







最后:策略达到了23.6%的年化收益,夏普比率达到5.87,最大回撤为-4.3%,平局年换手率为27.45 倍,平均持股数量为543 支。
文末有回测结果。
目录
1.模型思想
1.1遗传规划算法介绍
遗传规划算法是一种启发式算法,模拟了自然界中的生物进化过程,尤其是遗传机制。该算法通过模拟生物进化的过程,利用自然选择、交叉、变异等操作来搜索最优解。在遗传规划算法中,问题的解被编码成染色体的形式,然后通过交叉和变异等操作来生成新的解,然后利用适应度函数来评估每个解的优劣,从而实现逐代优化,直到找到满足停止条件的解或达到预设的迭代次数。遗传规划从随机生成的公式群体开始,通过模拟自然界中遗传进化的过程,来逐渐生成契合特定目标的公式群体。作为一种监督学习方法,遗传规划可以根据特定目标,发现某些隐藏的、难以通过人脑构建出的数学公式。传统的监督学习算法主要运用于特征与标签之间关系的拟合,而遗传规划则更多运用于特征挖掘(特征工程)。
量化多因子选股领域中,选股因子的挖掘是一个关注度经久不衰的主题。以往的因子研究中,人们一般从市场可见的规律和投资经验入手,进行因子挖掘和改进,即“先有逻辑、后有公式”的方法,常见的因子如估值、成长、财务质量、波动率等都是通过这种方法研究得出的。随着市场可用数据的增多和机器学习等先进技术的发展,我们可以借助遗传规划的方法在海量数据中进行探索,通过“进化”的方式得出一些经过检验有效的选股因子,再试图去解释这些因子的内涵,即“先有公式、后有逻辑”的方法。
因子挖掘中的搜索空间通常很大,可能包含数千甚至数百万个因子组合。遗传规划算法通过随机性和并行搜索的特性,能够更全面地探索搜索空间,提高了找到最优解的可能性。此外,用于投资的因子十分害怕过拟合,而遗传算法是一种鲁棒的优化算法,在因子挖掘中,往往存在数据的噪音和不确定性,遗传规划算法能够在一定程度上应对这种情况,减少过拟合的风险。同时,由于遗传规划算法得到的因子都是具有表达式的显式因子,不同于深度学习算法,其可解释性比较强,这对于量化投资策略的制定和优化非常重要,可以帮助投资者更好地理解模型的运作机制,增强投资决策的可信度。
一、遗传规划的总体流程
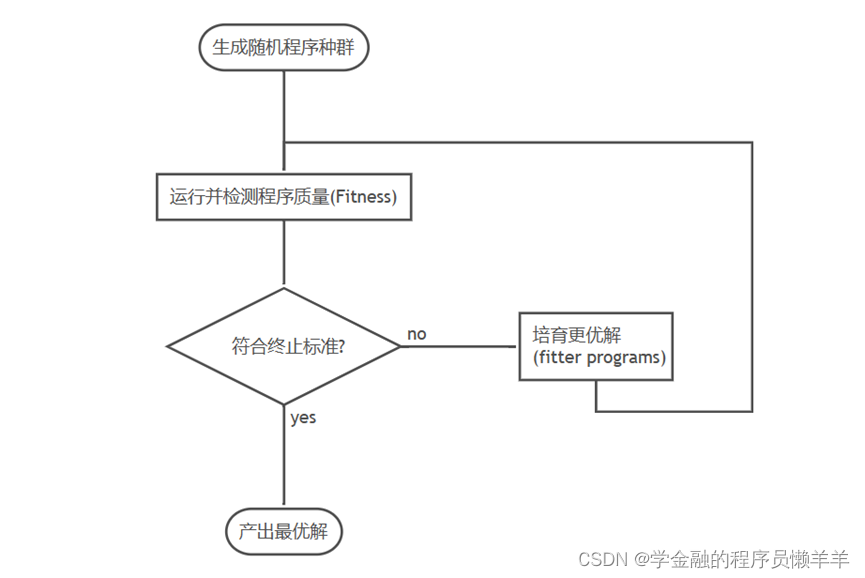 对照上面的流程图,我们可以来简单理清GP系统做了什么、想要做什么。
对照上面的流程图,我们可以来简单理清GP系统做了什么、想要做什么。
- 初始化:在给定初始条件(包括terminal sets, function sets和参数)后生成随机种群;
- 通过(多种方法)比较,评估适应性(fitness evaluation);
- 依据fitness进行概率性选择——“probabilistically selected based on fitness”;
- 被选择的程序作为父系,通过交叉(Crossover) ,变异(Mutation), 复制(Reproduction)等遗传算子(genetic operators)生成下一代(next generation);
- 判断是否符合终止标准(Termination Criterion),没符合的话继续迭代。
二、遗传规划中的表达式
