






堆栈操作
R1=0x005
R3=0x004
SP=0x80014
STMFD sp!, {r1, r3}
指令STMFD sp!, {r1, r3}是一条ARM架构中的存储多个寄存器到内存的指令,这里用于将r1和r3寄存器的内容存储到栈上。STMFD(Store Multiple Full Descending)是一种全递减模式的多寄存器存储指令,它会先将栈指针(SP)减去将要存储的寄存器数量乘以4(每个寄存器占用4字节),然后将寄存器内容存储到内存中,并最终更新栈指针的值(由于有!后缀,表示更新SP)。
根据给定的值:
R1的值为0x005。
R3的值为0x004。
栈指针SP的初始值为0x80014。
执行STMFD sp!, {r1, r3}指令后的操作结果:
因为要存储R1和R3两个寄存器,所以SP会先减去2 * 4 = 8字节。更新后的SP值为0x80014 - 8 = 0x8000C。
将R1和R3寄存器的内容按顺序(编码小的寄存器先存)存储到栈上,具体为:
R1的内容0x005会被存储到新的SP地址0x8000C。
然后,R3的内容0x004会被存储到0x80010的位置(因为是全递减模式,所以R1存储在更低的地址)。
注意:LDMDB R0!,{R8-R5}指令执行后,R0 - 4执行的地址是传给R8
在ARM汇编语言中,LDMDB R0!, {R8-R5}指令执行的是一个具有递减和写回的多寄存器加载操作。这条指令的含义可以拆解为以下几个部分:
LDM是Load Multiple的缩写,表示这是一个多寄存器加载指令。
DB代表Decrement Before,意味着在加载之前,基址寄存器(本例中为R0)的地址会先递减。
R0!表示使用R0作为基址寄存器,并在操作完成后,更新R0的值。!是写回(write-back)操作的标识。
{R8-R5}意味着从R8到R5这些寄存器将被加载数据。按照ARM的惯例,这样的范围是倒序的,即首先处理R8,然后是R7,以此类推,最后是R5。
关于R0-4执行后的地址是传给R8还是R5,通常在多寄存器加载/存储指令中,寄存器列表是按照升序排列,即使写作{R8-R5},在实际执行过程中也应当理解为操作是从低编号寄存器向高编号寄存器进行。然而,由于LDMDB指令使用的是递减模式,它实际上是从R8开始向下到R5加载数据,每次加载后基地址R0都会递减。
但是,容易引起混淆的一点是,ARM架构文档通常指示,在LDMDB这类指令中,数据是以升序的方式从内存地址加载的,即最低的寄存器号对应最低的地址。所以,如果从R0开始的一段连续内存被加载到了这些寄存器中,那么实际上:
R0的初始值减去递减的总量(因为是DB,所以操作前R0就已经被递减),通过写回操作更新R0的值;
由于是DB模式,所以加载操作是先将R0的值减少相应的数量后(在此例中,涉及到的寄存器数为4,所以可能是R0减少16(如果是32位系统)或更多(取决于寄存器宽度和具体的架构)),然后加载;
由于寄存器列表倒序的标记方式可能会导致理解上的混淆,实际存取顺序与寄存器编号的升序或降序无关,关键是根据指令的递增(IA/IB)或递减(DA/DB)模式确定加载顺序。
参考:https://blog.csdn.net/u011449588/article/details/44945411?spm=1001.2014.3001.5501
类似操作
在ARM指令集中,NE代表“Not Equal”,意味着该指令仅在零标志(Zero Flag)未被设置时执行。
总结操作结果,R1和R3的值会被存储到栈上,栈指针SP会更新为0x8000C,并且内存地址0x8000C和0x80010分别存储了R1和R3的值。
