






Python程序设计基础(微课版)林子雨主编
第一章Python语言概述
计算机语言
1.机器语言
2.汇编语言
3.高级语言
1.1.2为什么选择pyhton?
1)入门容易
2)功能强大
3)应用领域广泛
Python简介
1.2.1python简介
python:解释性高级语言
设计哲学:“优雅、快捷、明确、简单”
优点:语言简单、代码简洁(量少)、开源免费、面向对象、跨平台、强大的生态系统(功能强大)。
缺点:速度慢、代码不能加密、2.0和3.0不兼容。
1.2.3python应用
1.数据科学(大数据、数据可视化、数据分析)
2.人工智能(第三方库实现)
3.网站开发(django…)
4.系统管理
5.网络爬虫(Scrapy等)
1.2.4python版本
1.2.0和3.0版本区别:print()函数、除法运算3.0为浮点数,2.0为整数、3.0默认utf-8,2.0为ascii、取消xrange()函数改为range()函数。
编程重在对编程事项的理解和经验的积累,语言不同但思想是共通的。
搭建python环境
bing搜索python,或者点击这里下载适合你的操作系统的版本,安装过程略。
你可以使用更方便的pychram软件或者使用官方自带Idle都可以,如果你想下载使用pychram,请点击这里,安装过程略。
python规范
注释:
单行 #
多行 ‘’’ ‘’’
也可以"“” “”" (三个双引号)
代码缩进:
python使用代码缩进和冒号来区分代码之间的层次
第二章基础语法知识
关键字和标识符
2.1.1关键字和标识符
多写就行
2.1.2标识符
命名规则:
第一个字符不能是数字,无长度限制、不能是关键字、区分大小写、不能包含空格,@,%,$等特殊字符、避免开头和结尾都使用下划线,因为python采用这种方式定义了大量的关键字。
变量
2.2变量:在程序运行的过程中可以被改变的量
创建一个整型变量并赋值: num = 37
也可以使用中文变量名(极其不推荐)
id()函数可以用来返回变量所指值的内存地址。
>>>x = 5
>>>id(x)
>>>140710509405096
>>>y = x
>>>id(y)
>>>140710509405096
以上代码可以看出y的地址和x是一致的,说明python采用的是基于值的内存管理方式。
如果两个不同的变量指向了同一个值,那么这两个变量指向的也是同一块内存地址。
如果修改了其中一个变量的值的话,另一个变量不会受到影响,值不会变,地址不会变。
python拥有自动内存回收管理功能。
python是一种动态类型语言,变量的类型是可以随时发生变化的。
基本数据类型
基本数据类型:
2.3.1数字
1.整数
2.浮点数
3.布尔类型(空对象、值为0的任何数字或者None都是False)
4.复数:a+bj或complex(a,b)表示
2.3.2字符串
它是连续的字符序列,一般使用单引、双引、三引(‘’’ ‘’'或"“” “”"),三引号内的字符序列可以分布在连续的多行。
转义字符:\n、\t、'、\r、\、"
2.3.3数据类型转换
python提供了一些常用的数据类型转换函数:
int(x) 把x转换为整形
float(x)...
str(x)...
chr(x) 将整数x转换成一个字符
ord(x) 将一个字符x转换成对应的整数值
基本输入和输出
2.4.1input()输入
示例:x = input(“提示文字”)
注意:python3.x中,无论输入的是数字还是字符串,input()默认返回字符串。
想要接受数值:x = int(input(“提示文字”))
2.4.2print()输出
1.
print()函数是默认换行的,想要不换行你可以:
print(“自强不息”,“end=”)即可
你也可以输出到指定文件夹:
>>>fp = open(r'd:\test.txt','a+')
>>>print("为之则易,不为则难",file=fp)
>>>fp.close()
2.使用%进行格式化输出
1)
%d 十进制
%o 八进制
%x 十六进制
例如:
>>> nHex = 0xff
>>> print("%d,%o,%x"%(nHex,nHex,nHex))输出多个
>>> print("%d"%nHex)输出单个
2)浮点数输出
1.%f 保留小数点6位有效数字,可指定(%.2f),即保留两位小数;
2.%e 保留小数点后6位有效数字,以指数形式输出,可指定(%.2e),即保留两位小数,使用科学计数法;
3.%g 如果有6位有效数字,则使用小数方式,否则使用科学计数法,如果是(%.2g),使用小数方式或科学计数法。
3)字符串的输出
%s 字符串输出
%10s 右对齐,占位符10位,不够补空格
%-10s 左对齐,站10位
%.2s 截取两位字符串
%10.2s截取两位,右对齐占10位
%-10.2s截取两位,左对齐占10位
3.也可以使用”f-字符串“进行格式化输出
print(f'{表达式}')
>>>name = "小i"
>>>age = 66
>>>print(f'姓名:{name},年龄:{age}')
4.使用format格式化输出
运算符和表达式
2.5.1算数
±*/% **(幂)、//(取整除)
2.5.2赋值
=、+=、-=、*=、/=、%=、**=、\\=
2.5.3比较
>、<、>=、<=、!=、==
2.5.4逻辑
and(逻辑与)
or(逻辑或)
not(逻辑非)相当于!(非)
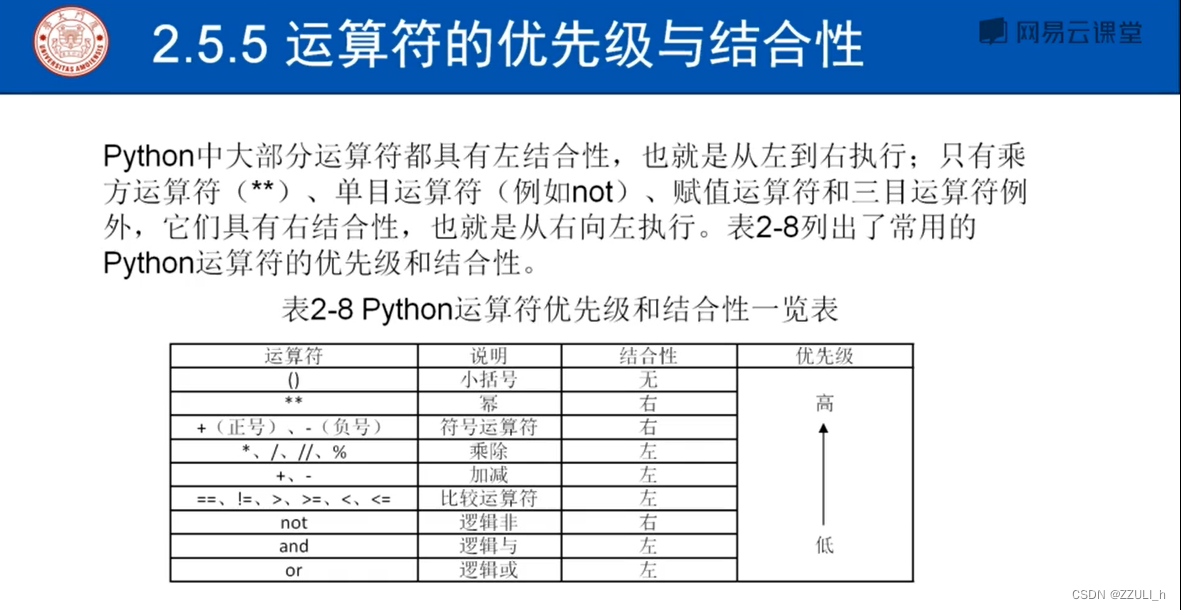
2.5.5优先级和结合性
第三章程序控制结构
程序控制结构
3.1程序控制结构
1.顺序结构
2.选择结构(分支结构)
3.循环结构
3.2选择语句
3.3循环语句
3.4跳转语句
3.5综合实例
选择语句
3.1程序控制结构
1.顺序结构
2.选择结构(分支结构)
3.循环结构
3.2选择语句
3.2.1 if语句
if表达式:
语句块
3.2.2 if…else语句
if 表达式1:
语句块1
else:
语句块2
3.2.3 if…elif…else语句
if 表达式1:
语句块1
elif 表达式2:
语句块2
elif 表达式3:
语句块3
...
