






This section introduces the open-loop methods where the grasp points are assumed to have been detected with the above mentioned procedures. These methods design the path from the robot hand to the grasp points on the target object. Here motion representation is the key problem. Although there exist an infinite number of trajectories from the robotic hand to the target grasp points, many areas could not be reached due to the limitations of the robotic arm. Therefore, the trajectories need to be planned. There exist three kinds of methods in the literatures, which are traditional DMP-based methods, imitating learning-based methods, and reinforcement learning-based methods, as shown in 4. Typical functional flow-charts of DMP-based methods, imitating learning-based methods, and reinforcement learning-based methods to move to the grasp point, are illustrated in Fig. 32.
本节介绍开环方法,其中假定已通过上述过程检测到目标点。 这些方法设计了从机器人手到目标物体上抓点的路径。 在这里,运动表示是关键问题。 尽管从机械手到目标抓握点的轨迹是无限的,但由于机械臂的限制,无法到达许多区域。 因此,需要计划轨迹。 文献中存在三种方法,分别是传统的基于DMP的方法,基于模仿学习的方法和基于强化学习的方法,如表4所示。基于DMP的方法,基于模仿学习的方法和基于强化学习的方法将机器人手移至抓点的典型功能流程图如图32所示。

Traditional methods
传统方法
Traditional methods consider the dynamics of the motion and generate motion primitives. The Dynamic Movement Primitives (DMPs) [Schaal, 2006] are one of the most popular motion representations that can serve as an reactive feedback controller. DMPs are units of action that are formalized as stable nonlinear attractor systems. They encode kinematic control policies as differential equations with the goal as the attractor [Rai et al., 2017]. A nonlinear forcing term allows shaping the transient behavior to the attractor without endangering the well-defined attractor properties. Once this nonlinear term has been initialized, e.g., via imitation learning, this movement representation can be generalized with respect to task parameters such as start, goal, and duration of the movement.
传统方法考虑运动的动力学并生成运动图元。 动态运动基元(DMP)[Schaal,2006]是可以用作反应反馈控制器的最受欢迎的运动表示之一。 DMP是作用单元,被形式化为稳定的非线性吸引系统。 他们将运动控制策略编码为微分方程,目标是吸引子[Rai等,2017]。 非线性强迫项可以使吸引子的瞬态行为成形,而不会危及明确定义的吸引子特性。 一旦该非线性项已经被初始化,例如,通过模仿学习,就可以相对于任务参数,例如运动的开始,目标和持续时间,来概括该运动表示。
DMPs have been successfully used to in imitation learning, reinforcement learning, movement recognition and so on. Colomé et al. [Colomé and Torras, 2018] addressed the process of simultaneously learning a DMP-characterized robot motion and its underlying joint couplings through linear dimensionality reduction, which provides valuable qualitative information leading to a reduced and intuitive algebraic description of such motion. Rai et al. [Rai et al., 2017] proposed learning feedback terms for reactive planning and control. They investigate how to use machine learning to add reactivity to a previously learned nominal skilled behaviors represented by DMPs. Pervez and Lee [Pervez and Lee, 2017] proposed a generative model for modeling the forcing terms in a task parameterized DMP. Li et al. [Li et al., 2018a] proposed an enhanced teaching interface for a robot using DMP and Gaussian Mixture Model (GMM). The movements are collected from a human demonstrator by using a Kinect v2 sensor. GMM is employed for the calculation of the DMPs, which model and generalize the movements.
DMP已成功用于模仿学习,强化学习,动作识别等。Colomé等人 [Coloméand Torras,2018]提出了通过线性降维同时学习DMP特征的机器人运动及其潜在关节耦合的过程,该过程提供了有价值的定性信息,从而简化了此类运动的直观代数描述。 Rai等人[Rai et al.,2017]提出了用于反应性规划和控制的学习反馈术语。他们研究了如何使用机器学习将反应性添加到DMP代表的先前学习的名义熟练行为中。 Pervez和Lee [Pervez and Lee,2017]提出了一种生成模型,用于对任务参数化DMP中的强迫项进行建模。 Li等人[Li et al.,2018a]提出了一种使用DMP和高斯混合模型(GMM)的增强型机器人教学界面。通过使用Kinect v2传感器从人类演示者收集动作。 GMM用于计算DMP,从而对运动进行建模和概括。
Imitation learning
模仿学习
This kind of method is also known as learning from demonstration. For the traditional methods, the kinematics of the robot is ignored, as it assumes that any set of contacts on the surface of the object can be reached, and arbitrary forces can be exerted at those contact points. Anyway, the actual set of contacts that can be made by a robotic hand is severely limited by the geometry of the hand. Through imitation learning, the grasp actions learned from successful grasps could be mapped to the grasping of target object in a more natural way. The movements from the demonstration can be decomposed into DMPs. When grasping the same or similar object, the same movement trajectory can be utilized.