为了方便对公式进行进行变异、生长等操作,在遗传规划中,公式一般会被表示成二叉树的形式假设有特征X0和 X1,需要预测目标 y。一个可能的公式是:
𝑦 = 𝑋02 − 3 × 𝑋1 + 0.5
在遗传规划中上式用 S-表达式(S-expression)表示:𝑦 = (+(−(× 𝑋0𝑋0)(× 3𝑋1))0.5)
,公式里包括了变量(X0和 X1)、函数(加、减、乘)和常数(3 和 0.5)。我们可以把公式表示为一个二叉树,如图所示:
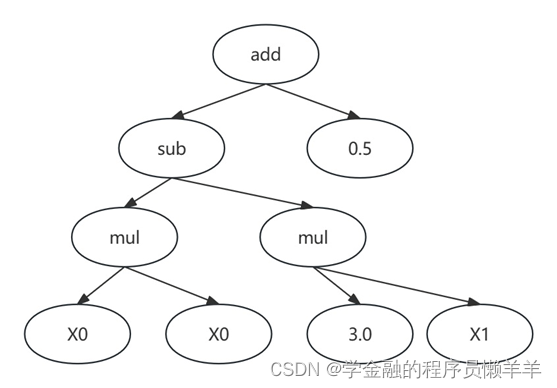 在这个二叉树里,所有的叶子都是变量或者常数,内部节点则是函数。树内的任意子树都可以被修改或替代。公式的输出值可以用递归的方法求得。
在这个二叉树里,所有的叶子都是变量或者常数,内部节点则是函数。树内的任意子树都可以被修改或替代。公式的输出值可以用递归的方法求得。
三、遗传规划中的适应度
类比于自然界中个体对其生存环境的适应程度,在遗传规划中,每个公式也有自己的适应度,适应度衡量了公式运算结果与给定目标的相符程度,是公式进化的重要参考指标。在不同的应用中,可以定义不同的适应度,例如对于回归问题,可以使用公式结果和目标值之间的均方误差为适应度,对于分类问题,可以使用公式结果和目标值之间的交叉熵为适应度。对于使用遗传规划生成的选股因子来说,可以使用因子在回测区间内的平均 RankIC或因子收益率来作为适应度。
四、遗传规划中的公式进化方法
遗传规划的核心步骤是公式的进化,算法会参照生物进化的原理,使用多种方式对公式群体进行进化,来生成多样性的、更具适应性的下一代公式群体。
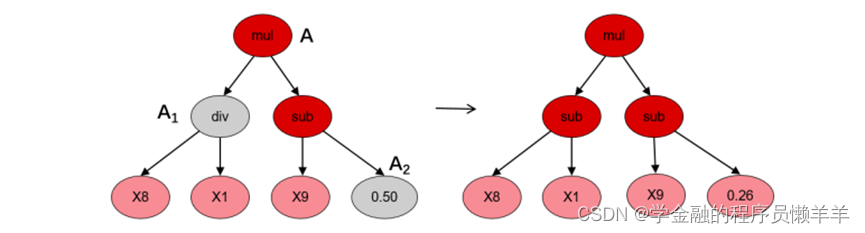
(1)交叉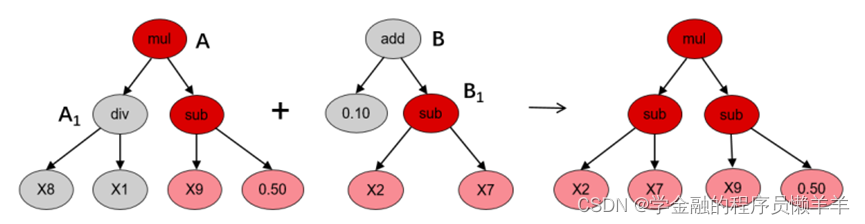
(2)子树变异
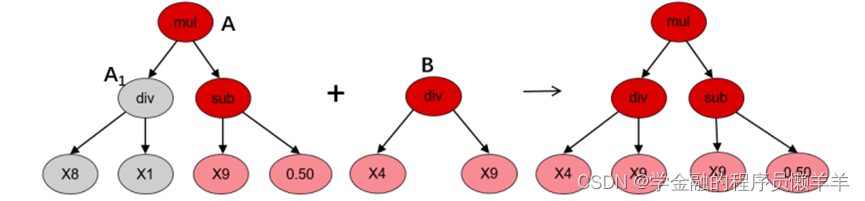 (3)点变异
(3)点变异
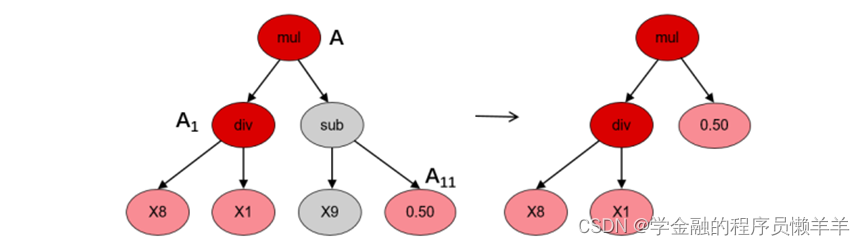
 (4)提升变异
(4)提升变异
1.2因子测试流程
测试流程包含下列步骤:
一、 数据获取和特征提取:
1) 股票池:全 A 股,剔除 ST、PT 股票,剔除每个截面期下一交易日停牌的股票。
2) 回测区间:2018/1/4~2023/12/31。
3) 原始因子列表如下表所示,都是个股的原始量价信息,未经过特征工程。
4) 预测目标:个股下一个交易日收益率。
| 特征名称 | 含义 |
| open | 开盘价(前复权) |
| close | 收盘价(前复权) |
| low | 最低价(前复权) |
| high | 最高价(前复权) |
| volume | 成交量 |
| pct_chg | 涨跌幅 |
| amt | 成交额 |
| vwap | 平均价(前复权) |
| pct_chg_openTomo | 开盘价计算涨跌幅 |
| overnightRet | 隔夜收益率 |
| turn | 换手率 |
| pe_ttm | 市盈率倒数 TTM |
| pb_new | 市净率倒数 |
二、使用遗传规划进行因子挖掘:
1) 使用图表 9 中的因子和图表 8 中的函数集,生成大量公式,并按照流程进行公式的进化和筛选。
2) 公式适应度的计算:假设有公式 F,得出该公式在截面 t 上对所有个股因子向量𝐹𝑡后,将因子暴露度序列减去其现在的均值、除以其标准差,得到一个新的近似服从 N(0,1)分布的序列。经过以上处理后,计算处理后因子在每个截面上与下一交易日收益率的 RankIC,取 RankIC 均值为公式 F 的适应度。
三、 对遗传规划挖掘出的因子,进行更详细的单因子测试,包含 IC 测试、回归测试和分层测试。尝试对因子含义进行解释。
四、 对遗传规划挖掘出的因子进行相关性分析。
五、 使用筛选出的因子建立多因子选股模型,并使用股指期货构建中性对冲策略,最后进行回测。
2.代码与实现
2.1 gplearn 介绍与参数设置
gplearn(https://gplearn.readthedocs.io)是目前最成熟的 Python 遗传规划项目之一。gplearn 提供类似于 scikit-learn 的调用方式,并通过设置多个参数来完成特定功能。下表展示了 gplearn 的主要参数。
| 参数名称 | 定义 |
| generations | 公式进化的世代数量。 |
| population_size | 每一代公式群体中的公式数量。 |
| n_components | 最终筛选出的最优公式数量。 |
| hall_of_fame | 选定最后的n_components个公式前,提前筛选出的备选公式的数量,n_components<hall_of_fame<population_size。 |
| function_set | 用于构建和进化公式时使用的函数集。 |
| parsimony_coefficient | 节俭系数,用于惩罚过于复杂的公式。 |
| tournament_size | 每一代的所有公式中,tourmament_size个公式会被随机选中,其中适应度最高的公式能进行变异或繁殖生成下一代公式。 |
| random_state | 随机数种子。 |
| init_depth | 公式树的初始化深度, init_depth是一个二元组(min_depth,max_depth),树的初始深度将处在[min_depth,max_depth]区间内。 |
| metric | 适应度指标。 |
| const_range | 公式中常数的取值范围,默认为(-1,1),如果设置为 None,则公式中不会有常数。 |
| p_crossover | 交叉变异概率,即父代进行交叉变异进化的概率。 |
| p_subtree_mutation | 子树变异概率,即父代进行子树变异进化的概率。 |
| p_hoist_mutation | Hoist 变异概率,即父代进行 Hoist 变异进化的概率。 |
| p_point_mutation | 点变异概率,即父代进行点变异进化的概率。 |
| p_point_replace | 点替代概率,即点变异中父代每个节点进行变异进化的概率。 |
2.2 自定义算子与自定义metrics