else:
语句块n
3.2.4 if语句嵌套
上面三种if语句是可以相互嵌套的。
year = int(input("Enter Year:"))
if year % 4 == 0:
if year % 100 == 0:
if year % 400 ==0:
flag = 1
else:
flag = 0
else:
flag = 1
else:
flag = 0
if flag:
print("闰")
else:
print("平")
3.3循环语句
3.4跳转语句
3.5综合实例
循环语句
while循环语句:
#digit.py
prompt = "请输入一个数字:判断奇偶:"
prompt += "\n输入“exit”退出游戏"
exit = "exit"
content = ""
while content != exit:
content = input(prompt)
if content.isdigit():
number = int(content)
if(number % 2==0):
print("ou")
else:
print("ji")
elif content != exit:
print("请输入数值")
判断素数:
import math
m = int(input("enter number:"))
n = int(math.sqrt(m))
prime = 1
for i in range(2,n+1):
if(m%i==0):
prime = 0
if(prime):
print("yes")
else:
print("no")
9*9
for i in range(1,10):
for j in range(1,i+1):
print("%d*%d=%d"%(i,j,i*j),end = ' ')
print()
菱形:
#下面介绍如何打印一个菱形,奇数行
rows = int(input("Enter rows:"))
if rows %2 != 0: #判断是否是奇数行,是,进入循环
for i in range(0,rows//2+1): #控制上半部分,(控制行数)
for k in range(rows-i,0,-1):
print(' ',end='')
for j in range(0,i*2+1): #控制每行打印的内容,
print("*",end='')
print()#别忘了换行
for i in range(rows//2,0,-1):
for k in range(0,rows-i+1):
print(' ',end='')
for j in range(i*2-1,0,-1):
print("*",end='')
print()
跳转语句
3.4.1break语句
跳出离的最近的循环体内
3.4.2ocntinue语句
跳出当前循环,不想影响下次循环进行
3.4.3pass语句
表示空语句,不做任何事情,一般起到占位作用
比如else:后边,我以后想加一个其他功能,占时先不加,就可以用pass
综合实例
蒙特卡洛求圆周率
#边长为2的正方形以及半径为一的⚪
#PI = (单位圆的面积) / (正方形的面积) = N / n
from random import random
n = 1000*10000
N = 0
for i in range(1,n):
x,y=random(),random()
dis = pow(x**2+y**2,0.5)
if dis<=1:
N+=1
pi = 4*N/n
print(pi)
第四章序列
列表的创建和删除
4.1列表
['a','b'.'c','d',2012,2023]
4.1.1列表的创建和删除
1)使用赋值运算符直接创建列表
2)创建空列表
empty_list = []
使用len()获取长度返回0
3)创建数值列表
可以使用list()函数将可迭代对象数据转换为列表:比如range(),可迭代的字符串
num_list = list(range(1,10,2))
4.删除列表
使用del命令删除整个列表,如果列表对象所指向的值不在有其他对象指向,python将同时删除该值,这是因为Python的自动内存管理机制
访问列表元素
4.1.2列表访问元素
my_list = [10, 20, 30, 40, 50]
# 访问第一个元素(下标为0)
first_element = my_list[0]
print(first_element) # 输出:10
# 访问第三个元素(下标为2)
third_element = my_list[2]
print(third_element) # 输出:30
您还可以使用负数的下标来从列表末尾开始访问元素,例如 -1 表示最后一个元素,-2 表示倒数第二个元素,以此类推。
# 访问最后一个元素
last_element = my_list[-1]
print(last_element) # 输出:50
# 访问倒数第二个元素
second_to_last_element = my_list[-2]
print(second_to_last_element) # 输出:40
#使用for-in可以实现对列表的便利
for element in my_list:
print(element)
增加、删除、修改列表元素
列表元素的添加:
1):append(x)
append() 方法用于在列表末尾添加新的对象
2): insert()
insert(i,x) 在数组中i位置之前插入一个值为x的新项。负值被视为相对于数组的末尾。
3): extend()
extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表),属于原地操作。
4): "+"运算符
可以使用“+”运算符来把元素添加到列表中。实例如下:
>>> num_list= [1,2,3]
>>> id(num_ list)
46818176
>>> num_list= num_ list + [4]
>>> num_list
[1,2, 3, 4]
>>> id(num_list)
47251392
可以看出,num_list在 添加新元素以后,内存地址发生了变化,这是因为, .
