






Verilog Test Bench
激励
施加激励
产生激励并加到设计有很多 种方法。一些常用的方法有:
• 从一个initial块中施加线性激励
• 从一个循环或always块施加激励
• 从一个向量或整数数组施加激励
• 记录一个仿真过程,然后在另一个仿真中回放施加激励
线性激励
• 线性激励有以下特性:
‾ 只有变量的值改变时才列出
‾ 易于定义复杂的时序关系
‾ 对一个复杂的测试,测试程序(test bench)可能非常大
循环激励
• 从循环产生激励有以下特性:
‾ 在每一次循环,修改同一组激励变量
‾ 有固定的时序关系
‾ 代码紧凑
数组激励
• 从数组产生激励有以下特性:
‾ 在每次反复中,施加同一组激励变量
‾ 激励数组可以直接从文件中读取
矢量采样
• 在仿真过程中可以对激励和响应矢量进行采样,作为其它仿真的激励和期望结果。
矢量回放
• 保存在文件中的矢量反过来可以作为激励
• 使用矢量文件输入/输出的优点:
– 激励修改简单
– 设计反复验证时直接使用工具比较矢量文件。
Verilog延时模型
术语及定义
• 硬件描述语言HDL:描述电路硬件及时序的一种编程语言
• 仿真器:读入HDL并进行解释及执行的一种软件
• 抽象级:描述方式的详细程度,如行为级和门级
• ASIC:专用集成电路(Application Specific Integrated Circuit)
• ASIC Vender:芯片制造商,开发并提供单元库
• Bottom-up design flow :一种先构建底层单元,然后由底层单元构造更大的系统的设计方法 。
• Top-down design flow :一种设计方法,先用高抽象级构造系统,然后再设计下层单元。
• RTL level:寄存器传输级(Register Transfer Level),可综合的一种设计抽象级
• Tcl:Tool command Language, 向交互程序输入命令的描述语言
• CTLF:(Compiled Timing Library Format)编译的时序库格式。特定工艺元件数据的标准格式。
• GCF:(General constraint Format)通用约束格式。约束数据的标准格式。
• MIPD:(Module Input Port Delay)模块输入端口延时。模块输入或输入输出端口的固有互连延时。
• MITD:(Multi-source Interconnect Transport Delay)多重互连传输延时。与SITD相似,但支持多个来源的不同延时。
• PLI:(Programming Language Interface)编程语言界面。基于C的对Verilog数据结构的程序访问。
• SDF:Standard Delay Format.(标准延时格式)。时序数据OVI标准格式。
• SITD:Single-Source Interconnect Transport Delay,单一源互连传输延时。和MIPD相似,但支持带脉冲控制的传输延时。
• SPF:Standard Parasitic Format.(标准寄生参数格式)。提取的寄生参数数据的标准格式。
• false path:在电路中一种有物理连接的路径,但实际工作时信号不会沿此路径传播,这种路径称为false path。又名伪路径
• 它主要用于:
- 异步时钟域:信号跨异步时钟域进行通信
- 静态电路:上电后进行配置并且以后不会变化的寄存器,可以认为是纯异