这种方法也称为从演示中学习。 对于传统方法,机器人的运动学被忽略了,因为它假定可以达到物体表面上的任何一块接触区域,并且可以在那些接触点上施加任意的力。 无论如何,可以由机械手进行的实际接触集受到手的几何形状的严格限制。 通过模仿学习,可以将从成功的抓取中学到的抓取动作以更自然的方式映射到对目标对象的抓取。 演示中的动作可以分解为DMP。 当抓取相同或相似的物体时,可以利用相同的运动轨迹。
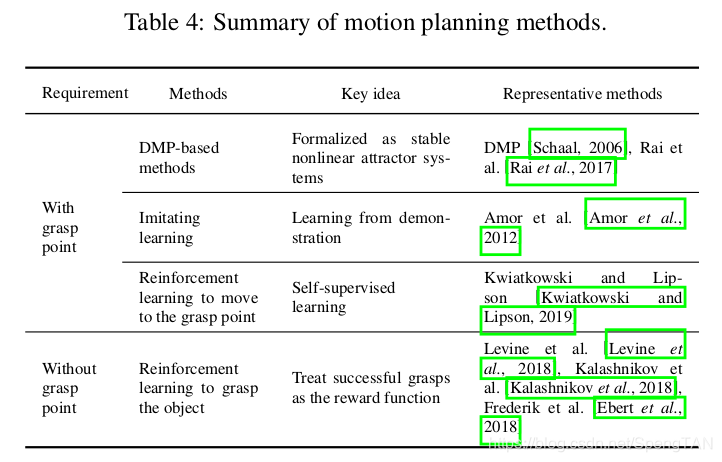
If the target object exists in a stored database, the grasp points could be directly obtained. The problem then becomes finding a path from the start-point to the end-point to reach the target object, and grasping the object with particular poses. If the target object is similar with example objects, the grasp point of the target object can be obtained through the methods in Section 3.5. The target object will be compared with those in the database and a demonstrated grasp used on a similar object will be selected. The target object can be considered as a transformed version of the demonstration object, and the grasp points can be mapped from one object to the other. Amor et al. [Amor et al., 2012] presented an imitation learning approach for learning and generalizing grasping skills based on human demonstration, as shown in Fig. 33. They split the task of synthesizing a grasping motion into three parts: learning efficient grasp representations from human demonstrations, warping contact points onto new objects, and optimizing and executing the reach-and-grasp movements. Their method can be used to easily program new grasp types into a robot and the user only needs to perform a set of example grasps.
如果目标对象存在于存储的数据库中,则可以直接获取抓取点。然后,问题就变成了找到从起点到终点的路径以到达目标对象,并以特定的姿势抓住对象。如果目标对象与示例对象相似,则可以通过第3.5节中的方法获得目标对象的抓点。将目标对象与数据库中的对象进行比较,并选择对类似对象的证明掌握。目标对象可以视为演示对象的变形版本,并且可以将抓取点从一个对象映射到另一个对象。 Amor等[Amor et al。,2012]提出了一种模仿学习方法,用于基于人类演示来学习和推广抓握技能,如图33所示。他们将合成抓握动作的任务分为三个部分:从人类那里学习有效的抓握表示演示,将接触点弯曲到新对象上,并优化和执行触手可及的动作。他们的方法可用于轻松地将新的抓握类型编程到机器人中,并且用户只需要执行一组示例抓握即可。
Reinforcement learning to move to the grasp point
强化学习
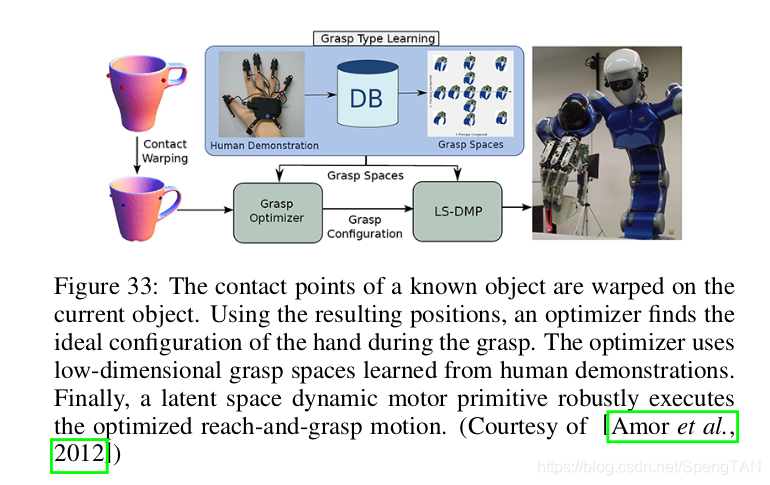
There exist methods utilizing reinforcement learning to achieve more natural movements [Kwiatkowski and Lipson,2019]. Aiming at the low control resolution of the robotic arm, Kwiatkowski and Lipson [Kwiatkowski and Lipson, 2019] proposed a self-modeling machine for the robotic arm, as shown in Fig. 34. They build the trajectory space of the robotic arm through random sampling, and then plan the path to the grasp position. This self-model can be applied to different tasks such as pick-and-place and handwriting. Their method provides a useful way to use simulators.
