于是对每一个询问行向量 q i q_i qi的所有特征进行了一个回答
- 任意两个询问行向量
q
i
,
q
j
q_i,q_j
qi,qj之间是可以没有任何关系的,相当于
m
m
m次互不影响的询问
那么自注意力机制就是在次基础上做的改进
我们现在有
m
m
m个事物,它们是一个整体,
m
m
m个事物之间有可能某个集合的事物之间是包含一定的关系的。如果我们想只用这
m
m
m个事物的当前特征去做attention,得到一些信息,那么显然我们的查询矩阵
Q
\boldsymbol{Q}
Q的每一行就要取对应事物的特征。那么
K
,
V
\boldsymbol{K,V}
K,V呢?我们还是取这个集合内每一个事物的对应信息。相当于从集合内部的事物之间的隐含的关系来找到信息
从而我们的
Q
,
K
,
V
\boldsymbol{Q,K,V}
Q,K,V的第
i
i
i个行向量来自第
i
i
i个事物的信息。为此我们需要引入
W
q
,
W
k
,
W
v
∈
R
d
×
b
\boldsymbol{W_q,W_k,W_v}\in \mathbb{R}^{d\times b}
Wq,Wk,Wv∈Rd×b三个矩阵来提取信息,当然它们是可学习的,而这
m
m
m个事物本身的信息可以写成一个
X
∈
R
m
×
d
\boldsymbol{X}\in \mathbb{R}^{m\times d}
X∈Rm×d,从而,
Q
=
X
W
q
,
K
=
X
W
k
,
V
=
X
W
v
\boldsymbol{Q=XW_q,K=XW_k,V=XW_v}
Q=XWq,K=XWk,V=XWv
最后套用原本的attention机制,我们得到
f
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
∈
R
m
×
d
f=softmax(\frac{\boldsymbol{QK}^T}{\sqrt{d}})\boldsymbol{V}\in \mathbb{R}^{m \times d}
f=softmax(dQKT)V∈Rm×d
f
f
f的每一个行向量就是第
i
i
i个事物从这n个事物当中提取到的信息了
注意到自注意力机制与普通的注意力机制的区别就在于:它的信息来源是一个固定的集合,集合的每一个元素既为其它元素提供信息,也从其它元素那里提取信息。所以我在这一节的一开始说,self更多的应该是指一个集合本身,而不是集合中的某一个元素
这样做的意义是:对于集合中的每一个元素
a
a
a,它可以从与它相近的其它元素中得到更多信息,而不仅仅是只有自己的信息
Multi-head Attention Mechanism
注意到之前对于每一个事物,我们只用了一组矩阵
W
q
,
Q
k
,
Q
v
W_q,Q_k,Q_v
Wq,Qk,Qv来提取其特征。一个很自然的问题:这样提取够吗?会不会导致提取的信息不足?
解决方案也很简单,那就多用几组
W
q
,
Q
k
,
Q
v
W_q,Q_k,Q_v
Wq,Qk,Qv来提取就好了,然后再把它们的结果放到一起,再拼在一起就可以啦。第
i
i
i组用的矩阵就是
W
q
i
,
Q
k
i
,
Q
v
i
W_{q_i},Q_{k_i},Q_{v_i}
Wqi,Qki,Qvi,不同组之间显然是可以并行计算的,互不影响。
关于缩放系数 d \sqrt{d} d
前面讲到了,attention操作最后需要做一个softmax,而softmax里面含有指数运算,如果数据的方差过大的话,最后得到的分布就会非常接近一个one hot分布,从而导致严重的梯度消失,为此我们需要对点积进行放缩。但是为什么放缩的系数是 d \sqrt{d} d呢?(其中 d d d是向量的长度)
我们考虑
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
∈
R
m
×
v
softmax(\frac{\boldsymbol{QK}^T}{\sqrt{d}})\boldsymbol{V}\in \mathbb{R}^{m \times v}
softmax(dQKT)V∈Rm×v
中的任意两个
d
d
d维向量
q
,
k
q,k
q,k,假设它们采样自均值为0,方差为1的分布,那么它们内积的二阶矩为
KaTeX parse error: No such environment: flalign at position 8: \begin{̲f̲l̲a̲l̲i̲g̲n̲}̲ \mathbb{E}[(q\…
又
E
[
q
⋅
k
]
2
=
0
\mathbb{E}[q\cdot k]^2=0
E[q⋅k]2=0,从而
V
a
r
[
q
⋅
k
]
=
d
\mathbb{V}ar[q\cdot k]=d
Var[q⋅k]=d
根据正态分布的3
σ
\sigma
σ原则,我们不妨假定
q
⋅
k
q\cdot k
q⋅k分布在
[
−
3
d
,
3
d
]
[-3\sqrt{d},3\sqrt{d}]
[−3d,3d]中,那么在softmax做指数运算之后,数据分布在
[
e
−
3
d
,
e
3
d
]
[e^{-3\sqrt{d}},e^{3\sqrt{d}}]
[e−3d,e3d]中,一般来说
d
d
d都是一个较大的值,从而左界实在是太小了,所以求梯度的时候很容易导致梯度消失,,为此我们经验性地除上一个
d
\sqrt{d}
d,使得
V
a
r
[
q
⋅
k
]
=
1
\mathbb{V}ar[q\cdot k]=1
Var[q⋅k]=1,这会使得最后的区间大致分布在
[
e
−
3
,
e
3
]
[e^{-3},e^3]
[e−3,e3],这是一个相对来说可以接受的区间,会有效缓解该问题,让网络能够更加稳定地更新。















 1226
1226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









