







本文首发于微信公众号:人工智能与图像处理
学术界的 SOTA 模型在落地部署到工业界应用到过程中,通常是要面临着低延迟(Latency)、高吞吐(Throughpout)、高效率(Efficiency)的挑战。而模型压缩算法可以将一个庞大而复杂的预训练模型转化为一个精简的小模型,从而减少对硬件的存储、带宽和计算需求,以达到加速模型推理和落地的目的。
近年来主流的模型压缩方法包括:数值量化(Data Quantization,也叫模型量化),模型稀疏化(Model sparsification,也叫模型剪枝 Model Pruning),知识蒸馏(Knowledge Distillation), 轻量化网络设计(Lightweight Network Design)和 张量分解(Tensor Decomposition)。
其中模型剪枝是一种应用非常广的模型压缩方法,其可以直接减少模型中的参数量。
一,深度神经网络的稀疏性
生物研究发现人脑是高度稀疏的。比如 2016 年早期经典的剪枝论文就曾提到,生理学上发现对于哺乳动物,婴儿期产生许多的突触连接,在后续的成长过程中,不怎么用的那些突触就会退化消失。结合深度神经网络是模仿人类大脑结构,和该生理学现象,我们可以认为深度神经网络是存在稀疏性的。
根据深度学习模型中可以被稀疏化的对象,深度神经网络中的稀疏性主要包括权重稀疏,激活稀疏和梯度稀疏。
1.1,权重稀疏
在大多数神经网络中,通过对网络层(卷积层或者全连接层)对权重数值进行直方图统计,可以发现,权重(训练前/训练后)的数值分布很像正太分布(或者是多正太分布的混合),且越接近于 0,权重越多,这就是权重稀疏现象。
相关论文认为,权重数值的绝对值大小可以看做重要性的一种度量,权重数值越大对模型输出贡献也越大,反正则不重要,删去后模型精度的影响应该也比较小。
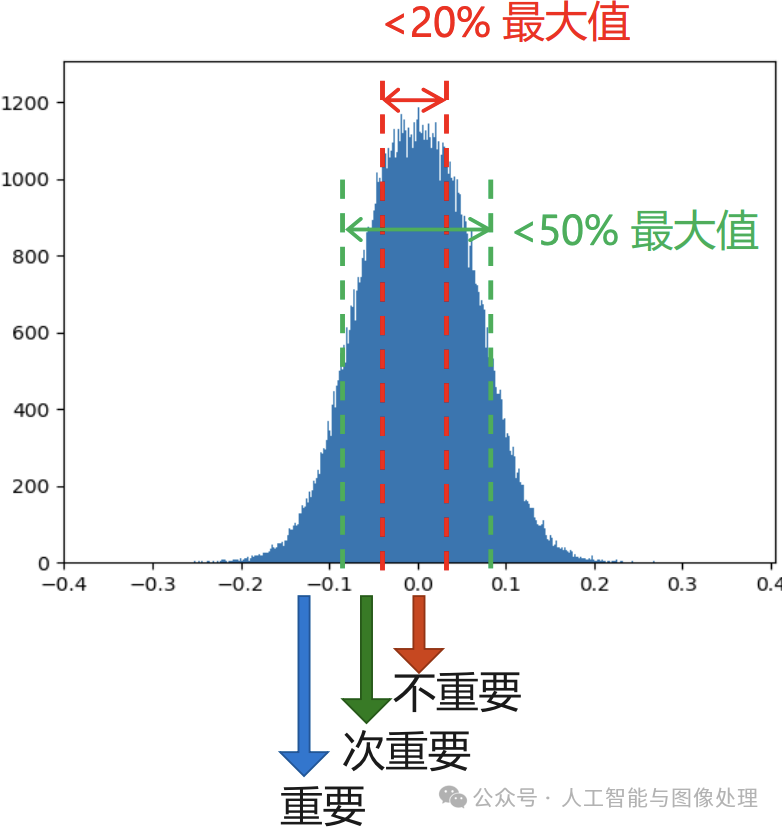
权重参数重要性
当然,权重剪枝(Weight Pruning)虽然影响较小但不等于没有影响,且不同类型、不同顺序的网络层,在权重剪枝后影响也各不相同。相关论文在 AlexNet 的 CONV 层和 FC 层的做了剪枝敏感性实验,结果如下图所示。
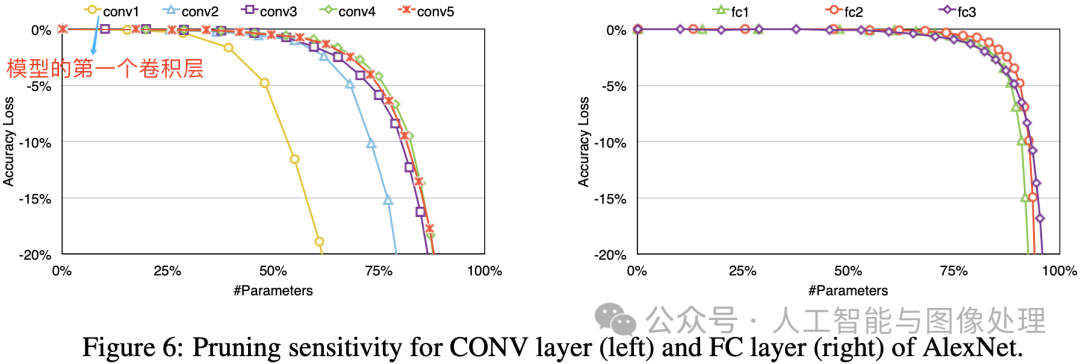
从图中实验结果可以看出,卷积层的剪枝敏感性大于全连接层,且第一层卷积层最为敏感。论文作者推测这是因为全连接层本身参数冗余性更大,第一层卷积层的输入只有 3 个通道所以比起他卷积层冗余性更少。
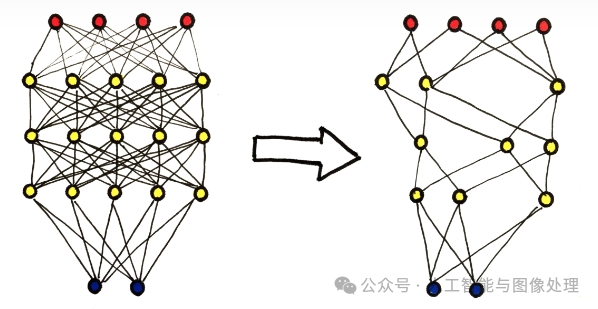
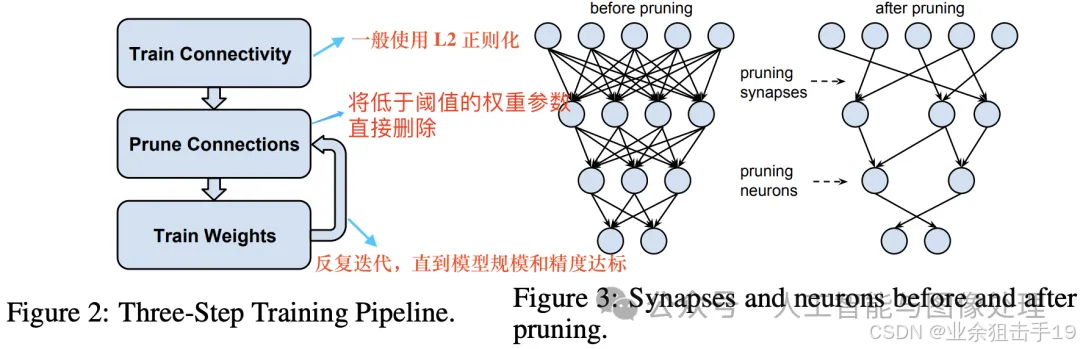
即使是移除绝对值接近于 0 的权重也会带来推理精度的损失,因此为了恢复模型精度,通常在剪枝之后需要再训练模型。典型的模型剪枝三段式工作 pipeline 流程和剪枝前后网络连接变化如下图所示。
1.2,激活稀疏
早期的神经网络模型——多层感知机(MLP)中,多采用Sigmoid函数作为激活单元。但是其复杂的计算公式会导致模型训练过慢,且随着网络层数的加深,Sigmoid 函数引起的梯度消失和梯度爆炸问题严重影响了反向传播算法的实用性。为解决上述问题,Hinton 等人于 2010 年提出了 ReLU 激活函数。