这是一个ARM架构中常见的利用栈保存现场的操作,常在函数调用前执行,以保护当前函数的局部变量和寄存器值不被调用的函数改变,同时调整SP为新的栈顶位置,以用于可能的后续操作。
LDRLE pc, [pc, r0, LSL #2]执行流程
指令LDRLE pc, [pc, r0, LSL #2]是一条条件加载(Load)指令,它的目的是根据某条件将数据从内存加载到程序计数器pc中。这条指令的各个部分代表的含义如下:
LDRLE:这是一个条件加载指令的前缀。LE代表"Less than or Equal",意味着只有当标志寄存器中的条件标志满足小于或等于(Z标志位为1或N不等于V)时,指令才会执行。如果条件不满足,则指令不执行任何操作,相当于NOP(无操作)。
pc:这是目标寄存器,即指令加载数据后的存储位置。这里的pc(程序计数器)用于控制程序的执行流程。
[pc, r0, LSL #2]:这是源操作数,表示加载操作的地址。该地址是通过将寄存器r0的值逻辑左移2位(LSL #2)然后加上当前pc的值来计算得到的。左移2位相当于乘以4,是用于访问数组或跳转表中元素的常用技巧。
执行流程大致如下:
检查条件标志位,判断是否满足"Less than or Equal"的条件。
如果条件满足,计算地址[pc, r0, LSL #2]。
从计算得到的内存地址处加载数据。
将加载得到的数据存储到pc寄存器中,实现程序的跳转。
LE判断
LE在LDRLE pc, [pc, r0, LSL #2]这条指令中代表的是“Less than or Equal to Zero”的意思,不是直接比较两个特定寄存器的值。
在ARM指令中,条件码如LE用于基于程序状态寄存器(condition flags)中的标志来决定是否执行某条指令。具体来说,LE条件码会检查零标志(Zero flag,Z)和符号标志(Negative flag,N)与溢出标志(Overflow flag,V)的关系。当Z标志被设置(表示前一运算的结果为零)或者N和V标志不等(表示负数结果不如预期那样大)时,LE条件满足,此时与LE相关的指令才会执行。因此,LE条件的比较是基于条件标志而不是直接比较寄存器之间的值。
在LDRLE pc, [pc, r0, LSL #2]指令的上下文中,如果条件满足(即程序认为上一个结果小于等于零),则加载指令被执行,否则该指令会被处理器忽略。这允许程序基于状态寄存器中的条件标志来有选择性地执行代码路径,支持分支、循环和条件执行等程序结构。
需注意,由于加载操作改变了pc的值,这实际上完成了一次条件分支操作,改变了程序的执行流程,可能用于实现如函数调用返回、条件分支等操作。此外,由于ARM的pc是流水线结构,对pc的操作通常涉及到流水线的处理,具体的影响需要根据处理器的具体实现来判断。
中断号有什么用
中断号在计算机系统中用于唯一标识每个中断源,它允许处理器和中断控制器正确识别和处理各种中断信号。每个中断源如外设(键盘、鼠标、网络接口)或内部事件(如定时器溢出、软件中断指令等)都分配有唯一的中断号。中断号的具体用途包括:
确定中断源:中断号可以帮助处理器确定触发中断的具体设备或条件。当多个中断源同时请求中断服务时,处理器或中断控制器通过中断号能够区分这些中断源。
中断向量表寻址:处理器使用中断号来访问中断向量表(IVT)或中断描述符表(IDT),这些表包含了每个中断号对应的中断服务程序(ISR)的入口地址。处理器根据中断号索引向量表,获得相应的中断处理程序地址,并跳转执行该程序。
确定中断优先级:在一些系统中,中断号还决定了中断请求的优先级,如recall slice 1所提及的LoongArch指令系统实现了向量中断,采用固定优先级仲裁机制,硬件中断号越大优先级越高。
