







针对上一篇文章,安装完毕之后,可以对faiss进行基本的案例学习,具体步骤如下:
step1:构造实验数据

step2:为向量集构建IndexFlatL2索引,它是最简单的索引类型,只执行强力L2距离搜索

step3:进行简单的k-近邻搜索
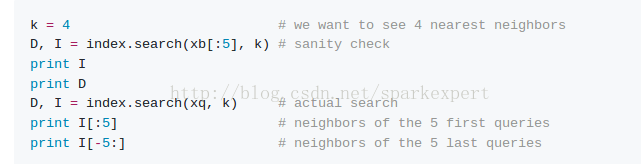
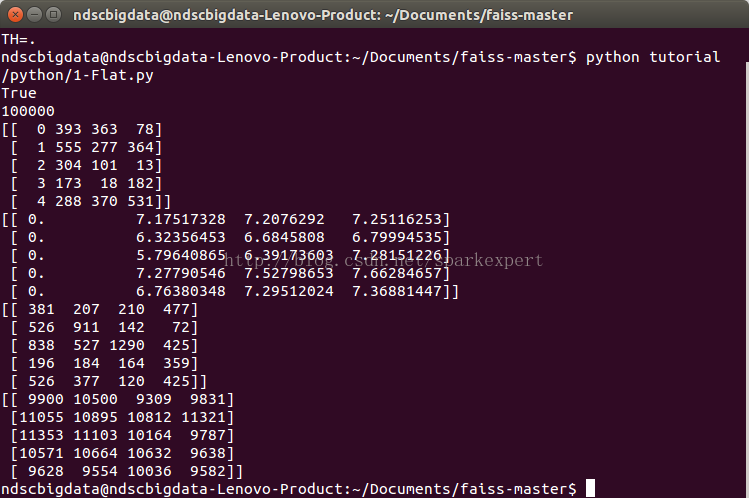
结果如下:
NOTE:
1.程序输出为查询向量的最近邻的4个向量的索引
step4:加快搜索速度
方法:
通过使用IndexIVFFlat索引,将数据集分割成多个,我们在d维空间中定义Voronoi单元,每个数据库向量落在其中一个单元格中。在搜索时,只有查询x所在的单元格中包含的数据库向量y和几个相邻的数据库向量y与查询向量进行比较。
搜索方法有两个参数:nlist(单元格数),nprobe(执行搜索访问的单元格数(nlist以外))
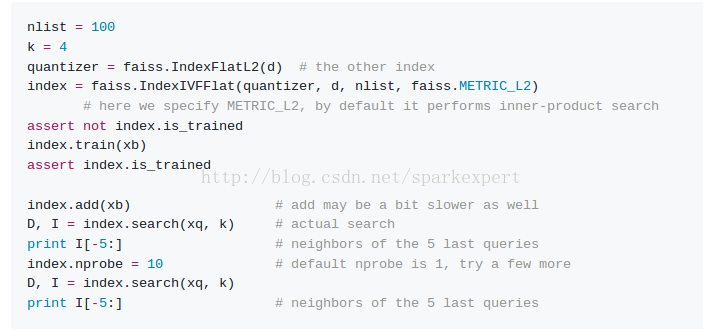
对于nprobe = 1,结果如下:
结果和上面的强力搜索类似,但是不同(见上文)。这是因为一些结果不在完全相同的Voronoi细胞。因此,访问更多的单元格可能是有用的。
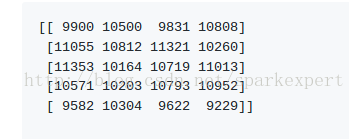
设置nprobe = 10,结果如下:
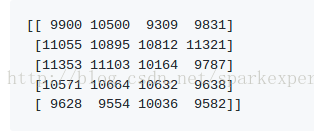
这是正确的结果。
但注意:在这种情况下获得完美的结果只是数据分布的一个假象,因为它在x轴上有一个强大的组件,这使得它更容易处理。nprobe参数始终是调整速度和结果精度之间权衡的一种方式。设置nprobe = nlist给出与强力搜索相同的结果(但较慢)。
step5:进一步缩小存储空间
我们看到的索引IndexFlatL2和IndexIVFFlat都存储完整的向量。 为了扩展到非常大的数据集,Faiss提供了基于产品量化器的有损压缩来压缩存储的向量的变体。压缩的方法基于乘积量化。
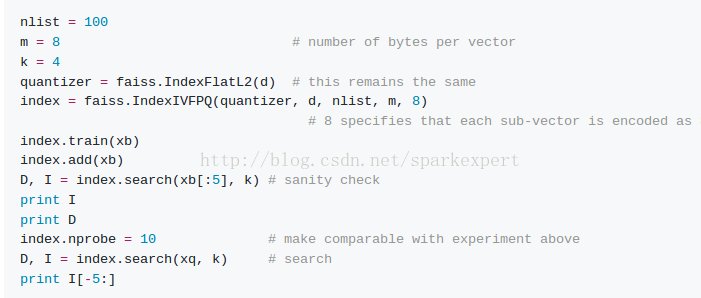
结果如下:
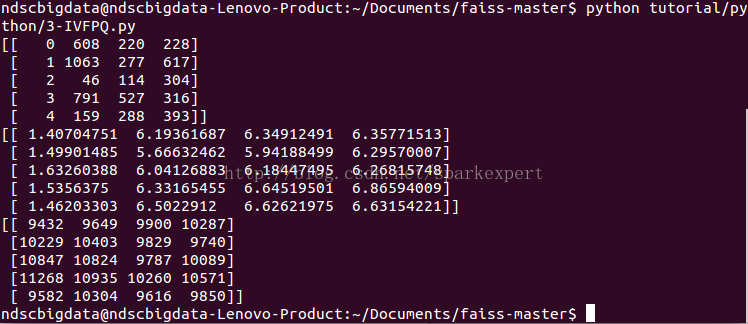
我们可以观察到最近的邻居被正确地找到(它是矢量ID本身),但是向量自身的估计距离不是0,尽管它远远低于与其他邻居的距离。这是由于有损压缩。
另外搜索真实查询时,虽然结果大多是错误的,但是它们在正确的空间区域,而对于真实数据,情况更好,因为:
1.统一数据很难进行索引,因为没有规律性可以被利用来聚集或降低维度
2. 对于自然数据,语义最近邻居往往比不相关的结果更接近。















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









