






最近在参照着《西瓜书》在学机器学习,里面写到引入“正则化”项可以有效防止过拟合,对此,本人看的一愣一愣的,所以查阅了一些资料,并掺入了一些个人理解,如个人理解有误请见谅,欢迎探讨,话不多说,进入正文。
在解释“正则化”可以防止过拟合前需要先解释些事情:
1、什么是拟合?——通俗讲就是用一条曲线去描数据点,使数据点尽可能多的在这条曲线上
2、什么是过拟合?——通俗讲就是用一条曲线去描数据点,且不管数据点的好坏以及数据点的特殊性,使所有的数据点都在这条曲线上
3、什么是“正则化”?——简单、直接的理解就是在损失函数中引入一个“正则化”项,来使得拟合曲线多项式中的系数变小,系数变小后过拟合风险就会降低(拟合曲线可用多项式表达,因为从泰勒展开式可以知道所有的曲线都是可以由多项式去逼近)
由3可以引申出本文需要着重解释的三大问题
问题一:为什么拟合曲线多项式中的系数变小了,过拟合风险就会降低?
对于问题一,我给出了两种解释思路,一种是自己想的,一种总结网上大佬的,大家看看哪种更能接受。
思路1:
下图就是一种过拟合的情况(因为本人比较懒,所以拿了别的博主的图来用)
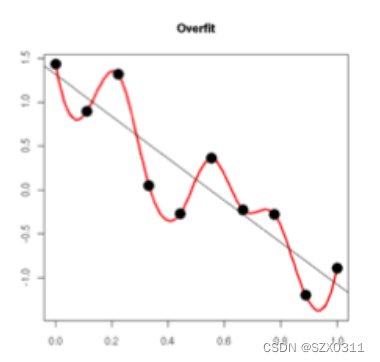
图中黑点是采样所得到的数据点,红线是过拟合时所得到的拟合曲线,黑线是实际规律曲线
为了更好说明,我们在相对坐标系中进行讨论,这里假设黑线是x轴,红色曲线是斜着的sin函数(即在相对坐标系中,关于x轴的sin函数)
将sin函数泰勒展开可得如下:
![]()
我们在sin函数前面乘以一个小于1的系数α,α就代表着sin函数的曲线的幅值,当α越小时,sin的幅值就越小,sin函幅值就越接近黑色实线,过拟合的风险就越小。
上面展开式左边乘以一个α,右边各项也应均乘以α,多项式的系数也就变小了,因此,我们知道拟合多项式中的系数变小,过拟合风险就会降低。
思路2:
当然,如果我上面给出的解释仍有小伙伴不能接受,不防从导数的方向去思考,多项式求导,系数大小直接决定所求导数绝对值的大小,导数绝对值越大,原函数变化速率越快,相应的变化的幅度也就越大,曲线可能就会更波动,过拟合的风险相应的也就会增大
问题二:为什么引入“正则化”项就可以使拟合曲线多项式中的系数变小?
我们定义损失函数为L(w),《西瓜书》中以w的2范数的平方做为“正则化”项
因此可以得到新的损失函数L'(w)如下所示:
![]()
式中w我们可以理解成多项式系数组成的向量,λ是正则化参数,且1>λ>0(别问为啥1>λ>0,问就是规定如此)
上面我们讲过,拟合曲线是个多项式,因此,我们只要根据w的约束条件求出相应的系数w后,就可以得到相应的拟合曲线
那么,w的约束是什么?——令损失函数最小就是w的约束。想一下,我们想得到的曲线肯定是泛化误差最小的曲线,而泛化误差是损失函数的期望,那么是不是可以得出,损失函数最小,泛化误差就最小(此处本人参考来源:损失函数的期望值与泛化误差_损失函数的数学期望-CSDN博客)
我们知道,一般损失函数都比较复杂,计算机无法直接给出准确的解,所以一般采用迭代的方式来求解损失函数最小时所对应的w,即令:
![]()
因此,可得:
引入“正则化”项前
![]()
![]()
引入“正则化”项后
![]()
![]()
式中1>η>0,η是学习率,《西瓜书》公式5.2下面一段有写
对比上式我们不难发现引入“正则化”项后w明显变小了。因此,可以知道引入“正则化”项可以有效的降低过拟合的风险
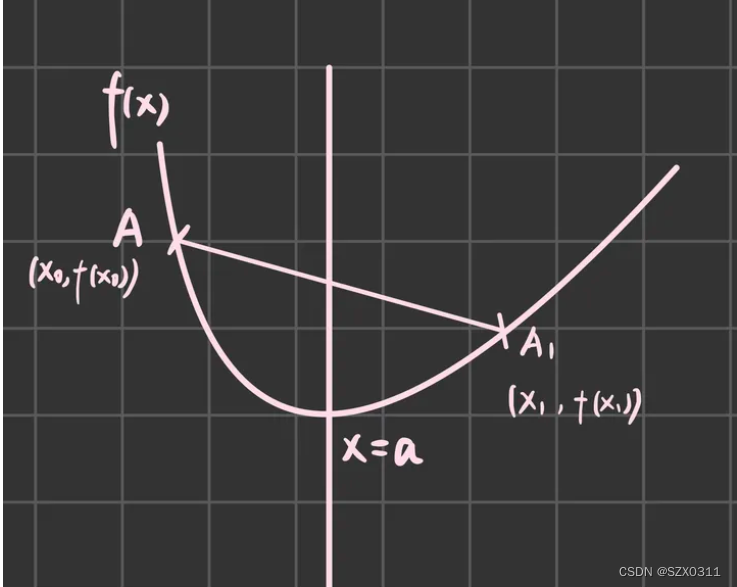
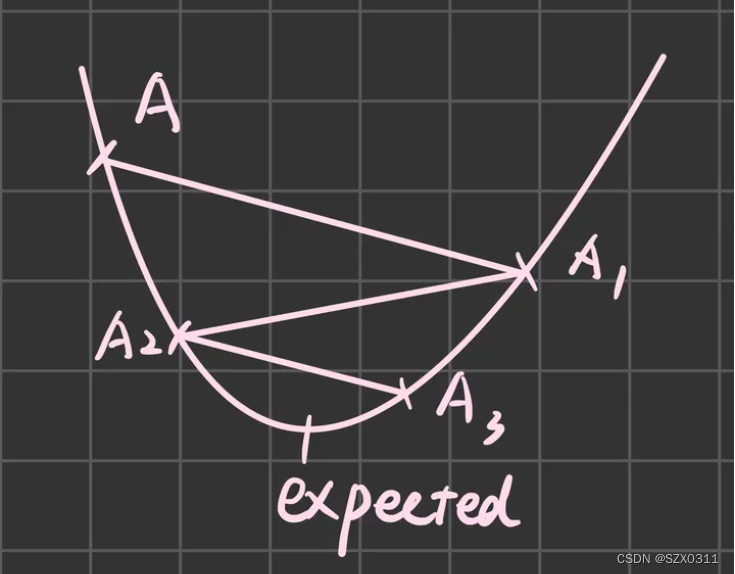
问题三:为什么![]() ?
?
这部分有些懒得解释,懒得写了,所以引用一下别人的,个人觉得写的蛮好的


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