步路径。 - 异步复位电路
• 环境约束:对电路工作的外在环境,包括电路的工作电压、工作温度以及工艺变化,以及电路与周边其他电路的关系,包括输入引脚的延时及驱动能力,输出引脚的负载及输出延时。
• 上升延时:信号从10%电平上升到90%电平所需要的时间。
• 固有延时:也是惯性延时,是任何电子器件都存在的一种延时特性,主要物理机制是分布电容效应。
• 传输延时:与固有延时相比,其不同之处在于传输延时时表达的是输入与输出之间的一种绝对延时关系。传输延时并不考虑信号持续的时间,它仅表示信号传输推迟或延迟了一个时间段,这个时间段即为传输延时。
• 模块路径(module path): 穿过模块,连接模块输入(input端口或inout端口)到模块输出(output端口或inout端口)的路径。
• 块延时(Lumped Delay):将全部延时集中到最后一个门上。这种模型简单但不够精确,只适用于简单电路。因为当到输出端有多个路径时不能描述不
同路径的不同延时。
可以用这种方法描述器件的传输延时,并且使用最坏情况下的延时(最大延时)。
• 分布延时:将延时标注在电路中的每个门上的延时描述方式。
缺点:
– 在结构描述中随规模的增大而变得异常复杂。
– 仍然不能描述基本单元(primitive)中不同引脚上的不同延时。

• 路径延时(path delay):与特定路径相关的延时。
specify
(A => O) = 2;
(B => O) = 3;
(C => O) = 1;
endspecify
• 时序检查(timing check):监视两个输入信号的时间关系并进行检查的系统任务,以保证电路能正确工作。
• 时序驱动设计(timing driven design):从前端到后端的整个设计流程中,用时序信息连接不同的设计阶段。
• VCD:波形记录数据库
• SHM:波形数据库
• 结构描述 : 用门及门的连接描述器件的功能
• primitives(基本单元) : Verilog语言已定义的具有简单逻辑功能的功能模型(models)
• 时钟从时钟源出发到达触发器时钟端口的延时,
称为时钟延迟,包含时钟源延迟(source
latency)和时钟网络延迟(network latency)。
• 时钟源延迟,也称为插入延迟(insertion
delay),是时钟信号从其实际时钟源点到达设计
中时钟定义点的传输时间。
• 时钟网络延迟是时钟信号从其定义的点到寄存器的时钟引脚的传输,经过缓冲器和连线产生的延迟。
• 时钟的不确定性:时钟偏移和时钟抖动都影响着时钟网络分支的延迟差异,在逻辑综合时,统称为时钟的不确定性。
• 时钟偏移:在时钟信号通过时钟网络到达寄存器的时钟引脚的过程中,由于存在线网延时、负载不均衡等原因,使得到达不同的寄存器时钟引脚的时
间不一致,即存在相位差,这种相位差称为时钟偏移,或时钟偏斜。
• 时钟偏移与时钟频率并没有直接关系,只与时钟线的长度及被时钟线驱动的时序器件的负载电容、个数有关。
• 时钟倾斜是同一个时钟有效沿到达各个负载的时间差。
• 有效的时钟树:减小时钟倾斜和时钟插入延迟。
• 三边沿准则:如果较快时钟域的频率是较慢时钟域的频率(或更多)的 1.5 倍
• 随机抖动:来源为热噪声、散粒噪声和轻弹噪声;
• 固有抖动:来源为开关电源噪声、串扰、电磁干扰等等,与电路设计有关,可以通过优化设计来改善,比如选择合适的电源滤波方案、合理的PCB布局和布线。