存在利用强化学习来实现更多自然运动的方法[Kwiatkowski and Lipson,2019]。 针对机器人手臂的低控制分辨率,Kwiatkowski和Lipson [Kwiatkowski and Lipson,2019]提出了一种用于机器人手臂的自建模机,如图34所示。他们通过随机建立机器人手臂的轨迹空间。 采样,然后计划到抓握位置的路径。 该自模型可以应用于不同的任务,例如取放和手写。 他们的方法提供了使用模拟器的有用方法。
Methods considering obstacles
考虑障碍的方法
Sometimes, the robot cannot approach the target object for reasons like constrained space, various obstacles and so on. Meanwhile, the obstacles may be too large for the robot to grasp. This requires the robot’s interaction with the environment. The most commonly seen solution for such grasping tasks is the object-centric method [Laskey et al., 2016], which separates the target and the environment. This kind of method works well in structured or semi-structured settings where objects are well separated. There also exists a clutter-centric approach [Dogar et al., 2012], which utilizes action primitives to make simultaneous contact with multiple objects. With this approach, the robot reaches for and grasps the target while simultaneously contacting and moving aside objects to clear a desired path.
有时,机器人由于空间受限,各种障碍物等原因而无法接近目标对象。 同时,障碍可能太大,机器人无法抓住。 这需要机器人与环境的互动。 对于此类抓取任务,最常见的解决方案是以对象为中心的方法[Laskey et al。,2016],该方法将目标与环境分开。 这种方法在对象分离良好的结构化或半结构化设置中效果很好。 还有一种以混乱为中心的方法[Dogar等,2012],该方法利用动作原语同时与多个对象接触。 通过这种方法,机器人可以到达并抓住目标,同时接触并移动物体以清除所需路径。
Challenges
The main challenge of this kind of methods is that it heavily depends on the accuracy of grasp detection. If the grasp positions are detected accurately, the motion planing will achieve a high rate of success. The efficiency of escaping the obstacles is also a challenge for practical robot operations.
这种方法的主要挑战在于,它在很大程度上取决于抓握检测的准确性。 如果准确地检测到抓握位置,则运动计划将获得很高的成功率。 逃脱障碍物的效率对于实际的机器人操作也是一个挑战。
End-to-end Motion Planning
This section introduces the close-loop methods where the grasp points are not given, as shown in Fig. 3. And typical functional flow chart of end-to-end motion planning is illustrated in Fig. 35. These methods directly accomplish the grasp task after given an original RGB-D image by using reinforcement learning.
本节介绍了没有给出抓取点的闭环方法,如图3所示。端到端运动计划的典型功能流程图如图35所示。 这些方法在获得原始的RGB-D图像之后,通过强化学习直接完成抓取任务。

Reinforcement learning to grasp the object
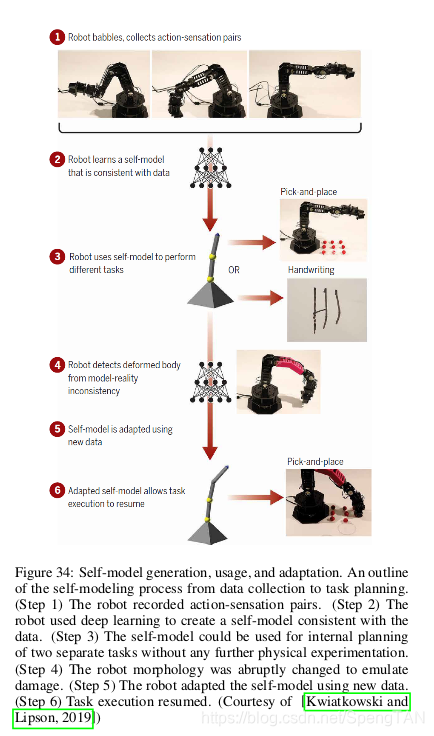
The reward function is defined relating to the state of grasping. Viereck et al. [Viereck et al., 2017] proposed an approach to learn a closed-loop controller for robotic grasping that dynamically guides the gripper to the object. Levine et al. [Levine et al., 2018] proposed a learning-based method for hand-eye coordination in robotic grasping from monocular images. They utilized the grasp attempts as the reward function, and trained a large convolutional neural network to predict the probability that task-space motion of the gripper will result in successful grasps. The architecture of the CNN grasp predictor is shown in Fig. 36. Kalashnikov et al. [Kalashnikov et al., 2018] utilized QT-Opt, a scalable self-supervised vision-based reinforcement learning framework, to perform closed-loop real-world grasping. Their method shows great scalability to unseen objects. Besides, it is able to automatically learn regrasping strategies, probe objects to find the most effective grasps, learn to reposition objects and perform other non-prehensile pre-grasp manipulations, and respond dynamically to disturbances and perturbations. Frederik et al. [Ebert et al., 2018] proposed a method on learning robotic skills from raw image observations by using autonomously collected experience. They devise a self-supervised algorithm for learning image registration to keep track of the objects of interest. Experimental results demonstrate that unlabeled data is successfully used to perform complex manipulation tasks. Fang et al. [Fang et al., 2018] proposed a task-oriented grasping network, which is a learning-based model for jointly predicting task-oriented grasps and subsequent manipulation actions given the visual inputs. Besides, they employed the self-supervised learning paradigm to allow the robot perform grasping and manipulation attempts with the training labels automatically generated.
