






一、背景介绍
今天要介绍的论文名称为 KAN: Kolmogorov–Arnold Networks,即KA网络,这是今年5月份预发布在arxiv上的文章,作者是MIT的博士。这也是上个月讨论得比较多的一篇文章,目前在github上的收藏数为13k。(github地址)
1.1 为何热门?
这篇文章为什么热门呢?主要的原因是作者对KAN的结构与MLP的结构进行对比实验,并把它认为是MLP的一个可能的替代品。那么我们知道,目前的绝大多数深度学习算法都是基于MLP框架的,即输入与线性权重相乘,再经过一个激活函数这种架构。这种在底层上的改变引来了很多的关注和讨论,会不会是深度学习领域的一次革新。
1.2 KAN的创新点
MLP 在节点(“神经元”)上具有固定的激活函数,而 KAN 在边缘(“权重”)上具有可学习的激活函数。 KAN 根本没有线性权重——每个权重参数都被参数化为样条函数的单变量函数取代。作者证明了,这种看似简单的改变使得 KAN 在准确性和可解释性方面优于 MLP。
二、理论介绍
2.1 KA理论
首先介绍一下KA理论,它表示,任意一个多变量函数都可以表示为一些单变量函数的集合。数学表达的形式如下。
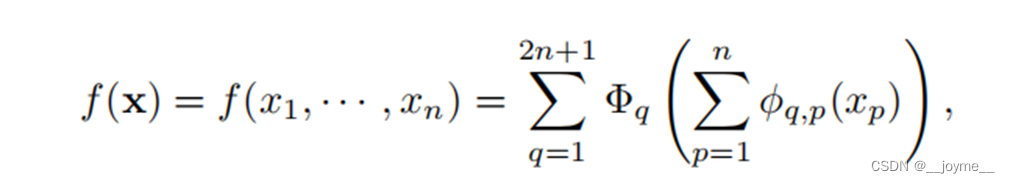