实现向量化中断:向量化中断(recall slice 2和recall slice 3)通过为每个中断分配不同的号码和处理程序,简化了中断处理过程,省去了识别具体中断源的开销,从而可以加速中断的处理。
因此,中断号对于处理器正确、高效地响应和处理中断至关重要,使得系统能够实现快速的任务切换,及时响应外设请求,保障了运行时的实时性和稳定性。
如何通过__swi(中断号) function给中断函数指定中断号(一般在C代码中撰写)
在ARM架构下,__swi关键字用于在C代码中声明软件中断(Software Interrupt)函数,并为其指定一个特定的中断号。使用这种方法可以实现C代码与特定的中断服务例程(ISR)之间的接口,通常用于嵌入式系统或者操作系统内核的开发中。下面是一个使用__swi关键字来声明软件中断函数的例子:
c
__swi(0x123) void MyInterruptFunction(int argument);
在这个例子中,__swi关键字后跟着括号内的0x123是指定给该软件中断函数的中断号。接下来,void MyInterruptFunction(int argument);声明了一个名为MyInterruptFunction的软件中断函数,它接受一个int类型的参数。
当需要触发这个软件中断时,可以通过以下方式调用这个函数:
c
MyInterruptFunction(argument_value);
此调用将导致产生一个0x123号软件中断,并将argument_value作为参数传递给对应的处理函数。在底层实现中,编译器会将软件中断的调用转换为相应的软件中断指令(如ARM指令集中的SWI指令),并附带正确的中断号。
需要注意的是,具体的__swi关键字的语法和使用方式可能会根据不同的编译器稍有差异。此外,中断服务例程的实现和注册方式也依赖于具体的系统架构和操作系统的要求。
CMN
CMN指令应用示例
假设我们有以下两个寄存器的值:
R1寄存器的值为5
R2寄存器的值为3
我们执行如下指令:
CMN R1, R2
这条指令会将R1和R2的值相加,但不会将结果存储在任何寄存器中。CMN R1, R2等效于R1+R2的操作,但只是用来更新状态寄存器中的标志位,不存储结果。
结果说明
执行上述CMN指令后,R1和R2相加的结果是5 + 3 = 8。根据这个结果,程序状态寄存器(CPSR)将会这样更新:
零标志(Z flag)不会被设置,因为结果8不为零。
负标志(N flag)不会被设置,因为结果8是一个正数。
溢出标志(V flag)和进位标志(C flag)的设置取决于操作数的范围和具体的计算结果。在这个例子中,由于加法未产生位溢出或超过寄存器容量的情况,这两个标志通常不会被设置。
综上所述,CMN指令通过相加操作测试两个数相加的结果,主要用于影响接下来的条件指令,例如BNE(Branch if Not Equal)、BGT(Branch if Greater Than)等,根据CMN操作后状态寄存器中的标志位来决定程序的下一步执行路径。
报错分析
C 编译阶段的错误,语法错误
A 汇编时的错误,汇编语法有问题
L 库不全,地址分配、资源不够的问题
报错
处理器模式
功耗
功率: Dynamic>Standby>Sleep(idle)>off
IDLE只能外部中断唤醒,Standby(Slow)可以程序唤醒
优先级

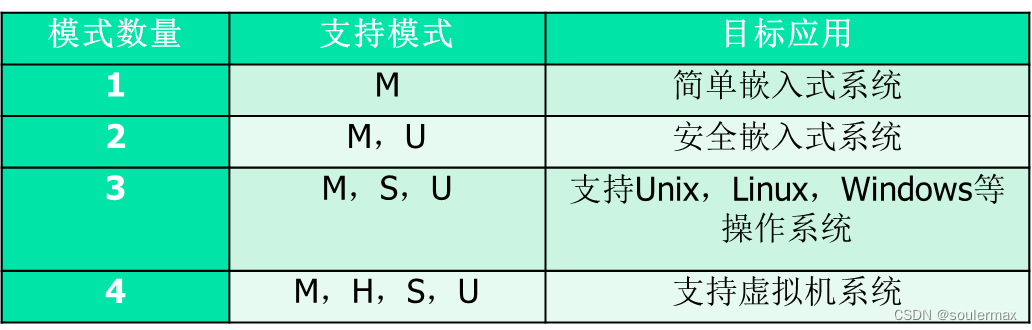
改变操作
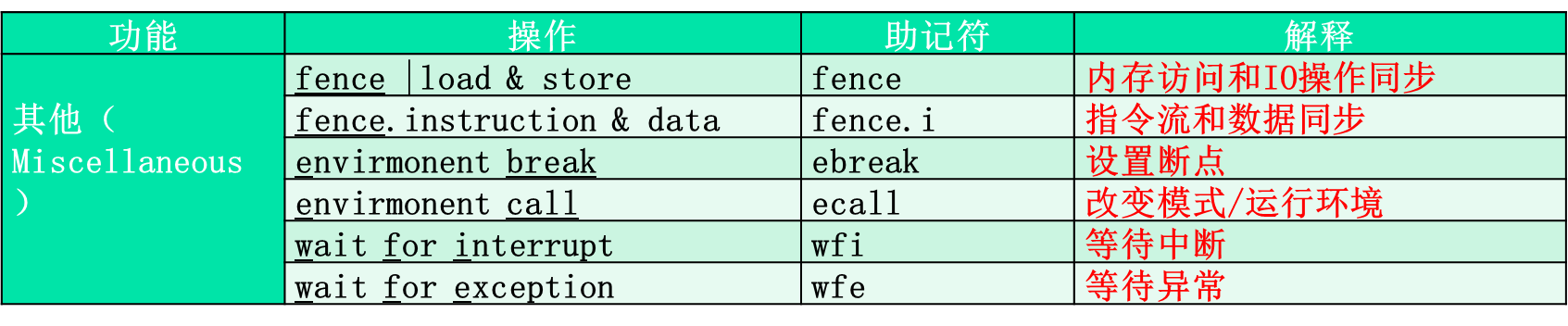
休眠模式WFI,WFE
Startup.s文件的功能和作用?