奖励函数与抓握状态有关。 Viereck等。 [Viereck et al。,2017]提出了一种学习用于机器人抓取的闭环控制器的方法,该控制器动态地将抓取器引导到对象。莱文等。 [Levine et al。,2018]提出了一种基于学习的单眼图像机器人手眼协调方法。他们将抓握尝试作为奖励函数,并训练了一个大型卷积神经网络来预测抓爪的任务空间运动将导致成功抓握的可能性。 CNN掌握预测器的体系结构如图36所示。 [Kalashnikov et al。,2018]利用QT-Opt(一种可扩展的基于自我监督的基于视觉的强化学习框架)来执行闭环的现实世界抓取。他们的方法对看不见的对象显示出极大的可伸缩性。此外,它能够自动学习重新抓握策略,探测对象以找到最有效的抓握,学习重新放置对象并执行其他非预紧式预抓握操作以及对干扰和扰动进行动态响应。 Frederik等。 [Ebert et al。,2018]提出了一种通过使用自主收集的经验从原始图像观察中学习机器人技能的方法。他们设计了一种自我监督算法来学习图像配准,以跟踪感兴趣的对象。实验结果表明,未标记的数据已成功用于执行复杂的操作任务。方等。 [Fang等人,2018]提出了一种面向任务的抓握网络,这是一种基于学习的模型,用于在预测视觉输入的情况下共同预测面向任务的抓握和随后的操纵动作。此外,他们采用了自我监督的学习范式,以允许机器人执行抓握和操纵尝试,并自动生成训练标签。
Methods considering obstacles
The above mentioned methods assume that no obstacles exist on the path between the robotic hand and the grasp positions on target object. There also exist some methods which learn to push the obstacles away and grasp the target object in a closed-loop manner. Zeng et al. [Zeng et al., 2018a] proposed a model-free deep reinforcement learning method to discover and learn the synergies between pushing and grasping. Their method involves two convolutional networks that map from visual observations to actions. The two networks are trained jointly in a Q-learning framework and are entirely self-supervised by trial and error, where rewards are provided from successful grasps. With picking experiments in both simulation and real-word scenarios, their system quickly learns complex behaviors aiming challenging clutter cases and achieves better grasping success rates and picking efficiencies.
上述方法假定机器人手与目标物体的抓握位置之间的路径上没有障碍物。 还存在一些学习以闭环方式推开障碍物并抓住目标物体的方法。 Zeng等。 [Zeng et al。,2018a]提出了一种无模型的深度强化学习方法,以发现和学习推推和抓握之间的协同作用。 他们的方法涉及两个从目视观察到动作映射的卷积网络。 这两个网络在Q学习框架中进行了联合培训,并且完全通过试错法进行自我监督,而尝试和错误则可以从成功的掌握中获得回报。 通过在模拟和真实单词场景中进行拣选实验,他们的系统可以快速地学习针对具有挑战性的混乱情况的复杂行为,并更好地把握成功率和拣选效率。
Challenges
The first challenge lies in that the data generated by simulation show limited efficiency, although there have been domain adaption methods [Bousmalis et al., 2018a] proposed to improve efficiency of deep robotic grasping. Meanwhile, it remains challenging on avoiding obstacles when trying to grasp the object. Especially when the structure of the robot arm should be considered, it is difficult to define the mathematical grasp model according to different tasks.
第一个挑战在于,尽管已经提出了领域自适应方法[Bousmalis et al。,2018a],以提高深度机器人的抓握效率,但是通过仿真生成的数据效率有限。 同时,在试图抓住物体时如何避免障碍仍然具有挑战性。 特别是在考虑机械臂的结构时,很难根据不同的任务来定义数学上的抓握模型。














03-08
 4634
4634
4634
09-30
411
411
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