添加新元素时,创建了一个新的列表,并把原列表中的元素和新元素依次
复制到新列表的内存空间。当列表中的元素较多时,该操作速度会比较慢。
5): "*"运算符
Python提供了“*” 运算符来扩展列表对象。可以将列表与整数相乘,生成一个新列表,新列
表是原列表中元素的重复。具体实例如下:
>>> num_list = [1,2,3]
>>> other_list = num_ list
>>> id(num_list)
47170496
>>> id(other_list)
47 1 70496
>>> num_list = num_ list*3
>>> num_list
[1,2,3,1,2,3,1,2,3]
>>> other_list
[1,2,3]
>>> id(num_list)
50204480
>>> id(other_list)
47170496
2.列表元素的删除
1):使用del可以删除指定位置的元素
>>> del list[index]
2):使用pop()可删除列表末尾的元素
>>>list.pop()
3):使用remove()方法删除首次出现的指定元素,如果列表中不存在要删除的元素,则抛出异常:
>>>list.remove(element)
3.列表元素的修改
修改列表元素的操作较为简单,实例如下:
>>> books = ["hadoop","spark","flink"]
>>> books
['hadoop', 'spark', 'flink']
>>> books[2] = "storm'
>>> books
['hadoop',' spark', storm']
对列表进行统计计算
4.1.4对列表进行统计计算
1.获取指定元素出现的次数
count() 方法用于统计某个元素在列表中出现的次数。
返回元素在列表中出现的次数。
2.获取指定元素首次出现的下标
index(value,[star,[stop]]) 函数用于从列表中找出某个值第一个匹配项的索引位置。(star和stop为可选值)
该方法返回查找对象的索引位置,如果没有找到对象则抛出异常。
3.统计数值列表的元素和
Python提供了sum()函数用于统计数值列表(包括可迭代对象)中各个元素的和,语法格式如下:
sum(iterable, start=0)其中,aList表示要统计的列表,start表示统计结果是从哪个数开始累加,
如果没有指定,默认值为0。具体实例如下:
>>> score = [84,82,95,77,65]
>>> total = sum(score) # 从0开始累加
>>> print("总分数是: ",total)
总分数是: 403
>>> totalplus = sum(score,100) #从100开始 累加
>>> print("增加100分后的总分数是: ",totalplus)
增加100分后的总分数是: 503
对列表进行排序
4.1.5对列表进行排序
sort(key=None,reverse=False)
key时可以指定的排序依据,reverse默认为false(升序),可指定为True为降序排序
>>>list.sort()
补:random.shuffle(可变序列) ,打乱可变序列。 sort() 方法和 sorted() 函数都用于对可迭代对象(如列表)中的元素进行排序,但它们之间有一些关键的区别:
原地排序 vs. 创建新列表:
sort(): sort() 方法是列表的方法,它会原地修改列表,即在排序后,原始列表的顺序会改变,而不会创建一个新的列表。这可以节省内存,但会影响原始数据。
sorted(): sorted() 函数不会修改原始列表,而是返回一个新的已排序的列表,原始列表保持不变。这对于保留原始数据的完整性很有用。
返回值:
sort(): sort() 方法没有返回值或返回值为 None,因为它在原地修改了列表。
sorted(): sorted() 函数返回一个新的已排序列表,你可以将其存储在一个变量中或直接使用。
使用情境:
如果你想要在原始列表上进行排序,并且不需要保留原始顺序,可以使用 sort() 方法,因为它更具效率。
如果你想要保留原始列表的顺序,并且需要一个新的已排序列表,可以使用 sorted() 函数。
成员资格判断
4.1.6成员资格判断
需要判断列表中是否存在指定的值,可采用in、not in、count()、index()来判断
>>> my_list = [1, 2, 3, 4, 5]
>>> 2 in my_list
True
>>> 99 in my_list
False
not in 与之类似
count()方法看返回值是否为0
index()看是否会抛出ValueError异常
切片操作
4.1.7切片操作
切片操作是访问序列中元素的一种方法,切片操作不是列表特有的,Python
中的有序序列(如字符串、元组)都支持切片操作。切片的返回结果类型和
切片对象类型一致,返回的是切片对象的子序列,比如,对一个列表切片返
回一个列表,对一个字符串切片返回字符串。
通过切片操作可以生成一个新的列表(不会改变原列表),切片操作的语法
格式如下:
listname[start: end : step]
其中,listname表示列表名称; start是切片 起点的索引,如果不指定,默
认值为0; end是 切片终点的索引(但是切片结果不包括终点索引的值),
如果不指定,默认为列表的长度; step是步长,默认值是1 (也就是一个
一个依次遍历列表中的元素),当省略步长时,最后一个冒号也可以省略。
下面是一些切片操作的具体实例:
>>> num_ list = [13,54,38,93,28,74, 59,92,85,66]
>>> num_ list[1:3] #从索引1的位置开始取,取到索引3的位置 (不含索引3)
[54, 38]
>>> num_ list[:3] #从索引0的位置开始取,取到索引3的位置(不含索引3)
[13, 54, 38]
>>> num_ list[1:] #从索引1的位置开始取,取到列表尾部,步长为1
[54, 38, 93, 28, 74, 59, 92, 85, 66]
>>> num_ list[1:] #从索引1的位置开始取,取到列表尾部,步长为1
[54, 38, 93, 28, 74, 59, 92, 85, 66]
>>> num_ list[:] #从头取到尾,步长为1
[13, 54, 38, 93, 28, 74, 59, 92, 85, 66]
>>> num_ lst:] #从头取到尾,步长为1
[13, 54, 38, 93, 28, 74, 59, 92, 85, 66]
>>> num_ lst:-1] #从尾取到头,逆向获取列表元素
[66, 85, 92, 59, 74, 28, 93, 38, 54, 13]
>>> num_ lst::2] #从头取到尾,步长为2
[13, 38, 28, 59, 85]
>>> num_ list[2:6:2] #从索引2的位置开始取元素,取到索引6的位置(不含索引6)
[38, 28]
>>> num_ list[0:100:1] #从索引0的位置开始取元素,取到索引100的位置
[13, 54, 38, 93, 28, 74, 59, 92, 85, 66]
>>> num_ list[100:] #从索 引100的位置开始取元素,不存在元素
>>> num_ list[8:2:-2] #从 索引8的位置逆向取元素,取到索引2的位置(不含索引2)
[85, 59, 28]
>>> num_ list[3:-1] #从索 引3的位置取到倒数第1个元素(不包含倒数第1个元素)
[93, 28, 74, 59, 92, 85]
>>> num_ list[-2] #取出倒数第2个元素
>>> num_ list
#原列表没有发生变化
[13, 54, 38, 93, 28, 74, 59, 92, 85, 66]
可以使用del命令和切片操作相结合来删除列
>>> numlist = [1,2,3,4,5,6]
>>> del numlist[0:2]
>>> numlist
[3, 4, 5, 6]
列表推导式
4.1.8列表推导式
列表推导式的一般语法结构:
new_list = [expression for element in iterable if condition]
expression 是用于生成新列表中的元素的表达式。
element 是用于迭代可迭代对象中的元素的变量名。
iterable 是可迭代对象,例如列表、字符串、范围等。
condition 是可选的,用于筛选元素的条件,只有满足条件的元素才会包含在新列表中。
>>> squres = [x**3 for x in range(1,11)]
>>> squres
[1, 8, 27, 64, 125, 216, 343, 512, 729, 1000]
列表推导式也可以包含多重循环,允许你迭代多个可迭代对象并生成新的列表。
#生成一个包含所有可能的组合的列表
>>> colors = ['red', 'green', 'blue']
>>> sizes = ['small', 'medium', 'large']
>>> combinations = [(color, size) for color in colors for size in sizes]
>>> print(combinations)
[('red', 'small'), ('red', 'medium'), ('red', 'large'), ('green', 'small'), ('green', 'medium'), ('green', 'large'), ('blue', 'small'), ('blue', 'medium'), ('blue', 'large')]
还可以支持更多层循环…
在使用了多层for循环的列表推导式任然可以使用if条件:
>>> list1 = [1,2,3,4,5]
>>> list2 = [20,15,33,24,27,58,46]
>>> rs = [[x,y]for x in list1 for y in list2 if y%x==0]
>>> rs
[[1, 20], [1, 15], [1, 33], [1, 24], [1, 27], [1, 58], [1, 46], [2, 20], [2, 24], [2, 58], [2, 46], [3, 15], [3, 33],
二维列表
list2 = ["庐山","嵩山","黄山","泰山"]
list1 = []
for i in range(3):
list1.append([])
for j in list2:
list1[i].append(j)
print(list1)
#使用列表推导式创建二维列表
dim_list = [[i]*4 for i in list2]
print(dim_list)
元组
4.2元组
元组存放不修改的元素的
4.2.1创建元组
与列表不同的是,创建元组时要使用圆括号
>>> tuple1 = (1,2,3,4,5)
空元组
>>> tuple2 = ()
当元组内只有一个元素时,要在其后边一个逗号
>>> tuple3 = ("A",)
也可以使用tuple()函数和range()函数来生成数值元组,例如:
>>> tuple4 = tuple(range(1,10,2))
>>> tupe
(1,3,,5,7,9)
4.2.2访问元组
可以使用下标索引访问元组中的元素
Python中列表的切片操作和元组切片操作是一致的
for-in遍历也是可以的
4.2.3修改元组
想都不要想,禁止修改
但是可以连接的!