更直观的理解可以看这个网络结构图,假设输入有2个特征,即n=2。最里面的部分表示这2个特征经过各自的一个激活函数后,结果相加。而中间节点的个数为2n+1,即5个。然后经过激活函数后再相加。而这个激活函数的可学习性体现在,它是由多个样条函数拟合而成,其中ci控制每一个样本函数的缩放,样条函数的数量(也叫网格数或者是分辨率)决定了这个激活函数的精度。
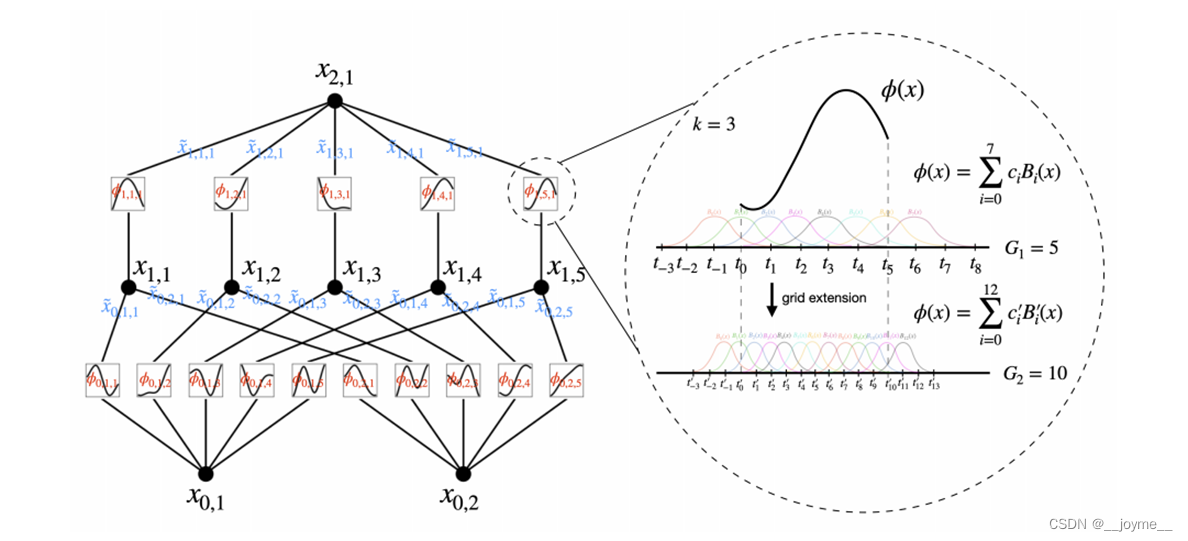
然而,这个理论有一定的局限性,它导致了网络结构的高和宽都是固定的(即网络最高只能有两层,宽也被输入特征维度所限制),没有一种更加“广义”的形式。
2.2 广义形式的KAN
因此呢,作者注意到了这个网络与MLP的结构高度相似,于是乎通过初步的数学分析,提出KAN层的概念,将其推广成多层的形式,使得网络能够具有任意的宽和高。
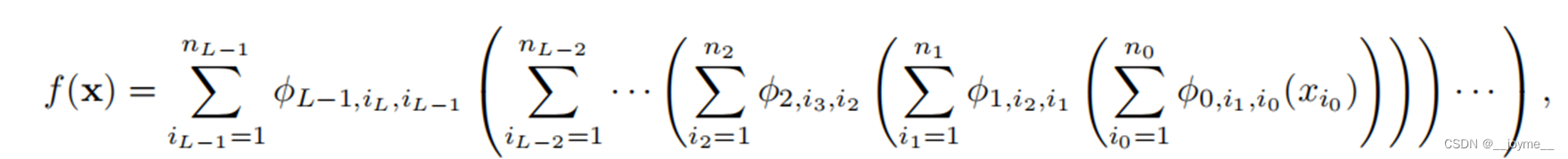
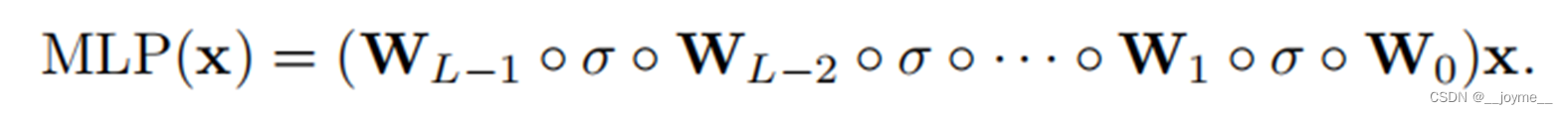
2.3 可学习的激活函数
为了优化计算,在激活函数的设计方面,作者加入一个基函数 b(x),使得激活函数 φ(x) 是基函数 b(x) 和样条函数的和。(类似于残差连接)
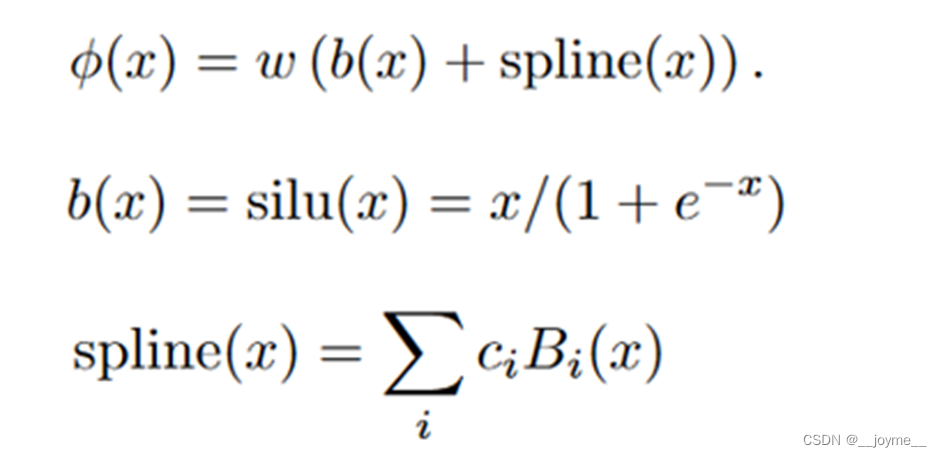