gplearn 提供了一套简洁、规范的遗传规划实现代码,但是不能直接运用于选股因子的挖掘。我们从源代码的层面,对 gplearn 进行了深度改进,使得其能运用于选股因子的挖掘。
首先,我们扩充了 gplearn 的函数集(function_set),提供了更多特征计算方法,以提升其因子挖掘能力。除了 gplearn 提供的基础函数集(加、减、乘、除、开方、取对数、绝对值等),我们还自定义了一些函数(包括多种时间序列运算函数,这是 gplearn 不支持的),函数列表详细展示在下表中。
| 算子类型 | 算子名称 | 算子定义 |
| 元素级运算 | add(X,Y) | X+Y |
| sub(X,Y) | X-Y | |
| mul(X,Y) | X*Y | |
| div(X,Y) | X/Y | |
| sqrt(X) | X 绝对值开方 | |
| log(X) | X取对数 | |
| abs(X) | X绝对值 | |
| neg(X) | -X | |
| inv(X) | 1/X | |
| max(X,Y) | 取两因子中大的值 | |
| min(X,Y) | 取两因子中小的值 | |
| sin(X) | sin(X) | |
| cos(X) | cos(X) | |
| tan(X) | tan(X) | |
| sig(X) | 1/(1+EXP(-X)) | |
| sign(X) | X的符号 | |
| ltp(X,Y) | X>Y则取 1,否则为 0 | |
| gtp(X,Y) | X<Y则取 1,否则为 0 | |
| signedpower(X) | 保留 X的符号进行平方 | |
| delta(X) | X相邻两期因子之间的差 | |
| 时序运算 | ts_delta(X,N) | X相隔 N期因子之间的差 |
| ts_pctdelta(X,N) | X相隔 N期因子之间变化百分比 | |
| ts_delay(X,N) | X因子值滞后 N期 | |
| ts_beta(X,Y,N) | X和 Y滚动 N期窗口回归得到的beta值 | |
| ts_pctdelta(X,N) | X和 Y滚动 N期窗口回归得到的截距项值 | |
| ts_resides(X,Y,N) | X和 Y滚动 N期窗口回归得到的残差值 | |
| ts_corr(X,Y,N) | X和 Y滚动 N期窗口 Pearson相关系数 | |
| ts_rank_corr(X,Y,N)) | X和 Y滚动 N期窗口 Spearman相关系数 | |
| ts_sum(X,N) | X滚动 N期窗口求和 | |
| ts_prod(X,N) | X滚动 N期窗口求累乘 | |
| ts_covariance(X,Y,N) | X和 Y滚动 N期窗口求协方差 X滚动 N期窗口标准差 | |
| ts_std(X,N) | X滚动 N期窗口标准差 | |
| ts_mean(X,N) | X滚动 N期窗口求均值 | |
| ts_timewighted_mean(X,N) | X滚动 N期窗口求按时间远近加权求均值 | |
| ts_rank(X,N) | X滚动 N期窗口求排名 | |
| ts_max(X,N) | X滚动 N期窗口最大值 | |