• 晶体振荡器:精度和稳定性最高,但芯片硅材料兼容性较差,若集成于芯片内部,会导致芯片面积增大,且频率固定且无法更改,一般作为片外系统时钟源;
• 环形振荡器:结构简单、功耗低,但其稳定性较低,不能满足系统时钟的性能要求;
• LC 振荡器:稳定性高,但电感的使用导致面积较大且成本较高;
• RC 振荡器:面积较小、成本较低,但其精度、稳定性易受温度和电源电压影响。(一般采用)
精确延时控制
• 说明门和模块路径的上升(rise)、下降(fall)和关断(turn-off)延时
and #(2, 3) (out, in1, in2, in3); // rise, fall
bufif0 #( 3, 3, 7) (out, in, ctrl); // rise, fall, turn- off
(in => out) = (1, 2); // rise, fall
(a => b) = (5, 4, 7); // rise, fall, turn-off
• 在路径延时中可以说明六个延时值(0 →1, 1 →0, 0 →Z, Z →1, 1 →Z, Z →0)
(C => Q) = (5, 12, 17, 10, 6, 22);
• 在路径延时中说明所有12个延时值(0 →1, 1 →0, 0 →Z, Z →1, 1 →Z, Z →0, 0 →X, X →1, 1 →X, X →0, X →Z, Z →X)
(C => Q) = (5, 12, 17, 10, 6, 22, 11, 8, 9, 17, 12, 16);
• 上面所说明的每一个延时还可细分为最好、典型、最坏延时。
or #( 3.2:4.0:6.3) o1( out, in1, in2); // min: typ: max
not #( 1:2:3, 2:3:5) (o, in); // min: typ: max for rise, fall
(b => y) = (2:3:4, 3:4:6, 4:5:8); // min: typ: max for rise, fall, and turnoff
触发器延时
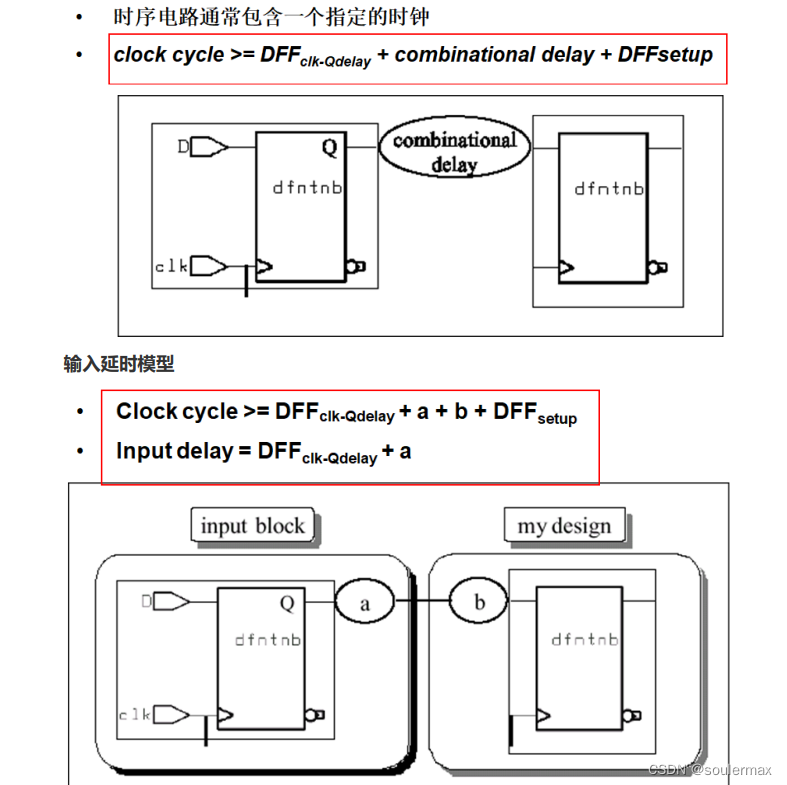
精确时序仿真–时序标注
通常的Verilog元件库仅包含固定时序数据。
若要进行精确的时序仿真,还需要的数据有:
• 输入传输时间
• 固有延时
• 驱动强度
• 总负载
• 互连寄生
• 环境因子
– 过程
– 温度
– 电压
同时还需要仿真最坏情况下的数据和最佳情况下时钟,反过来也要做一次。
在没有时序标注时Verilog仿真器做不到这一点。
verilog常见错误
reg与wire
模块端口和与之链接的信号的数据类型必须遵循以下规定:
1.输入端口在模块内部必须为wire形数据;在模块外部可以连接wire或者reg型数据。
2.输出端口在模块内部可以为wire或者reg型数据,在模块外部必须连接到wire型数据。
3.连接的两个端口位宽可以不同。
assign块与always块
assign块主要为wire赋值,always块主要为reg赋值。
标点符号
in,out声明中最后一个不应该有逗号,端口声明括号后面应该有分号。
敏感表不完全
看敏感列表有没有包括所有影响赋值的信号。
always触发信号应该有@
wait语句-电平敏感:
wait用于行为级代码中电平敏感的时序控制。
下面的输出锁存的加法器的行为描述中,使用了用关键字or的边沿敏感时序以及用wait语句描述的电平敏感时序。