ReLU 激活函数的定义为:
![]()
该函数使得负半轴的输入都产生 0 值的输出,这可以认为激活函数给网络带了另一种类型的稀疏性;另外 max_pooling 池化操作也会产生类似稀疏的效果。即无论网络接收到什么输入,大型网络中很大一部分神经元的输出大多为零。激活和池化稀疏效果如下图所示。
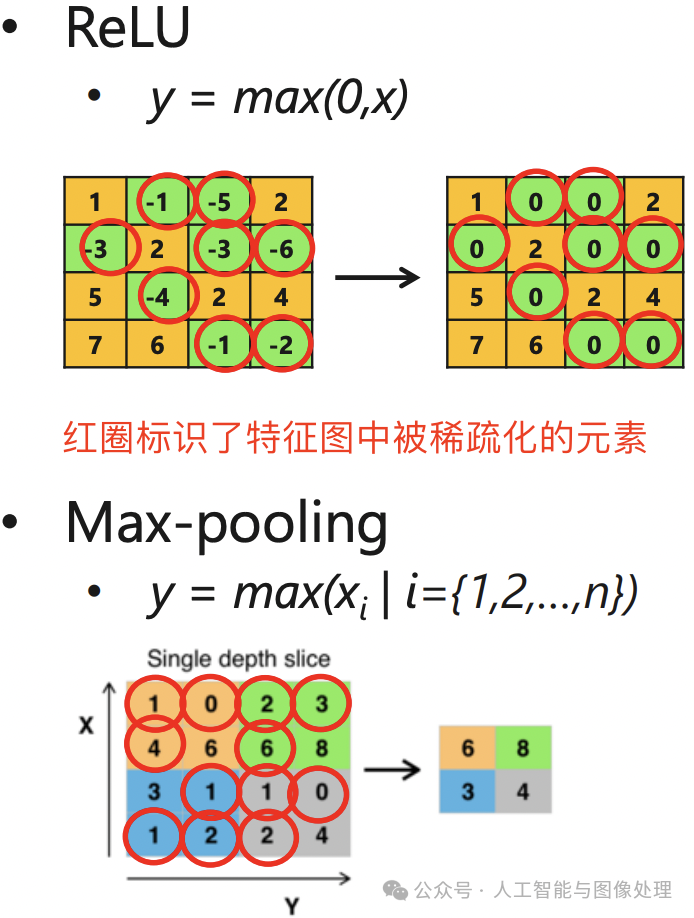
神经网络中的激活稀疏(即 ReLU 激活层和池化层输出特征图矩阵是稀疏的)
1.3,梯度稀疏
大模型(如 BERT)由于参数量庞大,单台主机难以满足其训练时的计算资源需求,往往需要借助分布式训练的方式在多台节点(Worker)上协作完成。采用分布式随机梯度下降(Distributed SGD)算法可以允许 N台节点共同完成梯度更新的后向传播训练任务。
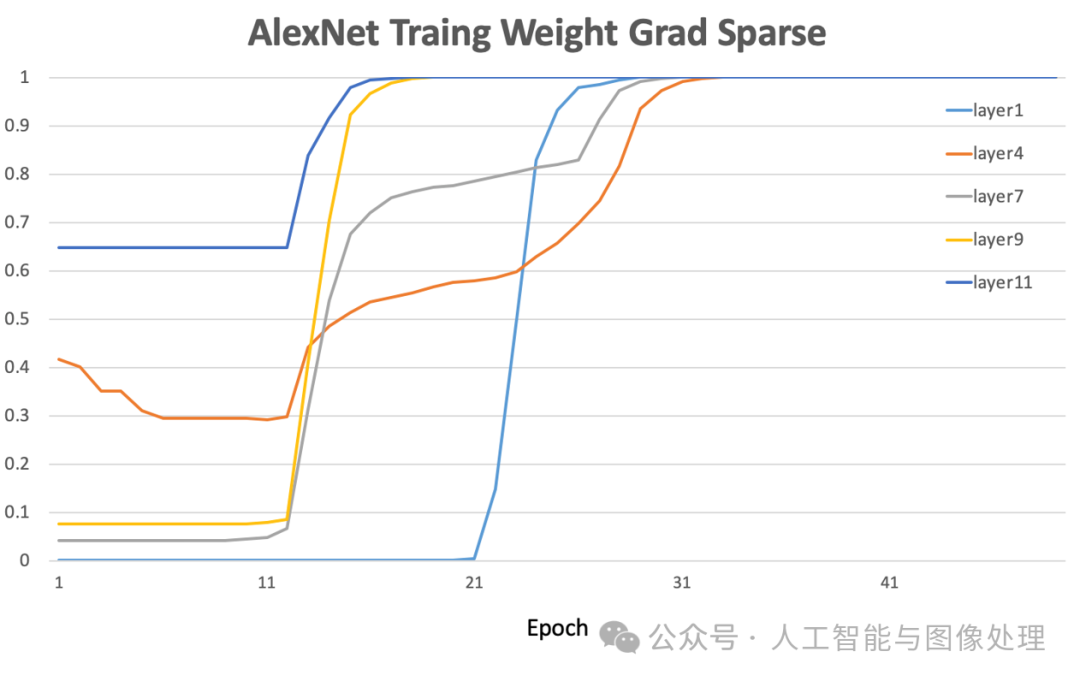
随着参与训练任务节点数目的增多,网络上传输的模型梯度数据量也急剧增加,网络通信所占据的资源开销将逐渐超过梯度计算本身所消耗的资源,从而严重影响大规模分布式训练的效率。另外,大多数深度神经网络模型参数的梯度其实也是高度稀疏的,有研究表明在分布式 SGD 算法中,99.9% 的梯度交换都是冗余的。例如下图显示了在 AlexNet 的训练早期,各层参数梯度的幅值还是较高的。但随着训练周期的增加,参数梯度的稀疏度显著增大。
二,模型剪枝-Pruning
定义:模型剪枝(Pruning)也叫模型稀疏化,不同于模型量化对每一个权重参数进行压缩,稀疏化方法是尝试直接“删除”部分权重参数。模型剪枝的原理是通过剔除模型中 “不重要” 的权重,使得模型减少参数量和计算量,同时尽量保证模型的精度不受影响。
1、剪枝分类:
按照剪枝结构,我们可以将剪枝分为两种类型:非结构化剪枝和结构化剪枝
1.1 非结构化剪枝
-
特点
-
一般做法:通过Pytorch访问所有weight,将满足条件的weight置为0就行,是比较精细的剪枝做法。
-
-
类型
-
细粒度剪枝(
fine-grained) -
向量剪枝(
vector-level) -
卷积核剪枝(
kernel-level)
-
1.2 结构化剪枝
-
类型
-
滤波器剪枝(
filter-level):对卷积核组进行纵向的修剪 -
通道剪枝(
channel-level):对卷积核组进行横向剪枝 -
层剪枝(
layer-level):直接删除整个卷积层
-
2、修剪标准
2.1 基于权重大小的修剪标准(Weight Magnitude-based Criterion)
该标准根据模型参数的绝对值大小来确定是否剪枝。具体而言,根据预先设定的阈值,将权重绝对值小于该阈值的参数设置为零,从而实现剪枝。这个标准假设权重绝对值较小的参数对模型的影响较小,因此可以被裁剪。
优点:
-
简单易实现,只需要比较权重的绝对值和阈值即可进行修剪。
-
可以实现较高的压缩比例,因为小于阈值的权重可以直接设置为零。
缺点:
-
忽略了参数的梯度信息,可能会丢失一些重要的参数。
-
需要手动选择合适的阈值,可能需要进行试错。
代码示例:
import torch
import torch.nn as nn
# 定义一个模型
model = nn.Sequential(