| ts_min(X,N) | X滚动 N期窗口最小值 | |
| ts_argmax(X,N) | X在过去 N期上最大值对应的日期离当前日期的时间差 | |
| ts_argmin(X,N) | X在过去 N期上最小值对应的日期离当前日期的时间差 |
其次,遗传规划由于涉及到大量的随机操作,时间开销较大,们还使用了 Python 中的并行运算技术,加快了因子矩阵的运算速度,缩短了因子挖掘时间。
此外,我也自定义了一些在投资中常用到的metrics,具体信息如下表所示。
| 评估方式 | 定义 |
| IC(Y,Y_PRED) | Y 和Y_PRED 的Pearson 相关系数 |
| RankIC(Y,Y_PRED) | Y 和Y_PRED 的Spearman 相关系数 |
| IR(Y,Y_PRED) | IC(Y,Y_PRED)均值/IC(Y,Y_PRED)方差 |
| RankICIR(Y,Y_PRED) | RankIC(Y,Y_PRED)均值/RankIC(Y,Y_PRED)方差 |
| long return(Y,Y_PRED) | Y_PRED 分层前10%多头股票在Y 上的均值 Y_PRED 分层前10%多头股票-Y_PRED 分层后10%多头股票在Y 上的均值 |
| long short return(Y,Y_PRED) | Y_PRED 分层前10%多头股票在Y(一般是收益率)上的夏普比率 |
| long sharp(Y,Y_PRED) | Y_PRED 分层前10%多头股票-Y_PRED 分层后10%多头股票在Y 上的夏普比率 |
| long short sharp(Y,Y_PRED) mutual information(Y,Y_PRED) | Y 和Y_PRED 的互信息,用于挖掘非线性因子 |
2.3改进思路及结果
该项目还存在以下一些问题
- 由于gplearn 框架仅支持二维数据,无法实现三维数据(股票×时间×初始特征) 的传入,因此在进行公式变异和公式fitness 计算时并不能完全契合投资时按照时 序进行投资决策制定的显示逻辑。
- 由于传入数据维度的限制,在开发自定义算子时难以使用时序计算相关的算子如因子间的滚动相关性)和截面计算相关的算子(例如因子值在界面上所处分位的计算)。
- 由于公式计算中涉及到大量的计算,仅使用CPU 进行计算需要耗费较多时间,许 多计算密集的步骤可以尝试结合numpy 矩阵计算、numba、cuda 等技术将代码进 行改进,将部分计算密集的算子在GPU 上进行计算。
- 没有实现并行运算,程序尚有提升速度的潜力。
基于上述一些问题,我首先将gplearn 所支持传入的数据结构进行了改进,将原先仅支持传入dataframe 的二维数据(samples×features)改成支持传入主流因子组织结构的(dict{feature(dates×stocks)})的形式,同时使用numpy 矩阵计算、numba、cuda 等技术将代码进行改进,将部分计算密集的算子在GPU 上进行计算。
其次,遗传规划由于涉及到大量的不会相互影响的进程操作,时间开销较大,们还使用了 Python 中的并行运算技术,加快了因子矩阵的运算速度,缩短了因子挖掘时间。