设置中断向量与中断服务程序地址
分配堆栈空间
设置时钟,看门狗Timer,内存控制,IO端口
设置中断入口IRQ_Entry
实现Reset_Handler
超过四个参数的处理情况
在ARM架构中,当发生软件中断(SWI)时,通常前四个参数会通过寄存器R0到R3传递给中断服务例程(ISR),如果有更多参数,则会通过堆栈传递。以下是处理超过4个参数的一个简单示例:
首先,假设我们有一个函数ExampleFunction,它需要6个参数,我们希望通过SWI来调用这个函数:
c
Copy
void ExampleFunction(int param1, int param2, int param3, int param4, int param5, int param6);
在调用SWI指令之前,我们可以这样准备参数:
c
Copy
// 假设参数已经被定义和初始化
// 将前四个参数加载到R0-R3寄存器
__asm{
MOV R0, param1
MOV R1, param2
MOV R2, param3
MOV R3, param4
}
// 将剩余参数存放到堆栈
__asm{
PUSH param6
PUSH param5
}
然后发起软件中断调用:
c
Copy
__asm{
SWI 0x123456 // 假设这是ExampleFunction对应的中断号
}
在中断服务例程SWI_handler中,我们需要从寄存器和堆栈中恢复这些参数以正确调用ExampleFunction:
c
Copy
void SWI_handler(void)
{
int p1, p2, p3, p4, p5, p6;
// 从寄存器获取前四个参数
p1 = R0;
p2 = R1;
p3 = R2;
p4 = R3;
// 从堆栈获取剩余参数
p5 = *(SP); // 假设SP是堆栈指针寄存器的伪代码表示
p6 = *(SP+4);
// 调用原函数
ExampleFunction(p1, p2, p3, p4, p5, p6);
}
参考第一期汇编的堆栈操作https://blog.csdn.net/soulermax/article/details/139623741
请注意,上述示例使用的是伪代码并简化了堆栈和寄存器操作的细节。在实际应用中,堆栈的操纵可能需要更详细的处理,比如考虑堆栈的增长方向及调用惯例。此外,具体的实现方式可能会根据使用的编译器和ARM的具体版本而有所不同。
软中断流程
1.通过__swi(中断号) function给中断函数指定中断号(一般在C代码中撰写)
2.调用function时,相当于执行了SWI 中断号指令
3.再执行SWI之前需要先注册中断程序,即把处理软中断的程序(SWI_handler)地址放到0x08软中断向量表地址上
4.注册之后执行SWI的时候,会执行0x08中断向量地址上存放的跳转指令(B SWI_handler ),即跳转到SWI_handler;同时将function的参数传递到寄存器内(如果参数不超过4个),超过4个应该存放到内存
5.跳转后,SWI_handler需要干五件事:
1)将保存函数参数的寄存器以及lr寄存器存放到堆栈里保存,
2)通过BIC指令获取中断号放置在r0寄存器,
3)将堆栈指针保存到r1,
4)跳转到要执行function的处理函数中(C_SWI_handle)加密,并将r0,r1寄存器作为函数参数传递
5)处理完中断函数后恢复现场
6.C_SWI_handle接受中断号和堆栈指针,通过堆栈指针开始从堆栈中获取参数数据,根据中断号选择计算的程序逻辑,计算完成将结果再次写入堆栈
7.最后从堆栈中取出计算结果放到寄存器r0中
8.中断结束,从堆栈中恢复现场,继续执行SWI指令后的指令
系统启动流程
以S3C2410A处理器的启动文件startup.s为例.