仿真工具及testbench编写
仿真算法
• 主要有三种仿真算法
– 基于时间的(SPICE仿真器)
– 基于事件的(Verilog-XL和NC Verilog仿真器)
– 基于周期的(cycle)
• 基于时间的算法用于处理连续的时间及变量
– 在每一个时间点对所有电路元件进行计算
– 效率低。在一个时间点只有约2~10%的电路活动
• 基于事件的算法处理离散的时间、状态和变量
– 只有电路状态发生变化时才进行处理,只模拟哪些可能引起电路状态改变的元件。仿真器响应输入引脚上的事件,并将值在电路中向前传播。
– 是应用最为广泛的仿真算法
– 效率高。“evaluate when necessary”
• 基于周期的仿真以时钟周期为处理单位(与时间无关)
– 只在时钟边沿进行计算,不管时钟周期内的时序
– 使用两值逻辑 (1, 0)
– 只关心电路功能而不关心时序,对于大型设计,效率高
– 仅适用于同步电路
• 基于事件仿真的时轮(time wheel)
• 仿真器在编译数据结构时建立一个事件队列。
• 只有当前时间片中所有事件都处理完成后,时间才能向前。
• 仿真从时间0开始,而且时轮只能向前推进。只有时间0的事件处理完后才能进入下一时片。
• 在同一个时间片内发生的事件在硬件上是并行的。
• 理论上时间片可以无限。但实际上受硬件及软件的限制。
系统任务
$finish是结束仿真的系统任务。
$time 系统函数,返回仿真当前时间
$monitor 系统任务,若参数列表中的参数值发生变化,则在时间单位末显示参数值。
m
o
n
i
t
o
r
(
monitor(
monitor(time, o, in1, in2);
m
o
n
i
t
o
r
(
monitor(
monitor(time, out, a, b, sel);
m
o
n
i
t
o
r
(
monitor(
monitor(time, “%b %h %d %o”, sig1, sig2, sig3, sig4);
(注意不能有空格)
d
i
s
p
l
a
y
显示信号值如
display 显示信号值 如
display显示信号值如display(“ %b %b %b”, a, b, c)
m
o
n
i
t
o
r
监视信号值如
monitor监视信号值 如
monitor监视信号值如monitor($time," o=%b a=%b b=%b s=%b", o, a, b, s);
$stop停止仿真
SHM:波形数据库

initial
begin
$shm_open(“./data/lab.shm”);
$shm_probe( );
end
用$shm_probe设置信号探针
$shm_probe(scope0, node0, scope1, node1, …);

VCD数据库
VCD数据库是仿真过程中数据信号变化的记录。它只记录用户指定的信号。
• 用户可以用
d
u
m
p
系统任务打开一个数据库,保存信号并控制信号的保存。除
dump系统任务打开一个数据库,保存信号并控制信 号的保存。除
dump系统任务打开一个数据库,保存信号并控制信号的保存。除dumpvars外,其它任务的作用都比较直观。
d
u
m
p
v
a
r
s
将在后面详细描述。•必须首先使用
dumpvars将在后面详细描述。 • 必须首先使用
dumpvars将在后面详细描述。•必须首先使用dumpfile系统任务,并且在一次仿真中只能打开一个VCD数据库。
