







深度学习理论与实践编程练习(Course 03)
命名格式:按照课程网站中的课后作业要求
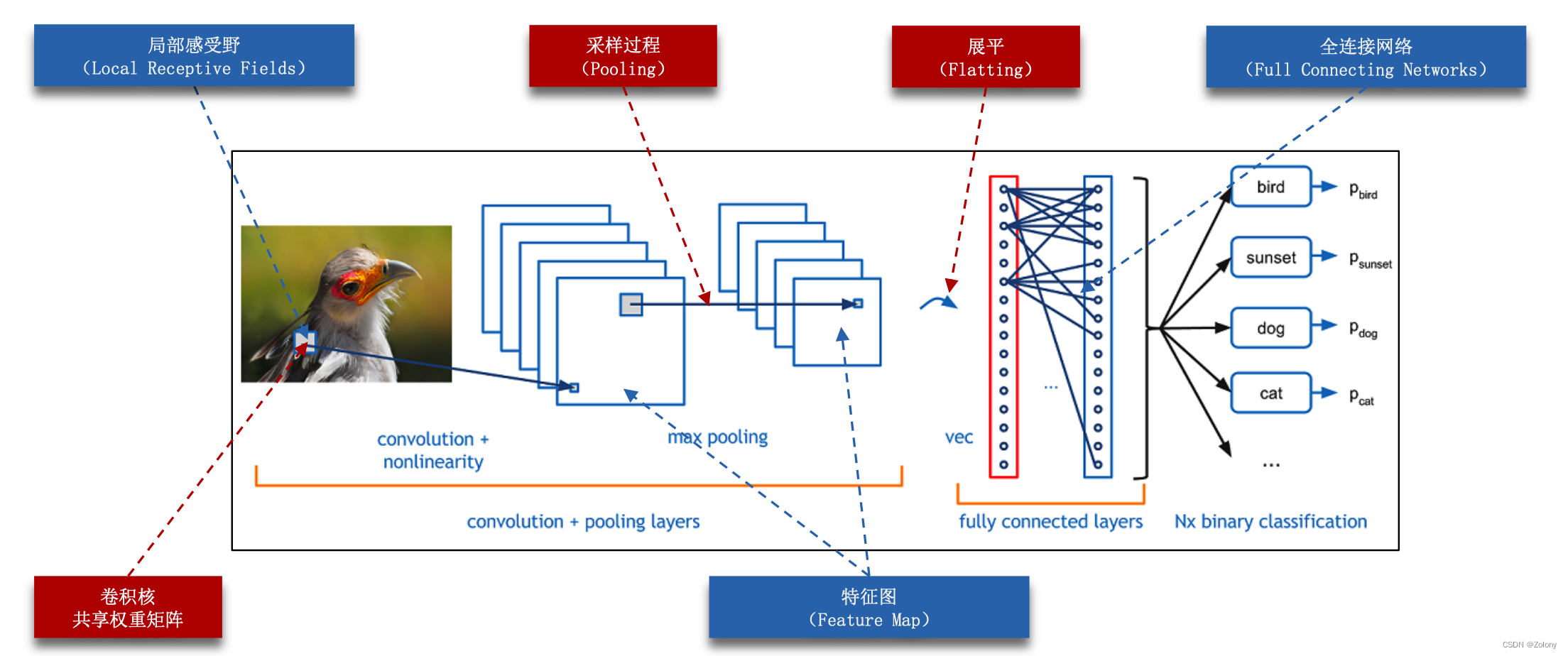
1. 根据Course03课程中对卷积神经网络的讲解,将缺失的全连接神经网络中代码块补全,并完成一次训练
[1] img2col 函数补全,通过补全函数,了解其实际含义
[2] Conv类中的前向过程
[3] Conv类中后向过程的 权重更新与误差反向传播
[4] Pool函数中的最大位置mask的计算过程
2. 修改卷积和池化的总操作数,观察对结果的影响
[1] 卷积后面跟随卷积层然后再接池化层,或者是用多个卷积池化操作的串联,观察对结果的影响。
[2] 修改的时候可以增加conv3和pool3实例,也可以修改卷积核的大小和卷积核的个数。
# numpy 测试
import numpy as np
a = np.array([[[1,2,3],[22,33,44],[333,444,555]],[[222,333,444],[11,22,33],[2,1,3]]])
print(np.repeat(a,2,axis=2))
print()
print(np.repeat(a,2,axis=0))
print()
print(np.repeat(a,2,axis=1))
# print(a.shape)
# print(a.reshape(2,3,3,1))
# print([i for i in range(1,1000,12)])
#print(a.reshape(-1,3))
[[[ 1 1 2 2 3 3]
[ 22 22 33 33 44 44]
[333 333 444 444 555 555]]
[[222 222 333 333 444 444]
[ 11 11 22 22 33 33]
[ 2 2 1 1 3 3]]]
[[[ 1 2 3]
[ 22 33 44]
[333 444 555]]
[[ 1 2 3]
[ 22 33 44]
[333 444 555]]
[[222 333 444]
[ 11 22 33]
[ 2 1 3]]
[[222 333 444]
[ 11 22 33]
[ 2 1 3]]]
[[[ 1 2 3]
[ 1 2 3]
[ 22 33 44]
[ 22 33 44]
[333 444 555]
[333 444 555]]
[[222 333 444]
[222 333 444]
[ 11 22 33]
[ 11 22 33]
[ 2 1 3]
[ 2 1 3]]]
## 引入python包,没有安装的请按照抛出的error通过conda来安装直至成功
import numpy as np
import torchvision
np.set_printoptions(threshold=np.inf)
def onehot(targets, num):
"""将数字的label转换成One-Hot的形式"""
# num为数量,targets[num]保存结果数字,返回result为num*10的数组,格式为result[num][target[num]]为1
result = np.zeros((num, 10))
for i in range(num):
result[i][targets[i]] = 1
return result
def img2col(x, ksize, step):
"""
将图像中所有需要卷积的地方转化成矩阵,方便卷积加速
:param x: 图像
:param ksize: 卷积大小
:param step: 步长
:return: 二维矩阵,每一行是所有深度上待卷积部分的一维形式
"""
# [width,height,channel] 宽,长,深度
wx, hx, cx = x.shape
# 返回的特征图尺寸
feature_w = (wx - ksize) // step + 1
image_col = np.zeros((feature_w * feature_w, ksize * ksize * cx))
num = 0
## 补全代码,补充image_col具体数值 ##
for i in range(feature_w):
for j in range(feature_w):
# reashape(-1)转换成行向量.
image_col[num] = x[i * step:i * step + ksize, j * step:j * step + ksize, :].reshape(-1)
num += 1
return image_col
## Relu 函数(激活函数)
class Relu(object):
def forward(self, x):
self.x = x
# np.maximun用于组个比较数组的大小取最大值
return np.maximum(x, 0)
def backward(self, delta):