1.系统上电后,先进行复位Reset
2.设置PC的初始值0,执行Reset_Handler
3.Reset_Handler初始化需要干以下几件事
1)设置WT_Setup(Watchdog Timer)、CLK_Setup(Clock)、MC_Setup(Memory
Controller)、PIO_Setup(IO port)、Stack_Setup(Stack/Heap)
2)设置异常中断的模式的栈指针,包括Undefined、Abort、FIQ、IRQ、Supervisor、User
3)设置SRAM
BL INISDRAM
4)堆栈空间的设置
5)进入C程序代码(__main -> init -> main)
如果调试时无法进入main,可能的原因是什么?
- main单词拼写错误
- 启动代码不对
- 没有将main.c文件添加到工程文件中
BootLoader移植需要修改什么代码?
- 管理和控制处理器内部设备的寄存器地址和数值。
- 不同处理器之间有差别的地方都需要进行修改。
openmp汇总
#pragma omp parallel for
int step = 100;
int _tmain(int argc, _TCHAR* argv[])
{
int i; // 注意int i 不要再for循环里面写int i = 0
#pragma omp parallel for
for (i = 0; i< step; i++)
{
printf("i = %d\n", i);
}
return 0;
}
#pragma omp parallel for private
为了防止共享数据导致并行抢占改写,需要使用private
share共享不能用于类似sum求和的方式
在并行编程中,尤其是在使用如CUDA这类的并行计算框架时,“shared”共享内存的使用限制主要源于其硬件和设计上的特性。使用共享内存进行类似求和(sum)这类操作时的限制或问题主要表现在以下几个方面:
- 竞争条件和原子操作
当多个线程尝试同时访问和修改同一块共享内存区域(如累加操作中的求和变量)时,可能会导致竞争条件。为了确保结果的正确性,必须使用原子操作来进行写操作,这会导致性能下降。因为原子操作会序列化对共享资源的访问,降低了并行度。 - 限制的共享内存大小
共享内存的大小是有限的,通常远小于全局内存。在大规模数据累加的场景中,如果尝试使用共享内存来存储中间结果或数据,很容易超出共享内存的容量限制。 - 同步问题
为了在使用共享内存时保持数据一致性,需要在适当的位置插入同步点,确保所有线程在继续执行前已经完成了对共享内存的访问。这种同步机制(如使用__syncthreads())会阻塞线程执行,直到同一block中的所有线程都达到同步点,可能会导致性能损失,尤其是在不同线程执行路径发散较大时。
因此,在某些情况下,直接在全局内存中进行累加操作并使用原子操作来保证结果的正确性,虽然原子操作可能较慢,但考虑到共享内存大小和同步问题,可能相对更加简单有效。另外,为降低这种操作的性能开销,一种常用的策略是使用分块或分段的方法,首先在每个block内部使用共享内存完成局部求和,然后再将这些局部结果汇总累加到全局变量中,这种方法可以在一定程度上利用共享内存的高速特性,同时减少对全局原子操作的依赖。
总的来说,“为什么share共享不能用于类似sum求和的方式”的问题,根本原因在于并行计算中的数据依赖和同步开销,以及共享内存资源的限制。利用共享内存进行并行累加需要精心设计以避免以上问题,保证高效且正确的计算。
critical每次让一个线程去操作,即让下一行代码串行
float sum = 0.0;
flaot a[10000],b[10000];
for(int j=0;j<10;j++)
{
sum=0.0;
#pragma omp parallel for shared(sum)
for(int i=0; i<N; i++) {
#pragma omp critical
sum += a[i] * b[i];
}
printf(“j=%d, sum=%f\n”,j,sum);
}
return sum;
reduction让所有线程在最后统一执行某一操作,例如:求和“+:”
float dot_prod(float* a, float* b, int N)
{
float sum = 0.0;
#pragma omp parallel for reduction(+:sum)
for(int i=0; i<N; i++) {
sum += a[i] * b[i];
}
return sum;
}
barrier用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行
#pragma omp parallel private(myid,istart,iend)
myrange(myid,istart,iend);
for(i=istart; i<=iend; i++){
a[i] = a[i] – b[i];
}
#pragma omp barrier
myval[myid] = a[istart] + a[0]
schedule分配线程执行
static:线程按顺序分配,线程内数据处理顺序也按照for循环顺序分配