nn.Linear(10, 100),
nn.ReLU(),
nn.Linear(100, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
# 基于权重大小的修剪标准
def weight_magnitude_pruning(model, threshold):
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
mask = torch.abs(module.weight) >= threshold
module.weight.data *= mask.float()
# 使用示例
threshold = 0.1
weight_magnitude_pruning(model, threshold)
2.2 基于梯度幅度的修剪标准(Gradient Magnitude-based Criterion)
该标准根据模型参数的梯度幅度来确定是否剪枝。梯度幅度较小的参数被认为对模型的训练和性能影响较小,因此可以被裁剪。一种常见的方法是,在训练过程中记录参数的梯度值,并根据梯度幅度进行修剪。
优点:
-
考虑了参数的梯度信息,可以保留对模型训练和性能有贡献的参数。
-
可以在训练过程中动态地进行修剪。
缺点:
-
在训练过程中需要额外计算参数的梯度,增加了计算开销。
-
梯度幅度的选择需要谨慎,过小的阈值可能会过度剪枝,导致模型性能下降。
代码示例:
import torch
import torch.nn as nn
# 定义一个模型
model = nn.Sequential(
nn.Linear(10, 100),
nn.ReLU(),
nn.Linear(100, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
# 基于梯度幅度的修剪标准
def gradient_magnitude_pruning(model, threshold):
for name, param in model.named_parameters():
if 'weight' in name:
mask = torch.abs(param.grad) >= threshold
param.data *= mask.float()
# 使用示例
threshold = 0.01
gradient_magnitude_pruning(model, threshold)
2.3 基于梯度和权重大小的混合标准(Hybrid Criterion)
该标准结合了基于权重大小和梯度幅度的修剪标准。它考虑了参数的重要性和训练过程中的梯度信息。例如,可以将基于权重大小的修剪标准用于全连接层,而对于卷积层可以使用基于梯度幅度的修剪标准。通过结合不同的标准,可以更加全面地评估参数的重要性,从而进行修剪。
优点:
-
综合考虑了权重大小和梯度幅度两个因素,更全面地评估参数的重要性。
-
可以根据不同类型的层使用不同的修剪标准,提高灵活性。
缺点:
-
实现相对复杂,需要根据具体情况设计合适的混合策略。
代码示例:
import torch
import torch.nn as nn
# 定义一个模型
model = nn.Sequential(
nn.Linear(10, 100),
nn.ReLU(),