两个元组可直接使用"+"号连接
或者呢直接对元组进行重新赋值来改变元组的值
4.2.4删除元组
del tuplename
4.2.5元组推导式
(表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]) 仅是把列表推导式中的[]改成了()而已,用法完全相同。
补:next() 是 Python中迭代器(iterator)对象的魔术方法之一。它用于手动迭代一个可迭代对象的元素,一次一个元素,直到达到末尾。
>>> 元组名.__next__()
4.2.6元组的常内置函数
len(tuple):计算元组大小,即元组中的元素个数;
max(tuple):返回元组中的元素最大值;
min(tuple):返回元组中元素最小值;
tuple(seq):将序列转为元组
。
4.2.7元组与列表的区别
元组和列表都属于序列,二者的区别主要体现在以下几个方面:
(1)列表属于可变序列,可以随时修改或删除列表中的元素,比如使用
append()、extend()、 insert()向 列表添加元素,使用del、remove() 和pop()
删除列表中的元素。元组属于不可变序列,没有append()、extend()和
insert()等方法,不能修改其中的元素,也没有remove()和pop()方法,不能
从元组中删除元素,更无法对元组元素进行del操作。
(2)元组和列表都支持切片操作,但是,列表可以使用切片方式来修改其 中的元素,而元组则不支持使用切片方式来修改其中的元素。
(3)元组的访问和处理速度比列表快。如果只是对元素进行遍历,而不需
要对元素进行任何修改,那么一般建议使用元组而非列表。
(4)作为不可变序列,与整数、字符串一样,元组可以作为字典的键(唯一固定的),而 列表则不可以。
实际应用中,经常需要在列表和元组之间进行切换,具体方法如下:
1):tuple()接受一个列表作为参数,返回同样的元素的元组。
2):list()函数可以接受一个元组作为参数,返回同样的元素的列表。
在 Python 中,tuple() 函数和 list() 函数用于将其他可迭代对象(如列表、元组、字符串等)转换为元组和列表,分别返回新的元组和列表,而不会修改原始对象。这意味着原始元组或列表不会受到影响,仅仅是创建了一个新的副本。
4.2.8序列封包和序列解包
程序把多个值赋给一个变量时,python会自动将多个值封装成元组,这种被称为是“序列封包”
>>> values = 1,2,3
>>> values
(1,2,3)
>>> type(values)
<class'tuple'>
>>> values[0]
1
解包:
>>> a,b,c = 1,2,3
abc分别赋值了123
>>>a,b,c = range(3)
abc分别赋值了012
可以将元组的各个元素依次赋值给多个变量,实例如下:
>>> a_tuple = tuple(range(1, 10, 2))
>>> print(a_tuple)
(1,3, 5, 7, 9)
>>>a,b,c, d,e=a_tuple
>>> print(a,b,c,d,e)
13579
下面是一个关于列表的序列解包的实例:
>>>a_list=[1,2, 3]
>>> x,y,z= a_list
>>> print(x, y, z)
123
字典
4.3字典
1)字典的元素是键值对,键必须得是唯一的
2)不支持索引和切片,但可以通过“key”查“value”
3)字典是无序的
4)字典是可变的,并且可以任意嵌套
4.3.字典的创建和删除
创建一个字典:
变量名 = {"key":"value","key":"value"}
变量名 = {} #这是一个空字典
另外,键也可以是元组类型,因为元组类型是不可变类型。
此外,Python还提供了内置函数dict()来创建字典,实例如下:
>>> books = [('hadoop', 132), ('spark', 563), (flink', 211)]
>>> dict1 = dict(books)
>>> dict1
{'hadoop': 132, 'spark': 563, 'flink': 211}
>>> scores = ['计算机', 85], ['大数据', 88], ['Spark编程', 89]]
>>> dict2 = dict(scores)
>>> dict2
{'计算机': 85, '大数据': 88, 'Spark编程': 89}
>>> dict3 = dict(curriculum='计算机' ,grade=87) #通过指定参数创建字典
>>> dict3
{'curriculum': '计算机', 'grade': 87}
>>> keys = ["语文","数学","英语"]
>>> values = [67,91,78]
>>> dict4 = dict(zip(keys,values))
>>> dict4
{语文':67, '数学':91, '英语': 78}
>>> dict5= dict() #创建空字典
>>> dict5
{}
补:zip()函数用于将可迭代对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表,例如:
>>> x = [1,2,3]
>>> y = ['a','b',''c]
>>> rs = zip(x,y)
>>> rs
<zip object at 0x123456>
>>> list(rs)
[(1, 'a'),(2, 'b'), (3, 'c')]
删除字典
del dictname
clear()清空字典元素
dictname.clear()
4.3.2访问字典
自带内包含多个“键值对”,而键是字典的关键数据,因此对字典的操作都是基于键的,主要操作有:
通过键访问值、通过键添加键值对、通过键删除键值对、通过键修改键值对、通过键判断指定键值对是否存在。
和元组列表一样,通过键访问值时使用的也是方括号语法,只是此时在方括号中放的是键,不是索引,若指定键不存在,报keyerror异常
dictname[key]
Python推荐使用get()方法而不是[]获取指定键的值:
dictionary.get(key, default)
default为可选项,用于指定当键不存在的时候返回一个默认值,默认省略则为None(屏幕上不可见)
items()返回“键值对”dict_items对象,keys返回“键”dict_keys对象,“values”返回“值”dict_values对象。
这些方法返回的对象都支持迭代,可以使用循环或其他迭代工具来访问字典的键、值或键-值对。这使得在处理字典数据时非常方便。如果需要将它们转换为列表,你可以使用 list() 函数将它们包装成列表,例如 list(my_dict.items())、list(my_dict.keys()) 或 list(my_dict.values())。
这几个方法返回的都是可迭代对象,使用for-in循环可以遍历它们
使用pop方法可以删除指定键的键值对,返回被删除的键对应的值。
字典是可变序列,因此是可以添加、修改和删除操作的。
dictname[key] = value
当需要修改字典对象某个元素的值时,可以为该元素赋予新值,新值会替换旧值。
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
#修改 ‘age’ 键对应的值
my_dict['age'] = 31
#添加新的键-值对
my_dict['job'] = 'Engineer'
print(my_dict)
{'name': 'Alice', 'age': 31, 'city': 'New York', 'job': 'Engineer'}