#include <omp.h>
#include <stdio.h>
int main() {
int i;
#pragma omp parallel for schedule(static)
for(i = 0; i < 10; i++) {
printf("Thread %d handles iteration %d\n", omp_get_thread_num(), i);
}
return 0;
}
dynamic:线程随机分配,线程内数据处理顺序也按照for循环顺序分配
#include <omp.h>
#include <stdio.h>
int main() {
int i;
#pragma omp parallel for schedule(dynamic, 2)
for(i = 0; i < 10; i++) {
printf("Thread %d handles iteration %d\n", omp_get_thread_num(), i);
}
return 0;
}
guided:线程和线程内数据处理顺序都是随机分配
#include <omp.h>
#include <stdio.h>
int main() {
int i;
#pragma omp parallel for schedule(guided)
for(i = 0; i < 10; i++) {
printf("Thread %d handles iteration %d\n", omp_get_thread_num(), i);
}
return 0;
}
这里感谢大佬的分享JackHCC
CUDA汇总
上一期提到了一维的CUDA编程https://blog.csdn.net/soulermax/article/details/139690249
本期是二维CUDA的编程
二维CUDA一个Block模板代码
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) // 注意二维数组的参数
{
int i = threadIdx.x;
int j = threadIdx.y; // 需要指定线程的两个维度
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1; // 使用的Block数目
dim3 threadsPerBlock(N, N); // 注意声明dim3类型,每个block采用N*N个线程
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
二维CUDA多个Block模板代码
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y; // 采用blockIDx * blockDim + threadIDx 的方式赋值变量
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16); // 数据类型都采用dim3,每个Block使用后16*16个线程
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); // 计算每个维度需要多少个Block,返回Block数目
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
二维CUDA多个Block参数为指针写法
// Kernel definition
__global__ void MatAdd(float *A, float *B, float *C, int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y; // 采用blockIDx * blockDim + threadIDx 的方式赋值变量
*(C+j*N+i) = *(B+j*N+i) + *(A+j*N+i);
// 或 C[j*N+i] = B[j*N+i] + A[j*N+i];
}
注意数组的写法。
STR R1,[R0,#-4]执行上述指令后R0的值变吗
指令STR R1, [R0, #-4]将寄存器R1的值存储到由R0指向的地址减去4的内存位置中。这条指令本身只修改存储在R0指定的地址处的内存内容,并不改变R0寄存器本身的值。
在ARM架构中,寻址模式[R0, #-4]用于指定以R0为基址,偏移量为-4的内存位置,它是用来计算需要存储数据的目标地址,而不是修改基址寄存器R0本身的值。
因此,执行上述STR R1, [R0, #-4]指令后,R0的值不会变化。只有内存中R0-4这个地址处的内容会被更新为R1寄存器中的值。
计算
CPI
Q:影响处理器性能(CPI等)的因素有哪些?
A:指令集设计,流水线深度,缓存设计,系统结构,机器周期
100M 的主频:时钟周期 T=1/100MHz=10ns,CPI=平均指令执行时间/时钟周期,平均速度=主频/CPI/1e6
最小ROM空间与RAM空间如何计算?
ROM = Code + RO + RW;RAM = RW + ZI;
如果调试过程中程序工作正常,但写入 ROM 后上电程序不能正确执行,可能的原因是什么?