nn.Linear(100, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
# 基于梯度和权重大小的混合标准
def hybrid_pruning(model, weight_threshold, gradient_threshold):
for name, module in model.named_modules():
if isinstance(module, nn.Linear):
weight_mask = torch.abs(module.weight) >= weight_threshold
gradient_mask = torch.abs(module.weight.grad) >= gradient_threshold
mask = weight_mask & gradient_mask
module.weight.data *= mask.float()
# 使用示例
weight_threshold = 0.1
gradient_threshold = 0.01
hybrid_pruning(model, weight_threshold, gradient_threshold)3、修剪方法
3.1 训练后剪枝
核心代码:
def prune_network(model, pruning_rate=0.5, method='global'):
for name, param in model.named_parameters():
if 'weight' in name:
tensor = param.data.cpu().numpy()
if method == "global":
threshold = np.percentile(abs(tensor), pruning_rate * 100)
else: # local pruning
threshold = np.percentile(abs(tensor), pruning_rate * 100, axis=1, keepdims=True)
mask = abs(tensor) > threshold
param.data = torch.FloatTensor(tensor * mask.astype(float)).to(param.device)3.2 训练时剪枝(pruning with rewinding)
核心代码
# 3. 训练时修剪
def train_with_pruning(model, dataloader, criterion, optimizer, device='cpu', num_epochs=10, pruning_rate=0.5):
model.train()
model.to(device)
for epoch in range(num_epochs):
running_loss = 0.0
for batch_idx, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs.view(inputs.size(0), -1))
loss = criterion(outputs, targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {running_loss / len(dataloader)}")