删除某个键值对可以使用del
del dictname[key]
updata()的使用方法:
用一个字典所包含的键值对来更新已有的字典。在执行update()方法时,如果被更新的字典中己包含对应的键值对,那么原值会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。
在 Python 中,update() 方法用于将一个字典的键值对合并到另一个字典中。具体来说,update()
方法接受一个字典作为参数,并将该字典中的键值对添加到调用方法的字典中。如果有重复的键,它将用新字典中的值来覆盖原字典中的值。
dict1.update(dict2)
#dict1:要合并的目标字典。
#dict2:包含要添加到目标字典的键值对的字典
字典推导式:
{表达式 for 迭代变量 in 可迭代对象 [if 条件表达式]}
>>> word_list = ["Beijing","Henan","Shanghai"]
>>> id = (11,22,33,44)
>>> my_dict = {key:value for key,value in zip(id,word_list)}
>>> my_dict
{11: 'Beijing', 22: 'Henan', 33: 'Shanghai'}
如果想要交换键和值的位置
>>> old_dict = {'Beijing': 11, 'Henan': 22, 'Shanghai': 33}
>>> new_dict = {k:v for v,k in old_dict.items()}
>>> new_dict
{11: 'Beijing', 22: 'Henan', 33: 'Shanghai'}
当然了在此基础上还可以添加if条件,比如 if v>22,那就就只会输出{33:‘Shanghai’}
集合
4.4.1集合的创建和删除
集合(Set)是一个无序且元素不可变类型。使用{}括起来
setname = {}
且如果存在重复元素,python只会保留一个
集合推导式:
{expression for item in iterable if condition}
也可使使用set()函数将列表、元组、range()对象等其他可迭代对象转换为结合
setname = set(iteration)
创建空集合必须使用set()而不是{},因为{}表示的是一个空字典。
可以使用del setname来删除集合
4.4.2集合元素的添加与删除
使用add()方法向集合中添加元素,只能是字符串、数字、布尔类型、不能是列表、元组等可迭代对象,如果要添加的元素已存在,集合不会做任何操作。
pop()、remove()用来删除集合中的一个元素。
pop()删除集合中的任意一个元素。
remove() 方法用于从集合中删除指定的元素,而不是像 pop() 方法那样随机删除一个元素。你需要指定要删除的元素,如果元素存在于集合中,它将被删除;如果元素不存在,将引发 KeyError 异常。
使用clear()方法会清空集合中的所有元素。
4.4.3集合中的∪、∩、和-操作
并集:集合A中的所有元素和B中的所有元素结合,去掉重复的。使用 union() 方法或 | 运算符来获取两个集合的并集。并集包含两个集合中的所有元素,去重后的结果。
set1 = {1, 2, 3}
set2 = {3, 4, 5}
#使用 union() 方法
union_result = set1.union(set2)
#或者使用 | 运算符
union_result = set1 | set2
print(union_result) # 输出: {1, 2, 3, 4, 5}
交集:交集就是集合A和集合B中都有的元素。使用 intersection() 方法或 & 运算符来获取两个集合的交集。交集包含同时存在于两个集合中的元素。
set1 = {1, 2, 3}
set2 = {3, 4, 5}
#使用 intersection() 方法
intersection_result = set1.intersection(set2)
或者使用 & 运算符
intersection_result = set1 & set2
print(intersection_result) # 输出: {3}
差集:为了更好地理解差集,我的解释是这样的:
A集合差B集合,如果A集合中含有和B集合相同的元素,把相同的元素去掉,留下只有A集合中有但是B集合中没有的这是A差B。同理,B差A刚好相反。
使用 difference() 方法或 - 运算符来获取一个集合减去另一个集合的差集。差集包含只存在于第一个集合中的元素。
set1 = {1, 2, 3}
set2 = {3, 4, 5}
使用 difference() 方法
difference_result = set1.difference(set2)
或者使用 - 运算符
difference_result = set1 - set2
print(difference_result) # 输出: {1, 2}
第五章字符串
基本概念
5.1基本概念
isinstance() 是一个内置的Python函数,用于检查一个对象是否属于指定的类或类型,或者是否属于指定的类型元组。
isinstance(object, classinfo)
object 是要检查的对象。
classinfo 可以是一个类、类型或类型元组。
isinstance() 函数会返回一个布尔值,如果 object 是 classinfo 指定的类型之一,或者是 classinfo 类型元组中的一个,就返回 True;否则返回 False。
三单引号’'‘ ’‘’可以输出多行字符串字面量。
添加了""那就不换行了,没有添加还是会继续换行的 。
字符串的索引和切片
5.2.1字符串的索引
正向索引:0开始,步增1
反向索引:-1开始,步减1
字符串中,使用下标运算符"[]"来查询指定索引值对应的字符。
1)python中修改字符串都是通过字符串拼接的方法实现的。当然这种方法不是很实用:
过程以及代码如下:
(1)求出字符串的长度m;
(2)如果m<n,那么返回失败;
(3)取出索引值为0至n-1的字符串,记为leftString;
(4)取出索引值为n+ 1至m-1的字符串,记为rightString;
(5)把leftString、修改后的字符和rightString拼接为一个 新的字符串newString;
(6)输出newString。
代码:
def modify_string(input_string, n, replacement_character):
# 步骤 1:计算字符串的长度
m = len(input_string)
# 步骤 2:检查 m 是否小于 n
if m < n:
return "失败" # 步骤 3:如果 m < n,则返回失败
# 步骤 4:取出左右两部分子字符串
left_string = input_string[:n] # 索引值为 0 至 n-1 的子字符串
right_string = input_string[n+1:] # 索引值为 n+1 至 m-1 的子字符串
# 步骤 5:拼接新的字符串
new_string = left_string + replacement_character + right_string
# 步骤 6:输出新字符串
return new_string
测试示例
original_string = "Hello, World!"
n = 5
replacement_char = '*'
result = modify_string(original_string, n, replacement_char)
print(result) # 输出: "Hello*World!"