• 在仿真前(时间0前)必须先指定要观测的信号,这样才能看到信号完整的变化过程。
• 仿真时定期的将数据保存到磁盘是一个好的习惯,万一系统出现问题数据也不会全部丢失。
• VCD数据库不记录仿真结束时的数据。因此如果希望看到最后一次数据变化后的波形,必须在结束仿真前使用$dumpall。
$dumpvars
• $dumpvars; // Dump所有层次的信号
• $dumpvars (1, top); // Dump top模块中的所有信号
• $dumpvars (2, top.u1); // Dump实例top. u1及其下一层的信号
• $dumpvars (0, top.u2, top.u1.u13.q); // Dump top.u2及其以下所有信号,以及信号top.u1.u13.q。
• $dumpvars (3, top.u1, top.u2); // Dump top.u1和top.u2及其下两层中的所有信号。
initial
begin
$dumpfile (“verilog.dump”);
$dumpvars (0, testfixture);
end
d
u
m
p
v
a
r
s
[
(
<
l
e
v
e
l
s
>
,
<
s
c
o
p
e
>
∗
)
]
;
s
c
o
p
e
可以是层次中的信号,实例或模块。•仿真时所有信号必须在同一时间下使用
dumpvars[(< levels>, <scope>*)]; scope可以是层次中的信号,实例或模块。 • 仿真时所有信号必须在同一时间下使用
dumpvars[(<levels>,<scope>∗)];scope可以是层次中的信号,实例或模块。•仿真时所有信号必须在同一时间下使用dumpvars。
• 就是说可以使用多条$dumpvars语句,但必须从同一时间开始。
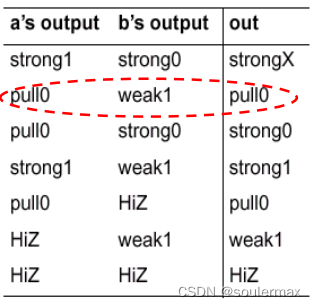
信号强度值系统
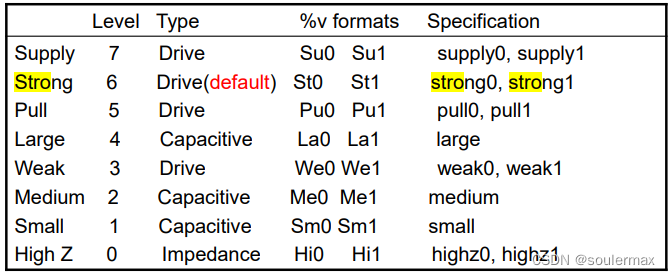
在Verilog中,级别高的强度覆盖级别低的强度。
约束(constraint)
• 约束是Design Compiler优化一个设计到目标工艺库的目标
• 设计规则约束(DRC):与所采用的制造工艺相关的限制,如最大的传输时间、最大的扇出、最大电容等。
• 设计规则 (Design Rule)约束:是由制造工艺决定的,是绝对不能违反的约束,即使时间及面积约束不能满足也在所不惜。
• 设计规则约束有三类:
- max_transition
- max_capacitance
- max_fanout
• 性能优化约束:设计目标及要求。如最大延时、最小延时、最大面积、最大功耗等。
• 在编译时,Design Compiler试图满足所有约束。
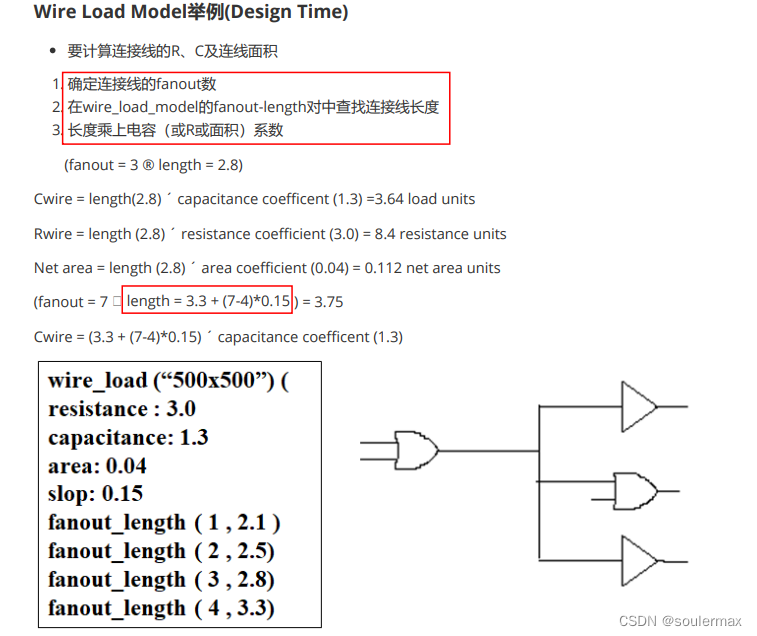
Wire Load Model
参数重载(overriding)
//instantiation
defparam u_ram_4x4.MASK = 7 ;
ram_4x4 u_ram_4x4
(
.CLK (clk),
.A (a[4-1:0]),
.D (d),
.EN (en),
.WR (wr), //1 for write and 0 for read
.Q (q) );
generate - 根据参数例化不同模块
module …..