delta[self.x < 0] = 0
return delta
## Softmax 函数(算最后的概率)
class Softmax(object):
def cal_loss(self, predict, label):
batchsize, classes = predict.shape
self.predict(predict)
loss = 0
delta = np.zeros(predict.shape)
for i in range(batchsize):
delta[i] = self.softmax[i] - label[i]
loss -= np.sum(np.log(self.softmax[i]) * label[i])
loss /= batchsize
return loss, delta
def predict(self, predict):
batchsize, classes = predict.shape
self.softmax = np.zeros(predict.shape)
for i in range(batchsize):
predict_tmp = predict[i] - np.max(predict[i])
predict_tmp = np.exp(predict_tmp)
self.softmax[i] = predict_tmp / np.sum(predict_tmp)
return self.softmax
dataset_path = "./datasets/mnist"
train_data = torchvision.datasets.MNIST(root=dataset_path, train=True, download=False)
# train=True代表加载train数据集,false代表加载test数据集,download=False代表不用下载原始数据集
train_data.data = train_data.data.numpy() # [60000,28,28] 这里加载的train数据集有60000个,后面test数据集有10000个
print(train_data.data.shape)
train_data.targets = train_data.targets.numpy() # [60000]
train_data.data = train_data.data.reshape(60000, 28, 28, 1) / 255. # 输入向量处理
print(train_data.data.shape)
train_data.targets = onehot(train_data.targets, 60000) # 标签one-hot处理 (60000, 10)
(60000, 28, 28)
(60000, 28, 28, 1)
## 全连接层
class Linear(object):
def __init__(self, inChannel, outChannel):
scale = np.sqrt(inChannel / 2)
# random.standard_normal标准正态分布(0,1),scale为缩小的倍数
self.W = np.random.standard_normal((inChannel, outChannel)) / scale
self.b = np.random.standard_normal(outChannel) / scale
self.W_gradient = np.zeros((inChannel, outChannel))
self.b_gradient = np.zeros(outChannel)
def forward(self, x):
"""前向过程"""
## 补全代码 ##
self.x = x
return np.dot(self.x, self.W) + self.b
def backward(self, delta, learning_rate):
"""反向过程"""
## 梯度计算
batch_size = self.x.shape[0]
## 补全代码 ##
self.W_gradient = np.dot(self.x.T, delta) / batch_size
# 列向量求和
self.b_gradient = np.sum(delta, axis=0) / batch_size
delta_backward = np.dot(delta, self.W.T)
## 反向传播
self.W -= self.W_gradient * learning_rate
self.b -= self.b_gradient * learning_rate
return delta_backward
## conv
class Conv(object):
def __init__(self, kernel_shape, step=1, pad=0):