5.2.2字符串的切片
切片操作与其它序列的切片基本一致,但是如果输入了错误的索引值,那么系统会返回一个空字符串,而不是一个错误或则是异常,比如:开始索引 = 结束索引、开始索引 > 结束索引等。
2)如果m和n分别指的是字符串的开头和结尾,那么想要查询从第2个字符到字符串结尾的资字串:
str[1:]
想要查询开头到倒数第二个字符:str[:-2]
如果都不写的话那就是整个字符串:str[:]
>>> aString = 'string'
3)切片的第三种写法:str[m::n]
①:如果n为正,则查询方向为正向索引的方向。
aString[1::2]--> 'tig'
aString[-5::2]-->'tig'
②:如果n为负,则查询的方向为反向索引的方向。
aString[5::-2]-->'git'
aString[-1::-2]-->'git'
③如果不写n,则视为aString[m::1]。 例如,aString[3::]的值 为"ing'",,
aString[- 3:]的值也是"ing",它们分别是从索引值为3和为-3的字符开始,以正
向索引的方向取每个字符直至字符串结尾。
④如果n和m都不写,则视为aString[::1],即从字符串的开头开始取每一- -个字
符,显然结果就是字符串本身。特别地,如果n为0,则系统会返回一个错误。
字符串的拼接
5.3字符串拼接
+拼接
%拼接
若要重复输出一个字符若干次,如"*"8就会输出8个“” join函数:可以将一个列表或者可迭代对象拼接为一个字符串,广泛用于生成参数列表。它要求可迭代对象中的所有元素都必须是字符串类型,否则会引发TypeError。
sourceDict = {
"name":"谢坤眼",
"age":21,
"course":"深度学习"
}
list1 = [str(key) + "=" + str(value) for key,value in sourceDict.items()]
querystr = '&'.join(list1) //" "内可指定任意字符
print(querystr)
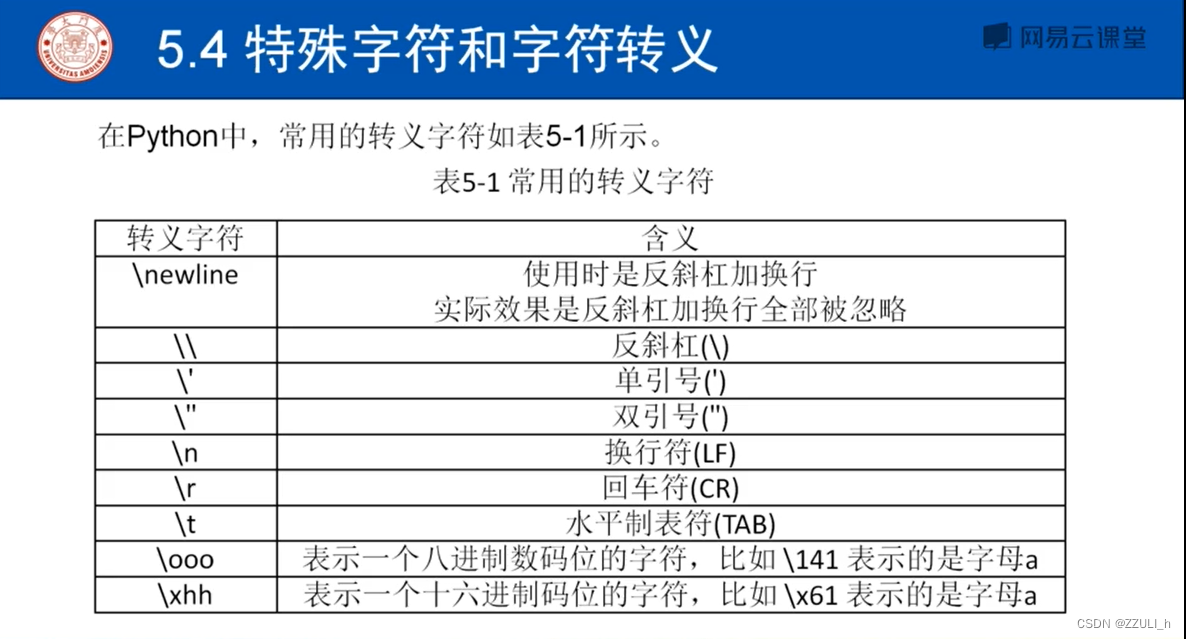
特殊字符和字符转义
原始字符串
5.5.1原始字符串
书写文件路径太多的"\"和"\\"会显得很乱,这时候加入先导符"r"("R"也可以),字符串的所有内容都不会被转义。
path = r"c:\desktop\test"
(1) 如果字面量只用到一种引号,显然只需要包裹时用另一种引号就可以;
(2)如果字面量同时用两种引号,那么可以在原始字符串中使用三连引号;
(3)如果字面量里同时出现两种三连引号,就只能放弃使用原始字符串,而改为使用普通的需要转义的字符串。
格式化字符串
5.5.2格式化字符串
格式规格迷你语言:
{参数编号:格式化规则}
参数如果写0,对应format函数第一个参数,1就是对应第二个参数。格式化规则的书写方法如下:
[对齐方式][符号显示规则][#][0][填充宽度][千分位分隔符][.<小数精度>][显示类型]
-
对齐方式:这是可选的,可以是 <(左对齐,默认)、>(右对齐)或 ^(居中对齐)。
-
符号显示规则:这也是可选的,可以是 +(显示正负号)、-(只显示负号)、空格(正数前加空格)或 0(用零填充)。
-
#:这是一个可选的标志,通常用于指定使用替代格式。
-
0:这也是一个可选的标志,表示用零填充。
-
填充宽度:这是一个整数,表示最终字符串的最小宽度。如果不足,将使用填充字符(通常为空格或零)来填充。
-
千分位分隔符:这是一个可选的标志,用 , 表示要在数字中插入千分位分隔符。
-
“.”:这是一个可选的标志,表示小数点。
-
小数精度:这是一个整数,表示要显示的小数位数。
9.显示类型:这是一个字符,表示要显示的数据类型,例如 d 表示整数,f 表示浮点数,s 表示字符串,等等。
输出不同进制的情况;
在格式化规则中,在符号显示规则后面的“#”,表示如果是以2进制显示数
字,则显示前导符“0b”,以8进制显示数字,则显示前导符“0o”,以16
进制显示数字,则显示前导符“0x”。如果不是上述情况,就没有任何效果。
具体实例如下:
>>> "{O:<#8b}{0:<#8o}{0: <#8d}{0: <#8x}{0:#8X}" .format(10)
'0b1010 0o12 10 0xa 0XA'占8位的空格已省略
使用格式化字符串也可以不用.format,使用更简便的写法"格式化字符串字面量",也可以称为"f-string",特点是在字符串前加"f"或"F"。使用过程中,将迷你语言的第一部分换成变量名即可。
>>> price = 10
>>> amount= 5
>>> f"价格: {price *amount.2f}"
'价格: 50.00'
字符串的编码
5.6字符串的编码
使用chr()函数将一个ascii码转换为其对应的数字
使用ord()函数进行反向转换
字节串字面量中的encode()和decode()方法
GBK、UTF-8、gb2312
ascii、Unicode…
常用操作
5.7常用操作
1)类型转换函数
int、long、float、complex、tuple、list、chr、ord、hex、unichr、oct。
2)表达式转换函数
eval() 是一个内置函数,用于执行包含有效Python表达式的字符串,并返回表达式的结果。这个函数的语法如下:
eval(expression, globals=None, locals=None)
expression 是一个包含Python表达式的字符串,可以是任何有效的Python表达式,例如数学运算、函数调用等。
globals 和 locals 是可选参数,用于指定全局和局部变量的命名空间。如果不提供这些参数,eval() 函数将在当前命名空间中执行表达式。
计算一个数学表达式
result = eval('2 + 3') # 结果将是 5
执行函数调用
x = 5
y = 10
result = eval('x + y') # 结果将是 15
#使用 globals 和 locals 参数指定命名空间
x = 5
y = 10
result = eval('x + y', {'x': x}, {'y': y}) # 结果将是 15
开发过程中慎用eval()
3)长度计算函数len()
>>> len(str)
3
4)大小写转换函数 lower和upper,非英文字母无效
5)查询函数find()
>>> "hello world".find("llo")
2
查询不到的话返回-1,而且还可以指定查询位置
str.find("要查询的",star,end)
需要注意的是,find() 方法只返回第一次出现的子字符串的索引,如果你想查找所有出现的子字符串,可以使用循环来遍历字符串并多次调用 find() 方法。如果你想从右侧开始查找,可以使用 rfind() 方法。
6)字符串分解函数split()
split() 函数是Python中的内置字符串方法,用于将一个字符串分割成子字符串,并将这些子字符串存储在一个列表中。
str.split(sep=None, maxsplit=-1)
sep 是分隔符,用于指定在哪些字符处进行分割,默认为 None,此时会使用空白字符(空格、制表符、换行符等)作为分隔符。
maxsplit 是最大分割次数,如果指定,函数将执行最多 maxsplit 次分割。设置为n就说明处理前n个分隔符,字符串会被分割为n+1段。
实例:
text = "apple,banana,orange"
#使用默认分隔符(空格)
result1 = text.split()
print(result1) # 输出: ['apple,banana,orange']
#使用逗号作为分隔符
result2 = text.split(',')
print(result2) # 输出: ['apple', 'banana', 'orange']
#使用分隔符并限制分割次数
result3 = text.split(',', maxsplit=1)