2.4 算法总结
KAN 只不过是样条曲线和 MLP 的组合,利用了各自的优点并避免了各自的缺点。样条对于低维函数来说是准确的,易于局部调整,并且能够在不同分辨率之间切换。然而,样条曲线存在严重的维数灾难 (COD) 问题,因为它们无法利用组合结构。另一方面,MLP 受到 COD 的影响较小,但由于其无法优化单变量函数,因此在低维度上不如样条准确。
三、实验结果
作者做了大量的实验,包括拟合符号函数,发现数学定律,发现物理定律,偏微分方程求解等,由于本文章篇幅有限,仅展示和分析部分结果。
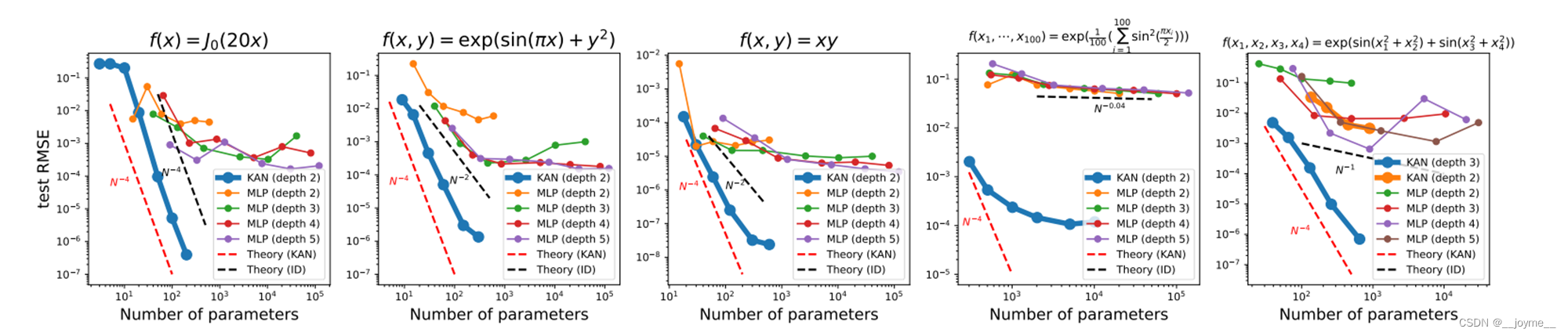
3.1 拟合符号函数
作者使用不同层数的MLP与KAN,在拟合符号函数上进行对比。从图中可以看出,横坐标是参数量,纵坐标是测试损失。这条蓝线是KAN,在同等参数量的情况下,KAN的精度更高。
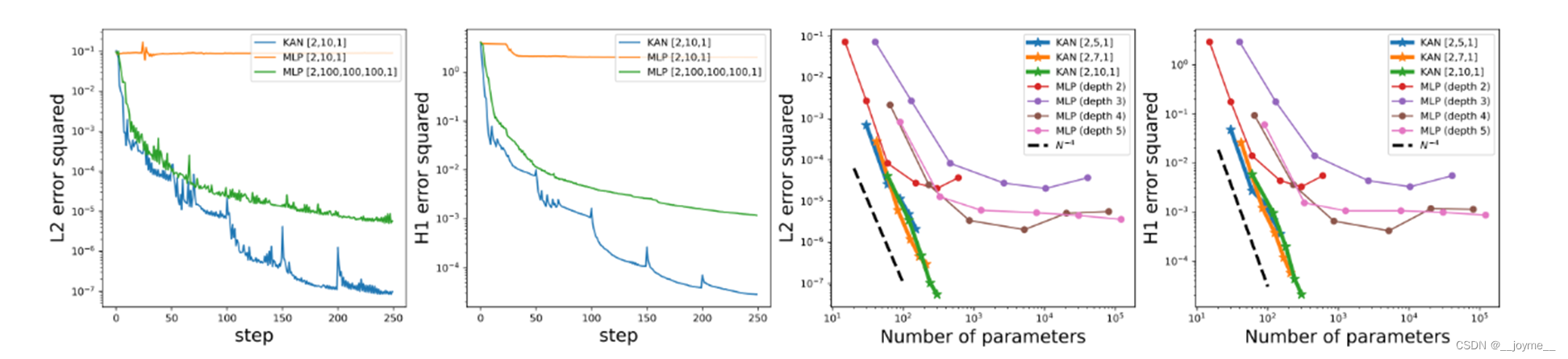
3.2 偏微分方程求解
在偏微分求解方面,KAN模型的求解精度和网络参数也是更少的。
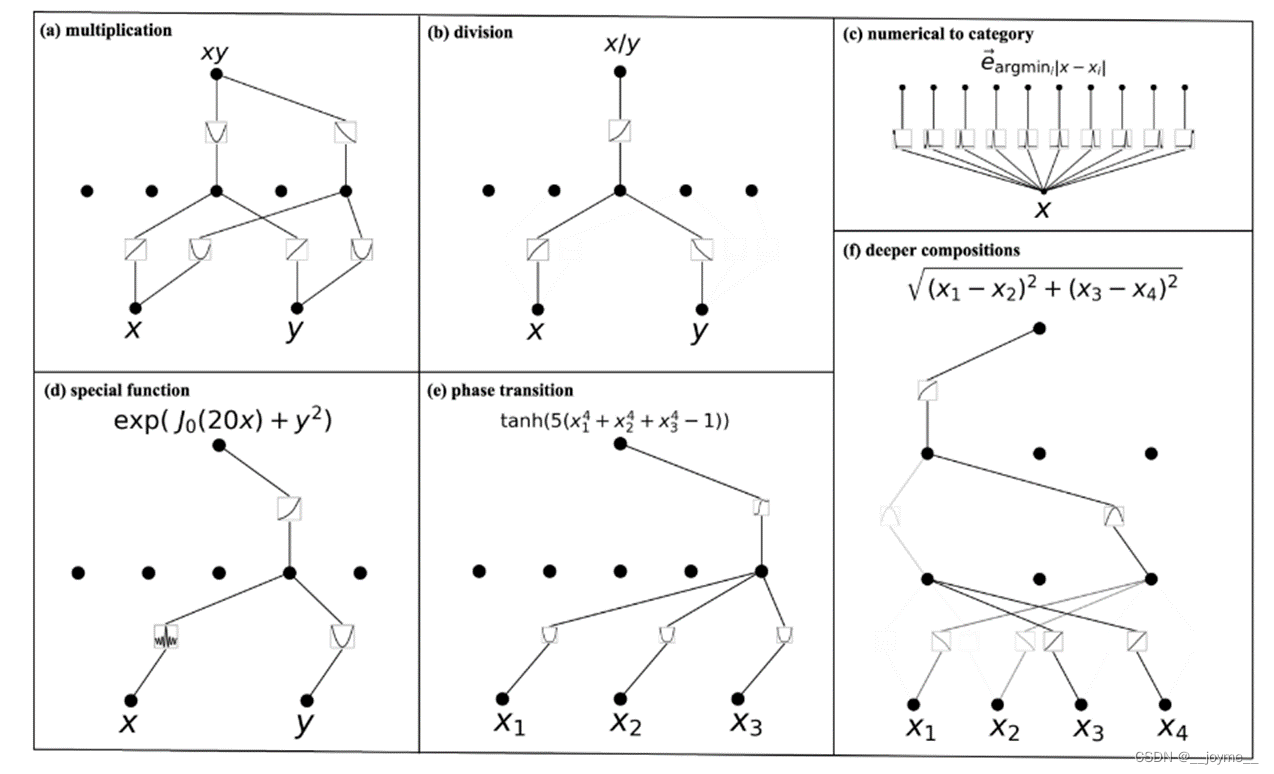
3.3 可解释性:符号公式
而在可解释方面,KAN模型可以直观地看到整个网络是由哪一些函数所构成的。
四、总结
(1)作者所提出的更深层次的 KAN 模型,在实验上取得了一些成功,但只对其做了初步的数学分析,仍需要更多的理论支撑。
(2)作者只进行了一些实验,仍有许多改进空间,比如样条激活函数可能被径向基函数或其他局部内核替换,可以使用自适应网格策略等。
Github仓库:https://github.com/mintisan/awesome-kan
包括:与卷积结合,与GPT结合,与NeRT结合,与Transformer结合……
(3)KAN 可能不是一个简单的插件,可以开箱即用。目前在程序优化上比较差,训练时间比较长。使用的时候也需要调整超参数,以达到可接受的性能与参数量。
Efficient-kan:GitHub - Blealtan/efficient-kan: An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN).
Fastkan:GitHub - ZiyaoLi/fast-kan: FastKAN: Very Fast Implementation of Kolmogorov-Arnold Networks (KAN)















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