并扩建添加了诸如因子在每一时间截面上的百分比排名、两因子滚动窗口回归取残差和因子滚动窗口标准差等算子。最终所有算子除了前面章节提到的表所示,还包含以下的截面运算表。
| 算子名称 | 算子定义 |
| rank_pool_pct(X) | 因子在每一时间截面上的百分比排名 |
| rank_pool_pct_sub(X,Y) | X,Y 因子在每一时间截面上的百分比排名之差 |
| rank_pool_pct_div(X,Y) | X,Y 因子在每一时间截面上的百分比排名相除 |
| rank_pool_pct_add(X,Y) | X,Y 因子在每一时间截面上的百分比排名之和 |
| rank_pool_pct_mul(X,Y) | X,Y 因子在每一时间截面上的百分比排名相乘 |
| pool_resides(X,Y) | X,Y 因子每一界面时间上进行回归并取残差 |
改进后将原有的进行一轮训练耗费10 小时缩减到30-60 分钟,大大提升了模型运行速度,这为因此地稳定大量产出提供了强力保障。
3.回测及结果
3.1 单因子测试结果
对因子的入库要求如下:
➢ 每轮训练中大于所选metric 的最低阈值,且因子间相关性大于0.9 的仅保留一个;
➢ Rankic>0.3 或中性化后rankic>0.03 或rankir>0.5 或中性化后rankir>0.5 或费用后头
部收益高年化>0.1 或费用前头部收益高年化>0.25 或换手率<100。
使用这一模型,选择不同的metric 总共进行了22 轮训练,生成了共28 个模型,其中符
合入库要求的因子共有645 个,表现的统计结果如下:
| rankic>0.03 | 中性化后rankic>0.03 | rankir>0.5 | 中性化后rankir>0.5 | 费用后头部收益高年化>0.1 | 费用前头部收益高年化>0.25 | 换手率<100 | |
| 数量 | 208 | 68 | 1 | 39 | 18 | 408 | 172 |
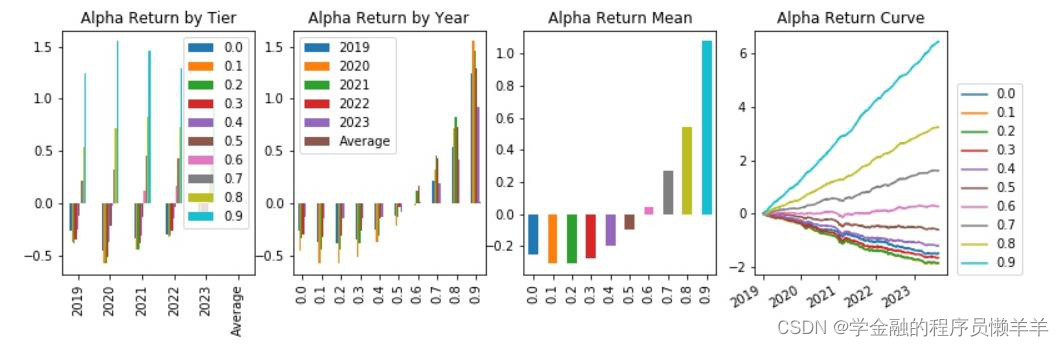
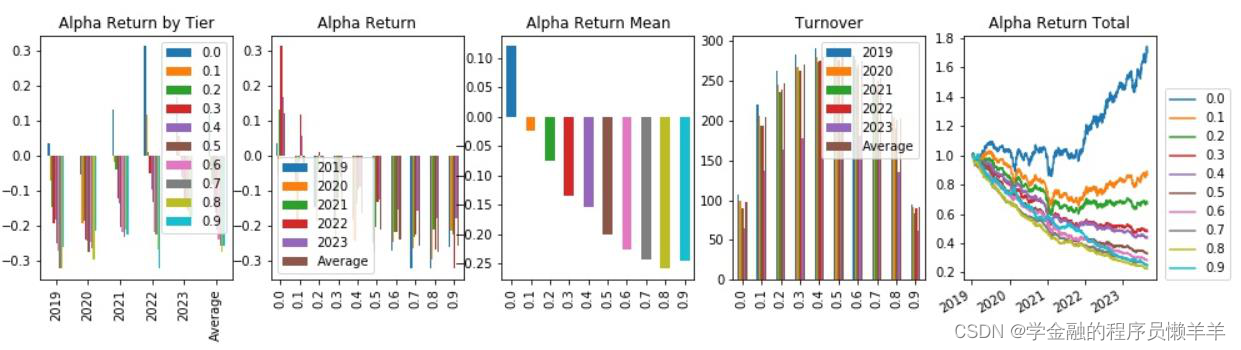
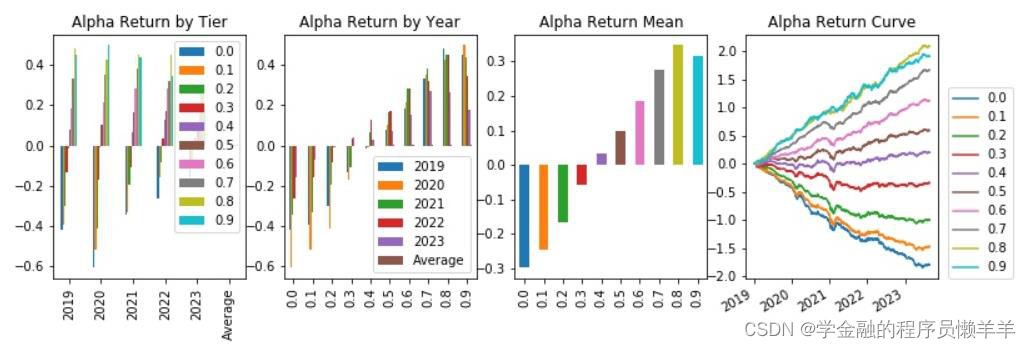
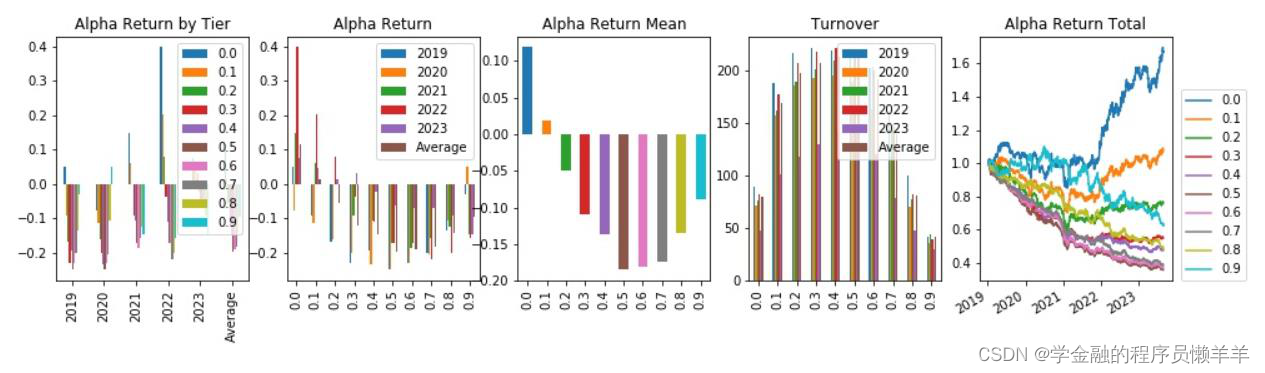
从645 个因子中精选出下列因子,期主要风险指标和分层回测情况如下所示。
| rankic >0. 03 | 中性化后rankic >0. 03 | rankir > 0.5 | 中性化后rankir >0.5 | 费用后头部收益高年化>0.1 | 费用前头部收益年 化>0.25 | 换手率<100 | ||