print(result3) # 输出: ['apple', 'banana,orange']
在这些示例中,我们使用了不同的分隔符对字符串进行分割,并使用了 maxsplit 参数来限制分割次数。
split() 方法返回一个列表,其中包含分割后的子字符串。如果没有找到分隔符,split() 方法会返回包含整个字符串的列表。
需要注意,split() 方法不会修改原始字符串,而是返回一个新的列表。
第六章函数
基本定义及调用
6.1普通函数
6.1.1基本定义及调用
定义函数规则:
①函数代码块形式上包括函数名部分和函数体部分
②函数名以def开头,后接函数标识符名称和(),冒号结尾
③圆括号内可定义多个或则不定义形参
④函数第一行语句可选择性添加函数说明
⑤函数体部分需要缩进
⑥return不写会默认返回None,函数碰到return就会结束执行。
函数调用:
函数名()
补:函数文档字符串"“” 说明 “”"
使用help(函数名)可以查看定义的函数说明
求s1~s2之间所有整数和
def sum_seq(s1,s2):
sum = 0
for i in range(s1,s2+1):
sum+=i
return sum
print(sum_seq(1,9))
文档字符串、函数标准和return语句
6.1.3函数标注
在Python中,你可以使用函数标注(Function Annotations)来提供关于函数参数和返回值的元数据信息。这些标注并不会影响函数的运行,但可以提供有关函数如何使用的信息。
def add(a: int, b: int) -> int:
"""这是一个加法函数,将两个整数相加并返回结果。"""
return a + b
a: int 和 b: int 是参数的标注,它们表示参数 a 和 b 应该是整数类型。
-> int 是返回值的标注,它表示这个函数将返回一个整数。 请注意,这些标注并不会强制要求参数和返回值的类型,它们只是提供了信息,供开发者和工具使用。例如,你仍然可以传递其他类型的参数给这个函数,但标注有助于代码的可读性和可维护性。
要访问函数标注,可以使用函数的 annotations 属性,如下所示:
print(add.__annotations__)
#输出:{'a': <class 'int'>, 'b': <class 'int'>, 'return': <class 'int'>}
6.1.4return语句
不写默认返回None
变量作用域
6.1.5变量作用域
局部作用域(Local Scope)和全局作用域(Global Scope),以及在函数内部定义的嵌套作用域(Enclosing Scope)和内置作用域(Built-in Scope)。
1.局部作用域:
函数内定义,函数内部访问,外部无法访问。仅在函数生命周期内可用,函数执行结束,变量销毁。
def my_function():
x = 10 # x是局部变量
print(x)
my_function()
print(x) # 这里会引发NameError,因为x不在全局作用域中
2.全局作用域:
全局作用域是在模块级别定义的,通常在整个模块中都可见。
全局变量可以在模块中的任何地方访问,包括函数内部。
如果要在函数内部修改全局变量,需要使用global关键字。
x = 10 # x是全局变量
def my_function():
global x # 使用global关键字让函数知道我们要修改的是全局变量x
x = 20
print(x)
my_function()
print(x) # 输出为20,因为函数内部修改了全局变量x
3.函数内部定义的嵌套作用域:
嵌套作用域是指在一个函数内部定义了另一个函数,内部函数可以访问外部函数的变量,但不可以修改外部函数的局部变量。
def outer_function():
x = 10 # x是外部函数的局部变量
def inner_function():
print(x) # 内部函数可以访问外部函数的变量x
inner_function()
outer_function()
函数的递归调用
匿名函数
在Python中,匿名函数也被称为lambda函数。匿名函数是一种小型、临时的函数,通常用于简单的操作,而不需要定义完整的函数。lambda函数使用lambda关键字创建,并可以在一行内定义。它们通常用于函数式编程和在需要函数作为参数的情况下使用。
基本语法如下:
lambda arguments: expression
arguments 是函数的参数列表。
expression 是一个表达式,定义了函数的返回值。
fn lambda a,b:b**2-a**2
x,y=5,4
print("{1}*{1}-{0}*{0}={2}".format(x,y,fn(x,y)))
print()
参数传递
6.3参数传递
不可变对象: 不可变对象是指其内容不可被修改的对象。
常见的不可变对象包括整数(int)、浮点数(float)、字符串(str)、元组(tuple)等。
不可变对象在传递给函数时,函数接收的是对象的副本,而不是原对象本身。
def modify_immutable(x):
x = x + 1
print("Inside function: x =", x)
num = 10
modify_immutable(num)
print("Outside function: num =", num)
#输出
Inside function: x = 11
Outside function: num = 10
在上述示例中,虽然函数内部对 x 进行了修改,但原始的 num 变量并没有被改变,因为整数是不可变对象。
可变对象: 可变对象是指其内容可以被修改的对象。 常见的可变对象包括列表(list)、字典(dict)、集合(set)等。
可变对象在传递给函数时,函数接收的是对原始对象的引用,而不是对象的副本。
def modify_mutable(lst):
lst.append(4)
print("Inside function: lst =", lst)
my_list = [1, 2, 3]
modify_mutable(my_list)
print("Outside function: my_list =", my_list)
#输出
Inside function: lst = [1, 2, 3, 4]
Outside function: my_list = [1, 2, 3, 4]
在上述示例中,函数内部对 lst 进行了修改,原始的 my_list 也被改变,因为列表是可变对象。
总结:
不可变对象在函数中的修改不会影响原始对象,因为函数接收的是对象的副本。
可变对象在函数中的修改会影响原始对象,因为函数接收的是对原始对象的引用。
了解对象的可变性在编写函数和处理函数参数时非常重要,因为它影响函数对传递对象的影响。
参数类型
位置参数
位置参数是最常见的参数类型,它们按照函数定义中的顺序传递给函数。
位置参数的值是根据它们在函数调用中的位置来确定的。
def example_function(arg1, arg2):
# arg1 和 arg2 是位置参数
pass
example_function(1, 2) # 1 传递给 arg1,2 传递给 arg2
关键字参数
关键字参数是通过参数名来传递的,与参数的位置无关。
使用关键字参数可以提高函数调用的可读性。
example_function(arg2=2, arg1=1) # 使用关键字参数
默认参数
默认参数是在函数定义中指定默认值的参数,如果调用时没有提供该参数的值,将使用默认值。
默认参数通常在参数列表的最后定义。
def example_function(arg1, arg2=0):
# arg2 是默认参数,如果不提供值,默认为 0
pass
example_function(1) # arg1=1, arg2 使用默认值 0
不定长参数
不定长参数允许函数接受任意数量的参数,通常用于处理可变数量的输入数据。
Python 中有两种类型的不定长参数:*args(接受位置参数)和**kwargs(接受关键字参数)。