generate
if (a1_width < 8)
mult_8bit u1 (a1, a2, prt);
else
mult_16bit u1 (a1, a2, prt);
endgenerate
…...
endmodule
generate
genvar i;
for (i = 0; i < 4; i = i + 1)
begin: u //命名块,若没有命名u,则工具自动生成
adder8 add (sum[i], co[i+1], a1[i], a2[i], ci[i]);
end
endgenerate
高级结构
task
module top;
……
task task_name;
<parameter_declaration>; //参数声明
<input_declaration>; //输入声明
<output_declaration>; //输出声明
<inout_declaration>; //inout声明
<reg_declaration>;
<time_declaration>; //内部变量声明
<integer_declaration>;
<event_declaration>;
begin
statement;
statement;
end
endtask
initial task_name(argu_list); // 任务调用
endmodule
静态例子
module mult (
input wire clk ,
en_mult ,
input wire [3: 0] a ,
b ,
output reg [7: 0] out
);
always @( posedge clk)
multme (a, b, out);
task multme; // 任务定义
input [3: 0] xme,
tome;
output [7: 0] result;
wait (en_mult)
result = xme * tome;
endtask
endmodule
动态例子
`timescale 1ns/1ns
module mult (
input wire clk ,
en_mult ,
input wire [3: 0] a , b
output reg [7: 0] out1 ,
out2
);
always @( posedge clk)
multme (a, b, out1);
always @( negedge clk)
multme (a, b, out2);
task automatic multme;
input [3: 0] xme,
tome;
output [7: 0] result;
begin
wait(en_mult);
#7 result = xme * tome;
end
endtask
endmodule
同步器总结
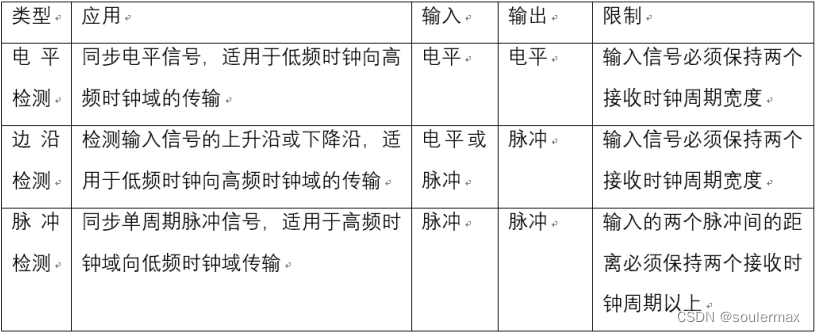
握手同步器由两个脉冲同步器构成。(边沿同步器也可以),适用于实现较为复杂,特别是其效率不高,在对设计性能要求较高的场合应该慎用。
SoC芯片的复位信号
- 冷复位:即上电复位 POR(Power On Reset)将整个芯片所有逻辑进行复位,包括微处理器、DSP及所有IP。
- 热复位:当系统产生严重错误,如死机时通过按键对系统复位。大多数热复位与冷复位相同,并使用同一个复位引脚,但也可能是采用独立引脚进行复位,可以使特定电路,如调试电路不复位,而其它电路全部得复位。
- 低电压复位(LVR复位):芯片集成欠压检测(BOD,brown out detector)模块,若检测到电压低于最低工作电压,则产生复位信号。
- 看门狗复位:很多系统设置了看门狗功能。看门狗实质上是一个计数器,系统初始化时会配置并启动看门狗。在工作过程中会定时对计数器清0。若系统程序运行错误致使计数器计满,发出系统中断或系统复位请求信号。
- 软件复位:由软件控制对系统中的某个部件进行复位,如发现某个部件工作状态异常,或为了降低功耗控制某部分断电,由软件控制其复位。















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