# [w, h, d]
width, height, in_channel, out_channel = kernel_shape
self.step = step
self.pad = pad # 此处为0,默认不padding padding作用:维持feature map大小和image原图一样
# scale 方差缩放比例,???
scale = np.sqrt(3 * in_channel * width * height / out_channel)
self.k = np.random.standard_normal(kernel_shape) / scale
self.b = np.random.standard_normal(out_channel) / scale
self.k_gradient = np.zeros(kernel_shape)
self.b_gradient = np.zeros(out_channel)
def forward(self, x):
self.x = x
if self.pad != 0:# 如果不为零时,进行padding
self.x = np.pad(self.x, ((0, 0), (self.pad, self.pad), (self.pad, self.pad), (0, 0)), 'constant')
bx, wx, hx, cx =self.x.shape # 第一次为[batch, 28, 28, 1]
# kernel的宽、高、通道数、个数nk
wk, hk, ck, nk = self.k.shape #[wk,hk, inchannel, outchannel]
feature_w = (wx - wk) // self.step + 1 # 返回的特征图尺寸
feature = np.zeros((bx, feature_w, feature_w, nk)) # bx个样本,每个样本nk个为feature_w x feature_w feature map
self.image_col = []
# kernal也进行了reshape,便于卷积加速,只保留通道维度,是个二维的矩阵
kernel = self.k.reshape(-1, nk) # [wk, hk, inchannel, outchannel]->[ , nk==outchannel]
# nk为输出的feature map个数,此时kernal为(wk*hk*ck)*nk
## 补全代码 ##
# bx为通道数
for i in range(bx): # 遍历所有batch
image_col = img2col(self.x[i], wk, self.step) # 返回num(视野个数)*(wk*hk*cx)(通道)的数组
feature[i] = (np.dot(image_col, kernel) + self.b).reshape(feature_w, feature_w, nk)
self.image_col.append(image_col)
return feature
def backward(self, delta, learning_rate):
bx, wx, hx, cx = self.x.shape # batch,14,14,inchannel
#bx个数wx,bx宽高,cx通道
wk, hk, ck, nk = self.k.shape # 5,5,inChannel,outChannel
bd, wd, hd, cd = delta.shape # batch,10,10,outChannel
# 计算self.k_gradient,self.b_gradient
# 参数更新过程
## 补全代码 ##
delta_col = delta.reshape(bd, -1, cd)
for i in range(bx):
self.k_gradient += np.dot(self.image_col[i].T, delta_col[i]).reshape(self.k.shape)
self.k_gradient /= bx
self.b_gradient += np.sum(delta_col, axis=(0,1))
self.b_gradient /= bx
# 计算delta_backward
# 误差的反向传递
delta_backward = np.zeros(self.x.shape)
# numpy矩阵(对应kernal)旋转180度
## 补全代码 ##
k_180 = np.rot90(self.k, 2, (0,1))
k_180 = k_180.swapaxes(2,3)
k_180_col = k_180.reshape(-1, ck)
if hd - hk + 1 != hx:
# 反向传播的时候,如果delta反向传播到l层和l层的image大小不一样,则通过padding补全边框的0从而实现size一致
pad = (hx - hd + hk - 1) // 2
# np.pad(delta,(delta的所有维度需要padding的前后行数)),比如下面表示二三维度前后需要padding个一个pad,constant为填充的模式
pad_delta = np.pad(delta, ((0, 0), (pad, pad), (pad, pad), (0, 0)), 'constant')
else:
pad_delta = delta
for i in range(bx):
pad_delta_col = img2col(pad_delta[i], wk, self.step)
delta_backward[i] = np.dot(pad_delta_col, k_180_col).reshape(wx, hx, ck)
# 反向传播
self.k -= self.k_gradient * learning_rate
self.b -= self.b_gradient * learning_rate
return delta_backward
## Max Pooling层
class Pool(object):
def forward(self, x):
b, w, h, c = x.shape
feature_w = w // 2
feature = np.zeros((b, feature_w, feature_w, c))
self.feature_mask = np.zeros((b, w, h, c)) # 记录最大池化时最大值的位置信息用于反向传播
for bi in range(b):
for ci in range(c):
for i in range(feature_w):
for j in range(feature_w):
## 补全代码
feature[bi, i, j, ci] = np.max(x[bi, i*2:i*2+2, j*2:j*2+2, ci])
index = np.argmax(x[bi, i * 2:i * 2 + 2, j * 2:j * 2 + 2, ci])
# index 返回 0~3
self.feature_mask[bi, i * 2 + index // 2, j * 2 + index % 2, ci] = 1
return feature
def backward(self, delta):