| gp_factor _2024010 | 指标 | -0.043 | -0.034 | -0.453 | -0.536 | -0.059 | 0.008 | 91.153 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024012 5_1_71 | 指标 | -0.042 | -0.037 | -0.329 | -0.401 | 0.164 | -0.001 | 31.356 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024010 16_1_127 7 | 指标 | -0.036 | -0.015 | -0.285 | -0.251 | 0.139 | 0.003 | 62.865 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor | 指标 | -0.034 | -0.014 | -0.315 | -0.219 | 0.135 | 0.003 | 68.181 |
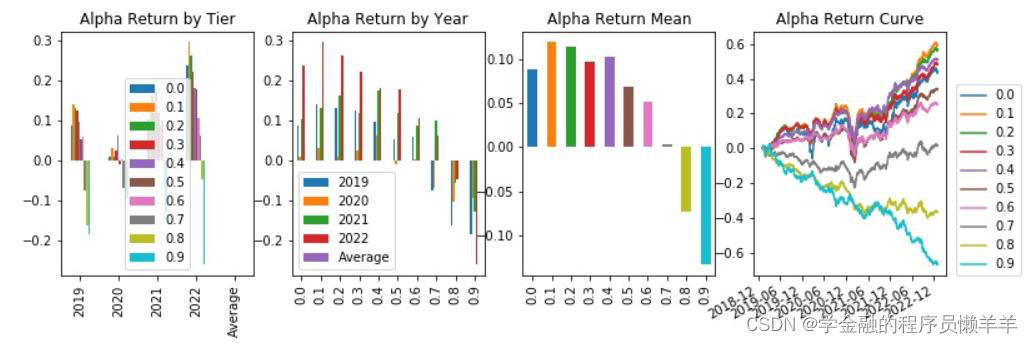
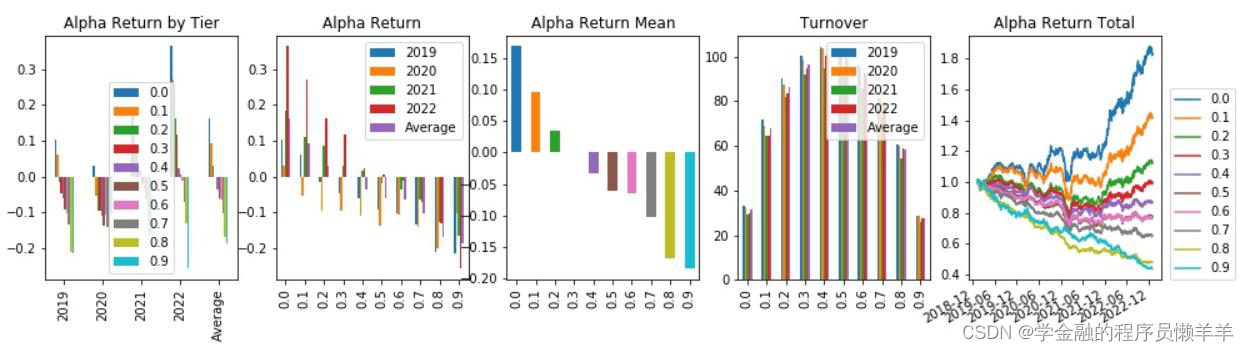
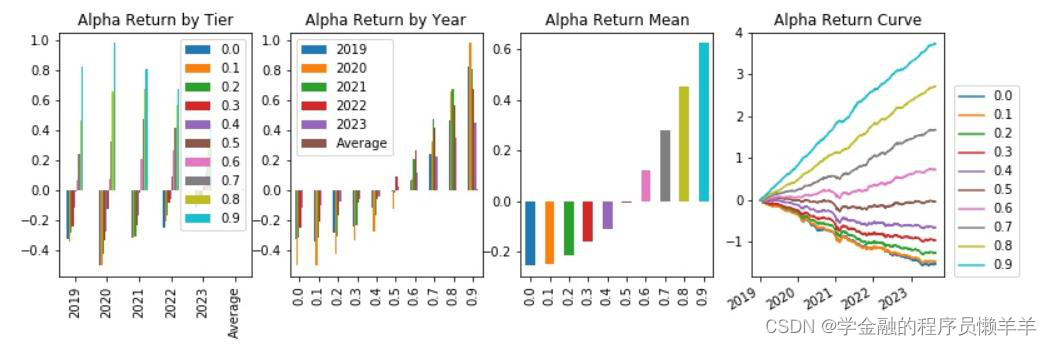
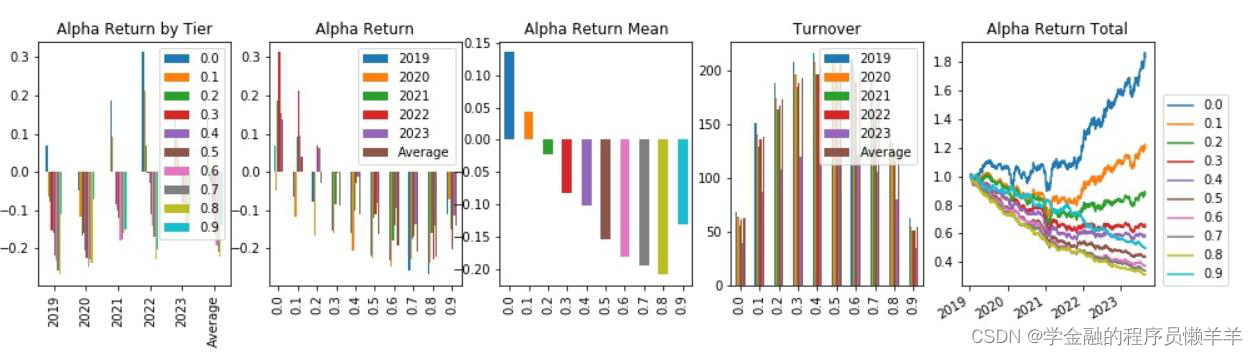
| _2024030 | 费用前分层回测 |
| ||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024022 | 指标 | -0.041 | -0.001 | -0.257 | -0.006 | 0.124 | 0.003 | 74.783 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024010 16_1_496 4 | 指标 | -0.048 | -0.027 | -0.373 | -0.361 | 0.121 | 0.006 | 97.129 |
| 费用前分层回测 |
| |||||||
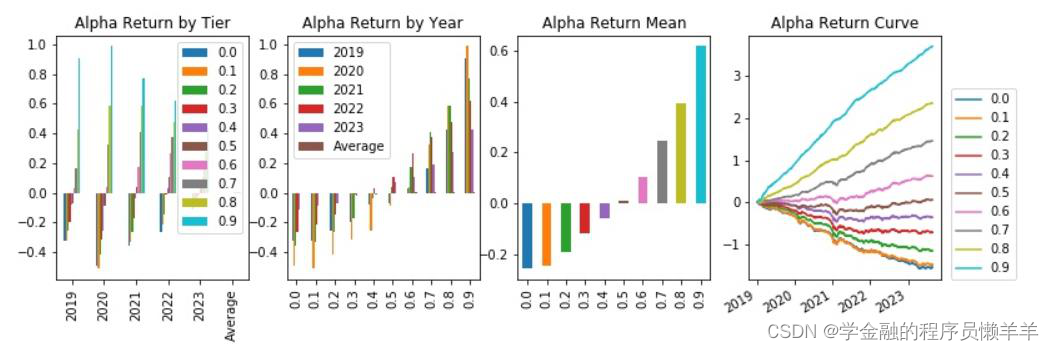
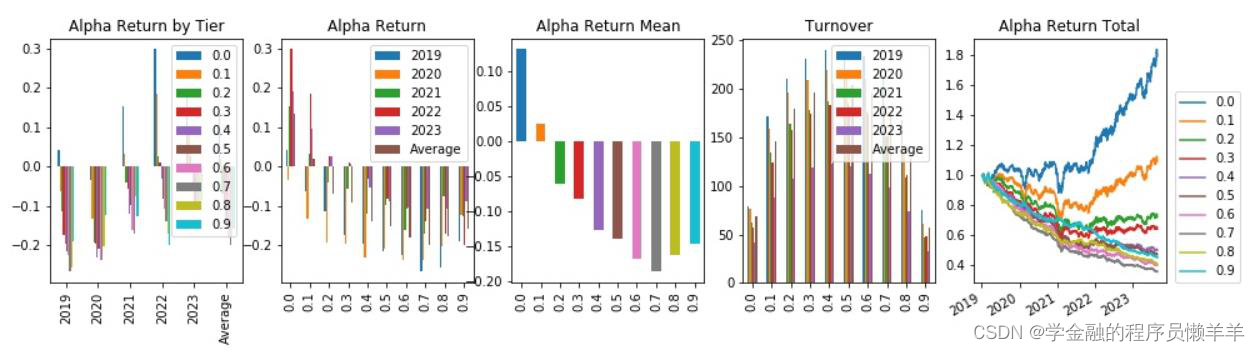
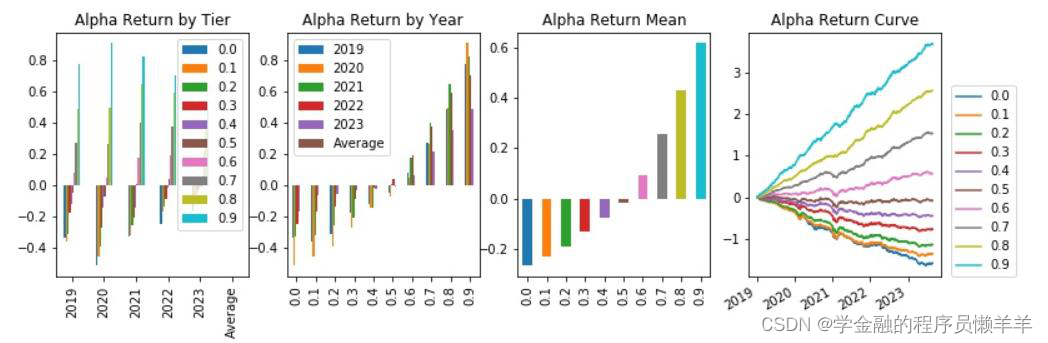
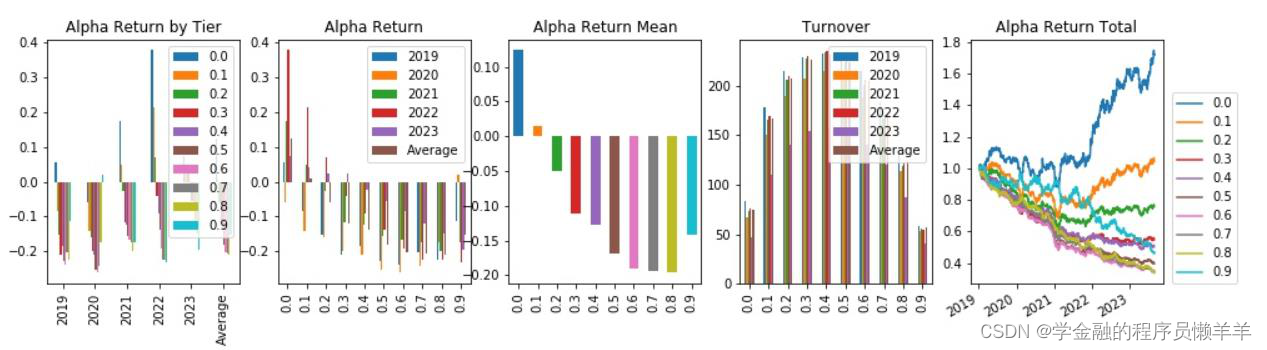
| 费用后分层回测 |
| |||||||
| gp_factor _2024022 | 指标 | -0.035 | -0.022 | -0.220 | -0.240 | 0.117 | 0.002 | 79.971 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024010 16_1_511 1 | 指标 | -0.037 | -0.021 | -0.350 | -0.273 | 0.114 | 0.005 | 84.870 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
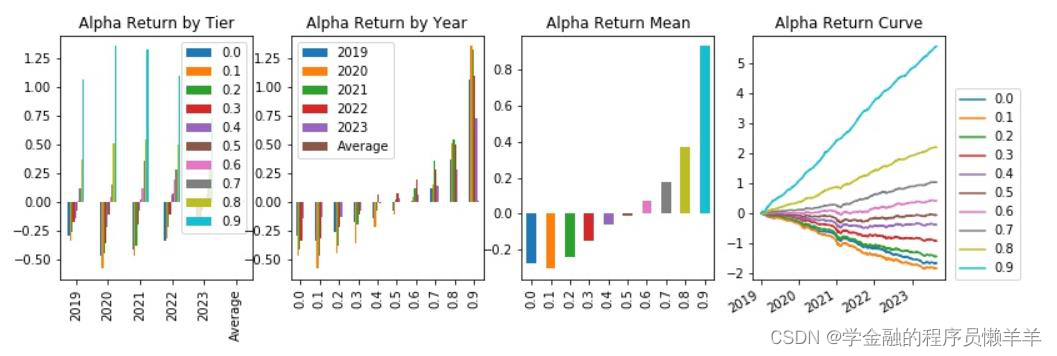
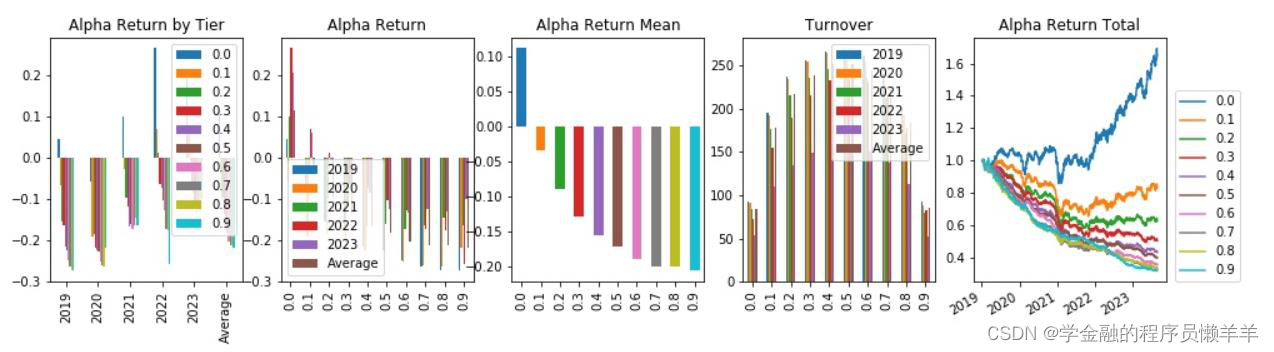