可变位置参数(args):
可变位置参数允许你在函数定义中接受不定数量的位置参数。这些参数将被封装为一个元组,你可以在函数内部按索引访问它们。
def example_function(arg1, *args):
print("arg1:", arg1)
for arg in args:
print("additional argument:", arg)
example_function(1, 2, 3, 4)
在上述示例中,*args 接受了额外的位置参数,将它们封装为一个元组。你可以传递任意数量的额外参数给函数,并在函数内部使用循环来访问它们。
可变关键字参数(kwargs):
可变关键字参数允许你在函数定义中接受不定数量的关键字参数。这些参数将被封装为一个字典,你可以按键来访问它们。
def example_function(arg1, **kwargs):
print("arg1:", arg1)
for key, value in kwargs.items():
print(f"additional argument: {key}={value}")
example_function(1, name="Alice", age=30, city="New York")
在上述示例中,**kwargs 接受了额外的关键字参数,将它们封装为一个字典。你可以传递任意数量的额外关键字参数给函数,并在函数内部使用循环来访问它们。
使用场景:
可变位置参数通常用于函数需要接受不定数量的参数的情况,例如,一个接受任意数量参数并返回它们的和的函数。
可变关键字参数通常用于函数需要接受不定数量的关键字参数的情况,例如,一个配置选项的函数,允许用户传递任意数量的参数来自定义配置。
需要注意的是,可变参数通常位于函数参数列表的末尾,因为它们会接受剩余的参数,而前面的参数会按位置或关键字来匹配。
2):使用*来指定参数可以按位置或关键字传递:
在函数参数列表中,将 *放在参数列表的某个位置,它之前的参数将被强制按位置传递,而之后的参数可以按位置或关键字传递。
这种方式允许更大的灵活性,允许调用者选择如何传递参数。
def example_function(arg1, arg2, *, arg3, arg4):
print(arg1, arg2, arg3, arg4)
#arg1 和 arg2 必须按位置传递
#arg3 和 arg4 必须按关键字传递
example_function(1, 2, arg3=3, arg4=4)
参数传递序列的解包
参数传递的序列解包是指将一个序列(通常是元组或列表)的元素解包并传递给函数的位置参数。这允许你使用一个序列中的元素来调用函数,而不必一个一个地列出每个元素作为参数。在Python中,你可以使用*运算符来进行序列解包。
def add(a, b, c):
return a + b + c
定义一个元组,包含三个整数
numbers = (1, 2, 3)
使用序列解包将元组的元素传递给函数
result = add(*numbers)
print(result) # 输出:6
更多示例:
>>> tup1 = ("a1","a2","a3")
>>> func(*tup1) #对元组进行解包
a1 a2 a3
>>> dict={'a':1,'b':2,'c':3}
>>> func(*dict) #对字典的键进行解包
abc
>>> func(*dict.values() #对字典的值进行解包
1 2 3
>>> set1 = {'a','b','c'}
>>> func(*set1) #对集合进行解包
b c a
>>> r1 = range(1,4)
>>> func(*r1) #对其他序列类型进行解包
1 2 3
这是单个星号(*) 对参数传递的序列解包的情形,而两个星号(**) 则是针对
字典的值进行解包的。需要注意的是,字典的键须要与形参的名称保持一致,
否则会报错。实例如下:
>>> def func(p1,p2,p3):
#形参列表中有多个位置参数
print(p1,p2,p3)
return #没有返回值,也就是None
>>>p= {'p1':1,'p2":2,'p3':3}
>>> func(**p) #对字典进行解包,注意键与形参- -致
123
>>> func(*p.values()) #对字典的值进行解包
123
第七章面向对象程序设计
对象和类
对象:即对客观事物的一个统称
类:类是一组相似事物的统称
特征:
封装:把类的内部实现和使用分离开来只保留有限的接口与外部进行联系,对于开发者,我们只需要关系他是如何调用的就可以了,无需关心内部实现。
继承:子类可以继承父类的属性和方法,并且可以在此基础上添加新的属性和方法,提高代码的复用性。
多态:多态使得程序的灵活性和可扩展性变得更好。
定义类
class ClassName:
'''类的帮助信息'''
pass
创建类的实例
#创建某类的一个实例
ObjName = ClassName() #可传实参
继承&方法重写
class Shape:
def __init__(self, color):
self.color = color
def area(self):
pass
class Circle(Shape):
def area(self, radius,PI=3.14):
return radius ** radius * PI
class Rectangle(Shape):
def area(self, width, height):
return width * height
c1 = Circle("天蓝色")
print(c1.color,c1.area(2))
s1 = Rectangle("珊瑚色")
print(s1.color,s1.area(6,6))
访问私有变量
# class Person:
# _name = "JackLove"
# def __init__(self):
# print("__init__()",self._name)
#
# Person()
# p1 = Person()
# print("实例对象直接访问保护类型",p1._name)
class Person:
__name = "Theshy"
def __init__(self):
print("__init__",self.__name)
Person()
p1 = Person()
# print(p1.__name) #直接访问私有类型会报错
#正确访问私有属性的方法: 实例名._类名__属性名
print(p1._Person__name)
为属性添加保护机制
# 电视节目点播系统 V1.0
import random
class channel:
list_c = ["CCTV1", "CCTV3", "CCTV14", "CCTV5", "CCTV6"]
def __init__(self, cctv):
self.__cctv = cctv;
@property
def cctv(self):
return self.__cctv
@cctv.setter
def cctv(self, values):
if values in self.list_c:
self.__cctv = values
return "当前播放" + values + "频道"
else:
return values + "节目不存在", "继续播放" + self.__cctv
rd = random.randint(0, len(channel.list_c) - 1)
p1 = channel(channel.list_c[rd])
print("正在播放:", p1.cctv)
print("这里有:", channel.list_c)
wantc = input("你想看哪个台?告诉我:")
p1.cctv = wantc
print("正在播放:", p1.cctv)















 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









