







本文首发于微信公众号:人工智能与图像处理
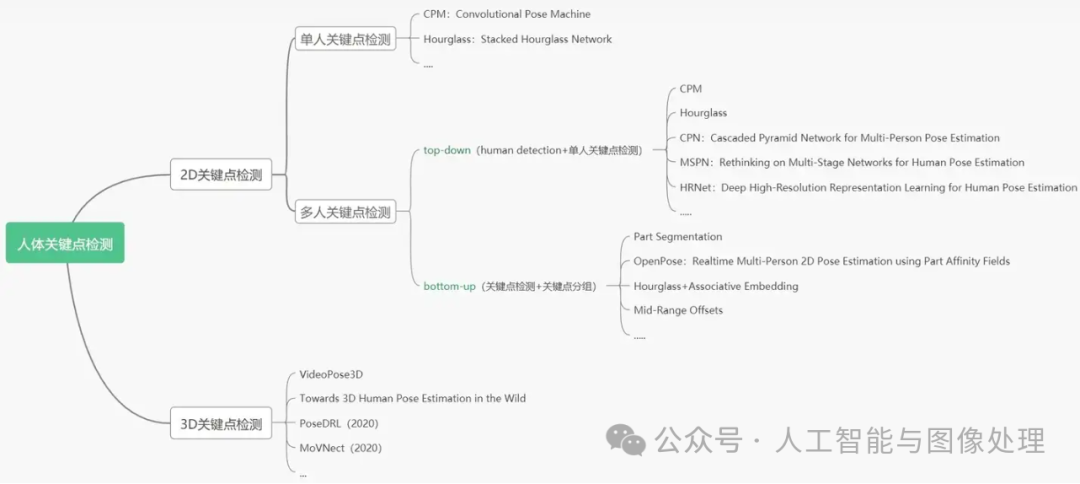
目录
一、简介
二、人体关键点检测数据集
三、关键点检测任务的目标构建
四、单人2D关键点检测相关算法
五、多人2D关键点检测相关算法
六、3D关键点检测相关算法
一、简介
本文主要介绍人体关键点检测领域,包括单人2D人体骨骼关键点检测算法、多人2D人体骨骼关键点检测算法以及3D人体骨骼关键点检测算法。这些技术在计算机视觉领域中具有广泛应用,包括姿态估计、行为识别、人机交互、虚拟现实、智能家居和无人驾驶等领域。人体骨骼关键点检测由于人体姿态多变、受多种因素影响,例如遮挡、光照等,因此具有极大挑战性。
本文主要介绍内容包括:
-
单人2D人体骨骼关键点检测算法
-
多人2D人体骨骼关键点检测算法
-
3D人体骨骼关键点检测算法
二、人体关键点检测相关数据集
2.1 2D数据集
表格排版不太好调,将就看下吧
| 数据集 | 类型 | 关节点数 | 样本数/10^3 | 使用情况 | 数据集地址 | ||||
| LSP | 单人 | 14 | 2 | 基本弃用 | http://sam.johnson.io/research/lsp.html | ||||
| FLIC | 单人 | 9 | 20 | 基本弃用 | https://bensapp.github.io/flic-dataset.html | ||||
| MPII | 单人、多人 | 16 | 25 | 主流 | http://human-pose.mpi-inf.mpg.de/ | ||||
| MSCOCO | 多人 | 17 | >300 | 主流 | http://cocodataset.org/#download | ||||
| AI Challenge | 多人 | 14 | 约=380 | 竞赛专用 | https://challenger.ai/competition/keypoint/subject | ||||
| PoseTrack | 多人 | 15 | >20帧 | 多用于姿态追踪 | https://www.posetrack.net/users/download.php | ||||
2.2 3D数据集
表格排版不太好调,将就看下吧
| 数据集 | 采集场景 | 采集人数 | 样本数/10^4帧 | 采集人数 | 数据集地址 |
| Human3.6M | 室内 | 11 | 360 | 运动捕捉 | http://vision.imar.ro/human3.6m/description.php |
| HumanEva | 室内 | 4 | 约=8 | 运动捕捉 | http://humaneva.is.tue.mpg.de/ |
| Total Capture | 室内 | 5 | 190 | 运动捕捉 | https://github.com/CMU-Perceptual-Computing-Lab/panoptic-toolbox、http://domedb.perception.cs.cmu.edu/dataset.html |
| JTA Dataset | 虚拟场景 | >20 | 50 | 人工注释 | http://aimagelab.ing.unimore.it/jta、https://github.com/fabbrimatteo/JTA-Dataset |
| MPI-INF-3DHP | 合成场景 | 8 | >130 | 运动捕捉、图像合成 | http://gvv.mpi-inf.mpg.de/3dhp-dataset/ |
| SURREAL | 合成场景 | 145 | 650 | 运动捕捉、图像合成 | https://www.di.ens.fr/willow/research/surreal/data/ |
| 3DPW | 室外 | 5 | >5 | 运动捕捉 | https://hyper.ai/cn/datasets/16463 |
| UP-3D | 图像采集 | 图像采集 | 约=0.7(10^4幅) | 人工注释 | http://files.is.tuebingen.mpg.de/classner/up/ |
| DensePose COCO | 图像采集 | 图像采集 | 5(10^4幅) | 人工注释 | https://github.com/facebookresearch/DensePose、https://www.aiuai.cn/aifarm278.html、http://densepose.org/#dataset |
三、关键点检测的Ground Truth的构建
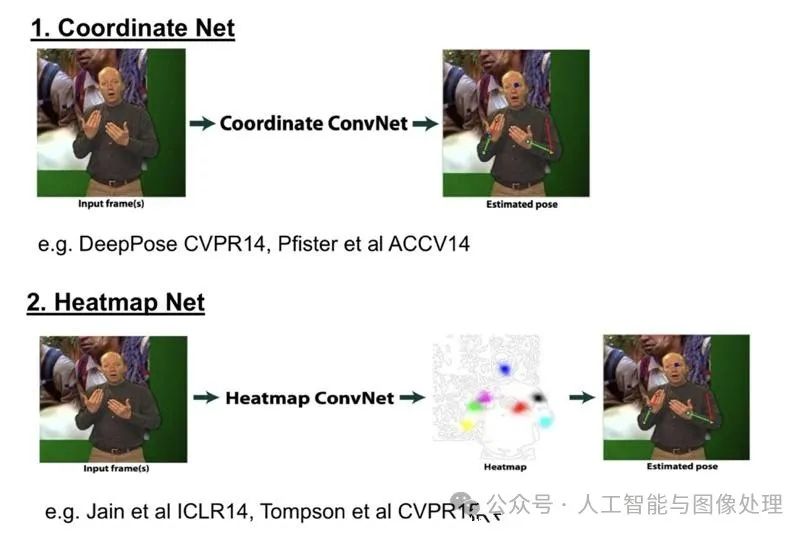
1)Coordinate
在关键点检测中,"Coordinate" 指的是直接将关键点的坐标作为最终神经网络需要回归的目标。这种方法可以直接获得每个关键点坐标的具体位置信息。
2)Heatmap
Heatmap是一种方法,它使用概率图来表示每个关键点类别的位置。对于图像中的每个像素位置,都会被赋予一个概率值,表示该像素点属于对应类别关键点的概率。通常来说,离关键点位置越近的像素点概率越接近1,离关键点位置越远的像素点概率则越接近0。通常可以通过使用相应的函数(如二维高斯函数)进行模拟。如果同一个像素位置到不同关键点的距离不同,即相对于不同关键点该位置的概率也不同,这时可以选择取最大值或平均值作为该位置的概率表示。
对于两种Ground Truth的差别:
坐标网络基本上需要回归出每个关键点相对于图像的偏移量,然而在实际学习中,长距离的偏移量很难准确回归,会产生较大误差。同时,训练过程中提供的监督信息较少,导致整个网络收敛速度较慢。
Heatmap网络直接回归每个关键点类别的概率,这样可以在一定程度上为每个点提供监督信息,使网络更快地收敛。同时,对每个像素位置进行预测可以提高关键点的定位精度。在可视化方面,Heatmap也比Coordinate更优。此外,实践证明,Heatmap确实要比Coordinate更为优越。具体结构如下图所示。
-
3)Heatmap + Offsets
Heatmap + Offsets是Google在CVPR 2017上提出的概念。与单纯的Heatmap不同的是,Google的Heatmap指的是在距离目标关键点一定范围内的所有点的概率值都为1。除了Heatmap之外,使用Offsets,即偏移量来表示距离目标关键点一定范围内的像素位置与目标关键点之间的关系。
四、单人2D关键点检测算法
-
1).DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR’14) mitmul/deeppose: DeepPose implementation in Chainer (github.com)
-
2).Efficient Object Localization Using Convolutional Networks (CVPR’15) https://arxiv.org/pdf/1411.4280.pdf
-
3).Convolutional Pose Machines(2016)(PDF) Convolutional Pose Machines (researchgate.net)
-
4).Learning Feature Pyramids for Human Pose Estimation(ICCV2017)bearpaw/PyraNet: Code for "Learning Feature Pyramids for Human Pose Estimation" (ICCV 2017) (github.com)
-
5).Stacked Hourglass Networks for Human Pose Estimation (2017) https://arxiv.org/pdf/1603.06937.pdf
-
6).Multi-Context Attention for Human Pose Estimation (2018)[1702.07432] Multi-Context Attention for Human Pose Estimation (arxiv.org)
-
7).A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation (2018) https://ojs.aaai.org/index.php/AAAI/article/view/12334
-
8).Deeply Learned Compositional Models for Human Pose Estimation (2018ECCV https://openaccess.thecvf.com/content_ECCV_2018/papers/Wei_Tang_Deeply_Learned_Compositional_ECCV_2018_paper.pdf
-
9).Human Pose Estimation with Spatial Contextual Information (2019) https://arxiv.org/pdf/1901.01760
-
10).Cascade Feature Aggregation for Human Pose Estimation (2019) https://arxiv.org/pdf/1902.07837
-
11).Toward fast and accurate human pose estimation via soft-gated skip connections (2020) https://arxiv.org/pdf/2002.11098
五、多人2D关键点检测算法
多人关键点检测分自上而下和自下而上两种方法:
-
自上而下(Top-Down)的人体骨骼关键点检测算法主要包含两个部分,目标检测和单人人体骨骼关键点检测,对于目标检测算法,这里不再进行描述,而对于关键点检测算法,首先需要注意的是关键点局部信息的区分性很弱,即背景中很容易会出现同样的局部区域造成混淆,所以需要考虑较大的感受野区域;其次人体不同关键点的检测的难易程度是不一样的,对于腰部、腿部这类关键点的检测要明显难于头部附近关键点的检测,所以不同的关键点可能需要区别对待;最后自上而下的人体关键点定位依赖于检测算法的提出的Proposals,会出现检测不准和重复检测等现象,大部分相关论文都是基于这三个特征去进行相关改进。
-
自下而上(Bottom-Up)的人体骨骼关键点检测算法主要包含两个部分,关键点检测和关键点聚类,其中关键点检测和单人的关键点检测方法上是差不多的,区别在于这里的关键点检测需要将图片中所有类别的所有关键点全部检测出来,然后对这些关键点进行聚类处理,将不同人的不同关键点连接在一块,从而聚类产生不同的个体。而这方面的论文主要侧重于对关键点聚类方法的探索,即如何去构建不同关键点之间的关系。
5.1 多人2d关键点检测算法(自上而下)
-
1).RMPE: Regional Multi-Person Pose Estimation(2018) https://arxiv.org/pdf/1612.00137