| gp_factor _2024022 7_1_859 | 指标 | -0.046 | -0.023 | -0.346 | -0.316 | 0.111 | 0.005 | 91.463 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024030 | 指标 | 0.042 | 0.002 | 0.315 | 0.024 | 0.109 | 0.004 | 84.334 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
| gp_factor | 指标 | 0.042 | 0.018 | 0.326 | 0.266 | 0.121 | -0.001 | 86.308 |
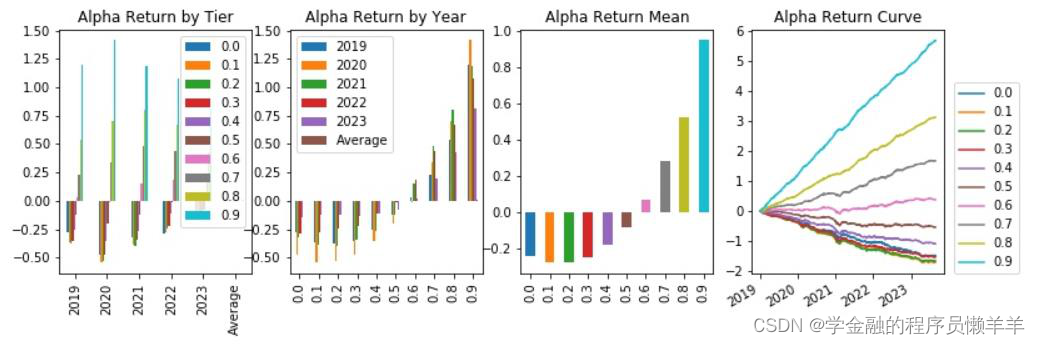
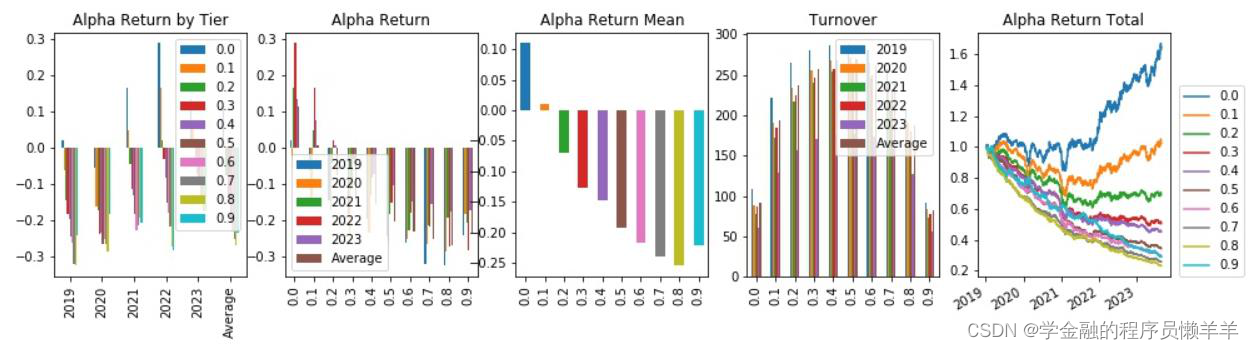
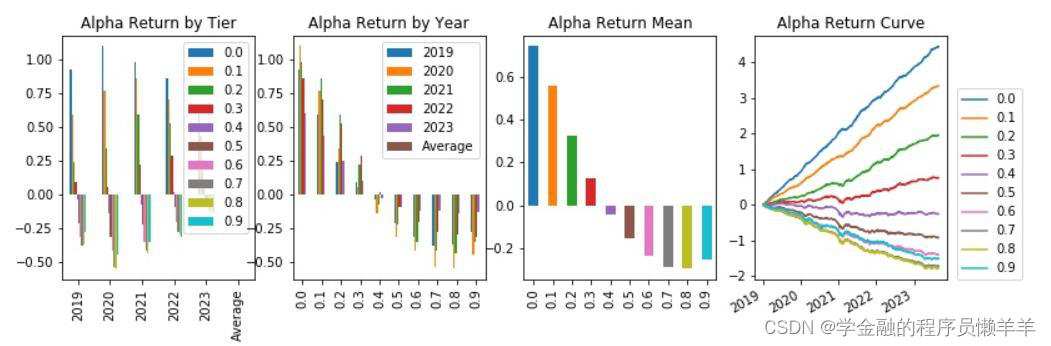
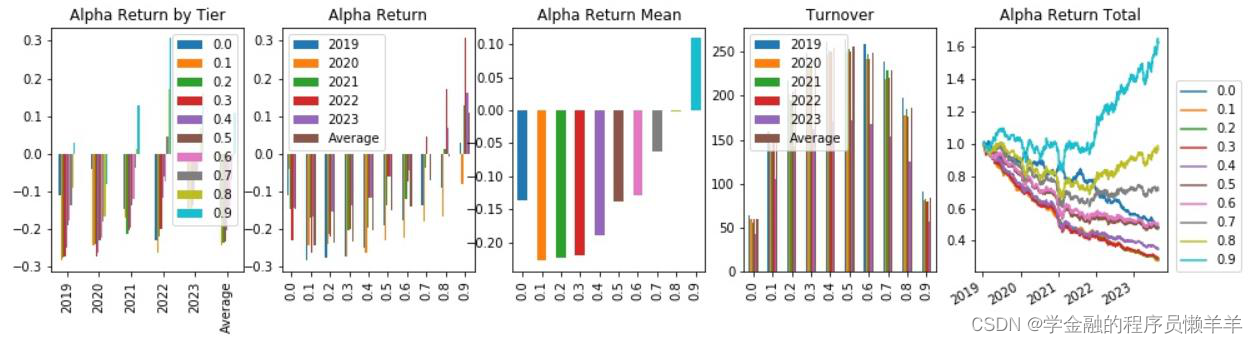
| _2024022 | 费用前分层回测 |
| ||||||
| 费用后分层回测 |
| |||||||
| gp_factor _2024012 6_2_1 | 指标 | -0.041 | -0.038 | -0.312 | -0.387 | 0.088 | 0.000 | 32.534 |
| 费用前分层回测 |
| |||||||
| 费用后分层回测 |
| |||||||
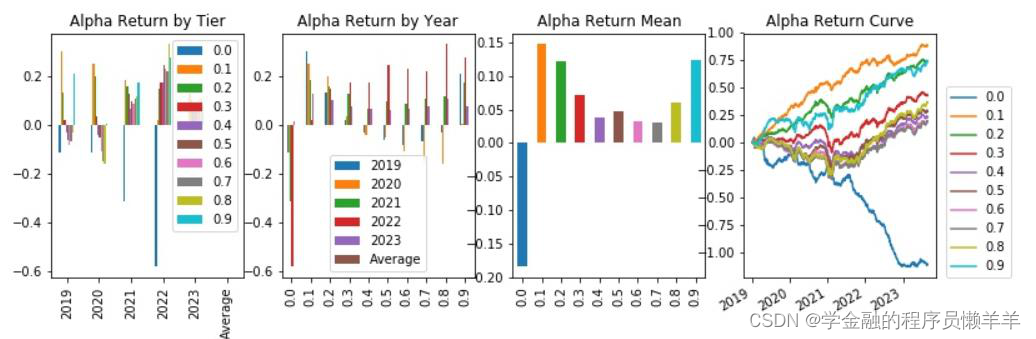
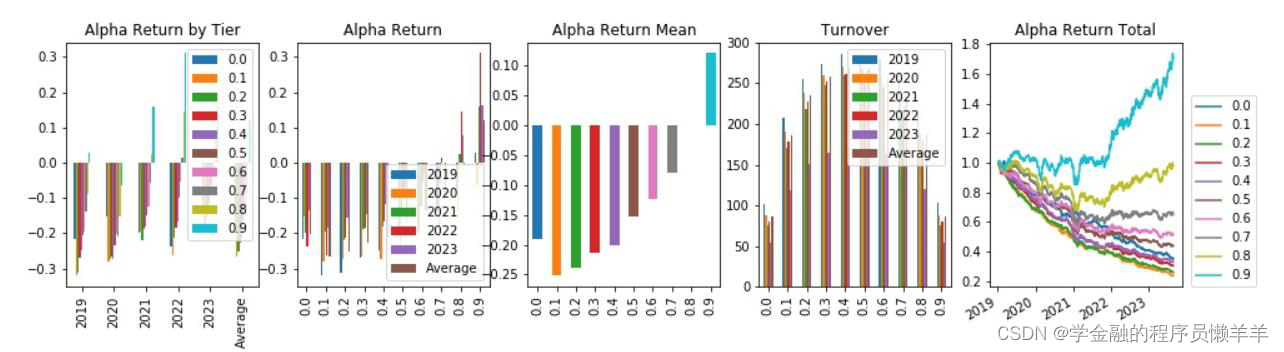
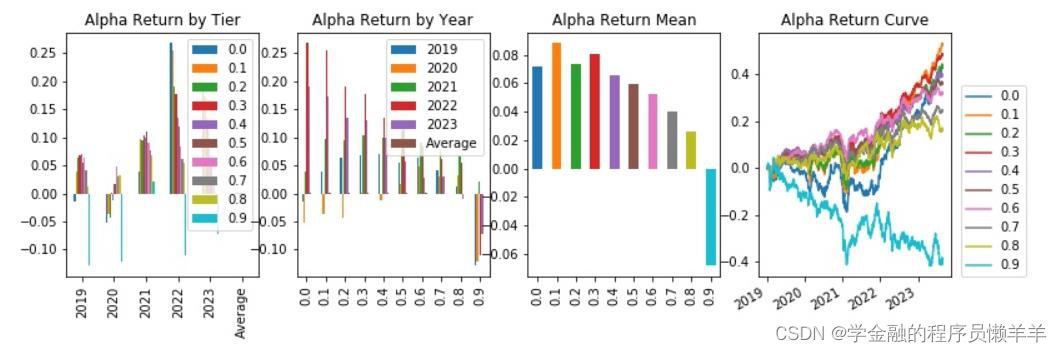
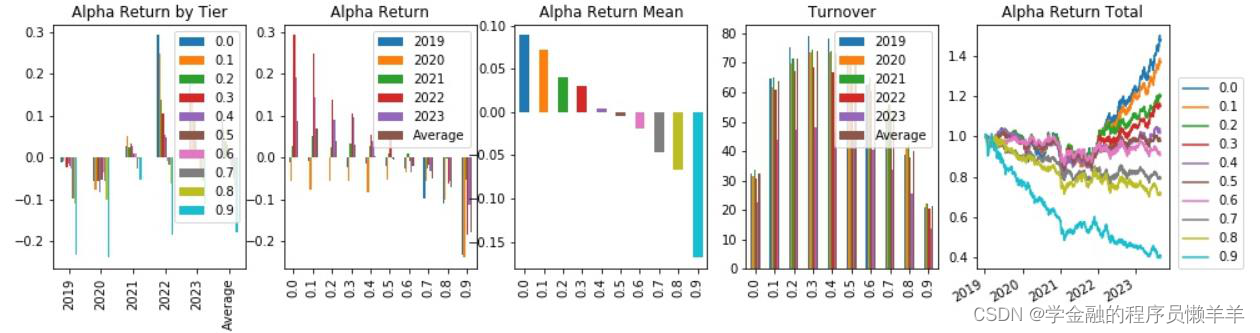
3.2 多因子模型选股
采用线性模型来对因子进行建模,首先采用最优化复合IC 加权的方式将候选因子中选出的100 个因子进行加权,随后使用复合因子进行选股,持有选股结果10%多头股票。
回测结果如下图所示:
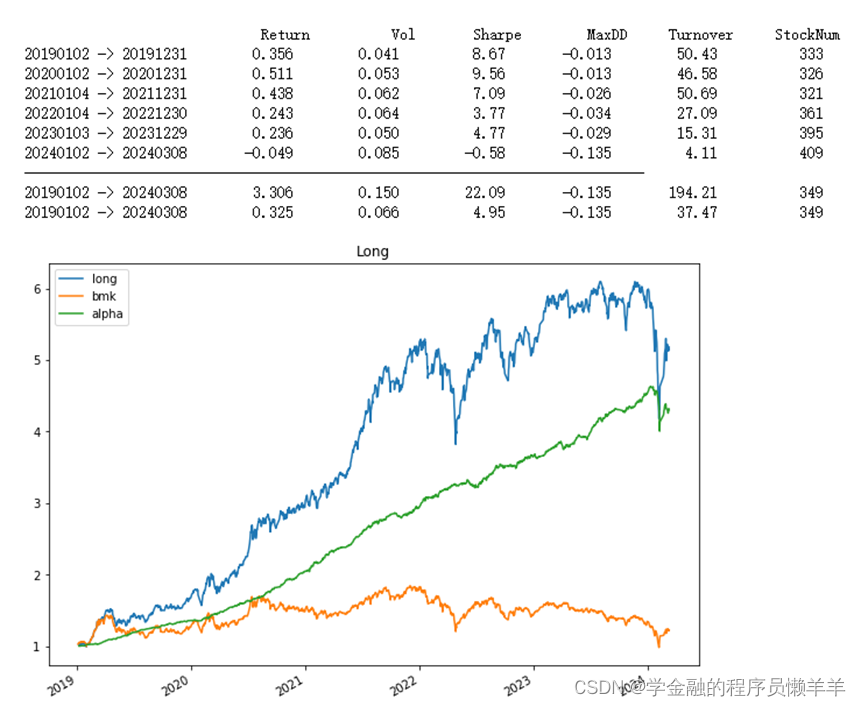
其中蓝色曲线为股票多头收益,绿色曲线为对冲后收益,黄色曲线为中证500 收益曲线。该对冲策略达到了32.5%的年化收益,夏普比率达到4.95,最大回撤为-13.5%,平均年换手率为37.47 倍,平均持股数量为349 支。即使考虑到实盘中对策略的收益存在侵蚀,该策略也是一个优秀的策略。
对模型添加一些风控限制后,表现如下:
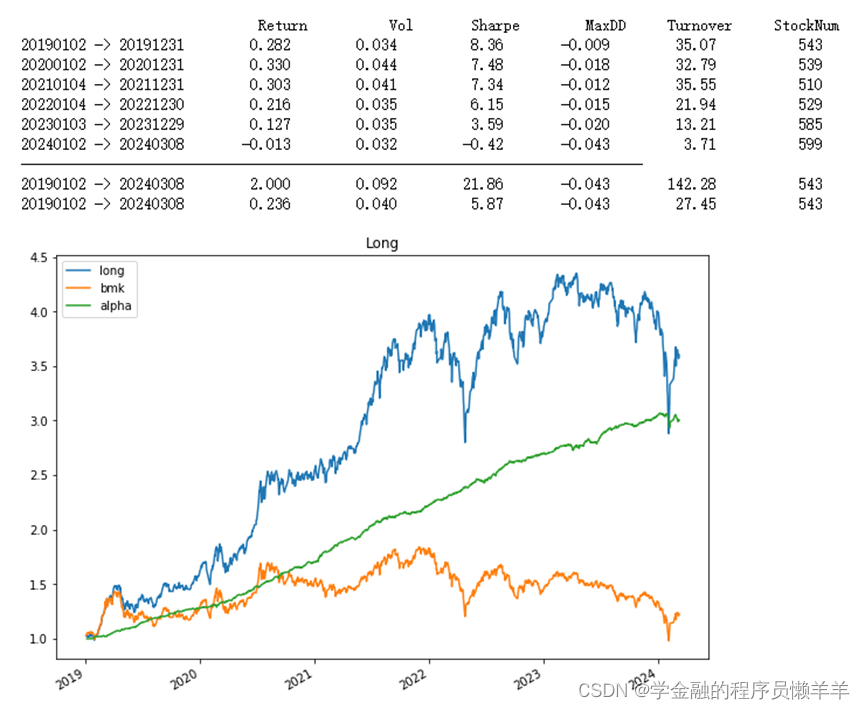
策略达到了23.6%的年化收益,夏普比率达到5.87,最大回撤为-4.3%,平局年换手率为27.45 倍,平均持股数量为543 支。虽然年化收益有所下降,但夏普比率和最大回撤等风险指标有了大幅改善。


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