A1:电源有问题;复位电路有问题(缺少 reset 复位程序);BOOT 启动有问题(启动模式选择错误);复位以后,中断向量表不在程序起始位 0x00。
A2:复位时中断向量表是空的,0x00000000没有中断向量表;写了初始化程序,初始化程序错误 ;链接顺序出错,这是导致没有中断向量表的原因之一;模式选择错误,启动模式选择错误。
如果实现上电后能够自动执行,需要哪些条件?
①Keil 环境中 Linker 的 target 地址配置选项应该为: RO Base =0x00000000 RW Base = 0x30000000
②Output 中勾选“Create HEX file”
③DRAM 初始化:Initialization by code Debug Init:需要在代码中加入初始化,上电后才能正常访问 RAM map 0x48000000, 0x60000000 read write ;
④硬件无问题(电源,复位电路,BOOT 引导程序等)
能否将中断向量表中的跳转指令“B”改成“BL”?请说明理由。
不能。BL和B两个指令的区別在于BL指令将当前的PC保存到LR。对于软中断来说,触发中断后。SP和LR切换到相应的模式下的SP和LR,此时LR中保存的是触发中断前的PC,如果中断向量表中的B改成BL,那么LR寄存器就会被修改,中断服务程序执行后就无法返回到触发中断的程序。
影响Cache命中率的因素有什么?
Cache 大小,替换策略(直接相连等),程序的结构和数据的访问方式。
某系统上电后不能自启动,可能的原因是?
没有装在Flash里;缺少Reset向量;缺少启动程序;板子坏了;中断向量表无法正常加载。
程序对Cache命中率的影响?
编写程序时,对同一个变量处理过程尽量放置在相近位置,这样可以提高 Cache的命中率。
程序中如何实现地址转换?
内存管理单元(Memory Manage Unit,MMU) :
控制虚拟地址(VA)映射到物理地址(PA)
控制内存的访问权限
控制可缓存性和缓冲性
影响流水线加速效果的因素?
流水线的的结构(分级数量和不同级执行时间的均匀性),能够连续顺序执行指令的数量,以及指令之间数据的相关性影响流水线加速比。
如果调试时无法进入main,可能的原因是什么?
main单词拼写错误;启动代码不对;没有将main.c文件添加到工程文件中。
中断程序无响应的原因?
没有中断服务程序;中断被屏蔽。
ARM9的三类地址:
虚拟地址(VA),是程序中的逻辑地址,0x00000000~0xFFFFFFFF
改进的虚拟地址(MVA),由于多个进程执行,逻辑地址会重合。所以,跟据进程号将逻辑地址分布到整个内存中。MVA = (PID << 25) | VA。PID占7位,所以最多只能有128个进程,每个进程只能分到 32MB 的逻辑地址空间
物理地址(PA),MVA通过MMU转换后的地址
adr最大偏移
不对齐255Byte,对齐1020Byte(255Words);adrl最大偏移:不对齐64KB,对齐256KB;Thumb指令没有adrl
Thumb指令特点:
使用ARM的r0-r7 8个通用寄存器
Thumb指令没有条件执行
指令自动更新标志,不需加(s)
仅有LDMIA(STMIA) ;只有IA一种形式且必须加“!”
在数据运算指令中,不支持第二操作数移位。
参数返回规则
结果为32bit整数时,通过r0传递
结果为64bit整数时,通过r0和R1传递
结果为浮点数时,通过浮点寄存器返回(f0,d0)
更多的数据通过内存返回
嵌入汇编
不支持 LDR Rn,= XXX 和 ADR, ADRL 伪指令
不支持 BX
用”&”替代 “0x” 表示16位数据
无需保存和恢复寄存器
参数
宽参数传递,被调用者把参数缩小到正确的范围。
宽返回,调用者把返回值缩小到正确的范围。
窄参数传递,调用者把参数缩小到正确的范围。
窄返回,被调用者把参数缩小到正确的范围。
GCC是宽参数传递和宽返回。
armcc 是窄参数传递与窄返回
尽量用int 或 unsigned int 型参数。
对于返回值尽量避免使用char和short类型
用局部变量替换全局变量,减少程序访问存储器的次数。
















 3325
3325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