# np.reapeat(x, num, axis=0/1) 没有axis默认合并成一维数组,有的话则在对应唯独num的轴向上重复num次
# delta repeat的axis为1和2分别是宽和高,axis=0为bx样本个数
# np.dot为矩阵相乘,np.array直接*表示的是对应元素分别相乘!!!!
# 下面语句作用为讲backward中的不是原来pool池化的点的delta设置为零(因为其在前向中没有起作用,因此在误差反向传播时误差应该为零)
return np.repeat(np.repeat(delta, 2, axis=1), 2, axis=2) * self.feature_mask
def train(batch=32, lr=0.01, epochs=10):
# Mnist手写数字集
dataset_path = "./datasets/mnist"
train_data = torchvision.datasets.MNIST(root=dataset_path, train=True, download=False)
train_data.data = train_data.data.numpy() # [60000,28,28]
train_data.targets = train_data.targets.numpy() # [60000]
train_data.data = train_data.data.reshape(60000, 28, 28, 1) / 255.
# 输入向量处理 /255归一化处理, reshape成(60000,28,28,1)目的使得访问train_data.data为[i,j,k]为一个np.array
train_data.targets = onehot(train_data.targets, 60000) # 标签one-hot处理 返回(60000, 10)
# [28,28] 卷积 6x[5,5] -> 6x[24,24]
conv1 = Conv(kernel_shape=(5, 5, 1, 6)) # width, height, in_channel, out_channel
relu1 = Relu()
# pool1 : 6x[24,24] -> 6x[12,12]
pool1 = Pool()
# 6x[12,12] 卷积 16x(6x[12,12]) -> 16x[8,8]
conv2 = Conv(kernel_shape=(5, 5, 6, 16)) # 8x8x16
relu2 = Relu()
# pool2 : 16x[8,8] -> 16x[4,4]
pool2 = Pool()
# 在这里可以尝试增加网络的深度,再实例化conv3和pool3,记得后面的前向传播过程
# 和反向传播过程也要有对应的过程
nn = Linear(256, 10) # inchannel outchannel
softmax = Softmax()
for epoch in range(epochs):
for i in range(0, 60000, batch):
# 60000中每隔batch取一组数据
X = train_data.data[i:i + batch] #[batch, 28, 28, 1]
Y = train_data.targets[i:i + batch]#[batch, 10]
# 前向传播过程
predict = conv1.forward(X)
predict = relu1.forward(predict)
predict = pool1.forward(predict)
predict = conv2.forward(predict)
predict = relu2.forward(predict)
predict = pool2.forward(predict)
predict = predict.reshape(batch, -1)
predict = nn.forward(predict)
# 误差计算
loss, delta = softmax.cal_loss(predict, Y)
# 反向传播过程
delta = nn.backward(delta, lr)
delta = delta.reshape(batch, 4, 4, 16)
delta = pool2.backward(delta)
delta = relu2.backward(delta)
delta = conv2.backward(delta, lr)
delta = pool1.backward(delta)
delta = relu1.backward(delta)
conv1.backward(delta, lr)
print("Epoch-{}-{:05d}".format(str(epoch), i), ":", "loss:{:.4f}".format(loss))
lr *= 0.95 ** (epoch + 1)
np.savez("simple_cnn_model.npz", k1=conv1.k, b1=conv1.b, k2=conv2.k, b2=conv2.b, w3=nn.W, b3=nn.b)
def eval():
model = np.load("simple_cnn_model.npz")
dataset_path = "./datasets/mnist"
test_data = torchvision.datasets.MNIST(root=dataset_path, train=False)
test_data.data = test_data.data.numpy() # [10000,28,28]
test_data.targets = test_data.targets.numpy() # [10000]
test_data.data = test_data.data.reshape(10000, 28, 28, 1) / 255.
conv1 = Conv(kernel_shape=(5, 5, 1, 6)) # 24x24x6
relu1 = Relu()
pool1 = Pool() # 12x12x6
conv2 = Conv(kernel_shape=(5, 5, 6, 16)) # 8x8x16
relu2 = Relu()
pool2 = Pool() # 4x4x16
nn = Linear(256, 10)
softmax = Softmax()
conv1.k = model["k1"]
conv1.b = model["b1"]
conv2.k = model["k2"]
conv2.b = model["b2"]
nn.W = model["w3"]
nn.n = model["b3"]
num = 0
for i in range(10000):
X = test_data.data[i]
X = X[np.newaxis, :]
Y = test_data.targets[i]
predict = conv1.forward(X) #返回[bx*feature_w*feature_W*ck]
predict = relu1.forward(predict) # relu激活函数
predict = pool1.forward(predict)
predict = conv2.forward(predict)
predict = relu2.forward(predict)
predict = pool2.forward(predict)
predict = predict.reshape(1, -1)
predict = nn.forward(predict)
predict = softmax.predict(predict)
if np.argmax(predict) == Y:
num += 1
print("TEST-ACC: ", num / 10000 * 100, "%")
eval()
train()















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