-
2).Cascaded Pyramid Network for Multi-Person Pose Estimation(cpn)(2018) https://arxiv.org/pdf/1711.07319
-
3).Rethinking on Multi-Stage Networks for Human Pose Estimation(2019) https://arxiv.org/pdf/1901.00148
-
4).Spatial Shortcut Network for Human Pose Estimation(2019 https://arxiv.org/pdf/1904.03141
-
5).Deep High-Resolution Representation Learning for Human Pose Estimation (2019cvpr) https://arxiv.org/pdf/1902.09212
5.2 多人2d关键点检测算法(自下而上)
-
1).OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE2019)https://arxiv.org/pdf/1812.08008
-
2).Single-Network Whole-Body Pose Estimation(ICCV2019) https://arxiv.org/pdf/1909.13423
六、3D关键点检测算法
-
1).Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose(2017) https://arxiv.org/pdf/1611.07828
-
2).A simple yet effective baseline for 3d human pose estimation(ICCV2017) https://arxiv.org/pdf/1705.03098
-
3).RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation(CVPR2019) https://arxiv.org/pdf/1902.09868
-
4).Generating Multiple Hypotheses for 3D Human Pose Estimation with Mixture Density Network(cvpr2019) https://arxiv.org/pdf/1904.05547
-
5).Learnable Triangulation of Human Pose(ICCV 2019 oral) https://arxiv.org/pdf/1905.05754
-
6).Weakly-Supervised Discovery of Geometry-Aware Representation for 3D HumanPose Estimation(cvpr2019) https://arxiv.org/pdf/1903.08839
-
7).3D human pose estimation in video with temporal convolutions and semi-supervised training (cvpr2019) https://arxiv.org/pdf/1811.11742
-
8).Semantic Graph Convolutional Networks for 3D Human Pose Regression (cvpr2019)https://arxiv.org/pdf/1904.03345
-
9).Exploiting Spatial-temporal Relationships for 3D Pose Estimation via Graph Convolutional Networks(ICCV2019) https://openaccess.thecvf.com/content_ICCV_2019/papers/Cai_Exploiting_Spatial-Temporal_Relationships_for_3D_Pose_Estimation_via_Graph_Convolutional_ICCV_2019_paper.pdf
-
10).3D Human Pose Estimation using Spatio-Temporal Networks with Explicit Occlusion Training (AAAI2020) https://arxiv.org/pdf/2004.11822
-
11).Motion Guided 3D Pose Estimation from Videos(2020) https://arxiv.org/pdf/2004.13985
-
12).XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera(2020) https://arxiv.org/pdf/1907.00837
-
13).VIBE: Video Inference for Human Body Pose and Shape Estimation (2020cvpr)https://arxiv.org/pdf/1912.05656

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