# 在每个 epoch 结束后进行剪枝
prune_network(model, pruning_rate, method="global") # <================================== just prune the weights ot 0 but still allow them to grow back by optimizer.step()
return model上述剪枝的方法除了直接置零的剪枝外,还有将部分权重数据remove的。
-
直接填0的剪枝
优点:保留了原始网络结构,便于实现和微调,部分减少模型的计算量
缺点:零权重仍然需要存储,因此不会减少内存使用,一些硬件和软件无法利用稀疏计算,从而无法提高计算效率
-
直接remove的剪枝
优点:可以减少模型的计算量和内存使用,可以通过减少网络容量来防止过拟合
缺点:可能会降低网络的表示能力,导致性能下降,需要对网络结构进行改变,这可能会增加实现和微调的复杂性。
4、稀疏训练
其步骤主要包含以下四步:
-
1)初始化带有随机mask的网络:首先我们定义了一个包含两个线性层的神经网络,同时使用create_mask方法为每个线性层创建一个与权重相同形状的mask,通过top-k方法选择一部分元素变成0,实现了一定的稀疏性,其中sparsity_rate为稀疏率
-
2)训练一个epoch的pruned network:使用随机mask训练网络,然后更新mask
-
3)剪枝权重:将权重较小的一部分权重剪枝,对应的mask中的元素变成0
-
4)重新regrow同样数量的random weights:在mask中元素为0的位置随机选择与剪枝的元素数量相同,将其对应的元素重新生成
5、dropout和dropconnect layer
dropout和dropconnect都是常见的神经网络正则化技术,它们的主要作用是减少神经网络的过拟合现象,提高模型的泛化能力。但是它们在实现上有所不同,下面分别介绍一下它们的区别。(from chatGPT)
-
dropout
dropout是Hinton团队在2012年提出的正则化方法。它的实现方式是在神经网络的训练过程中,以一定的概率随机地删除一部分神经元,即将神经元的输出设置为0,从而使神经元不会过度依赖其他神经元。dropout可以看做是一种模型平均方法,可以让不同的神经元组合成不同的子网络,增加了模型的泛化能力。
-
dropconnect
dropconnect是Wan等人在2013年提出的正则化方法。它的实现方式是在神经网络的训练过程中,以一定的概率随机地删除一部分连接权重,即将权重设置为0,从而使每个神经元都不能过度依赖其他神经元的输入。相比于dropout,dropconnect删除的是权重,而不是神经元的输出,从而可以更加灵活地控制神经元之间的相互关系。
综上所述,dropout和dropconnect的主要区别在于它们删除的是神经元输出还是连接权重。由于删除的对象不同,它们对于模型的正则化效果也会有所不同,需要根据具体的应用场景选择合适的正则化方法。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









